




1、背景
PostgreSQL中扫描的方式有:
- Sequence Scan:顺序扫描(全表扫描)。按顺序扫描所有页面
- Index Scan:根据索引列创建的索引进行扫描,速度快
- Index only Scan:SELECT 表的目标列都在索引键中,为了减少 I/O,仅索引扫描会直接使用索引中的键值
索引扫描在读取表的非索引键的数据时,按照以下顺序:从索引页面获取TID->从heap中取数据->从索引页面获取TID->从heap中取数据 …,索引列是有序的,但不能保证是按照存储的块位置排序,这就有可能导致随机页面访问,从而造成随机I/O。
PostgreSQL设计了Bitmap index Scan(位图索引扫描),大致思路是:首先根据索引查找,将取出所有符合条件的block id在内存中进行排序,一次性的顺序的读取page。这样既使用了索引查找快捷的特点,又避免了随机I/O。
2、原理
在观察执行计划的时候。如果使用的是位图索引扫描,我们通常会发现Bitmap Index Scan嵌套在内层,Bitmap Heap Scan在外层,如下:
在PostgreSQL中,位图扫描分为两个阶段:
- Bitmap Index Scan 第一阶段:执行 index scan并创建位图。根据where条件的索引列,在索引中找出符合条件的行所在的page,并在内存中进行排序并创建bitmap。当找到与搜索条件匹配的索引条目时,将该位设置为 1(true),否则设置为0(false)
- Bitmap Heap Scan 第二阶段:按照第一阶段创建的位图,从左到右顺序的读取标记为1的heap page,0的跳过
写在前面:
查了很多资料都说位图扫描读取的是block。看到一个视频,提到bitmap scan有两种level:row和block。下面是按照此视频思路进行分析:
(视频指路👉:https://www.youtube.com/watch?v=UXKYAZOWDgk&list=PL1XF9qjV8kH0ghGRGo3_f-FWqWvAbv1dh&index=39)
1)Row - Level
- 前提:work_mem足够大
- 步骤:根据匹配索引的row id构建位图,在顺序读取位图时,获取到匹配的行
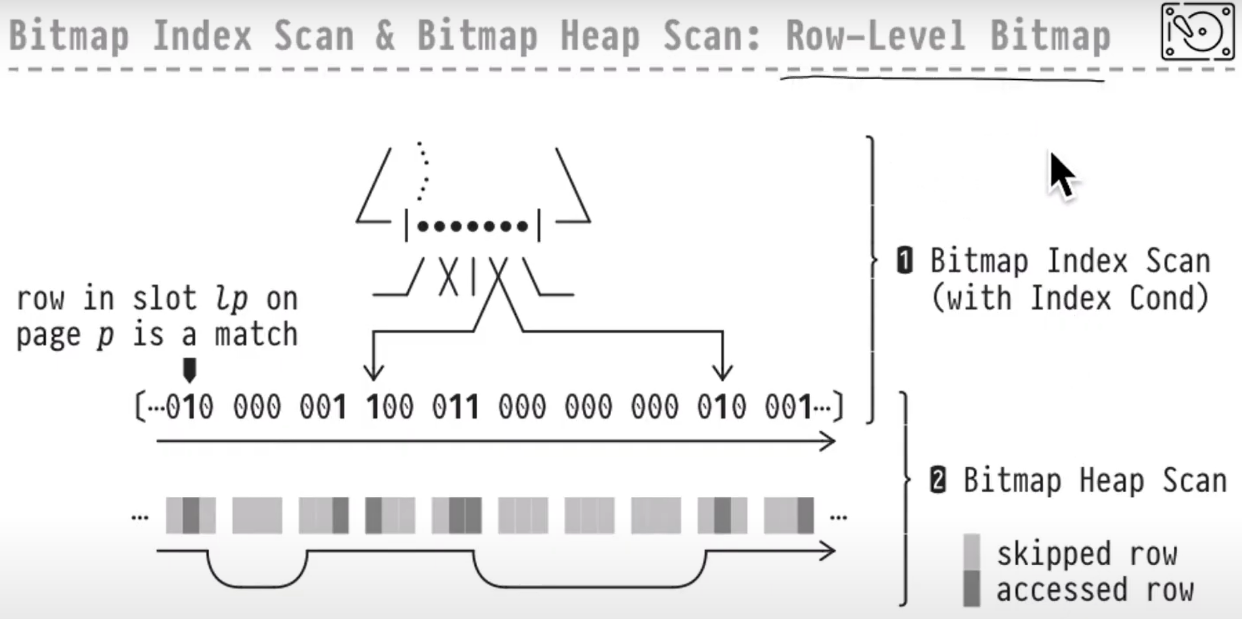
2)Page - Level
- 前提:work_mem不足以放下所有行
- 思路:取得符合条件的所有行号, 获得对应的block id,将block id在内存中排序并构建位图。根据位图顺序从heap 表搜索数据
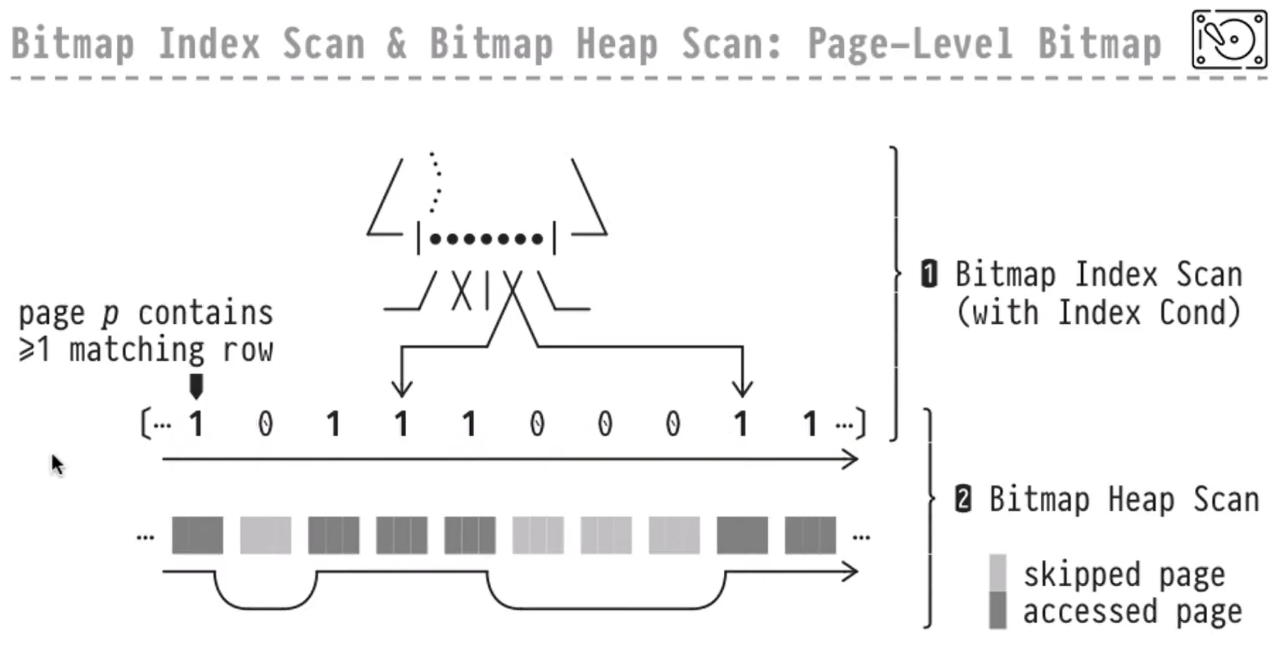
⚠️注意:由于构建的是block的位图,在扫描heap page时,需要进行recheck操作,从堆表页面中筛选出符合条件的row
3、案例
构造测试数据
maleah_db=# create table bms_test(a int,b int,c text) ;
CREATE TABLE
maleah_db=# insert into bms_test select i,ceil(random()*50),'test_'||i from generate_series(1,1000000) i;
INSERT 0 1000000
maleah_db=# create index idx_bms_a on bms_test(a) ;
CREATE INDEX
maleah_db=# create index idx_bms_b on bms_test(b) ;
CREATE INDEX
maleah_db=# create index idx_bms_c on bms_test(c) ;
analyzeCREATE INDEX
maleah_db=# analyze ;
ANALYZE
1)Row - Level
设置 work_mem = 64MB
-
Bitmap Index Scan阶段根据
b = 44进行索引扫描,并构建位图 -
Bitmap Heap Scan阶段根据构建的位图进行顺序读取,有6125个block
如果是Row -Level的位图扫描,Recheck阶段可以省去
maleah_db=# set work_mem = '64MB';
SET
maleah_db=# explain (analyze) select * from bms_test where b = 44 ;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on bms_test (cost=222.13..6840.04 rows=19833 width=19) (actual time=1.592..9.852 rows=20039 loops=1)
Recheck Cond: (b = 44)
Heap Blocks: exact=6125
-> Bitmap Index Scan on idx_bms_b (cost=0.00..217.17 rows=19833 width=0) (actual time=0.898..0.898 rows=20039 loops=1)
Index Cond: (b = 44)
Planning Time: 0.091 ms
Execution Time: 10.485 ms
(7 rows)
2)Page - Level
将work_mem设置值较小
- Bitmap Index Scan阶段根据
b = 44进行索引扫描并构建位图(这里work_mem不足以放下构建的位图) - Bitmap Heap Scan阶段根据构建的位图进行顺序读取。
有 972 个block是精准的记录匹配的元组,而由于work_mem太小,有5153个block标记成"lossy",只记录哪些页面包含匹配的元组,而不是单独记住每个元组。在执行recheck阶段后,必须检查页面上的每个元组并重新检查扫描条件以
查看要返回哪些元组,可以看到Rows Removed by Index Recheck:792131,
maleah_db=# set work_mem = '64KB';
SET
maleah_db=# explain (analyze) select * from bms_test where b = 44 ;
QUERY PLAN
----------------------------------------------------------------------------------------------------------------------------
Bitmap Heap Scan on bms_test (cost=222.13..18107.34 rows=19833 width=19) (actual time=0.925..50.501 rows=20039 loops=1)
Recheck Cond: (b = 44)
Rows Removed by Index Recheck: 792131
Heap Blocks: exact=972 lossy=5153
-> Bitmap Index Scan on idx_bms_b (cost=0.00..217.17 rows=19833 width=0) (actual time=0.808..0.809 rows=20039 loops=1)
Index Cond: (b = 44)
Planning Time: 0.087 ms
Execution Time: 51.193 ms
(8 rows)
4、小结
- bitmap scan目的是通过建立位图的方式,避免index scan带来的随机I/O,从而减少查询过程中的I/O消耗
- Bitmap index Scan是在内存中完成,借助B-Tree索引实现,不占用空间,随用随构建,用完即删。
- Bitmap Index Scan阶段是要从index中得到满足条件的tuple的heap block id。并给block id排序,构建位图;然后进入Bitmap Heap Scan阶段按照构建的位图顺序扫描heap page。
- 位图会记录row id(row - level),但如果bitmap太大,会将位图转换成“lossy”样式(page - level):只记录block id,所以需要recheck,读取heap page时需重新检查扫描条件找出匹配的元组
- 在数据量比较大的情况下,走bitmap scan虽然可以减少I/O代价,但不能忽视recheck阶段所带来的损耗
参考
https://dba.stackexchange.com/questions/119386/understanding-bitmap-heap-scan-and-bitmap-index-scan
https://www.postgresql.org/message-id/12553.1135634231@sss.pgh.pa.us
