




示例:创建表 Y,设置两个普通索引, 创建一个存储过程用于插入数据。
-- MySQL版本:mysql> select version();+------------+| version() |+------------+| 5.7.28-log |+------------+1 row in set (0.00 sec)-- 隔离级别: RRmysql> set global transaction_isolation='REPEATABLE-READ' ;Query OK, 0 rows affected (0.00 sec)mysql> show global variables like '%isolation%';+-----------------------+-----------------+| Variable_name | Value |+-----------------------+-----------------+| transaction_isolation | REPEATABLE-READ || tx_isolation | REPEATABLE-READ |+-----------------------+-----------------+2 rows in set (0.00 sec)CREATE TABLE `Y` (`id` int(11) NOT NULL AUTO_INCREMENT,`a` int(11) DEFAULT NULL,`b` int(11) DEFAULT NULL,PRIMARY KEY (`id`),KEY `a` (`a`),KEY `b` (`b`)) ENGINE=InnoDB;delimiter ;;create procedure idata()begindeclare i int;set i=1;while(i<=100000)doinsert into Y (`a`,`b`) values(i, i);set i=i+1;end while;end;;delimiter ;call idata();
执行如下事务:Session A:start transaction with consistent snapshot;Session B:delete from t;Session B:call idata();Session B:explain select * from Y where a between 10000 and 20000;Session B:explain select * from Y force index(a) where a between 10000 and 20000;Session A:commit;
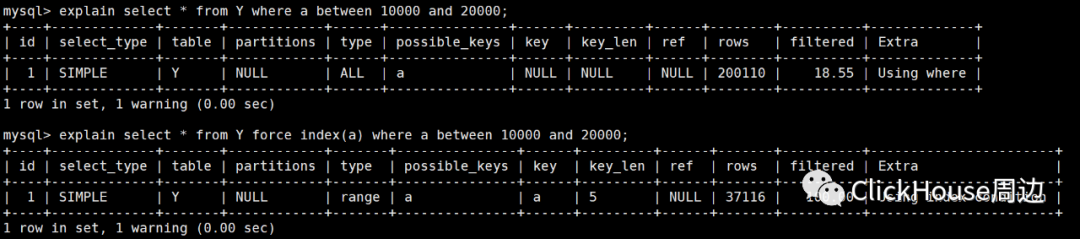
table :此次查询访问的表(单表无所谓,多表连接查询需要关注)type :索引查询的类型(ALL、index、range范围、ref等值、eq_ref、const(system)、NULL)possible_keys :可能会应用的索引key : 最终选择的索引key_len :索引覆盖长度,主要是用来判断联合索引应用长度。rows :此次查询需要扫描的行数(预估值)Extra :额外信息
explain select * from Y where a between 10000 and 20000;
可以发现,在 Session B 的场景下,执行器却没有选择 a 所在的索引,而是选择基于主键索引的全表扫描。
set long_query_time=0;将慢查询日志打开,并将阙值设为 0. 在记录的日志中,可以发现 MySQL 并没有选择 a 所在的索引,同时花费了更长的时间。
这样看,MySQL 的优化器不一定每次都能选择合适的索引。想要理解出现该现象的原因,就要从优化器的选择逻辑说起。MySQL 中优化器的目的就是找到一个最优的执行方案,从而用最小的代价去执行语句。
优化器在选择索引时,主要会考虑如下的因素:
扫描的行数
有没有涉及到临时表
排序
MySQL 在执行语句前,其实并不能准确的计算出扫描的行数,而是通过数学统计信息来估算记录数。这个统计信息被称为索引的“区分度”,在索引上不同的值越多,区分度就越高。在一个索引上不同值的个数,称为“基数”。基数越大,索引的区分度越好。

这里的 Cardinality 就是索引的基数,但基数并不是完全准确的。MySQL 是在获取基数时,实际上是采用采样统计的方式。
计算时,会选择 N 个数据页,并统计这些页面上的不同值,得到一个平均值,然后乘以该索引的页面数,然后得到的就是索引的基数。
在 MySQL 中,有两种存储索引的方式,可通过设置 innodb_stats_persistent 来切换:on 时:表示统计信息会持久化存储,默认 N 为 20,M 为 10off 时,统计信息仅会存储在内存中,默认 N 为 8,M 为 16
Select * from Y where a between 10000 and 20000 ;
select * from Y force index(a) where a between 10000 and 20000 ;
mysql 是通过标记删除的方法来删除记录的,并不是在索引和数据文件中真正的删除。而且由于一致性读的保证,不能删除 delete 的空间,再加上 insert 的空间。导致统计信息有误。
选用错误索引的解决办法对于行数预估错误的情况, 可采用如下的方法:
如果遇到 EXPLAIN 和预估的行数,数值相差较大时,可以通过analyze table 来重新统计索引信息。
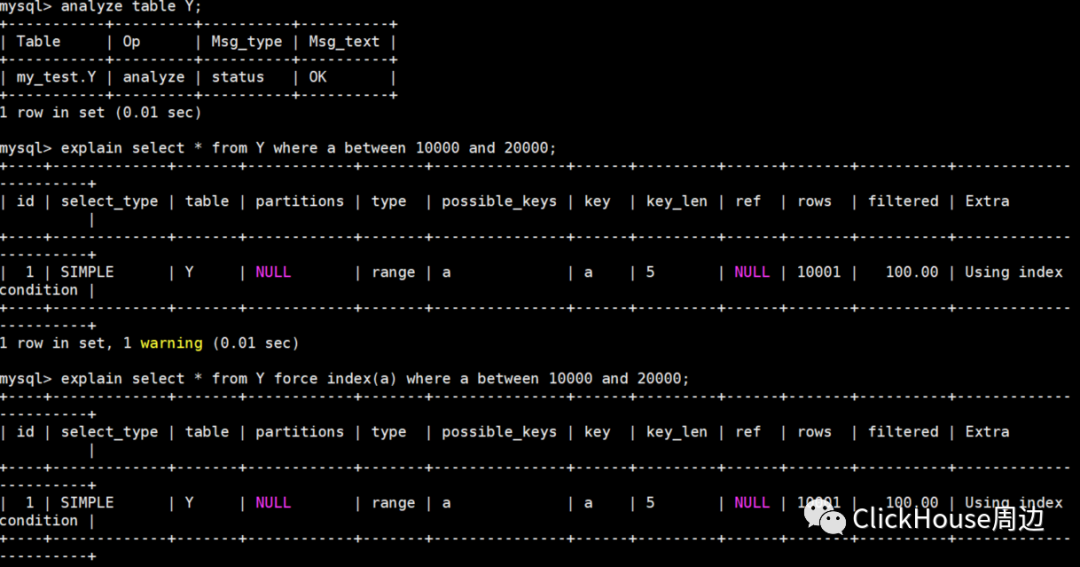
直接通过 force index 强制指定需要使用的索引,不让优化器进行判断。但使用 force 也可能带来一些问题:
迁移数据库时,语法不支持
不容易变更并且不太方便,因为选错索引的情况一般不会经常发生,在生产环境出现问题后,才需要改代码,但还需要重新进行上线测试,部署。
那知道的选错索引的情况,再总结一下MySQL在不走索引的情况:
全表扫描 :select * from city;SQL注入:select * from city where id=1001 or 1=1;
Mysql表t100w num列有索引select * from t100w where num > 1000; ----> 全表扫描
where id = 1000000where id > 500000 and id < 600000limit 100
help--->help contents--->help Table Maintenance方法一:ANALYZE TABLE world.city;方法二:OPTIMIZE TABLE world.city;方法三:删除索引重建
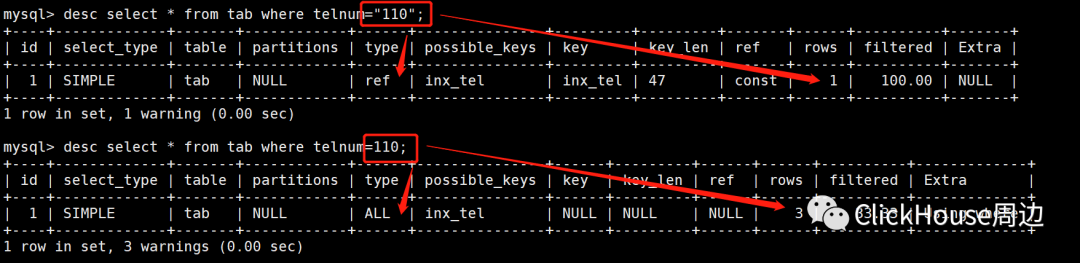
错误的例子:select * from test where id-1=9;正确的例子:select * from test where id=10;
错误的例子:create table tab (id int,name char(10),telnum varchar(11));insert into tab values (1,"a","110"),(2,"b","120"),(3,"c","119");select * from tab;alter table tab add index inx_tel(telnum);mysql> desc tab;+--------+-------------+------+-----+---------+-------+| Field | Type | Null | Key | Default | Extra |+--------+-------------+------+-----+---------+-------+| id | int(11) | YES | | NULL | || name | char(10) | YES | | NULL | || telnum | varchar(11) | YES | MUL | NULL | |+--------+-------------+------+-----+---------+-------+3 rows in set (0.00 sec)mysql> desc select * from tab where telnum="110";mysql> desc select * from tab where telnum=110;
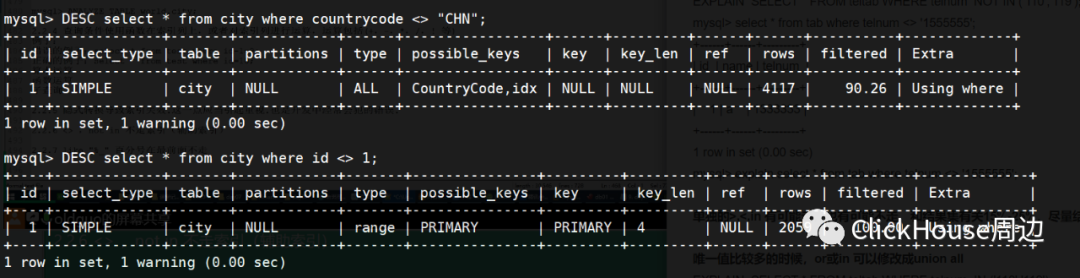
DESC select * from city where countrycode <> "CHN";DESC select * from city where id <> 1;
单独的>,<,in 有可能走,也有可能不走,和结果集有关15%-25%,尽量结合业务添加limit
唯一值比较多的时候,or或in 可以修改成union all
EXPLAIN SELECT * FROM teltab WHERE telnum IN ('110','119');改写成:EXPLAIN SELECT * FROM teltab WHERE telnum='110'UNION ALLSELECT * FROM teltab WHERE telnum='119';
range索引扫描: EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '31%'不走索引: EXPLAIN SELECT * FROM teltab WHERE telnum LIKE '%110'
%linux%类的搜索需求,可以使用elasticsearch 或者 mongodb 专门做搜索服务的数据库产品。
调整索引的思路
降低索引树高度。 如果InnoDB表的数据写入顺序能和B+树索引的叶子节点顺序一致的话,这时候存取效率是最高的。
使用自增列(INT/BIGINT类型)做主键,这时候写入顺序是自增的,和B+数叶子节点分裂顺序一致;
该表不指定自增列做主键,同时也没有可以被选为主键的唯一索引(上面的条件),这时候InnoDB会选择内置的ROWID作为主键,写入顺序和ROWID增长顺序一致;除此以外,如果一个InnoDB表又没有显示主键,又有可以被选择为主键的唯一索引,但该唯一索引可能不是递增关系时
select count(*) from world.city;select count(distinct countrycode) from world.city;select count(distinct countrycode,population ) from world.city;

