




执行计划是对一条 SQL 查询语句在数据库中执行过程的描述。用户可以通过 EXPLAIN 命令查看优化器针对指定 SQL 生成的逻辑执行计划。
如果要分析某条 SQL 的性能问题,通常需要先查看 SQL 的执行计划,排查每一步 SQL 执行是否存在问题。所以读懂执行计划是 SQL 优化的先决条件,而了解执行计划的算子是理解 EXPLAIN 命令的关键。
EXPLAIN 命令格式
OceanBase 数据库的执行计划命令有三种模式:EXPLAIN BASIC、EXPLAIN 和 EXPLAIN EXTENDED。这三种模式对执行计划展现不同粒度的细节信息:
EXPLAIN BASIC命令用于最基本的计划展示。EXPLAIN EXTENDED命令用于最详细的计划展示(通常在排查问题时使用这种展示模式)。EXPLAIN命令所展示的信息可以帮助普通用户了解整个计划的执行方式。
EXPLAIN 命令格式如下:
EXPLAIN [BASIC | EXTENDED | PARTITIONS | FORMAT = format_name] [PRETTY | PRETTY_COLOR] explainable_stmt
format_name:
{ TRADITIONAL | JSON }
explainable_stmt:
{ SELECT statement
| DELETE statement
| INSERT statement
| REPLACE statement
| UPDATE statement }
EXPLAIN 命令适用于 SELECT、DELETE、INSERT、REPLACE 和 UPDATE 语句,显示优化器所提供的有关语句执行计划的信息,包括如何处理该语句,如何联接表以及以何种顺序联接表等信息。
一般来说,可以使用 EXPLAIN EXTENDED 命令,将表扫描的范围段展示出来。使用 EXPLAIN OUTLINE 命令可以显示 Outline 信息。
FORMAT 选项可用于选择输出格式。TRADITIONAL 表示以表格格式显示输出,这也是默认设置。JSON 表示以 JSON 格式显示信息。
使用 EXPLAIN PARTITITIONS 也可用于检查涉及分区表的查询。如果检查针对非分区表的查询,则不会产生错误,但 PARTIONS 列的值始终为 NULL。
对于复杂的执行计划,可以使用 PRETTY 或者 PRETTY_COLOR 选项将计划树中的父节点和子节点使用树线或彩色树线连接起来,使得执行计划展示更方便阅读。示例如下:
obclient> CREATE TABLE p1table(c1 INT ,c2 INT) PARTITION BY HASH(c1) PARTITIONS 2;
Query OK, 0 rows affected
obclient> CREATE TABLE p2table(c1 INT ,c2 INT) PARTITION BY HASH(c1) PARTITIONS 4;
Query OK, 0 rows affected
obclient> EXPLAIN EXTENDED PRETTY_COLOR SELECT * FROM p1table p1 JOIN p2table p2 ON p1.c1=p2.c2\G
*************************** 1. row ***************************
Query Plan: Plan signature: 16659768050887532275
==========================================================
|ID|OPERATOR |NAME |EST. ROWS|COST|
----------------------------------------------------------
|0 |PX COORDINATOR | |1 |277 |
|1 | EXCHANGE OUT DISTR |:EX10001|1 |277 |
|2 | HASH JOIN | |1 |275 |
|3 | ├PX PARTITION ITERATOR | |1 |92 |
|4 | │ TABLE SCAN |p1 |1 |92 |
|5 | └EXCHANGE IN DISTR | |1 |184 |
|6 | EXCHANGE OUT DISTR (PKEY)|:EX10000|1 |183 |
|7 | PX PARTITION ITERATOR | |1 |183 |
|8 | TABLE SCAN |p2 |1 |183 |
==========================================================
Outputs & filters:
-------------------------------------
0 - output([INTERNAL_FUNCTION(p1.c1(0x7f16d163ae40), p1.c2(0x7f16d163d2b0), p2.c1(0x7f16d163bd70), p2.c2(0x7f16d163cd50))(0x7f16d16da350)]), filter(nil), rowset=256
1 - output([INTERNAL_FUNCTION(p1.c1(0x7f16d163ae40), p1.c2(0x7f16d163d2b0), p2.c1(0x7f16d163bd70), p2.c2(0x7f16d163cd50))(0x7f16d16da350)]), filter(nil), rowset=256, dop=1
2 - output([p1.c1(0x7f16d163ae40)], [p2.c2(0x7f16d163cd50)], [p1.c2(0x7f16d163d2b0)], [p2.c1(0x7f16d163bd70)]), filter(nil), rowset=256,
equal_conds([p1.c1(0x7f16d163ae40) = p2.c2(0x7f16d163cd50)(0x7f16d163c670)]), other_conds(nil)
3 - output([p1.c1(0x7f16d163ae40)], [p1.c2(0x7f16d163d2b0)]), filter(nil), rowset=256,
affinitize, force partition granule.
4 - output([p1.c1(0x7f16d163ae40)], [p1.c2(0x7f16d163d2b0)]), filter(nil), rowset=256,
access([p1.c1(0x7f16d163ae40)], [p1.c2(0x7f16d163d2b0)]), partitions(p[0-1]),
is_index_back=false,
range_key([p1.__pk_increment(0x7f16d163d7e0)]), range(MIN ; MAX)always true
5 - output([p2.c2(0x7f16d163cd50)], [p2.c1(0x7f16d163bd70)]), filter(nil), rowset=256
6 - (#keys=1, [p2.c2(0x7f16d163cd50)]), output([p2.c2(0x7f16d163cd50)], [p2.c1(0x7f16d163bd70)]), filter(nil), rowset=256, dop=1
7 - output([p2.c1(0x7f16d163bd70)], [p2.c2(0x7f16d163cd50)]), filter(nil), rowset=256,
force partition granule.
8 - output([p2.c1(0x7f16d163bd70)], [p2.c2(0x7f16d163cd50)]), filter(nil), rowset=256,
access([p2.c1(0x7f16d163bd70)], [p2.c2(0x7f16d163cd50)]), partitions(p[0-3]),
is_index_back=false,
range_key([p2.__pk_increment(0x7f16d163dac0)]), range(MIN ; MAX)always true
Used Hint:
-------------------------------------
/*+
*/
Qb name trace:
-------------------------------------
stmt_id:0, stmt_type:T_EXPLAIN
stmt_id:1, SEL$1 > SEL$C6D21C0F
Outline Data:
-------------------------------------
/*+
BEGIN_OUTLINE_DATA
LEADING(@"SEL$C6D21C0F" ("test_aaa"."p1"@"SEL$1" "test_aaa"."p2"@"SEL$1"))
USE_HASH(@"SEL$C6D21C0F" "test_aaa"."p2"@"SEL$1")
PQ_DISTRIBUTE(@"SEL$C6D21C0F" "test_aaa"."p2"@"SEL$1" NONE PARTITION)
FULL(@"SEL$C6D21C0F" "test_aaa"."p1"@"SEL$1")
FULL(@"SEL$C6D21C0F" "test_aaa"."p2"@"SEL$1")
OUTER_TO_INNER(@"SEL$1")
OPTIMIZER_FEATURES_ENABLE('4.0.0.0')
END_OUTLINE_DATA
*/
Plan Type:
-------------------------------------
DISTRIBUTED
Optimization Info:
-------------------------------------
p1:table_rows:1, physical_range_rows:1, logical_range_rows:1, index_back_rows:0, output_rows:1, est_method:default_stat, optimization_method=cost_based, avaiable_index_name[p1table]
p2:table_rows:1, physical_range_rows:1, logical_range_rows:1, index_back_rows:0, output_rows:1, est_method:default_stat, optimization_method=cost_based, avaiable_index_name[p2table]
Parameters:
-------------------------------------
1 row in set (0.01 sec)
执行计划形状与算子信息
在数据库系统中,执行计划在内部通常是以树的形式来表示的,但是不同的数据库会选择不同的方式展示给用户。
如下示例分别为 PostgreSQL 数据库、Oracle 数据库和 OceanBase 数据库对于 TPCDS Q3 的计划展示。
obclient> SELECT /*TPC-DS Q3*/ *
FROM (SELECT dt.d_year,
item.i_brand_id brand_id,
item.i_brand brand,
Sum(ss_net_profit) sum_agg
FROM date_dim dt,
store_sales,
item
WHERE dt.d_date_sk = store_sales.ss_sold_date_sk
AND store_sales.ss_item_sk = item.i_item_sk
AND item.i_manufact_id = 914
AND dt.d_moy = 11
GROUP BY dt.d_year,
item.i_brand,
item.i_brand_id
ORDER BY dt.d_year,
sum_agg DESC,
brand_id)
WHERE ROWNUM <= 100;
PostgreSQL 数据库执行计划展示如下:
Limit (cost=13986.86..13987.20 rows=27 width=91) Sort (cost=13986.86..13986.93 rows=27 width=65) Sort Key: dt.d_year, (sum(store_sales.ss_net_profit)), item.i_brand_id HashAggregate (cost=13985.95..13986.22 rows=27 width=65) Merge Join (cost=13884.21..13983.91 rows=204 width=65) Merge Cond: (dt.d_date_sk = store_sales.ss_sold_date_sk) Index Scan using date_dim_pkey on date_dim dt (cost=0.00..3494.62 rows=6080 width=8) Filter: (d_moy = 11) Sort (cost=12170.87..12177.27 rows=2560 width=65) Sort Key: store_sales.ss_sold_date_sk Nested Loop (cost=6.02..12025.94 rows=2560 width=65) Seq Scan on item (cost=0.00..1455.00 rows=16 width=59) Filter: (i_manufact_id = 914) Bitmap Heap Scan on store_sales (cost=6.02..658.94 rows=174 width=14) Recheck Cond: (ss_item_sk = item.i_item_sk) Bitmap Index Scan on store_sales_pkey (cost=0.00..5.97 rows=174 width=0) Index Cond: (ss_item_sk = item.i_item_sk)Oracle 数据库执行计划展示如下:
Plan hash value: 2331821367 -------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | -------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 100 | 9100 | 3688 (1)| 00:00:01 | |* 1 | COUNT STOPKEY | | | | | | | 2 | VIEW | | 2736 | 243K| 3688 (1)| 00:00:01 | |* 3 | SORT ORDER BY STOPKEY | | 2736 | 256K| 3688 (1)| 00:00:01 | | 4 | HASH GROUP BY | | 2736 | 256K| 3688 (1)| 00:00:01 | |* 5 | HASH JOIN | | 2736 | 256K| 3686 (1)| 00:00:01 | |* 6 | TABLE ACCESS FULL | DATE_DIM | 6087 | 79131 | 376 (1)| 00:00:01 | | 7 | NESTED LOOPS | | 2865 | 232K| 3310 (1)| 00:00:01 | | 8 | NESTED LOOPS | | 2865 | 232K| 3310 (1)| 00:00:01 | |* 9 | TABLE ACCESS FULL | ITEM | 18 | 1188 | 375 (0)| 00:00:01 | |* 10 | INDEX RANGE SCAN | SYS_C0010069 | 159 | | 2 (0)| 00:00:01 | | 11 | TABLE ACCESS BY INDEX ROWID| STORE_SALES | 159 | 2703 | 163 (0)| 00:00:01 | --------------------------------------------------------------------------------------------------OceanBase 数据库执行计划展示如下:
|ID|OPERATOR |NAME |EST. ROWS|COST | ------------------------------------------------------- |0 |LIMIT | |100 |81141| |1 | TOP-N SORT | |100 |81127| |2 | HASH GROUP BY | |2924 |68551| |3 | HASH JOIN | |2924 |65004| |4 | SUBPLAN SCAN |VIEW1 |2953 |19070| |5 | HASH GROUP BY | |2953 |18662| |6 | NESTED-LOOP JOIN| |2953 |15080| |7 | TABLE SCAN |ITEM |19 |11841| |8 | TABLE SCAN |STORE_SALES|161 |73 | |9 | TABLE SCAN |DT |6088 |29401| =======================================================
由示例可见,OceanBase 数据库的计划展示与 Oracle 数据库类似。
OceanBase 数据库执行计划中的各列的含义如下:
| 列名 | 含义 |
|---|---|
ID | 执行树按照前序遍历的方式得到的编号(从 0 开始)。 |
OPERATOR | 操作算子的名称。 |
NAME | 对应表操作的表名(索引名)。 |
EST. ROWS | 估算该操作算子的输出行数。 |
COST | 该操作算子的执行代价(微秒)。 |
说明
在表操作中,
NAME字段会显示该操作涉及的表的名称(别名),如果是使用索引访问,还会在名称后的括号中展示该索引的名称, 例如t1(t1_c2)表示使用了t1_c2索引。如果扫描的顺序是逆序,还会在后面使用RESERVE关键字标识,例如t1(t1_c2,RESERVE)。
OceanBase 数据库 EXPLAIN 命令输出的第一部分是执行计划的树形结构展示。其中每一个操作在树中的层次通过其在 operator 中的缩进予以展示,层次最深的优先执行,层次相同的以特定算子的执行顺序为标准来执行。
上述 TPCDS Q3 示例的计划展示树如下: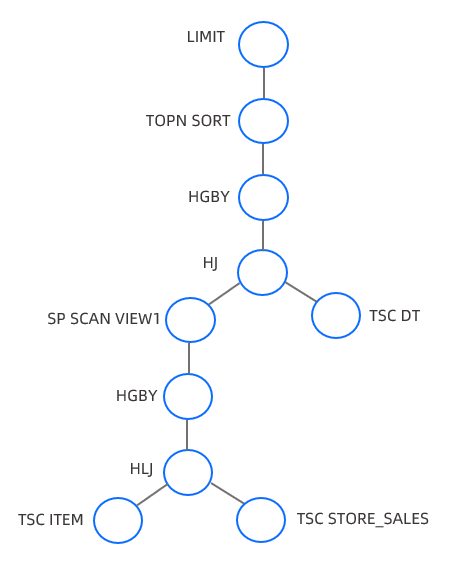
OceanBase 数据库 EXPLAIN 命令输出的第二部分是各操作算子的详细信息,包括输出表达式、过滤条件、分区信息以及各算子的独有信息(包括排序键、联接键、下压条件等)。示例如下:
Outputs & filters:
-------------------------------------
0 - output([t1.c1], [t1.c2], [t2.c1], [t2.c2]), filter(nil), sort_keys([t1.c1, ASC], [t1.c2, ASC]), prefix_pos(1)
1 - output([t1.c1], [t1.c2], [t2.c1], [t2.c2]), filter(nil),
equal_conds([t1.c1 = t2.c2]), other_conds(nil)
2 - output([t2.c1], [t2.c2]), filter(nil), sort_keys([t2.c2, ASC])
3 - output([t2.c2], [t2.c1]), filter(nil),
access([t2.c2], [t2.c1]), partitions(p0)
4 - output([t1.c1], [t1.c2]), filter(nil),
access([t1.c1], [t1.c2]), partitions(p0)