




▋ OceanBase 4.0的分布式查询优化
我们认为分布式查询优化一定要使用一阶段的方法,即要同时枚举本地算法和分布式算法并且使用分布式代价模型来计算代价,而不是通过分阶段的方式来枚举本地算法和分布式算法。OceanBase 4.0 重构了整个分布式查询优化方法,从原先的二阶段变成了一阶段的分布式查询优化方法。
为了方便我们描述一阶段的分布式查询优化方法,这里我们简单介绍一下 System-R 的 Bottom-up 的动态规划方法。给定一个 SQL 语句,System-R 用 bottom-up 的动态规划的方法来进行连接枚举和连接算法的选择。给定一个 N 张表的连接,该方法以 size 为驱动枚举每一个子集的执行计划。对于每一个枚举的子集,该方法通过如下的方式来获取最优的计划:
枚举所有单机的连接算法,维护序这个物理属性,使用单机代价模型来计算代价。
保留代价最小的计划和存在有用序的计划,一个计划的序是有用的当且仅当该序对后续算子的分配有用。
下图展示了一个 4 张表的连接枚举例子。该算法首先会枚举大小为 1 的基表的计划,对于每一张基表,该方法会枚举所有的索引并且保留代价最小和存在有用序的计划。然后该算法为枚举每个大小为 2 的子集的计划,比如在枚举 {R1,R2} 这两张表的连接的时候,该方法会考虑所有的单机的连接算法,然后再正交上所有 R1 和 R2 保留的计划,最终达到枚举所有执行计划的目的。以此类推,该算法会继续枚举直至大小为 4 的子集的计划都已经枚举完成。
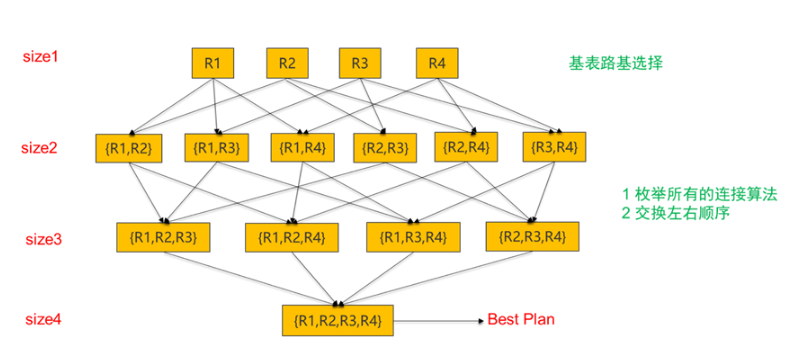
基于已有的单机的 System-R 的查询优化方法,OceanBase 4.0 的分布式查询优化按照如下的方式工作:
对于每一个枚举的子集,枚举所有算子的分布式算法,对于每一个分布式算法,OceanBase 使用分布式代价模型来计算代价,同时 OceanBase 会同时维护序和分区信息这两个物理属性。
对于每一个枚举子集,除了保留代价最小的计划,保留存在有用序的计划,同时还需要保留有存在有用分区信息的计划。一个分区信息是有用的当且仅当它对后续的算子有用。考虑下图所示的场景, 在该场景中,P1 采用了 HASH-HASH 重分区的 HASH JOIN 方法, P2 采用了对 R2 做 BROADCAST 的 HASH JOIN 方法,虽然 P2 的代价比 P1 的代价高,但是 P2 继承了 R1 的分区信息,对后续的 group by 算子是有用的,因此 P2 这个计划也会被保留。
create table R1(a int primary key, b int, c int, d int) partition by hash(a) partitions 4;
create table R2(a int primary key, b int, c int, d int) partition by hash(a) partitions 4;
select R1.a, SUM(R2.c) from R1, R2 where R1.b = R2.b group by R1.a;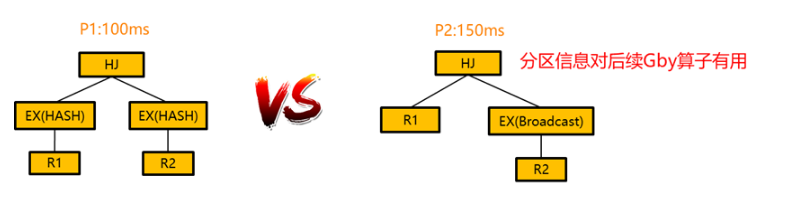
OceanBase 4.0 使用了一阶段的分布式查询优化方法,相比于单机的查询优化,分布式查询优化的计划空间是非常大的。为了解决计划空间大的问题,OceanBase 4.0 发明了很多快速裁剪计划的方法以及新增了新的连接枚举算法来支持超大规模表的分布式计划枚举。 通过这些技术,OceanBase 4.0 大大减少了分布式计划空间,提升了分布式查询优化的性能。同时我们的实验结果也表明OceanBase 4.0 可以在秒级内完成 50 张表的分布式计划的枚举。
————————————————
原文链接:https://blog.csdn.net/OceanBaseGFBK/article/details/128035333
最后修改时间:2023-02-06 15:48:21
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
