




Table of Contents
Cassandra应用场景(案例) - Cassandra教程™
Cassandra与HBase比较(区别) - Cassandra教程™
Cassandra与关系数据库比较(区别) - Cassandra教程™
Cassandra CQLsh - Cassandra教程™
Cassandra创建键空间(Keyspace) - Cassandra教程™
Cassandra删除数据记录 - Cassandra教程™
Tutorialspoint Cassandra 教程
来源:易百教程
Cassandra教程™
本Cassandra系列教程提供了Cassandra的基本和高级概念。这个Cassandra教程是专为初学者和专业人士编写设计的。
Cassandra是由Apache提供一个分布式和可扩展的NoSQL数据库。
我们的Cassandra教程包括Cassandra的所有主题,如功能,架构,关系与NoSQL,Cassandra vs HBase,安装,键空间,表,视图,Cassandra查询语言,安全性等。
前提条件
在学习Cassandra之前,您必须具备SQL的基本知识。
读者
本Cassandra教程旨在帮助初学者和专业人士。
问题与反馈
本教程是专为初学者准备的,我们不保证您在使用此Cassandra编程教程中没有任何问题。 但是如果有遇到任何错误,不防直接联系反馈给我们,我们能及时去排查和更正,以方便后来更多的学习者。
本站所有代码下载:请扫描本页面底部二维码并关注微信公众号,回复:"代码下载" 获取。
本文属作者原创,转载请注明出处:易百教程 » Cassandra教程
Cassandra是什么? - Cassandra教程™
Apache Cassandra是高度可扩展的,高性能的分布式NoSQL数据库。 Cassandra旨在处理许多商品服务器上的大量数据,提供高可用性而无需担心单点故障。
Cassandra具有能够处理大量数据的分布式架构。 数据放置在具有多个复制因子的不同机器上,以获得高可用性,而无需担心单点故障。
Cassandra是NoSQL数据库
NoSQL数据库是非关系数据库。 它也称为不仅SQL。 它是一个数据库,提供一种机制来存储和检索关系数据库中使用的表格关系以外的数据。 这些数据库是无架构的,支持轻松复制,具有简单的API,最终一致,并且可以处理大量的数据。
Cassandra流行背后的原因
Cassandra是Apache产品。 它是一个开放源码,分布式和分散式/分布式存储系统(数据库)。 它用于管理遍布全球的大量结构化数据。 它提供高可用性,没有单点故障。
Cassandra最重要的几个关键点:
- Cassandra是一个面向列的数据库。
- Cassandra具有可扩展性,一致性和容错能力。
- Cassandra的分销设计是基于Amazon的Dynamo及其在Google Bigtable上的数据模型。
- Cassandra是在Facebook创建的,与关系数据库管理系统完全不同。
- Cassandra遵循Dynamo风格的复制模式,没有单点故障,但增加了更强大的“列系列”数据模型。
- Cassandra正在被Facebook,Twitter,Cisco,Rackspace,eBay,Twitter,Netflix等大型公司所采用。
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
下一篇:Cassandra历史
Cassandra历史 - Cassandra教程™
Cassandra最初由Facebook的两名印度人Avinash Lakshman(亚马逊Dynamo的作者之一)和Prashant Malik共同开发。 它被开发用于为Facebook收件箱搜索功能提供支持。
以下是Cassandra历史上最重要的几个事件:
- Cassandra在Facebook由Avinash Lakshman和Prashant Malik开发。
- 它是为Facebook收件箱搜索功能开发的。
- 2008年7月由Facebook开放。
- 它在2009年3月被Apache Incubator接受收编。
- Cassandra自2010年2月起作为Apache的顶级项目。
- 最新版本的Apache Cassandra是3.2.1。
请参阅下表,其中包括所有Cassandra版本,其发布日期及其功能:
版本 | 原始发行日期 | 最新版本 | 发布日期 | 状态 |
0.6 | 2010-04-12 | 0.6.13 | 2011-04-18 | 不再支持 |
0.7 | 2011-01-10 | 0.7.10 | 2011-10-31 | 不再支持 |
0.8 | 2011-06-03 | 0.8.10 | 2012-02-13 | 不再支持 |
1.0 | 2011-10-18 | 1.0.12 | 2012-10-04 | 不再支持 |
1.1 | 2012-04-24 | 1.1.12 | 2013-05-27 | 不再支持 |
1.2 | 2013-01-02 | 1.2.19 | 2014-09-18 | 不再支持 |
2.0 | 2013-09-03 | 2.0.17 | 2015-09-21 | 不再支持 |
2.1 | 2014-09-16 | 2.1.17 | 2017-02-21 | 仍然支持 |
2.2 | 2015-07-20 | 2.2.9 | 2017-02-21 | 仍然支持 |
3.0 | 2015-11-09 | 3.0.11 | 2017-02-21 | 仍然支持 |
3.10 | 2017-02-03 | 3.10 | 2017-02-03 | 仍然支持 |
3.11 | 2017-02-22 | 3.11 | 2017-02-11 | Github 3.11分支 |
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra是什么?下一篇:Cassandra的特点
Cassandra的特点 - Cassandra教程™
有很多优秀的技术特点使Cassandra非常受欢迎。 以下是Cassandra的一些热门特性/功能的列表:
高可扩展性
Cassandra具有高度的可扩展性,可以帮助您可随时添加更多硬件,以便根据需求附加更多客户和更多数据。
刚性结构
Cassandra没有一个单一的故障点,它可用于无法承受故障的关键业务应用程序。
快速线性规模的性能
Cassandra线性可扩展。它可以提高吞吐量,因为它可以帮助您增加群集中的节点数量。 因此,它保持快速的响应时间。
容错
Cassandra是容错的。 假设集群中有4个节点,这里每个节点都有相同数据的副本。 如果一个节点不再服务,则其他三个节点可以按照请求进行服务。
灵活的数据存储
Cassandra支持所有可能的数据格式,如结构化,半结构化和非结构化。 它可以帮助您根据需要更改数据结构。
简单的数据分发
Cassandra中的数据分发非常简单,因为它可以灵活地通过在多个数据中心复制数据来分发所需的数据。
事务支持
Cassandra支持事务,诸如原子性,一致性,隔离和持久性(ACID)等属性。
快速写入
Cassandra的设计是在便宜的商品硬件上运行。 它执行快速写入,可以存储数百TB的数据,而不会牺牲读取效率。
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra历史下一篇:Cassandra的架构
Cassandra的架构 - Cassandra教程™
Cassandra旨在处理多个节点之间的大数据工作负载,而无需担心单点故障。 它在其节点之间具有对等分布式系统,数据分布在集群中的所有节点上。
- 在Cassandra中,每个节点是独立的,同时与其他节点互连。 集群中的所有节点都扮演着相同的角色。
- 集群中的每个节点都可以接受读取和写入请求,而不管数据实际位于集群中的位置。
- 在一个节点发生故障的情况下,可以从网络中的其他节点提供读/写请求。
Cassandra中的数据复制
在Cassandra中,集群中的节点作为给定数据片段的副本。 如果某些节点以超时值响应,Cassandra会将最新的值返回给客户端。 返回最新值后,Cassandra会在后台执行读取修复,以更新旧值。
请参阅以下图示,以了解Cassandra如何在集群中的节点之间使用数据复制的原理图,以确保没有单点故障。
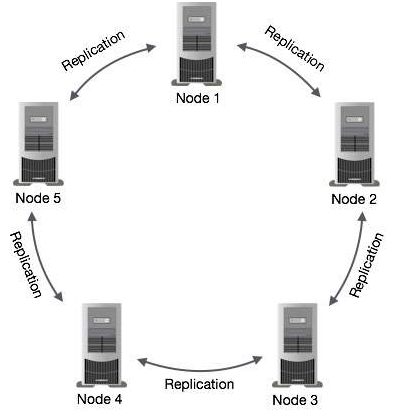
Cassandra的组成部分
Cassandra的主要组成部分主要有:
- 节点(Node):Cassandra节点是存储数据的地方。
- 数据中心(Data center):数据中心是相关节点的集合。
- 集群(Cluster):集群是包含一个或多个数据中心的组件。
- 提交日志(Commit log):在Cassandra中,提交日志是一个崩溃恢复机制。 每个写入操作都将写入提交日志。
- 存储表(Mem-table):内存表是内存驻留的数据结构。 提交日志后,数据将被写入内存表。 有时,对于单列系列,将有多个内容表。
- SSTable:当内容达到阈值时,它是从内存表刷新数据的磁盘文件。
- 布鲁姆过滤器(Bloom filter):这些只是快速,非确定性的,用于测试元素是否是集合成员的算法。 它是一种特殊的缓存。 每次查询后都会访问Bloom过滤器。
Cassandra查询语言
Cassandra查询语言(CQL)用于通过其节点访问Cassandra。 CQL将数据库(Keyspace)视为表的容器。 程序员使用cqlsh:提示使用CQL或单独的应用程序语言驱动程序。
客户端可以接近任何节点进行读写操作。 该节点(协调器)在客户机和保存数据的节点之间扮演代理。
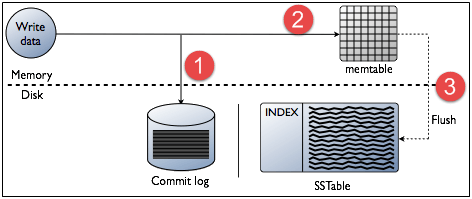
写操作
节点的每个写入活动都由写入节点的提交日志捕获。 之后,数据将被捕获并存储在内存表中。 每当内存表已满时,数据将被写入SStable数据文件。 所有写入在整个集群中自动分区和复制。 Cassandra定期整合SSTables,丢弃不必要的数据。
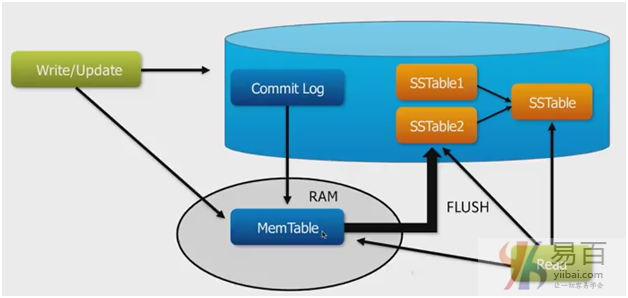
读操作
在读操作中,Cassandra从mem-table中获取值,并检查bloom过滤器以找到包含所需数据的适当SSTable。
有三种类型的读请求被协调者发送给副本。
- 直接请求
- 摘要要求
- 读修复请求
协调器发送的直接请求到副本中的一个。 之后,协调器将摘要请求发送到由一致性级别指定的副本数,并检查返回的数据是否是更新的数据。
之后,协调器将所有剩余的副本发送摘要请求。 如果任何节点发出过期值,后台读修复请求将更新该数据。 这个过程称为读修复机制。
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra的特点下一篇:Cassandra应用场景(案例)
Cassandra应用场景(案例) - Cassandra教程™
Cassandra可用于不同类型的应用。 以下是Cassandra应该是推荐的用例列表:
消息传递
Cassandra是一个很好的数据库,可以处理大量的数据。 因此,是提供移动和消息服务的公司是首选。 这些公司有大量的数据,所以Cassandra最适合他们。
处理高速应用
Cassandra可以处理高速数据,因此它是数据来自不同设备或传感器的数据速度非常快的应用程序的绝佳数据库。
产品目录和零售应用程序
Cassandra被许多零售商用于购物车数据保持和快速的产品目录输入和输出。
社交媒体分析和推荐引擎
Cassandra是许多在线公司和社交媒体提供商的良好数据库,用于分析和推荐给客户。
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra的架构下一篇:Cassandra数据类型
Cassandra数据类型 - Cassandra教程™
Cassandra支持不同类型的数据类型。 下面来看看看下表中的不同数据类型:
CQL | 常量 | 描述 |
asci | Strings | US-ascii字符串 |
bigint | Integers | 64-bit有符号long |
blob | blobs | 任意十六进制字节 |
boolean | Booleans | True 或 False |
counter | Integers | 为64位分布式计数器值 |
decimal | Integers, Floats | 可变精度小数 |
double | Integers, Floats | 64位浮点数 |
float | Integers, Floats | 32位浮点数 |
frozen | 元组,集合,用户定义的类型 | 存储Cassandra类型 |
inet | Strings | ipv4或ipv6格式的IP地址 |
int | Integers | 32位有符号整数 |
list | 元素的集合 | |
ma | JSON风格的元素集合 | |
set | 元素的集合 | |
tex | strings | UTF-8编码字符串 |
timestamp | Integers, Strings | ID生成日期加上时间 |
timeuuid | uuids | 类型1 uuid |
tuple | 一组2,3字段 | |
uuid | uuids | 标准uuid |
varchar | strings | UTF-8编码字符串 |
varint | Integers | 任意精度整数 |
Cassandra自动数据到期
Cassandra提供了数据可以自动过期的功能。
在数据插入期间,您必须以秒为单位指定“ttl”值。 ‘ttl‘值是数据生存价值的时间。 在这段时间之后,数据将被自动删除。
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra应用场景(案例)下一篇:Cassandra数据模型
Cassandra数据模型 - Cassandra教程™
Cassandra中的数据模型与RDBMS中正常情况完全不同。 我们来看看Cassandra如何存储数据。
群集
Cassandra数据库分布在运行的几(多)台机器上。 最外层的容器被称为包含不同节点的群集。 每个节点都包含一个副本,如果发生故障,副本将负责顶上。 Cassandra将节点以环形格式排列在群集中,并为其分配数据。
键空间
键空间(Keyspace)是Cassandra中数据的最外层容器。 以下是Cassandra中Keyspace的基本属性:
- 复制因子:它指定集群中的机器数量,将接收相同数据的副本。
- 复制放置策略:这是一个策略,如何数据将复制品放在环中。有三种类型的策略,如:
- 简单策略(机架感知策略)
- 旧网络拓扑策略(机架感知策略)
- 网络拓扑策略(数据中心共享策略)
- 列家族:列家族置于键空间之下。 键空间是一个或多个列族的列表的容器,而列族是一组行的容器。 每行包含已排序的列。列家族表示数据的结构。每个键空间至少有一个并且经常有很多列家族。
在Cassandra中,良好的数据模型非常重要,因为不良数据模型可能会降低性能,特别是当您尝试在Cassandra上实现RDBMS概念时。
Cassandra数据模型规则
- Cassandra不支持JOINS,GROUP BY,OR子句,聚合等等。因此必须按照需要存储数据的方式存储数据。
- 最大化数据重复,因为Cassandra是分布式数据库,数据重复提供即时可用性而无单点故障。
数据建模目标
在Cassandra中建模数据时,您应该有以下目标:
- 在群集周围均匀传播数据:要在Cassandra群集的每个节点上传播相等数量的数据,您必须选择整数作为主键。 数据根据作为主键的第一部分的分区键传播到不同的节点。
- 查询数据时读取的分区数最小化:分区用于将一组记录与相同的分区键绑定。 当读取查询发出时,它从不同的分区收集不同节点的数据。
在许多分区的情况下,需要访问所有这些分区来收集查询数据。 这并不意味着不应该创建分区。 如果您的数据非常大,则无法在单个分区上保留大量数据。 单个分区将会减慢。 所以必须有一个平衡数量的分区。
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra数据类型下一篇:Cassandra与HBase比较(区别)
Cassandra与HBase比较(区别) - Cassandra教程™
下表说明了Cassandra和HBase之间的主要区别:
HBase | Cassandra |
HBase是基于Bigtable(Google) | Cassandra基于DynamoDB(亚马逊)。 它最初是由前亚马逊工程师在Facebook开发的。 这是Cassandra支持多数据中心的原因之一。 |
HBase使用Hadoop基础架构(Zookeeper,NameNode,HDFS)。 部署Hadoop的组织必须具备Hadoop和HBase的知识。 | Cassandra与Hadoop分开开发,其基础工具和操作知识的要求与Hadoop不同。 然而,对于分析,许多Cassandra部署使用Cassandra + Storm(使用zookeeper)和/或Cassandra + Hadoop。 |
HBase-Hadoop基础工具有几个由Zookeeper,Name Node,HBase master和数据节点组成的“移动部件”,Zookeeper是集群的,自然是容错的。名称节点需要集群为容错。 | Cassandra使用单个节点类型。 所有节点相等并执行所有功能。 任何节点都可以作为协调器,确保没有Spof。 添加Storm或Hadoop当然会增加基础设施的复杂性。 |
HBase非常适合进行基于范围的扫描。 | Cassandra不支持基于范围的行扫描,这可能在某些用例中是有限制的。 |
HBase提供跨越一个HBase集群的异步复制。 | Cassandra随机分区提供了跨越单行的行复制。 |
HBase仅支持有序分区。 | Cassandra正式支持有序分区,但Cassandra没有生产用户使用有序分配,由于“热点”创建并操作困难等热点引起。 |
由于有序分区,HBase可以轻松地水平放置,同时还支持Rowkey范围扫描。 | 如果数据存储在Cassandra的列中以支持范围扫描,Cassandra中行大小的实际限制是10兆字节。 |
HBase支持原子比较和设置,HBase支持一行内的事务。 | Cassandra不支持原子比较和设置。 |
HBase不支持单行读取负载平衡,一行只有一个区域服务器一次提供。 | Cassandra将支持单行读取负载平衡。 |
Bloom过滤器可用于HBase作为另一种形式的索引。 | Cassandra使用bloom过滤器进行键查找。 |
触发器由HBase中的协处理器功能支持。 | Cassandra不支持协处理器功能。 |
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra数据模型下一篇:Cassandra与关系数据库比较(区别)
Cassandra与关系数据库比较(区别) - Cassandra教程™
下表列出了Cassandra和关系数据库(RDBMS)之间的主要区别:
Cassandra | 关系数据库 |
Cassandra用于处理非结构化数据。 | RDBMS用于处理结构化数据。 |
Cassandra具有灵活的模式。 | RDBMS具有固定的模式。 |
在Cassandra中,表是“嵌套键值对”列表(行x列键x列值)。 | 在RDBMS中,表是数组的数组(一行x列) |
在Cassandra中,keyspace是包含与应用对应的数据的最外层的容器。 | 在RDBMS中,数据库是包含与应用程序对应的数据的最外层的容器。 |
在Cassandra中,表或列族是键空间的实体。 | 在RDBMS中,表是数据库的实体。 |
在Cassandra中,行是一个复制单元。 | 在RDBMS中,行是单个/条记录。 |
在Cassandra中,列是一个存储单元。 | 在RDBMS中,列是表示关系的属性。 |
在Cassandra中,使用集合来表示关系。 | 在RDBMS中,有外键,连接等的概念。 |
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra与HBase比较(区别)下一篇:Cassandra安装与配置
Cassandra安装与配置 - Cassandra教程™
Apache Cassandra和Datastax企业级被不同组织用于存储大量数据。在安装Apache Cassandra之前,您必须具备以下事项:
- 必须拥有datastax社区版本,可以点击这里下载Cassandra3.10。
- 必须提前安装好JDK8以上版本。
- 必须提前安装好JDK。
最新版本的Java 8,要验证是否安装了正确版本的Java,请在终端上输入:
java -version
对于使用cqlsh, 需要安装Python 2.7(一定要使用这个版本哦)。要验证是否安装了正确版本的Python,请在终端上输入:
python --version
如下所示 -
C:\Users\Administrator>python --version
Python 2.7.10
C:\Users\Administrator>
从二进制tar文件安装
从Apache Cassandra下载网站下载最新的稳定版本。
将文件解压到某处,如在本示例为:D:\software\apache-cassandra-3.10,例如:
注:为了使用方便,可以将D:\software\apache-cassandra-3.10\bin添加到环境变量中。
进入目录D:\software\apache-cassandra-3.10\bin,通过从命令行调用 cassandra -f,在前台启动Cassandra。 按“Control + C”键停止Cassandra。 在后台通过从命令行调用cassandra启动Cassandra。 调用kill pid或pkill -f CassandraDaemon来停止Cassandra,其中pid是Cassandra进程标识,可以通过调用pgrep -f CassandraDaemon来找到它。
通过从命令行调用nodetool状态来验证Cassandra是否正在运行。
配置文件位于conf子目录中。
由于Cassandra,日志和数据目录分别位于日志和数据子目录中。 旧版本默认为/var/log/cassandra和/var/lib/cassandra。 因此,有必要以root权限启动Cassandra,或者将conf/cassandra.yaml更改为使用当前用户拥有的目录,如下文有关更改目录位置的部分所述。
现在我们来一步步地演示上面的命令,首先启动 cassandra , 在前台启动Cassandra使用以下命令 -
D:\software\apache-cassandra-3.10\bin> cassandra -f
WARNING! Powershell script execution unavailable.
Please use 'powershell Set-ExecutionPolicy Unrestricted'
on this user-account to run cassandra with fully featured
functionality on this platform.
Starting with legacy startup options
.... ....
INFO [main] 2017-04-17 22:35:51,658 Server.java:155 - Using Netty Version: [netty-buffer=netty-buffer-4.0.39.Final.38bdf86, netty-codec=netty-codec-4.0.39.Final.38bdf86, netty-codec-haproxy=netty-codec-haproxy-4.0.39.Final.38bdf86, netty-codec-http=netty-codec-http-4.0.39.Final.38bdf86, netty-codec-socks=netty-codec-socks-4.0.39.Final.38bdf86, netty-common=netty-common-4.0.39.Final.38bdf86, netty-handler=netty-handler-4.0.39.Final.38bdf86, netty-tcnative=netty-tcnative-1.1.33.Fork19.fe4816e, netty-transport=netty-transport-4.0.39.Final.38bdf86, netty-transport-native-epoll=netty-transport-native-epoll-4.0.39.Final.38bdf86, netty-transport-rxtx=netty-transport-rxtx-4.0.39.Final.38bdf86, netty-transport-sctp=netty-transport-sctp-4.0.39.Final.38bdf86, netty-transport-udt=netty-transport-udt-4.0.39.Final.38bdf86]
INFO [main] 2017-04-17 22:35:51,677 Server.java:156 - Starting listening for CQL clients on localhost/127.0.0.1:9042 (unencrypted)...
INFO [main] 2017-04-17 22:35:51,919 CassandraDaemon.java:528 - Not starting RPC server as requested. Use JMX (StorageService->startRPCServer()) or nodetool (enablethrift) to start it
这就启动了。。。
按“Control + C”键停止Cassandra。接下来演示在后台通过从命令行调用cassandra启动Cassandra。
D:\software\apache-cassandra-3.10\bin> cassandra
... ...
INFO [main] 2017-04-17 22:37:38,985 ColumnFamilyStore.java:406 - Initializing system.schema_usertypes
INFO [main] 2017-04-17 22:37:39,002 ColumnFamilyStore.java:406 - Initializing system.schema_functions
INFO [main] 2017-04-17 22:37:39,042 ColumnFamilyStore.java:406 - Initializing system.schema_aggregates
INFO [main] 2017-04-17 22:37:39,046 ViewManager.java:137 - Not submitting build tasks for views in keyspace system as storage service is not initialized
INFO [main] 2017-04-17 22:37:39,614 ApproximateTime.java:44 - Scheduling approximate time-check task with a precision of 10 milliseconds
... ...
INFO [main] 2017-04-17 22:37:56,101 Server.java:155 - Using Netty Version: [netty-buffer=netty-buffer-4.0.39.Final.38bdf86, netty-codec=netty-codec-4.0.39.Final.38bdf86, netty-codec-haproxy=netty-codec-haproxy-4.0.39.Final.38bdf86, netty-codec-http=netty-codec-http-4.0.39.Final.38bdf86, netty-codec-socks=netty-codec-socks-4.0.39.Final.38bdf86, netty-common=netty-common-4.0.39.Final.38bdf86, netty-handler=netty-handler-4.0.39.Final.38bdf86, netty-tcnative=netty-tcnative-1.1.33.Fork19.fe4816e, netty-transport=netty-transport-4.0.39.Final.38bdf86, netty-transport-native-epoll=netty-transport-native-epoll-4.0.39.Final.38bdf86, netty-transport-rxtx=netty-transport-rxtx-4.0.39.Final.38bdf86, netty-transport-sctp=netty-transport-sctp-4.0.39.Final.38bdf86, netty-transport-udt=netty-transport-udt-4.0.39.Final.38bdf86]
INFO [main] 2017-04-17 22:37:56,128 Server.java:156 - Starting listening for CQL clients on localhost/127.0.0.1:9042 (unencrypted)...
INFO [main] 2017-04-17 22:37:56,427 CassandraDaemon.java:528 - Not starting RPC server as requested. Use JMX (StorageService->startRPCServer()) or nodetool (enablethrift) to start it
如下图所示 -
要运行Cassandra shell,重新启动一个命令行窗口并输入cqlsh命令,您将看到命令行执行的结果以下:
D:\software\apache-cassandra-3.10\bin> cqlsh
WARNING: console codepage must be set to cp65001 to support utf-8 encoding on Windows platforms.
If you experience encoding problems, change your console codepage with 'chcp 65001' before starting cqlsh.
Connected to Test Cluster at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 3.10 | CQL spec 3.4.4 | Native protocol v4]
Use HELP for help.
WARNING: pyreadline dependency missing. Install to enable tab completion.
cqlsh>
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra与关系数据库比较(区别)下一篇:Cassandra CQLsh
Cassandra CQLsh - Cassandra教程™
Cassandra CQLsh代表Cassandra CQL shell。 CQLsh指定如何使用Cassandra命令。 安装后,Cassandra提供了一个提示Cassandra查询语言shell(cqlsh)。 它有助于用户与之通信。
Cassandra命令在CQLsh上执行。 看起来像这样:
启动CQLsh:
D:\software\apache-cassandra-3.10\bin>cqlsh
WARNING: console codepage must be set to cp65001 to support utf-8 encoding on Windows platforms.
If you experience encoding problems, change your console codepage with 'chcp 65001' before starting cqlsh.
Connected to Test Cluster at 127.0.0.1:9042.
[cqlsh 5.0.1 | Cassandra 3.10 | CQL spec 3.4.4 | Native protocol v4]
Use HELP for help.
WARNING: pyreadline dependency missing. Install to enable tab completion.
cqlsh>
CQLsh提供了很多选项,在下表中是一些常用的命令:
选项 | 使用/作用 |
help | 此命令用于显示有关CQLsh命令选项的帮助主题。 |
version | 它用于查看您正在使用的CQLsh的版本。 |
color | 它用于彩色输出。 |
debug | 它显示其他调试信息。 |
execute | 它用于引导shell接受并执行CQL命令。 |
file= “file name” | 通过使用此选项,cassandra将在给定文件中执行命令并退出。 |
no-color | 它指示Cassandra不使用彩色输出。 |
u “username” | 使用此选项可以验证用户。 默认用户名为:cassandra。 |
p “password” | 使用此选项,您可以使用密码验证用户。 默认密码是:cassandra。 |
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra安装与配置下一篇:Cassandra创建键空间(Keyspace)
Cassandra创建键空间(Keyspace) - Cassandra教程™
Cassandra查询语言(CQL)可帮助开发人员与Cassandra沟通交互。 Cassandra查询语言的语法与SQL非常相似。
什么是键空间(Keyspace)?
键空间(Keyspace)是用于保存列族,用户定义类型的对象。 键空间(Keyspace)就像RDBMS中的数据库,其中包含列族,索引,用户定义类型,数据中心意识,键空间(Keyspace)中使用的策略,复制因子等。
在Cassandra中,“Create Keyspace”命令用于创建keyspace。
语法:
CREATE KEYSPACE <identifier> WITH <properties>
或者 -
Create keyspace KeyspaceName with replicaton={'class':strategy name,
'replication_factor': No of replications on different nodes}
Cassandra Keyspace的不同组件
策略:Cassandra语法中有两种类型的策略声明:
- 简单策略:在一个数据中心的情况下使用简单的策略。 在这个策略中,第一个副本被放置在所选择的节点上,剩下的节点被放置在环的顺时针方向,而不考虑机架或节点的位置。
- 网络拓扑策略:该策略用于多个数据中心。 在此策略中,您必须分别为每个数据中心提供复制因子。
复制因子:复制因子是放置在不同节点上的数据的副本数。 超过两个复制因子是很好的获得没有单点故障。 所以3个以上是很好的复制因子。
实例:
让我们举个例子来演示如何创建一个名为“yiibai_ks”的键空间。
CREATE KEYSPACE yiibai_ks WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};
执行结果如下所示 -
cqlsh> CREATE KEYSPACE yiibai_ks
... WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};
cqlsh>
cqlsh> CREATE KEYSPACE yiibai_ks WITH replication = {'class':'SimpleStrategy', 'replication_factor' : 3};
AlreadyExists: Keyspace 'yiibai_ks' already exists
cqlsh>
验证:
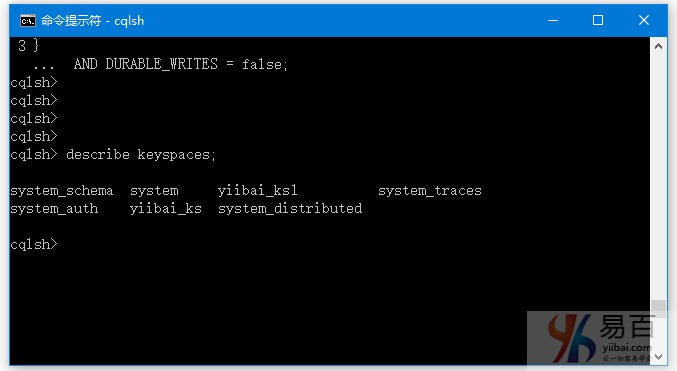
要检查键空间是否创建,请使用“DESCRIBE”命令。 通过使用此命令可以看到创建的所有键空间。
cqlsh> DESCRIBE yiibai_ks;
CREATE KEYSPACE yiibai_ks WITH replication = {'class': 'SimpleStrategy', 'replication_factor': '3'} AND durable_writes = true;
cqlsh>
查看所有的键空间,可使用以下命令 -
cqlsh> DESCRIBE keyspaces
system_schema system_auth system yiibai_ks system_distributed system_traces
cqlsh>
Durable_writes属性
默认情况下,表的durable_writes属性设置为true,您也可以将此属性设置为false。 但是,这个属性不能设置为单机策略。
示例:
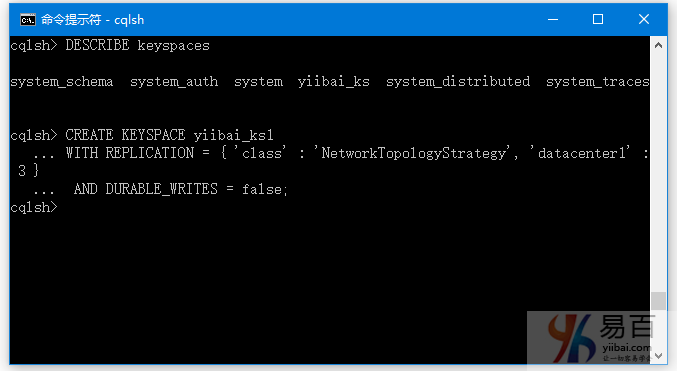
让我们举个例子来看看durable_write属性的用法。
CREATE KEYSPACE yiibai_ks1
WITH REPLICATION = { 'class' : 'NetworkTopologyStrategy', 'datacenter1' : 3 }
AND DURABLE_WRITES = false;
如下图中所示 -
验证:
要检查键空间是否创建,请使用“DESCRIBE”命令。 通过使用此命令可以看到创建的所有键空间。
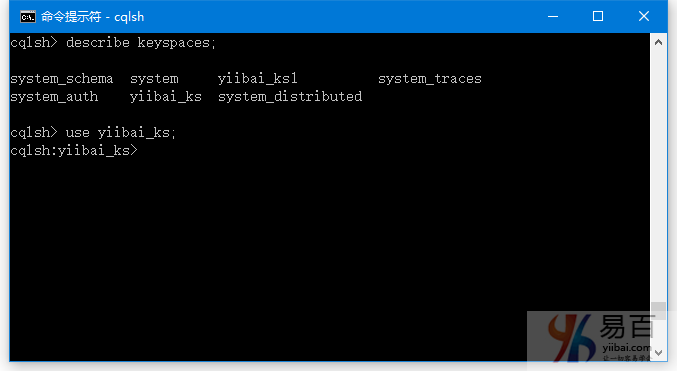
使用键空间
要使用创建的键空间,可使用USE命令。
语法:
USE <identifier>
这里,我们使用的是名称为 yiibai_ks 的键空间(keyspace)。如下图所示 -
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra CQLsh下一篇:Cassandra修改键空间
Cassandra修改键空间 - Cassandra教程™
“ALTER keyspace”命令用于更改Cassandra中创建的键空间中的复制因子,策略名称和持久写入属性。
语法:
ALTER KEYSPACE <identifier> WITH <properties>
或者 -
ALTER KEYSPACE "KeySpace Name"
WITH replication = {'class': 'Strategy name', 'replication_factor' : 'No.Of replicas'};
又或者 -
Alter Keyspace KeyspaceName with replication={'class':'StrategyName',
'replication_factor': no of replications on different nodes}
with DURABLE_WRITES=true/false
改变Cassandra中的Keyspace的要点
- Keyspace Name: Cassandra中的键名称不能更改。
- Strategy Name: 可以通过使用新的策略名称来更改战略名称。
- Replication Factor : 可以通过使用新的复制因子来更改复制因子。
- DURABLE_WRITES : DURABLE_WRITES值可以通过指定其值true / false来更改。 默认情况下为true。 如果设置为false,则不会将更新写入提交日志,反之亦然。
实例:
我们来举个例子来说明“更改键空间”。 这将会将KeyCenter策略从“SimpleStrategy”更改为“NetworkTopologyStrategy”,将DataCenter1的复制因子从3更改为1。
ALTER KEYSPACE yiibai_ks
WITH replication = {'class':'NetworkTopologyStrategy', 'replication_factor' : 1};
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra创建键空间(Keyspace)下一篇:Cassandra删除键空间
Cassandra删除键空间 - Cassandra教程™
在Cassandra中,“DROP Keyspace”命令用于从Cassandra中删除所有数据,列族,用户定义的类型和索引的键空间。
Cassandra在删除键空间之前,先获取键空间的快照。 如果Cassandra中不存在keyspace,Cassandra将返回错误,除非使用IF EXISTS关键字。
语法
DROP keyspace KeyspaceName ;
示例:
我们举一个例子来删除名为“yiibai_ks”的键空间(keyspace)。
DROP keyspace yiibai_ks;
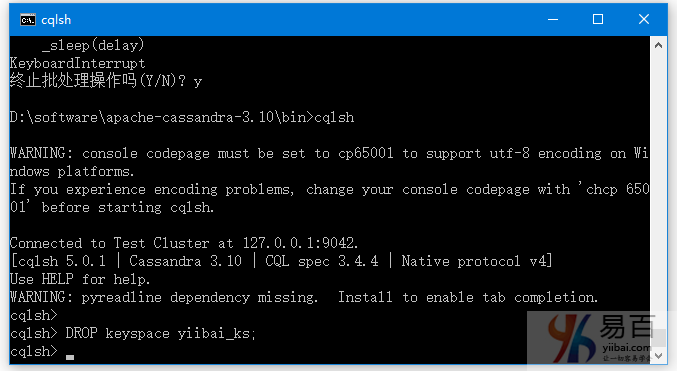
验证:
在执行上述命令后,从Cassandra中删除键空间“yiibai_ks”,其中包含所有数据和模式。
您可以使用“USE”命令验证它。
cqlsh> use yiibai_ks;
InvalidRequest: Error from server: code=2200 [Invalid query] message="Keyspace 'yiibai_ks' does not exist"
cqlsh>
现在可以看到“yiibai_ks”键空间被删除。 如果再次使用“DROP”命令,您将收到以下消息。
cqlsh> DROP keyspace yiibai_ks;
ConfigurationException: Cannot drop non existing keyspace 'yiibai_ks'.
cqlsh>
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra修改键空间下一篇:Cassandra创建表
Cassandra创建表 - Cassandra教程™
在Cassandra中,CREATE TABLE命令用于创建表。 这里,列系列用于存储数据,就像RDBMS中的表一样。
所以,也可以认为CREATE TABLE命令用于在Cassandra中创建一个列族。
语法
CREATE (TABLE | COLUMNFAMILY) <tablename>
('<column-definition>' , '<column-definition>')
(WITH <option> AND <option>)
要么,可声明一个主键:
CREATE TABLE tablename(
column1 name datatype PRIMARYKEY,
column2 name data type,
column3 name data type.
)
您还可以使用以下语法定义主键:
Create table TableName
(
ColumnName DataType,
ColumnName DataType,
ColumnName DataType
.
.
.
Primary key(ColumnName)
) with PropertyName=PropertyValue;
主键有两种类型:
- 单个主键:对单个主键使用以下语法。
Primary key (ColumnName)
- 复合主键:对复合主键可使用以下语法。
Primary key(ColumnName1,ColumnName2 . . .)
示例:
让我们举个例子来演示如何使用CREATE TABLE命令。
在这里,我们使用前面已经创建的键空间 - “yiibai_ks”。并使用以下脚本 -
USE yiibai_ks;
CREATE TABLE student(
student_id int PRIMARY KEY,
student_name text,
student_city text,
student_fees varint,
student_phone varint
);
如下图所示 -
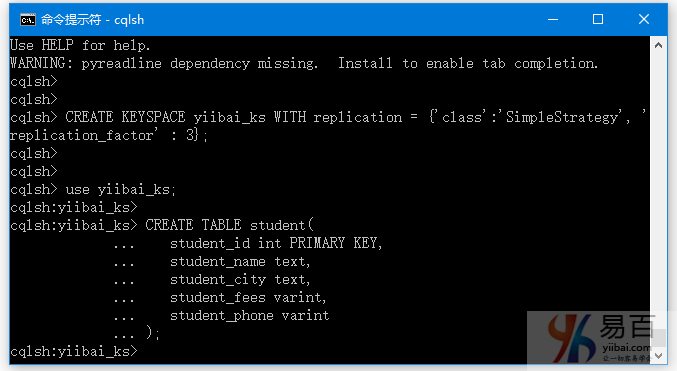
在执行上面语句后,该表现在创建。 您可以使用以下命令检查它。
SELECT * FROM student;
执行结果如下所示 -
cqlsh:yiibai_ks>
cqlsh:yiibai_ks> SELECT * FROM student;
student_id | student_city | student_fees | student_name | student_phone
------------+--------------+--------------+--------------+---------------
(0 rows)
cqlsh:yiibai_ks>
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra删除键空间下一篇:Cassandra修改表
Cassandra修改表 - Cassandra教程™
ALTER TABLE命令用于在创建表后更改表。 您可以使用ALTER命令执行两种操作:
- 添加一列
- 删除一列
语法:
ALTER (TABLE | COLUMNFAMILY) <tablename> <instruction>
添加一列
您可以使用ALTER命令在表中添加一列。 在添加列时,您必须知道列名称与现有列名称不冲突,并且表不使用紧凑存储选项进行定义。
语法:
ALTER TABLE table name
ADD new column datatype;
示例:
现在举个例子来说明在已经创建的名为“student”的表上使用ALTER命令。 这里我们在名为student的表中添加一个名为student_email的文本数据类型列。
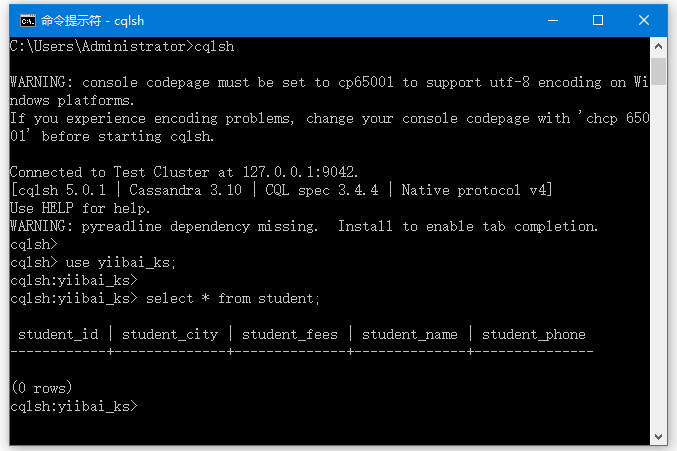
使用以下命令后:
ALTER TABLE student ADD student_email text;
执行上面命令添加一个新列。 您可以使用SELECT命令检查它。
cqlsh> use yiibai_ks;
cqlsh:yiibai_ks>
cqlsh:yiibai_ks> select * from student;
student_id | student_city | student_fees | student_name | student_phone
------------+--------------+--------------+--------------+---------------
(0 rows)
cqlsh:yiibai_ks> ALTER TABLE student ADD student_email text;
cqlsh:yiibai_ks> select * from student;
student_id | student_city | student_email | student_fees | student_name | student_phone
------------+--------------+---------------+--------------+--------------+---------------
(0 rows)
cqlsh:yiibai_ks>
删除一列
您还可以使用ALTER命令从表中删除现有的列。 在从表中删除列之前,应该检查表是否没有使用紧凑存储选项进行定义。
语法:
ALTER table name DROP column name;
示例:
让我们举个例子,从名为student的表中删除一个名为student_email的列。
使用以下命令后:
ALTER TABLE student DROP student_email;
现在,您可以看到student表中名为“student_email”的列现在已被删除。如果要删除多个列,请使用“,”分隔列名。
cqlsh:yiibai_ks> ALTER TABLE student ADD student_email text;
cqlsh:yiibai_ks> select * from student;
student_id | student_city | student_email | student_fees | student_name | student_phone
------------+--------------+---------------+--------------+--------------+---------------
(0 rows)
cqlsh:yiibai_ks> ALTER TABLE student DROP student_email;
cqlsh:yiibai_ks> select * from student;
student_id | student_city | student_fees | student_name | student_phone
------------+--------------+--------------+--------------+---------------
(0 rows)
cqlsh:yiibai_ks>
看这个例子:
这里我们将删除以下两列:student_fees和student_phone。
ALTER TABLE student DROP (student_fees, student_phone);
输出结果如下所示 -
cqlsh:yiibai_ks> ALTER TABLE student DROP student_email;
cqlsh:yiibai_ks> select * from student;
student_id | student_city | student_fees | student_name | student_phone
------------+--------------+--------------+--------------+---------------
(0 rows)
cqlsh:yiibai_ks> ALTER TABLE student DROP (student_fees, student_phone);
cqlsh:yiibai_ks> select * from student;
student_id | student_city | student_name
------------+--------------+--------------
(0 rows)
cqlsh:yiibai_ks>
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra创建表下一篇:Cassandra删除表
Cassandra删除表 - Cassandra教程™
DROP TABLE命令用于删除表。
语法:
DROP TABLE <tablename>
示例:
我们来举个例子来演示如何删除/丢弃一个表。 在这里作为演示将删除 student 表。
cqlsh:yiibai_ks> select * from student;
student_id | student_city | student_name
------------+--------------+--------------
(0 rows)
cqlsh:yiibai_ks>
使用以下命令后:
DROP TABLE student;
现在名为“student”的表。 您可以使用DESCRIBE命令验证表是否被删除。 这里“student”表已被删除; 不会在列系列列表中找到它。
DESCRIBE COLUMNFAMILIES;
输出结果如下 -
cqlsh:yiibai_ks> DROP TABLE student;
cqlsh:yiibai_ks> DESCRIBE COLUMNFAMILIES;
<empty>
cqlsh:yiibai_ks>
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra修改表下一篇:Cassandra截断表
Cassandra截断表 - Cassandra教程™
TRUNCATE命令用于截断表。 如果您截断表,表的所有行将永久删除。
语法:
TRUNCATE <tablename>
示例:
我们有一个名为“student”的表具有以下数据(创建表并插入数据):
cqlsh:yiibai_ks> CREATE TABLE student(
... student_id int PRIMARY KEY,
... student_name text,
... student_fees varint
... );
cqlsh:yiibai_ks>
cqlsh:yiibai_ks> INSERT INTO student (student_id, student_fees, student_name)
... VALUES(1,5000, 'Maxsu');
cqlsh:yiibai_ks> INSERT INTO student (student_id, student_fees, student_name)
... VALUES(2,3000, 'Minsu');
cqlsh:yiibai_ks> INSERT INTO student (student_id, student_fees, student_name)
... VALUES(3, 2000, 'Modlee');
cqlsh:yiibai_ks>
cqlsh:yiibai_ks> select * from student;
student_id | student_fees | student_name
------------+--------------+--------------
1 | 5000 | Maxsu
2 | 3000 | Minsu
3 | 2000 | Modlee
(3 rows)
cqlsh:yiibai_ks>
现在,我们使用TRUNCATE命令:
TRUNCATE student;
现在表已经被截断了,您可以使用SELECT命令验证它。
SELECT * FROM student;
如下图所示 -
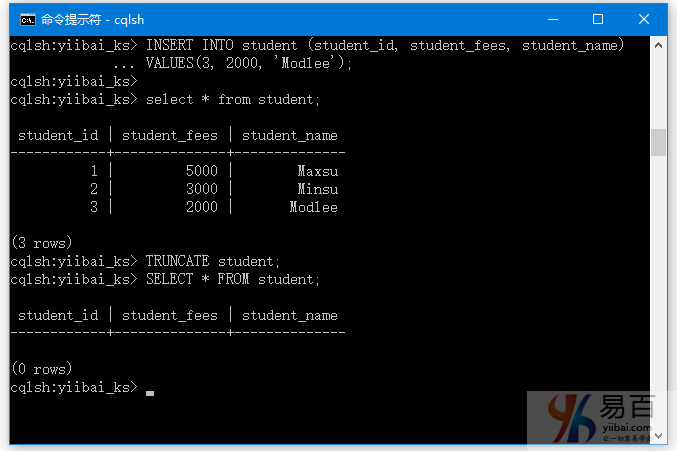
您可以看到表student现在被截断。
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra删除表下一篇:Cassandra创建索引
Cassandra创建索引 - Cassandra教程™
CREATE INDEX命令用于在用户指定的列上创建一个索引。 如果您选择索引的列已存在数据,则Cassandra会在“create index”语句执行后在指定数据列上创建索引。
语法:
CREATE INDEX <identifier> ON <tablename>
创建索引的规则
- 由于主键已编入索引,因此无法在主键上创建索引。
- 在Cassandra中,不支持集合索引。
- 没有对列进行索引,Cassandra无法过滤该列,除非它是主键。
示例:
让我们举个例子来演示如何在列上创建索引。 在这里,我们为表“student”中的“student_name”列创建一个索引。
cqlsh:yiibai_ks> SELECT * FROM student;
student_id | student_fees | student_name
------------+--------------+--------------
(0 rows)
cqlsh:yiibai_ks>
执行以下命令创建一个索引 -
CREATE INDEX name ON student (student_name);
上面语句中,是在“student_name”列上创建了索引。
cqlsh:yiibai_ks> CREATE INDEX name ON student (student_name);
cqlsh:yiibai_ks> describe student;
CREATE TABLE yiibai_ks.student (
student_id int PRIMARY KEY,
student_fees varint,
student_name text
) WITH bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
CREATE INDEX name ON yiibai_ks.student (student_name);
cqlsh:yiibai_ks>
注意:您可以再次使用创建索引查询来验证索引是否已创建。 它将显示已创建索引的消息。
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra截断表下一篇:Cassandra删除索引
Cassandra删除索引 - Cassandra教程™
DROP INDEX命令用于删除指定的索引。 如果索引创建时未指定索引名称,则索引名称为TableName_ColumnName_idx。
语法
DROP INDEX <identifier>
或者 -
Drop index IF EXISTS KeyspaceName.IndexName
删除索引的规则
- 如果索引不存在,它将返回错误,除非您使用IF EXISTS,否则不返回任何操作。
- 在创建索引期间,您必须使用索引名称指定keyspace名称,否则将当前键空间中的索引删除。
示例:
下面举个例子来演示如何删除某列上的索引。 在这里,我们将创建的索引放在表“student”中的“student_name”列中。键空间的名称是“yiibai_ks”。
Drop index IF EXISTS yiibai_ks.student_name_index;
如下语句 -
## 首先创建一个索引: student_name_index
cqlsh:yiibai_ks> CREATE INDEX student_name_index ON student (student_name);
cqlsh:yiibai_ks> describe student;
CREATE TABLE yiibai_ks.student (
student_id int PRIMARY KEY,
student_fees varint,
student_name text
) WITH bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
CREATE INDEX student_name_index ON yiibai_ks.student (student_name);
## 删除索引 = student_name_index
cqlsh:yiibai_ks> Drop index IF EXISTS student_name_index;
cqlsh:yiibai_ks> describe student;
CREATE TABLE yiibai_ks.student (
student_id int PRIMARY KEY,
student_fees varint,
student_name text
) WITH bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
cqlsh:yiibai_ks>
从“student_name”列中删除索引。
注意:通过再次使用DROP索引命令,可以验证索引是否被删除。 它将显示一条消息,索引已经被删除。
cqlsh:yiibai_ks> Drop index student_name_index;
InvalidRequest: Error from server: code=2200 [Invalid query] message="Index 'student_name_index' could not be found in any of the tables of keyspace 'yiibai_ks'"
cqlsh:yiibai_ks>
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra创建索引下一篇:Cassandra批量
Cassandra批量 - Cassandra教程™
在Cassandra中,BATCH用于同时执行多个修改语句(插入,更新,删除)。 当你必须更新一些以及删除一些现有的列是非常有用的。
语法
BEGIN BATCH
<insert-stmt>/ <update-stmt>/ <delete-stmt>
APPLY BATCH
实例:
让我们举个例子来演示BATCH命令。 在这里,我们有一个名为“student”的表,其中包含列(student_id,student_fees,student_name),具有以下数据。
在这个例子中,我们将执行BATCH(插入,更新和删除)操作:
- 插入一个包含以下信息的新行(4,4000,Sumsu)。
- 更新行ID为3的学生的student_fees列的值为8000。
- 删除具有行ID为2的雇员的student_fees值。
完整的语句如下所示 -
## 创建表
CREATE TABLE student(
student_id int PRIMARY KEY,
student_name text,
student_fees varint
);
## 插入数据
INSERT INTO student (student_id, student_fees, student_name)
VALUES(1,5000, 'Maxsu');
INSERT INTO student (student_id, student_fees, student_name)
VALUES(2,3000, 'Minsu');
INSERT INTO student (student_id, student_fees, student_name)
VALUES(3, 2000, 'Modlee');
查询数据结果如下 -
cqlsh:yiibai_ks> select * from student;
student_id | student_fees | student_name
------------+--------------+--------------
1 | 5000 | Maxsu
2 | 3000 | Minsu
3 | 2000 | Modlee
(3 rows)
cqlsh:yiibai_ks>
执行BATCH命令 -
BEGIN BATCH
INSERT INTO student(student_id, student_fees, student_name) values(4, 5500, Sumlee);
UPDATE student SET student_fees=8000 WHERE student_id=3;
DELETE student_fees FROM student WHERE student_id=2;
APPLY BATCH;
现在执行了BATCH命令之后。 您可以使用SELECT命令验证它。
cqlsh:yiibai_ks> BEGIN BATCH
... INSERT INTO student(student_id, student_fees, student_name) values(4, 5500, 'Sumlee');
... UPDATE student SET student_fees=8000 WHERE student_id=3;
... DELETE student_fees FROM student WHERE student_id=2;
... APPLY BATCH;
cqlsh:yiibai_ks> SELECT * FROM student;
student_id | student_fees | student_name
------------+--------------+--------------
1 | 5000 | Maxsu
2 | null | Minsu
4 | 5500 | Sumlee
3 | 8000 | Modlee
(4 rows)
cqlsh:yiibai_ks>
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra删除索引下一篇:Cassandra插入数据
Cassandra插入数据 - Cassandra教程™
INSERT命令用于将数据插入到表的列中。
语法:
INSERT INTO <tablename>
(<column1 name>, <column2 name>....)
VALUES (<value1>, <value2>....)
USING <option>
示例:
在之前的文章中,我们创建一个名为“student”的表,其中包含列(student_id, student_fees, student_name),需要在student表中插入一些数据。
我们来看看向“student”表中插入数据的代码 -
## 创建表
CREATE TABLE student(
student_id int PRIMARY KEY,
student_name text,
student_fees varint
);
## 向表插入数据
INSERT INTO student (student_id, student_fees, student_name)
VALUES(1,5000, 'Maxsu');
INSERT INTO student (student_id, student_fees, student_name)
VALUES(2,3000, 'Minsu');
INSERT INTO student (student_id, student_fees, student_name)
VALUES(3, 2000, 'Modlee');
在执行上面语句插入数据后,可以使用SELECT命令验证是否成功插入了数据。
SELECT * FROM student;
执行结果如下所示 -
cqlsh:yiibai_ks> CREATE TABLE student(
... student_id int PRIMARY KEY,
... student_name text,
... student_fees varint
... );
cqlsh:yiibai_ks>
cqlsh:yiibai_ks> INSERT INTO student (student_id, student_fees, student_name)
... VALUES(1,5000, 'Maxsu');
cqlsh:yiibai_ks> INSERT INTO student (student_id, student_fees, student_name)
... VALUES(2,3000, 'Minsu');
cqlsh:yiibai_ks> INSERT INTO student (student_id, student_fees, student_name)
... VALUES(3, 2000, 'Modlee');
cqlsh:yiibai_ks>
cqlsh:yiibai_ks> SELECT * FROM student;
student_id | student_fees | student_name
------------+--------------+--------------
1 | 5000 | Maxsu
2 | 3000 | Minsu
3 | 2000 | Modlee
(3 rows)
cqlsh:yiibai_ks>
如下图所示 -
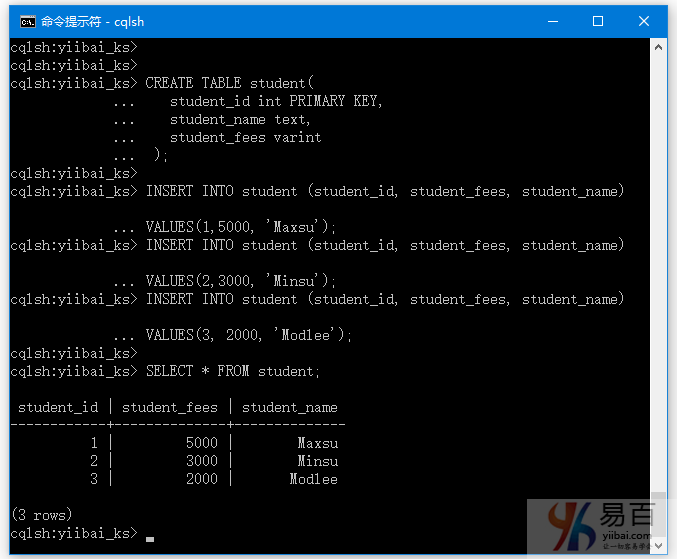
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra批量下一篇:Cassandra读取数据
Cassandra读取数据 - Cassandra教程™
SELECT命令用于从Cassandra表中读取数据。 您可以使用此命令读取整个表,单个列,特定单元格等等。
语法
SELECT FROM <tablename>
示例:
下面举个例子来演示如何从Cassandra表中读取数据。 我们有一个名为“student”的表和以下列(student_id,student_fees,student_name)。
使用SELECT命令读整个表
SELECT * FROM student;
执行结果如下 -
cqlsh:yiibai_ks> SELECT * FROM student;
student_id | student_fees | student_name
------------+--------------+--------------
1 | 5000 | Maxsu
2 | 3000 | Minsu
3 | 2000 | Modlee
(3 rows)
cqlsh:yiibai_ks>
读取特定列 -
该示例将从student表中只读student_id和student_id列的数据。
SELECT student_id, student_name FROM student;
使用WHERE子句
WHERE子句与SELECT命令一起使用,以指定必须满足获取数据的确切条件。
语法:
SELECT FROM <table name> WHERE <condition>;
注意:WHERE子句只能在作为主键的一部分的列,或者在其上具有辅助索引上使用。
如下查询条件语句 -
SELECT * FROM student WHERE student_id=2;
执行结果如下 -
cqlsh:yiibai_ks> SELECT * FROM student WHERE student_id=2;
student_id | student_fees | student_name
------------+--------------+--------------
2 | 3000 | Minsu
(1 rows)
cqlsh:yiibai_ks>
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra插入数据下一篇:Cassandra更新数据
Cassandra更新数据 - Cassandra教程™
UPDATE命令用于更新Cassandra表中的数据。 如果在更新数据后看不到任何结果,则表示数据成功更新,否则将返回错误。 在更新Cassandra表中的数据时,通常使用以下关键字:
- Where:WHERE子句用于选择要更新的行。
- Set:SET子句用于设置值。
- Must:它用于包括构成主键的所有列。
语法:
UPDATE <tablename>
SET <column name> = <new value>
<column name> = <value>....
WHERE <condition>
又或者 -
Update KeyspaceName.TableName
Set ColumnName1=new Column1Value,
ColumnName2=new Column2Value,
ColumnName3=new Column3Value,
.
.
.
Where ColumnName=ColumnValue
注意:使用UPDATE命令并且给定的行可用时,UPDATE会创建一个新行。
示例:
我们举个例子来演示如何更新Cassandra表中的数据。 我们有一个名为“student”的表,其中列(student_id,student_fees,student_name)具有以下数据:
cqlsh:yiibai_ks> SELECT * FROM student;
student_id | student_fees | student_name
------------+--------------+--------------
1 | 5000 | Maxsu
2 | 3000 | Minsu
3 | 2000 | Modlee
(3 rows)
cqlsh:yiibai_ks>
在这里,我们将student_id为2记录的student_fees的值更新为10000,student_name更新为XunWang。
UPDATE student SET student_fees=10000,student_name='XunWang' WHERE student_id=2;
在执行上面语句之后,表已更新。 您可以使用SELECT命令验证它。
SELECT * FROM student;
执行结果如下 -
cqlsh:yiibai_ks> SELECT * FROM student;
student_id | student_fees | student_name
------------+--------------+--------------
1 | 5000 | Maxsu
2 | 3000 | Minsu
3 | 2000 | Modlee
(3 rows)
cqlsh:yiibai_ks> UPDATE student SET student_fees=10000,student_name='XunWang' WHERE student_id=2;
cqlsh:yiibai_ks> SELECT * FROM student;
student_id | student_fees | student_name
------------+--------------+--------------
1 | 5000 | Maxsu
2 | 10000 | XunWang
3 | 2000 | Modlee
(3 rows)
cqlsh:yiibai_ks>
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra读取数据下一篇:Cassandra删除数据记录
Cassandra删除数据记录 - Cassandra教程™
DELETE命令用于从Cassandra表中删除数据。 您可以使用此命令删除完整的表或选定的行。
语法:
DELETE FROM <identifier> WHERE <condition>;
下面举个例子来演示如何从Cassandra表中删除数据。 我们有一个名为“student”的表其中列(student_id,student_fees, student_name),这个表中具有以下数据。
cqlsh:yiibai_ks> SELECT * FROM student;
student_id | student_fees | student_name
------------+--------------+--------------
1 | 5000 | Maxsu
2 | 10000 | XunWang
3 | 2000 | Modlee
(3 rows)
cqlsh:yiibai_ks>
删除整行
要删除student_id为3的整行记录,请使用以下命令:
DELETE FROM student WHERE student_id=3;
在执行上面语句之后,student_id为 3 的行记录已被删除。 您可以使用SELECT命令验证它。
cqlsh:yiibai_ks> SELECT * FROM student;
student_id | student_fees | student_name
------------+--------------+--------------
1 | 5000 | Maxsu
2 | 10000 | XunWang
3 | 2000 | Modlee
(3 rows)
cqlsh:yiibai_ks> DELETE FROM student WHERE student_id=3;
cqlsh:yiibai_ks> SELECT * FROM student;
student_id | student_fees | student_name
------------+--------------+--------------
1 | 5000 | Maxsu
2 | 10000 | XunWang
(2 rows)
cqlsh:yiibai_ks>
删除一个特定的列名
示例:
删除student_id为2的记录中的student_fees列中的值。
DELETE student_fees FROM student WHERE student_id=2;
现在删除 您可以验证:
cqlsh:yiibai_ks> SELECT * FROM student;
student_id | student_fees | student_name
------------+--------------+--------------
1 | 5000 | Maxsu
2 | 10000 | XunWang
(2 rows)
cqlsh:yiibai_ks> DELETE student_fees FROM student WHERE student_id=2;
cqlsh:yiibai_ks> SELECT * FROM student;
student_id | student_fees | student_name
------------+--------------+--------------
1 | 5000 | Maxsu
2 | null | XunWang
(2 rows)
cqlsh:yiibai_ks>
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra更新数据下一篇:Cassandra集合
Cassandra集合 - Cassandra教程™
Cassandra集合用于处理任务。 您可以在集合中存储多个元素。 Cassandra支持三种类型的集合:
- Set
- List
- Map
Set集合
Set集合存储查询时返回排序元素的元素组。
语法:
Create table table_name
(
id int,
Name text,
Email set<text>,
Primary key(id)
);
示例:
下面举个例子来展示Set集合。创建一个具有三列(id, name 和 email)的表“employee”。
use yiibai_ks;
create table employee(
id int,
name text,
email set<text>,
primary key(id)
);
执行上面语句创建表以后如下:
cqlsh:yiibai_ks> create table employee(
... id int,
... name text,
... email set<text>,
... primary key(id)
... );
cqlsh:yiibai_ks> describe employee;
CREATE TABLE yiibai_ks.employee (
id int PRIMARY KEY,
email set<text>,
name text
) WITH bloom_filter_fp_chance = 0.01
AND caching = {'keys': 'ALL', 'rows_per_partition': 'NONE'}
AND comment = ''
AND compaction = {'class': 'org.apache.cassandra.db.compaction.SizeTieredCompactionStrategy', 'max_threshold': '32', 'min_threshold': '4'}
AND compression = {'chunk_length_in_kb': '64', 'class': 'org.apache.cassandra.io.compress.LZ4Compressor'}
AND crc_check_chance = 1.0
AND dclocal_read_repair_chance = 0.1
AND default_time_to_live = 0
AND gc_grace_seconds = 864000
AND max_index_interval = 2048
AND memtable_flush_period_in_ms = 0
AND min_index_interval = 128
AND read_repair_chance = 0.0
AND speculative_retry = '99PERCENTILE';
cqlsh:yiibai_ks>
现在,向上面创建的employee表中插入一些值:
INSERT INTO employee (id, email, name)
VALUES(1, {'yestouu@gmail.com'}, 'yestouu');
INSERT INTO employee (id, email, name)
VALUES(2,{'kanchan@qq.com'}, 'Kanchan');
INSERT INTO employee (id, email, name)
VALUES(3, {'maxsu@126.com'}, 'Maxsu');
执行上面语句结果如下 -
cqlsh:yiibai_ks> INSERT INTO employee (id, email, name)
... VALUES(1, {'yestouu@gmail.com'}, 'yestouu');
cqlsh:yiibai_ks> INSERT INTO employee (id, email, name)
... VALUES(2,{'kanchan@qq.com'}, 'Kanchan');
cqlsh:yiibai_ks> INSERT INTO employee (id, email, name)
... VALUES(3, {'maxsu@126.com'}, 'Maxsu');
cqlsh:yiibai_ks> select * from employee;
id | email | name
----+-----------------------+---------
1 | {'yestouu@gmail.com'} | yestouu
2 | {'kanchan@qq.com'} | Kanchan
3 | {'maxsu@126.com'} | Maxsu
(3 rows)
cqlsh:yiibai_ks>
List集合
当元素的顺序重要时,使用列表(List)集合。我们以扩展上面示例中的employee表并新增一列department为例。
alter table employee add department list<text>;
执行结果如下 -
cqlsh:yiibai_ks> alter table employee add department list<text>;
cqlsh:yiibai_ks> select * from employee;
id | department | email | name
----+------------+-----------------------+---------
1 | null | {'yestouu@gmail.com'} | yestouu
2 | null | {'kanchan@qq.com'} | Kanchan
3 | null | {'maxsu@126.com'} | Maxsu
(3 rows)
cqlsh:yiibai_ks>
现在添加新列(department)。 在新列“department”中插入一些值。
INSERT INTO employee (id, email, name, department) VALUES(4, {'sweetsu@gmail.com'}, 'Sweetsu', ['IT Devopment']);
执行上面语句结果如下 -
cqlsh:yiibai_ks> alter table employee add department list<text>;
cqlsh:yiibai_ks> select * from employee;
id | department | email | name
----+------------+-----------------------+---------
1 | null | {'yestouu@gmail.com'} | yestouu
2 | null | {'kanchan@qq.com'} | Kanchan
3 | null | {'maxsu@126.com'} | Maxsu
(3 rows)
cqlsh:yiibai_ks> INSERT INTO employee (id, email, name, department) VALUES(4, {'sweetsu@gmail.com'}, 'Sweetsu', ['IT Devopment']);
cqlsh:yiibai_ks> select * from employee;
id | department | email | name
----+------------------+-----------------------+---------
1 | null | {'yestouu@gmail.com'} | yestouu
2 | null | {'kanchan@qq.com'} | Kanchan
4 | ['IT Devopment'] | {'sweetsu@gmail.com'} | Sweetsu
3 | null | {'maxsu@126.com'} | Maxsu
(4 rows)
cqlsh:yiibai_ks>
Map集合
Map集合用于存储键值对。它将一件事映射到另一件事。 例如,如果要将必备课程名称来保存课程信息,则可以使用Map集合。
例子:
创建一个名为“course”的表。
create table course(
id int,
prereq map<text, text>,
primary key(id)
);
-- 插入数据
INSERT into course(id,prereq) VALUES(1, {'Programming':'CPP&&Java', 'Network':'Artificail Intelligence'});
现在创建表,在Map集合类型中插入一些数据。
输出:
cqlsh:yiibai_ks> create table course(
... id int,
... prereq map<text, text>,
... primary key(id)
... );
cqlsh:yiibai_ks> INSERT into course(id,prereq) VALUES(1, {'Programming':'CPP&&Java', 'Network':'Artificail Intelligence'});
cqlsh:yiibai_ks> select * from course;
id | prereq
----+--------------------------------------------------------------------
1 | {'Network': 'Artificail Intelligence', 'Programming': 'CPP&&Java'}
(1 rows)
cqlsh:yiibai_ks>
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra删除数据记录下一篇:Cassandra数据类型
Cassandra数据类型 - Cassandra教程™
CQL提供了丰富的内置数据类型,包括集合类型。 除了这些数据类型,用户还可以创建自己的自定义数据类型。 下表提供了CQL中可用的内置数据类型的列表。
数据类型 | 常量 | 说明 |
ascii | strings | 表示ASCII字符串 |
bigint | bigint | 表示64位有符号long类型 |
blob | blobs | 表示任意字节 |
Boolean | booleans | 表示真或假 |
counter | integers | 表示计数器列 |
decimal | integers, floats | 表示可变精度小数 |
double | integers | 表示64位IEEE-754浮点数 |
float | integers, floats | 表示32位IEEE-754浮点数 |
inet | strings | 表示IP地址,IPv4或IPv6 |
int | integers | 表示32位有符号的int类型 |
text | strings | 表示UTF8编码的字符串 |
timestamp | integers, strings | 表示时间戳 |
timeuuid | uuids | 表示1类型UUID |
uuid | uuids | 表示类型1或类型4 |
varchar | strings | 表示UTF8编码的字符串 |
varint | integers | 表示任意精度的整数 |
集合类型
Cassandra查询语言还提供了一个集合数据类型。 下表提供了CQL中可用的集合列表。
集合 | 描述 |
list | 列表(list)是一个或多个有序元素的集合。 |
map | 映射(map)是键值对的集合。 |
set | set是一个或多个元素的集合。 |
用户定义的数据类型:
Cqlsh为用户提供了创建自己的数据类型的功能。 下面给出了处理用户定义的数据类型时使用的命令。
- CREATE TYPE - 创建用户定义的数据类型。
- ALTER TYPE - 修改用户定义的数据类型。
- DROP TYPE - 删除用户定义的数据类型。
- DESCRIBE TYPE - 描述用户定义的数据类型。
- DESCRIBE TYPES - 描述用户定义的数据类型。
本站所有代码下载:请扫描本页面底部(右侧)二维码并关注微信公众号,回复:"代码下载" 获取。
上一篇:Cassandra集合下一篇:哥,这回真没有了
