




分布式、去中心、可扩展性
前面我们把这六条分成了两类,分布式、去中心、可扩展,这三个围绕的是 KEY 的独立性。尤其是 Partition Key,它是具有极强的独立性的。由于它的极度独立,理论上任何不同 Partition Key 的数据,就都可以放在不同机器上,去独立的提供服务,也就成就它的分布式、去中心和可扩展。对照这几条特性看一下。
分布式,百度词条上解释为,建立在网络上的软件系统。有四大特性:
分布性。分布式系统由多台计算机组成,它们在地域上是分散的,可以散布在一个单位、一个城市、一个国家,甚至全球范围内。整个系统的功能是分散在各个节点上实现的,因而分布式系统具有数据处理的分布性。一个逻辑上的数据库表,他是分散存储来多个 Node 中的。不同的 Key 值的记录会由 Cassandra 的不能节点提供分散的的服务。
自治性。分布式系统中的各个节点都包含自己的处理机和内存,各自具有独立的处理数据的功能。通常,彼此在地位上是平等的,无主次之分,既能自治地进行工作,又能利用共享的通信线路来传送信息,协调任务处理。Cassandra 只有在 Partition Key 划分数据所属 Node 的存储位置时,有主次副本之分。比如说,我的 Node1 要存放的 Key 值是多少到多少,其他的勉强称之为副本。其实 Cassandra 存的是多个地位平等主本,且都具备独立处理数据等能力,它们协同处理任务,并非传统意义上的主备数据概念。
并行性。一个大的任务可以划分为若干个子任务,分别在不同的主机上执行。每个 Node 自然是自己提供涉及的 Key 的服务,相互之间独立、并行。对于不同的 CQL 而言,可能会由不同 Node 来完成查询。也可以是一个 CQL 里面涉及的多个 Node,它们也基本上是并行来完成这个 CQL 的。
全局性。分布式系统中必须存在一个单一的、全局的进程通信机制,使得任何一个进程都能与其他进程通信,并且不区分本地通信与远程通信。同时,还应当有全局的保护机制。系统中所有机器上有统一的系统调用集合,它们必须适应分布式的环境。在所有 CPU 上运行同样的内核,使协调工作更加容易。Cassandra 是完全符合这个定义的,Coordinator 节点并不是固定的。每个节点都可以接受任何的 CQL,并且来充当协调者的角色。重要的是,对于一个应用程序或者客户端而且,可以不关心 Cassandra 后来是怎么样存储和查询数据的。它从外面看到的,始终只有一张完整的逻辑数据表。
有了分布式的基础,Cassandra 可以运行在多个 Node 下,并且多个 Node 可以部署在真实的不同的数据中心机房里,不同机架上,也就能做到去中心 Decentralized。有了这个基础,就可以配合 Cassandra 的多中心的复制策略 NetworkTopologyStrategy,在每一个数据中心定义数据复制了。
可扩展这个词其实,并不是特别准确,它的重点其实是可水平扩展。简而言之,就是在图中环上加 Node,就可以提高 Cassandra 的处理能力。这其实和它的分布式特点是密不可分的。Cassandra 的拆分粒度最细,理论上几乎可以到一个 Partition KEY。或者说,每一个 Partition KEY,都可以被看作可以拆分的,独立处理的最小的单位。增加数据的同时只要增加 Node 就可以了,这就使得它的水平扩展性是很好的。
做一个偏激的假设,如果 Cassandra 只有一份数据存储,就凭 Key 独立的特点,把不同的 Key 分到不同的机器上提供服务,也可以算得上是分布式、去中心和可扩展的。但是它这个特点是不完美,不彻底的。因为机器分得越多,任何一台机器故障,它提供的服务就是不完整的。
高可用、容错性、可配置一致性
接下来,我们继续看另外三个特点,高可用、容错性、可配置的一致性,这些特点围绕的核心就数据冗余。
任何的高可用背后,一定是有数据冗余的。传统数据库通常偏爱的是主备模式,就是当提供服务的数据库节点 DOWN 掉之后,备节点开始提供服务。这时候往往故障检测、主备切换,应用切换的时间就会成为关注的焦点,做得好一点的数据库可以在 1 分钟或者几十秒内完成切换。不过在如今 7*24*365 的环境下,1 分钟的故障恢复时间通常并不能让用户十分满意,当切换时间压缩到一定程度,还会出现一个矛盾点,就是数据库异常时间监测阈值。如果设得太长,主备切换就慢,设太短了,一个网络抖动,就可能触发不必要的主备切换误判。
Cassandra 的数据复制(replicas)并不像传统的备份数据,它更像是多份主数据,这些数据都是时时刻刻对外提供服务的,换句话说,有一个数据库节点 DOWN 掉,完全不需要主备切换时间。在资源充足的情况下,甚至是几乎无感的(比如 7 个 replicas 坏了 1 个)。
在 Cassandra 里面,数据复制(replicas)多少份,怎么存储,这个策略是可以根据不同的 Keyspace 来设置的,相当于提供一个灵活的选择,可以根据数据库表的实际使用场景和形态,来决定数据复制的策略。
数据冗余可以说是分布式系统中的常规操作,像参数数据之类的,经常会采用数据冗余的方法来处理。然而,有冗余的地方就有同步。数据一致性问题,永远和数据冗余相伴而生。好在 Cassandra 有 Timestamps 来解决一致性问题,容错性只是一致性的一个衍生产品,简单的说,只是 Cassandra 发现了一个老 Timestamps 的错误数据,后台修复一下而已。
而可配置一致性,就是 Cassandra 的一个特别重要的特性了。因为它的影响但不仅仅是对于高可用,它还直接影响数据库性能。就传统数据库而言,开不开备库,对 OLTP 交易性能也是有直接影响的(包括 Redis 也是)。从理论上来说,Cassandra 要等更多的 Node 写入数据,那响应时间就会越慢。这个响应时间取决与最慢的那个 Node。若要交易响应更快,就需要通过异步的方式。所以 Cassandra 通常都不会等所有的 Node 都响应,等多少 Node,等哪些 Node,就是可配置一致性。
在数据写入读取方面 Cassandra 的一直性级别有:
ANY(仅写入),ONE,TWO,THREE ,QUORUM,ALL
LOCAL_ONE, LOCAL_QUORUM,EACH_QUORUM
以上这些级别很好理解,不需要逐个解释。关于高可用和强一致性,永远都是鱼和熊掌。假如我们的系统使用了最快的方式写入,比如写 ANY,读 ONE。那么读到的数据并不是最实时的准确数据的可能性就会大幅增加。如上面的图,有 6 个节点在写入数据,任意一个写成功,程序就成功返回。那么假定其余 5 个节点还没有完成写入。那这时候,有一个读 ONE 的程序,恰好读到了这 5 节点中的一个,并成功返回,这就产生了数据的不一致。要做到数据的强一致,读写策略就必须配合设置,满足这样的条件。
W+R>RF W—写一致性级别 R—读一致性级别 RF—副本数
Cassandra 的这个设计非常的巧妙,它提供极好的调优灵活性。数据库调优的本质无非是个损有余而补不足的过程,这个有余并非指损性能好的地方去补性能不好的地方。
数据库或数据,有些地方有些功能,我们不用或者少用,性能不需要那么好,称之为有余;有些地方有些功能我们常用,主要用,性能要越快越好,我们称之为不足。比如很多系统的某个数据库表,它的访问形态是有局限性的。有可能一张表,100 次插入,只有 1 次读取,像流水数据。有可能一张表,1 次插入,100 次读取,像参数数据。这里面就有了极大的灵活性,我们可以损失冷门操作的性能,来保障我们的主要操作。例如,以读取为主的表,我们可以设置写入的一致性为 ALL ,读取的一致性为 ONE。从而获得一个非常高效的系统性能。
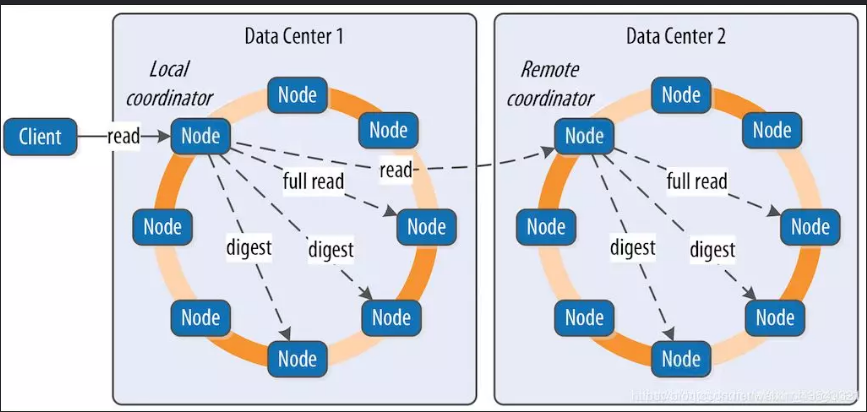
需要注意的是,数据的复制因子,是定义在 Keyspace,也就是在存储方面决定。而读取的一致性,是由客户端决定的。同样的数据,也可以根据不同使用场景来使用不同的一致性级别。比如说,对数据实时性要求高时,可以设置成读 QUORUM 或者 ALL,实时性要求低时,选择读 ONE。
