




点击蓝字 关注我们


数据源多:已知的数据库、湖、仓等数据源类型非常多,包括一些 saas 网站、软件等,总数量甚至到达几百种,伴随着新技术的出现,这个数字还在不断上涨;不同数据源之间也容易出现版本不兼容的情况,为数据集成平台造成了一些困难; 质量难以保证,监控缺失:最常出现的问题是数据的丢失和重复,很难保证数据的一致性;另一方面,在数据同步过程中出现问题无法进行回滚或者断点执行;同步过程中的监控缺失也会带来信息的不透明,例如不确定已经同步的数据数量等; 资源使用高:对于 CDC 的同步来说,多个表需要同步时,频繁读取 binlog 对数据源造成的压力较大;数据源侧一些大事务或者 Schema 变更等都会影响下游;JDBC 这类同步,当连接数过多时,有时无法保证数据及时到达; 管理维护难:很多企业离线同步和实时同步是分开的,甚至需要写两套代码,不仅日常管理运维非常困难,在进行离线和实时切换时,数据割接甚至需要人工进行; 技术栈复杂:企业的技术栈差异非常大,选择同步组件时学习成本较高。


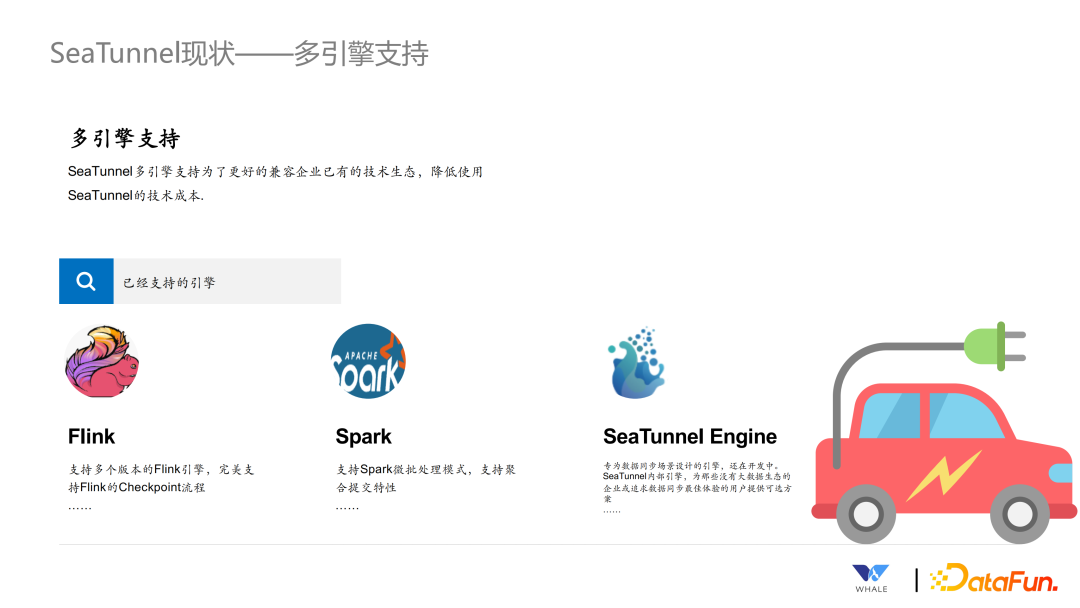
Flink:支持多个版本的 Flink 引擎,并支持 Flink 的分布式快照算法等。 Spark:支持 Spark 的微批处理模式,并能像 Flink 一样保存 checkpoint,以支持断点续传和失败会滚。 SeaTunnel Engine:为数据同步设计的专用引擎,主要用于企业环境中没有 Flink 和 Spark 的引擎情况下,想要简单使用 SeaTunnel 同步数据的场景。SeaTunnel Engine 解决了 Flink 和 Spark 等计算引擎中出现的一些问题,例如容错粒度大,JDBC 连接过多,binlog 重复读取等。
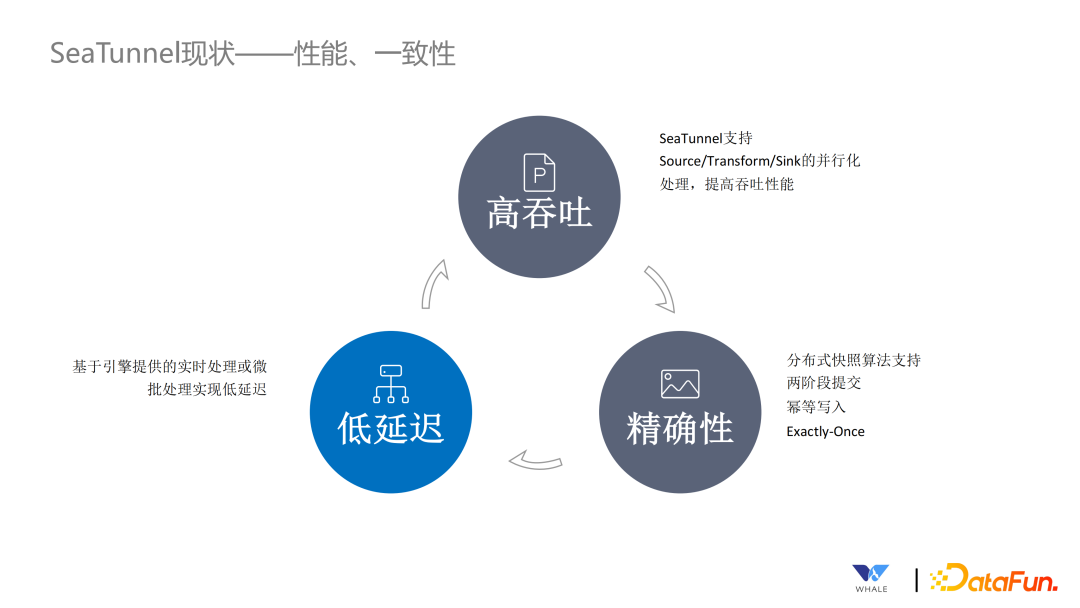
高吞吐:当前 SeaTunnel 所有的连接器都做了并行化处理,从而提高整个数据同步的吞吐量。 精确性:SeaTunnel 支持分布式快照的算法,在连接器内部实现了两阶段提交和幂等写入,保证数据只会处理一次。 低延迟:借助实时处理和微批处理的特性,实现数据低延迟。
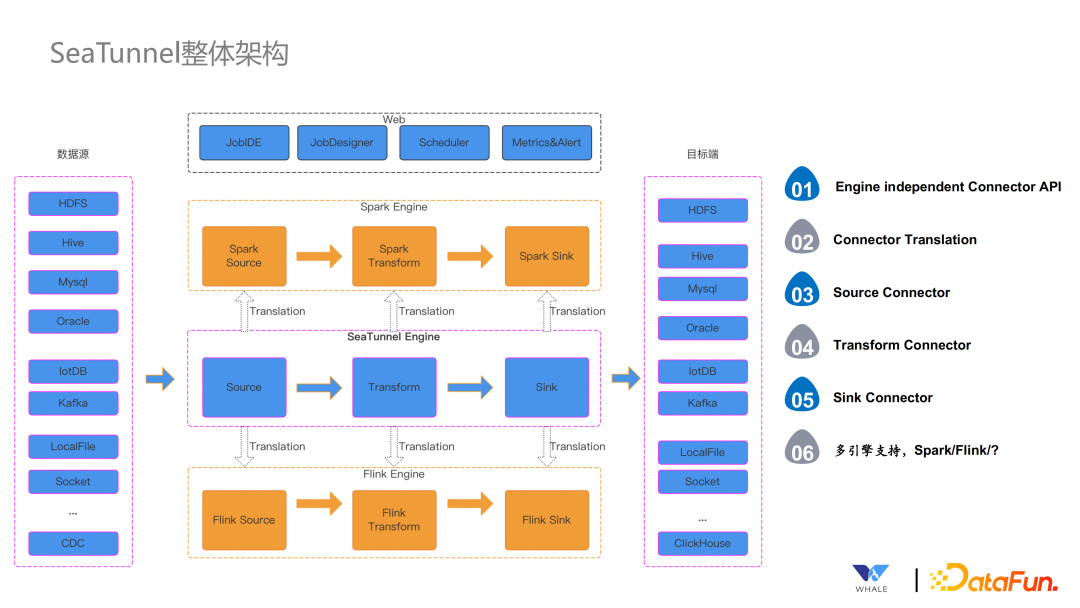
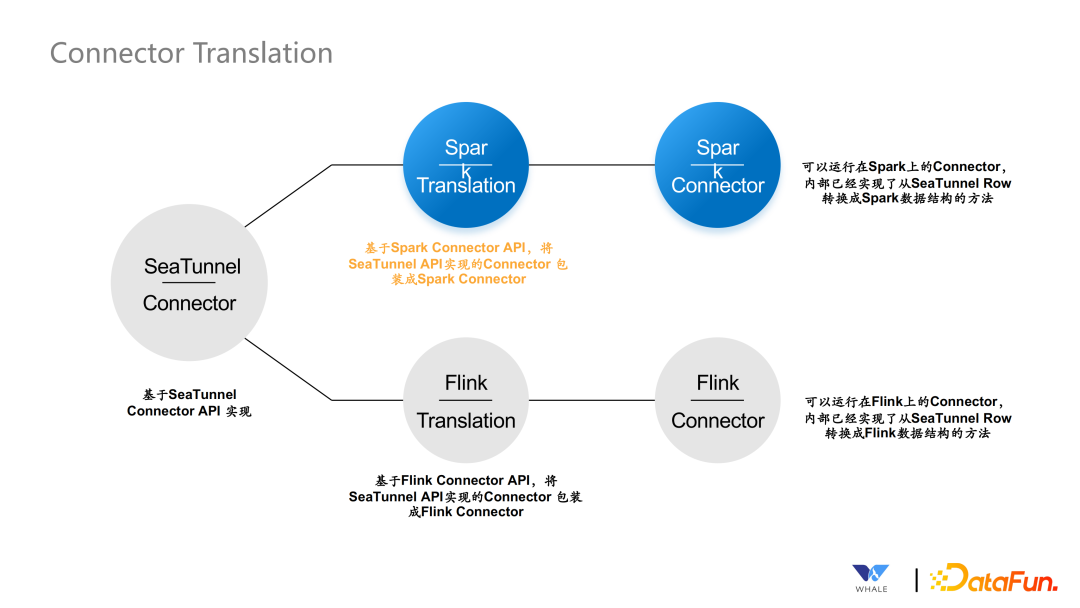
Engine Independent Connector API:独立的连接器 API Connector Translation:连接器翻译层 Source Connector:Source 连接器 Transform Connector:Transform 连接器 Sink Connector:Sink 连接器 多引擎支持

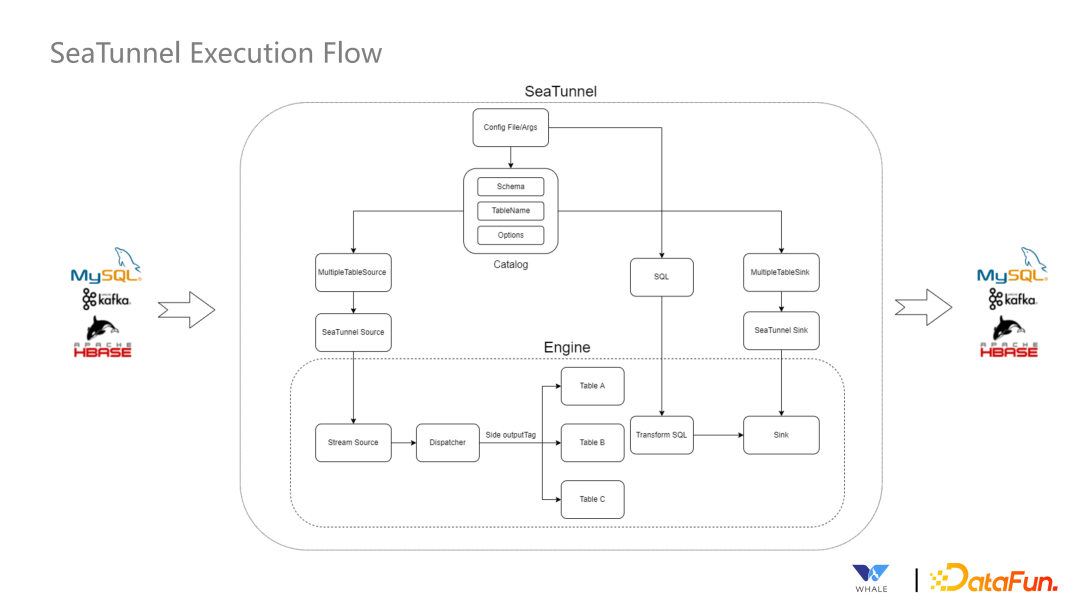
首先会针对来源引擎不同的 Source Connector 进行翻译,翻译后由 Source Connector 开始读取数据。 接下来由 Transform Connector 进行数据的标准化 最终通过 Sink Connector 进行写出操作。
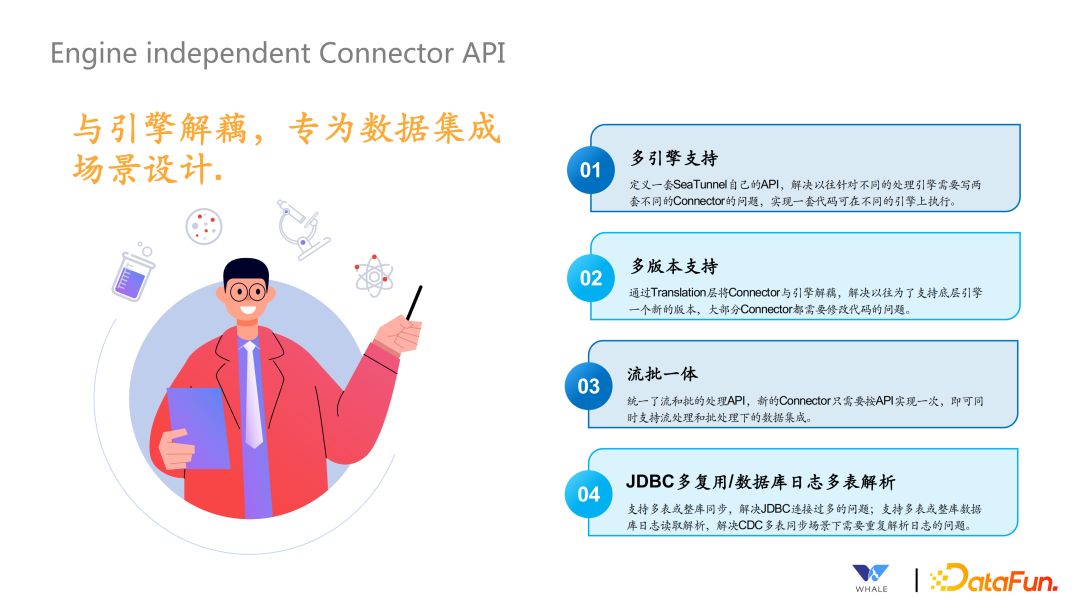
多引擎支持:定义一套 SeaTunnel 自己的 API,解耦底层计算引擎 多版本支持:因为 Connector 和不同引擎的 Connector 之间设计了 Transform 层,就可以解决引擎多版本问题,Transform 可以针对不同的版本进行翻译。 流批一体:同样的一套代码,支持在批处理的场景下使用,也支持在流处理的场景下使用。 JDBC 复用/数据库日志多表解析:解决 JDBC 连接过多的情况,尽可能通过一个连接同步多张表的数据。同理,对于一个库下的表,尽可能也只同步一次,多个表独立解析即可。
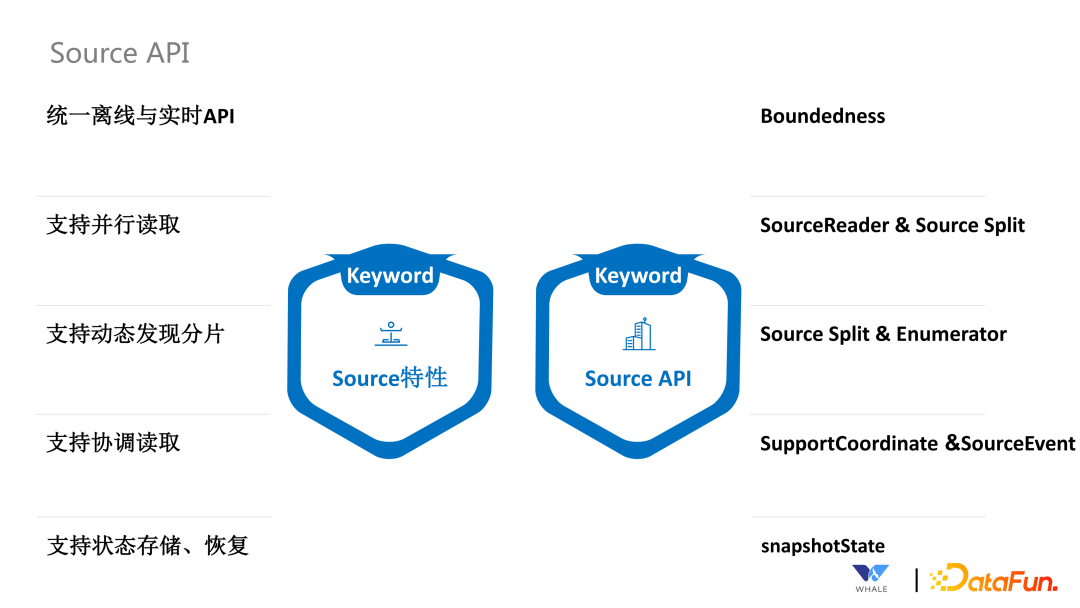
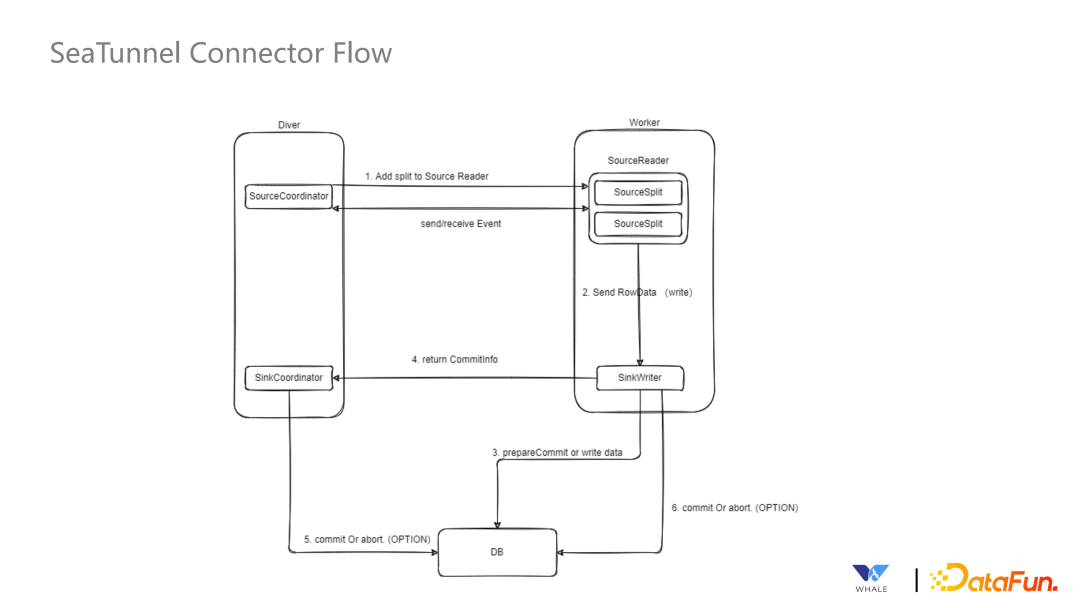
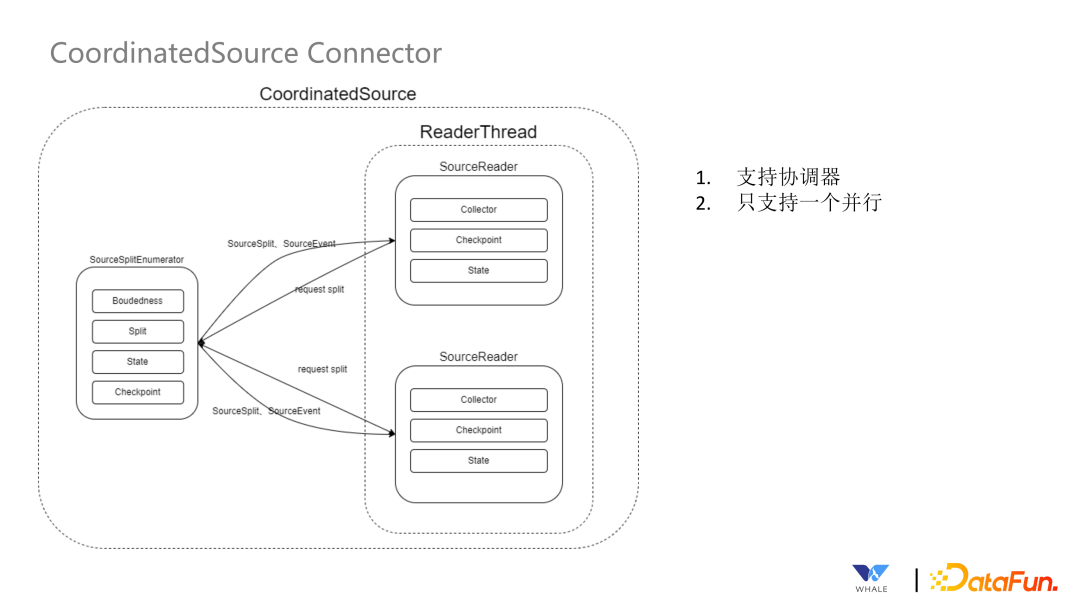
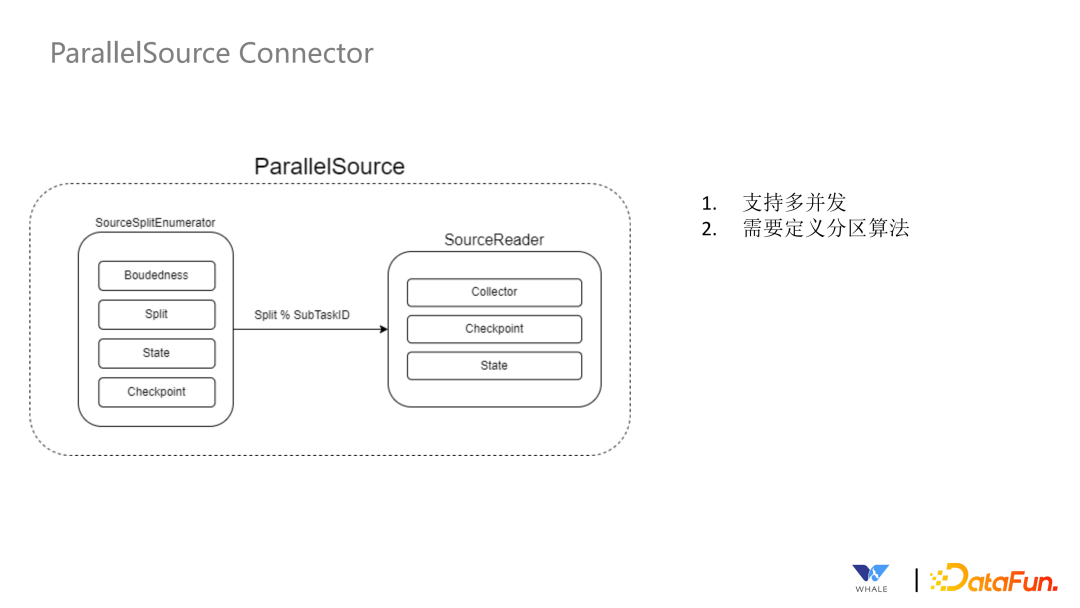
通过 Boundedness 接口,实现批流统一。 通过 SourceReader 和 SourceSplit 支持并行读取。 通过 SourceSplit 和 Enumerator 支持动态发现分片。这个在流处理中更为常见,需要及时发现新增的文件分片;还有一种场景是通过正则表达式匹配 Topic,当新的可以匹配上的 Topic 出现的时候,可以自动读取。 通过 SupportCoordinate 和 SourceEvent 支持协调读取。这个主要用于 CDC 同步场景,在初次同步数据时,需要以批处理的方式全量同步数据,同步完成后主动切换成流处理的方式同步增量数据。 通过 SnapshotState 支持状态存储和恢复。当前针对 Flink 引擎是直接使用 Flink 自带的 Snapshot 功能,对于Spark引擎,SesTunnel 定制实现了 Snapshot 保存到 HDFS 的功能。
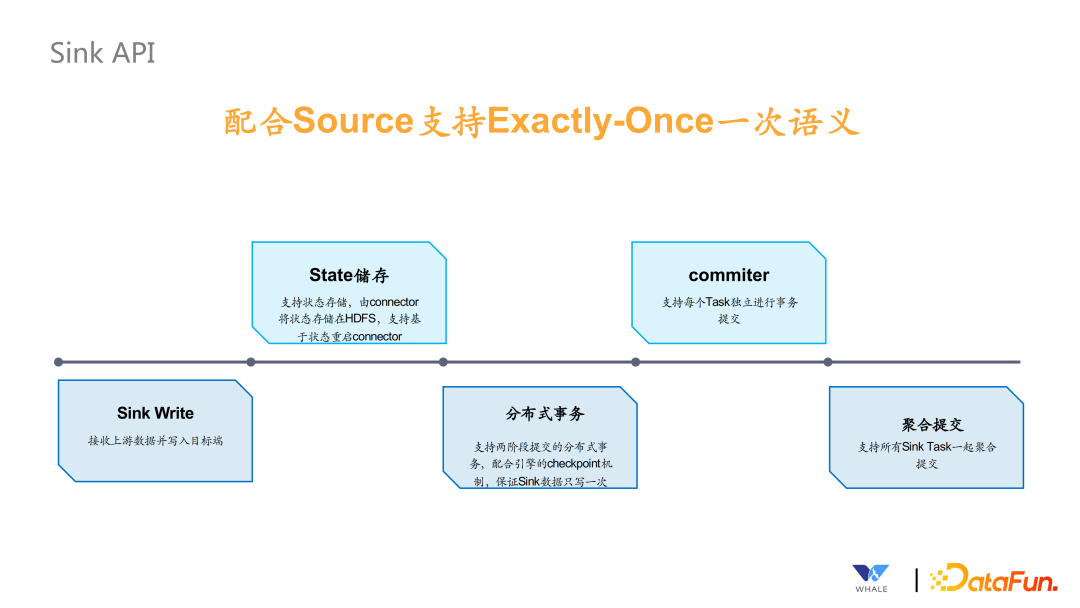
Sink Writer,接收上游数据并写入目标端。 State 存储,支持状态存储,由 Connector 将状态存储在 HDFS 中,支持基于状态重启 Connector。 支持分布式事务,支持两阶段提交的分布式事务,配合引擎的 checkpoint 机制,保证 Sink 数据只写一次。 Commiter,支持每个 Task 独立进行事务的提交,主要依赖 Flink 提供的这样的功能。 支持聚合提交,主要用于 Spark 场景下,checkpoint 状态保存,需要使用到。
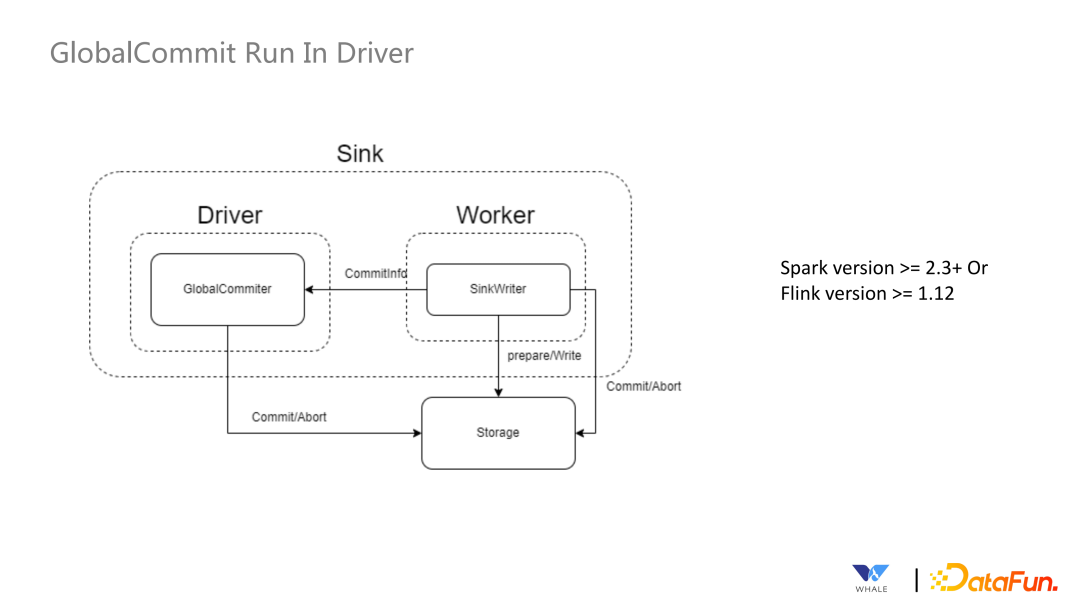
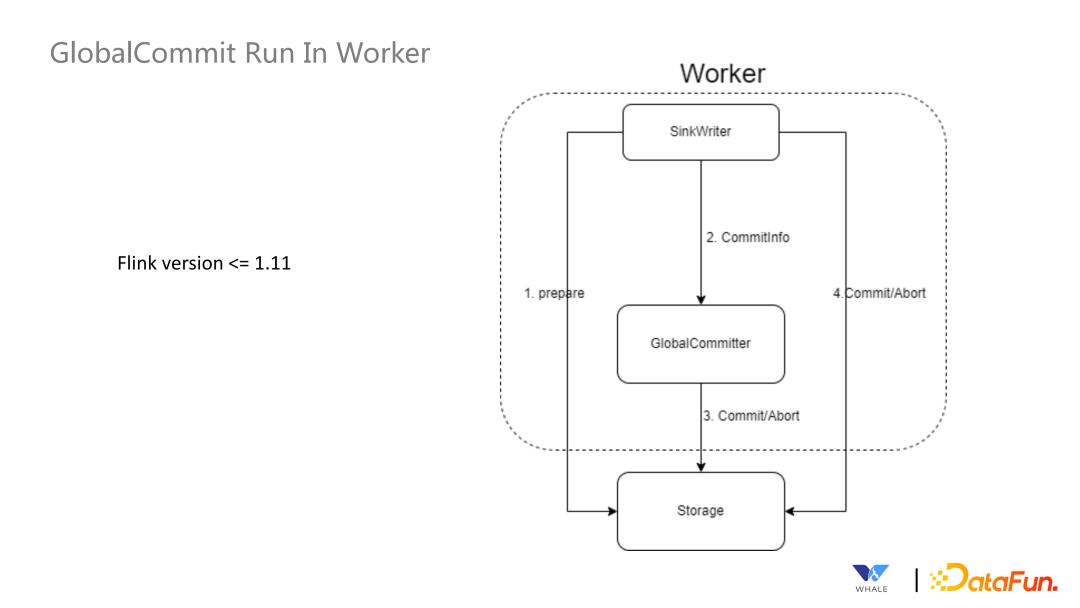
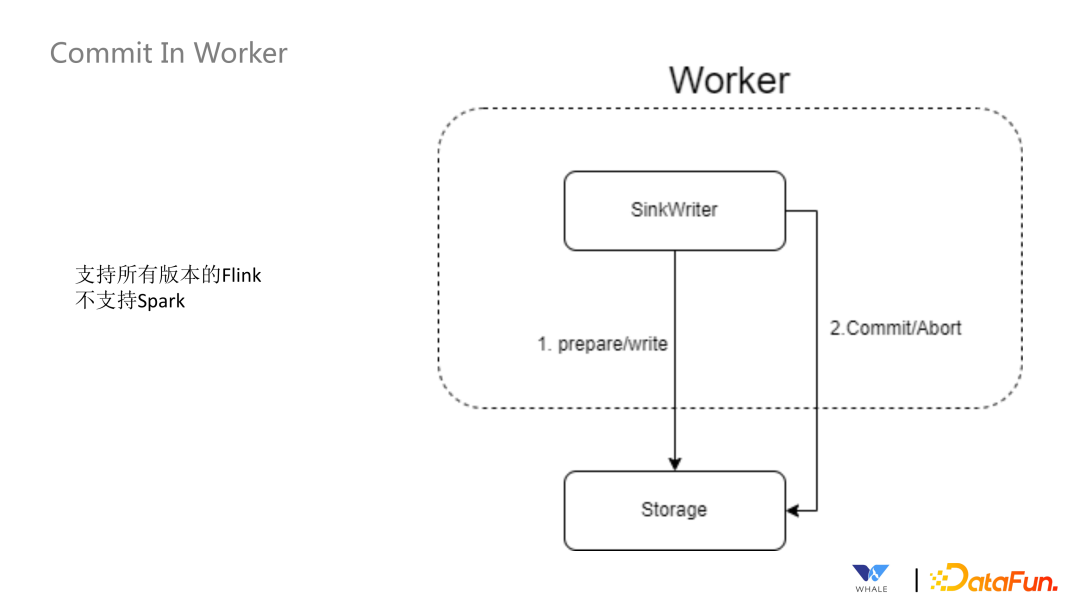

数据源管理:SeaTunnel 定义了一套 API 来支持创建数据源插件,基于 SPI 实现后即可集成该数据源的配置、连接测试工作等。 元数据获取:主要用于引导式界面,选择数据源后,支持自动获取元数据的表结构,方便可视化的配置同步作业的源和目标端的表名映射,字段映射等。 数据类型定义:所有连接器都使用 SeaTunnel 定义的格式,在 Connector Translation 会转换为对应引擎的格式。 连接器创建:SeaTunnel 提供了一套 API 用于创建自动获取信息创建 Source、Sink 等实例。

连接器数量翻倍,总共能支持 80+ 连接器。 发布 SeaTunnel Web,支持可视化作业管理,支持编程式和引导式的作业配置,支持内部调度(处理简单任务,crontab 为主)和第三方调度(以 dolphin scheduler 为主)。 发布 SeaTunnel Engine,支持通过减少 JDBC 的连接和 binlog 的重复读取以达到更省资源的效果;通过拆分任务为 pipeline,pipeline 之间的报错不会相互影响,也支持独立重启操作;借助共享线程以及底层的处理,推动整体同步任务更快的完成;过程中加入监控指标,监控同步任务运行中 Connector 的运行状态,包括数据量和数据质量。


Apache SeaTunnel

往期推荐
分享、点赞、在看,给个3连击呗!

文章转载自SeaTunnel,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
