





大家好,今天和大家分享的是PG 生成性能报告相关的工具pg_profile.
熟悉oracle的小伙伴都知道,每当系统出现问题,尤其是客户或者开发的同事放映某一段时间数据库有性能问题, DBA 最先想到的是先用AWR 或者ASH按照事故的放生时间生成一个报告,
拿到报告后观测各种可能出现问题的指标来分析问题。 如果是开发偷偷新上了什么性能不好的SQL, 或者网络,存储IO有什么问题,可以当成直接的证据提供给相关人员。
PG数据库作为ORACLE 替换的种子选手, 也是可以找到类似生成AWR report 的方案的, 还是通过强大的插件机制 pg_profile 和 pgpro-pwr。
pg_profile 目前是开源的,国内的阿里云上的 Postgres RDS 默认集成了这个插件。
pgpro-pwr 这个是业内著名公司Postgres Professional 开的商业版的插件,是需要 license的。 本次就不过多介绍了
pg_profile 这个插件从工作原理上来说,是依赖于如下的基础指标数据
1.依赖 pg_stat_xxx 这些 system statistics 采集的视图
2.依赖 pg_stat_kcache 插件,负责采集系统级别的CPU,SYSTEM io等负载的信息
3.依赖 pg_stat_statements 插件,负责收集SQL statement 级别的统计信息
4.依赖 pg_wait_sampling 插件,负责收集等待事件的信息
5.依赖 dblink 插件,可以实现远程收集其他实例信息的功能。
pg_profile 这个插件主要是由PGPSQL和HTML 2种开发语言组成, 所以不需要C语言的 make & make install 的编译安装。
下面我们来测试安装一下pg_profile:
Github 链接地址: https://github.com/zubkov-andrei/pg_profile
这个extension 的信息采集,依赖于如下的几个插件:
1.pg_stat_statements 和 dblink PG源码中内置的软件,只需要进入到 src/contrib/{pg_stat_statements|dblink} 安装即可
pg_stat_statements 利用这个插件收集 SQL 语句相关的统计信息。
dblink 需要这个插件的原因是 pg_pofile 可以进行远程收集其他数据库实例的性能报告信息。
INFRA [postgres@wqdcsrv3352 contrib]# cd pg_stat_statements/
INFRA [postgres@wqdcsrv3352 pg_stat_statements]# make
INFRA [postgres@wqdcsrv3352 pg_stat_statements]# make install
INFRA [postgres@wqdcsrv3352 contrib]# cddblink/
INFRA [postgres@wqdcsrv3352 dblink]# make
INFRA [postgres@wqdcsrv3352 dblink]# make install
2.pg_stat_kcache 需要单独下载:
pg_stat_kcache 这个插件是用来收集一些文件系统的负载信息。
Github link: https://github.com/powa-team/pg_stat_kcache
INFRA [postgres@wqdcsrv3352 postgreSQL]# git clone https://github.com/powa-team/pg_stat_kcache.git
INFRA [postgres@wqdcsrv3352 postgreSQL]# cd pg_stat_kcache
INFRA [postgres@wqdcsrv3352 pg_stat_kcache]# make
INFRA [postgres@wqdcsrv3352 pg_stat_kcache]# make install
3.pg_wait_sampling 需要单独下载:(可选项)
pg_wait_sampling 这个是可选项,如果安装了这个插件,可以在性能报告中显示 等待事件的信息
Github link: https://github.com/postgrespro/pg_wait_sampling
INFRA [postgres@wqdcsrv3352 postgreSQL]# git clone https://github.com/postgrespro/pg_wait_sampling.git
INFRA [postgres@wqdcsrv3352 postgreSQL]# cd pg_wait_sampling
INFRA [postgres@wqdcsrv3352 pg_wait_sampling-1.1.4]# make USE_PGXS=1
INFRA [postgres@wqdcsrv3352 pg_wait_sampling-1.1.4]# make USE_PGXS=1 install
4.最后安装pg_profile :
Github release link:https://github.com/zubkov-andrei/pg_profile/releases
这个插件只需要解压到 $(pg_config --sharedir)/extension 路径下即可
INFRA [postgres@wqdcsrv3352 postgreSQL]# INFRA [postgres@wqdcsrv3352 postgreSQL]# wget https://github.com/zubkov-andrei/pg_profile/releases/download/4.1/pg_profile--4.1.tar.gz
INFRA [postgres@wqdcsrv3352 postgreSQL]# tar xzf pg_profile--4.1.tar.gz --directory $(pg_config --sharedir)/extension
我们把这个插件 pg_wait_sampling,pg_stat_statements 添加到配置文件中, 并重启数据库
shared_preload_libraries = 'pg_wait_sampling,pg_stat_statements,pg_stat_kcache'
track_activities = on
track_counts = on
track_io_timing = on
track_wal_io_timing = on # Since Postgres 14
track_functions = all/pl
创建 extension : pg_wait_sampling, pg_stat_statements,dblink,pg_stat_kcache
postgres@[local:/tmp]:2008=#51293 create extension pg_wait_sampling;
CREATE EXTENSION
postgres@[local:/tmp]:2008=#53277 create extension pg_stat_kcache;
CREATE EXTENSION
postgres@[local:/tmp]:2008=#94013 create extension pg_stat_statements;
CREATE EXTENSION
postgres@[local:/tmp]:2008=#44608 create extension dblink;
CREATE EXTENSION
postgres@[local:/tmp]:2008=#59239 create extension pg_profile;
CREATE EXTENSION
postgres@[local:/tmp]:2008=#53277 \dx+
Objects in extension "pg_stat_kcache"
Object description
---------------------------------
function pg_stat_kcache()
function pg_stat_kcache_reset()
view pg_stat_kcache
view pg_stat_kcache_detail
(4 rows)
Objects in extension "pg_stat_statements"
Object description
---------------------------------------------------
function pg_stat_statements(boolean)
function pg_stat_statements_info()
function pg_stat_statements_reset(oid,oid,bigint)
view pg_stat_statements
view pg_stat_statements_info
(5 rows)
Objects in extension "pg_wait_sampling"
Object description
------------------------------------------------
function pg_wait_sampling_get_current(integer)
function pg_wait_sampling_get_history()
function pg_wait_sampling_get_profile()
function pg_wait_sampling_reset_profile()
view pg_wait_sampling_current
view pg_wait_sampling_history
view pg_wait_sampling_profile
(7 rows)
Object description
-------------------------------------------------------------------------
foreign-data wrapper dblink_fdw
function dblink_build_sql_delete(text,int2vector,integer,text[])
...
Objects in extension "pg_profile"
Object description
--------------------------------------------------------------------------------
function check_stmt_cnt_all_htbl(jsonb,integer)
...
...
view v_sample_timings
(257 rows)
安装完毕后,我们可以发现 pg_profile 这个插件拥有 257 个对象。
我们先在本地安装一个server, 这里server 的概念就是要生成报告的一个实例, 这个实例可以是本次的,也可以是远程的
我们创建一个本地的实例: 这个我们创建一个单独的账户 profile_mon , 这个账号用于读取所有性能相关采集的指标,并写入pg_pofile 相应表里面。
postgres@[local:/tmp]:2008=#38536 create role profile_mon login password 'pwd_mon';
CREATE ROLE
postgres@[local:/tmp]:2008=#38536 grant pg_read_all_stats to profile_mon;
GRANT ROLE
postgres@[local:/tmp]:2008=#38536 grant execute on function pg_stat_statements_reset TO profile_mon;
GRANT
postgres@[local:/tmp]:2008=#38536 select set_server_connstr('local','dbname=postgres port=2008 user=profile_mon password=pwd_mon');
set_server_connstr
--------------------
1
(1 row)
接下来我们设置一下set_server_size_sampling, 这个是来定义采集表的大小的信息的采集器的时间窗口,
因为采集表的大小是一个耗时,耗资源的操作,所以我们需要预先采集好了写入试图相关的表中,并不是生产报告的时候,再去实际去查每一个表的大小。
这里我们设置每天夜里跑一次:23:00 开始, 跑一个小时, 间隔为1天
postgres@[local:/tmp]:2008=#39046 SELECT set_server_size_sampling('local','23:00+08',interval '1 minutes',interval '24 hour');
set_server_size_sampling
--------------------------
1
(1 row)
postgres@[local:/tmp]:2008=#39046 SELECT * FROM show_servers_size_sampling();
server_name | window_start | window_end | window_duration | sample_interval
-------------+--------------+-------------+-----------------+-----------------
local | 23:00:00+08 | 23:01:00+08 | 00:01:00 | 24:00:00
(1 row)
我们手动创建一下 sample 采样:
(5,“2023-02-16 18:04:06+08”,f,) 原始的开头应该是 ID =1 开始的, 由于实验的演示的原因,我在之前删除了几个 sample, 所以现在开始的ID =5
postgres@[local:/tmp]:2008=#39046 select take_sample();
take_sample
------------------------
(local,OK,00:00:00.85)
(1 row)
postgres@[local:/tmp]:2008=#39046 select show_samples();
show_samples
-----------------------------------
(5,"2023-02-16 18:04:06+08",f,,,)
(1 row)
下面我们可以用pgbench 跑一下性能测试: 大致跑个5分钟
INFRA [postgres@wqdcsrv3352 ~]# pgbench -M prepared -r -c 8 -j 4 -T 300 -U postgres -p 2008 -d pgbench -l
tps = 292.941923 (without initial connection time)
statement latencies in milliseconds and failures:
0.306 0 \set aid random(1, 100000 * :scale)
0.434 0 \set bid random(1, 1 * :scale)
0.414 0 \set tid random(1, 10 * :scale)
0.407 0 \set delta random(-5000, 5000)
1.276 0 BEGIN;
2.644 0 UPDATE pgbench_accounts SET abalance = abalance + :delta WHERE aid = :aid;
2.240 0 SELECT abalance FROM pgbench_accounts WHERE aid = :aid;
2.825 0 UPDATE pgbench_tellers SET tbalance = tbalance + :delta WHERE tid = :tid;
4.355 0 UPDATE pgbench_branches SET bbalance = bbalance + :delta WHERE bid = :bid;
2.327 0 INSERT INTO pgbench_history (tid, bid, aid, delta, mtime) VALUES (:tid, :bid, :aid, :delta, CURRENT_TIMESTAMP);
8.731 0 END;
等pgbench 跑完结束之后,我们再次手动的生成一个采样 sample
postgres@[local:/tmp]:2008=#129381 select take_sample();
take_sample
------------------------
(local,OK,00:00:00.87)
(1 row)
我们查看一下现有的sample 数量:
postgres@[local:/tmp]:2008=#129381 select show_samples();
show_samples
-----------------------------------
(5,"2023-02-16 18:04:06+08",f,,,)
(6,"2023-02-16 19:57:43+08",f,,,)
(2 rows)
我们还需要在server 部署一个定时 corntab job 来触发每隔30分钟,自动采取一个样本。
*/30 * * * * psql -h /tmp -p 2008 -c 'SELECT take_sample()' > /dev/null 2>&1
原则上至少有2个smaple , 才能生成 report, 生成report 的函数是: get_report(5,6) 5,6 是2个sample 的采样ID
INFRA [postgres@wqdcsrv3352 ~]# psql -h /tmp -p 2008 -Aqtc "SELECT get_report(5,6)" -o report_5_6.html
get_report 这个函数的入参除了支持 sample id, 之外还支持输入时间范围:
psql -h /tmp -p 2008 -Aqtc "select get_report(tstzrange('2023-02-16 14:35:27+08','2023-02-16 15:08:44+08'))" -o report_range_14:35-15:08.html
接下来,我们查看一下生成的report:
大致分为: server 统计信息类: DATABASE, WAL, tablespace , wait event 等等
SQL 语句统计类别: 各类TOP SQL
数据库内表,索引的统计信息
用户函数的统计信息
vacuum 的相关对象的信息
实例修改参数的信息
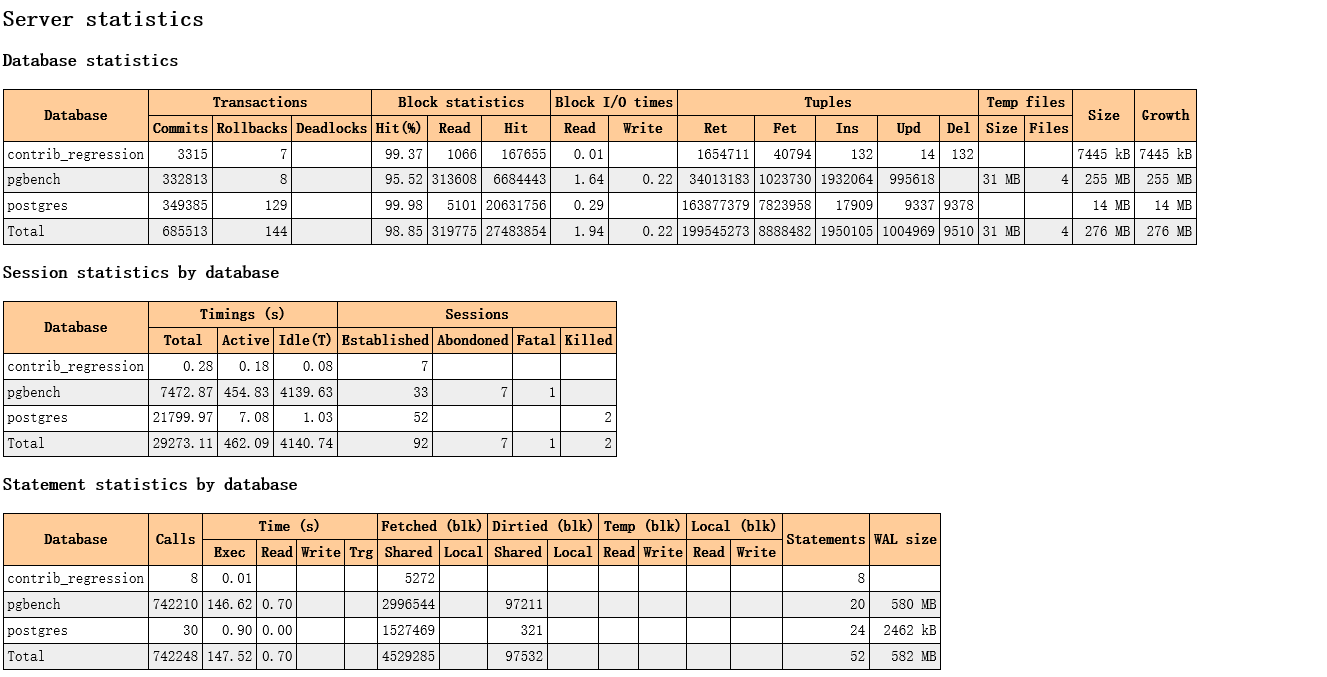
TOP SQL:
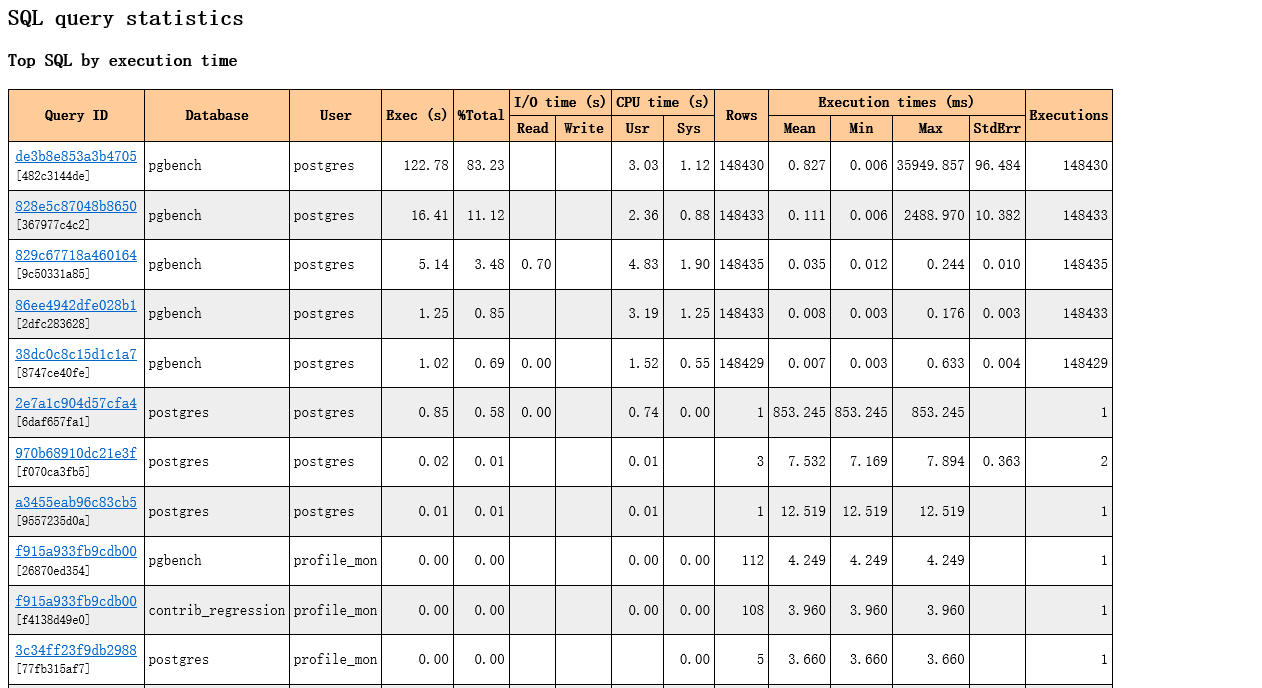
除了get_report 这个函数, pg_profile 还支持2个时段 report 作比对 类似于oracle AWR 的 awrddrpt.sql 功能: get_diffreport
postgres@[local:/tmp]:2008=#19819 select take_sample();
take_sample
------------------------
(local,OK,00:00:00.94)
(1 row)
postgres@[local:/tmp]:2008=#19819 select show_samples();
show_samples
-----------------------------------
(5,"2023-02-16 18:04:06+08",f,,,)
(6,"2023-02-16 19:57:43+08",f,,,)
(7,"2023-02-16 20:27:43+08",f,,,)
(3 rows)
INFRA [postgres@wqdcsrv3352 ~]# psql -h /tmp -p 2008 -Aqtc "select get_diffreport(5,6,6,7)" -o report__diff.html
查看对比的报告:

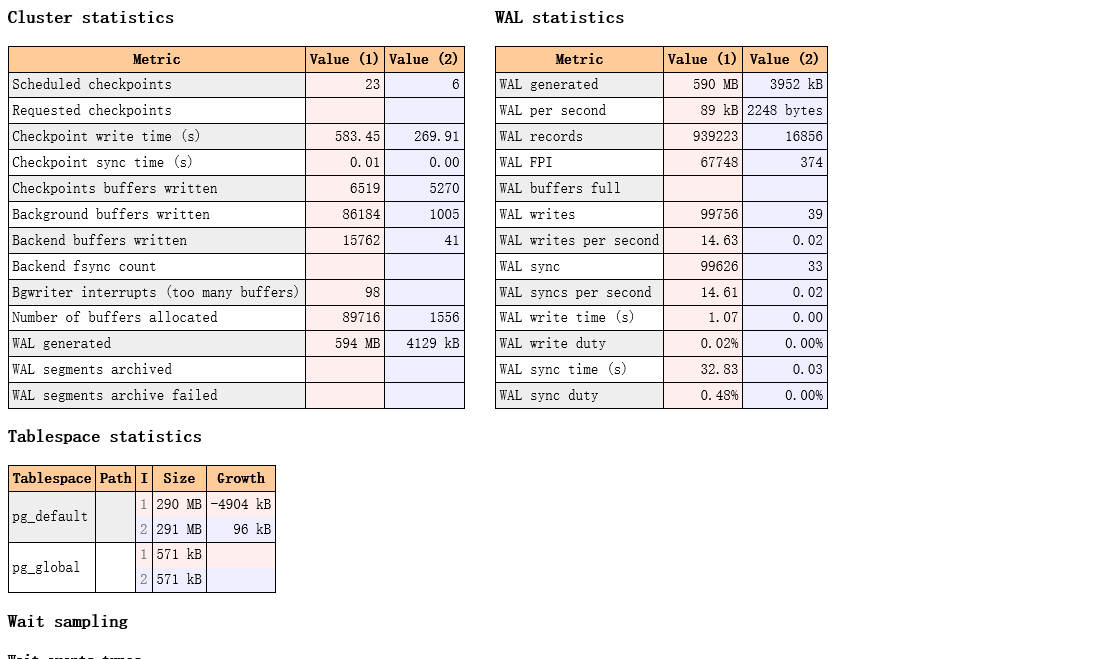
写到最后
1.我们再来看一下一些有用的参数:
在postgres.conf 中设置
pg_profile.max_sample_age= 7 -- 设置sample 的过期时间,以防止采集量占用空间过大
pg_profile.topn = 20 -- report中显示的 top N的对象
pg_profile.track_sample_timings = off --记录采样的详细时间
pg_profile.max_query_length = 20000 查询语句的最大长度,超出部分阶段
2.如果部署pg_profile 到生产,需要对大型数据库sample 采样的性能影响做评估(不建议采样频率太高),需要对存储sample的空间大小做评估。
3.如果你的生产库已经有了 Prometheus + Grafana + Alert manager 这套监控的东西, 这个PG_PROFILE 可以最为额外的补充和数据支持。
Grafana 只是看图形的趋势, PG_PROFILE 生成的数据表格更为详细。
Have a fun 🙂 !
