




数据库版本
Mogdb数据库版本:2.1.1
系统版本:Kylin V10 SP2
故障现象
监控prometheus告警,提示服务器内存剩余率偏低,开始介入处理。
登录服务器发现服务器本身内存非常小,只有6G,大部分内存都被buffer/cache使用,可用内存仅剩余1G。

服务器为kylin系统,之前该类服务器存在audit和mate-indicators进程占用内存过多的已知BUG,以为本次也是类似的问题,直接top走起,使用top命令检查占用较多内存的进程,发现mogdb首当其冲。而audit和mate进程都不在前十,尴尬了。
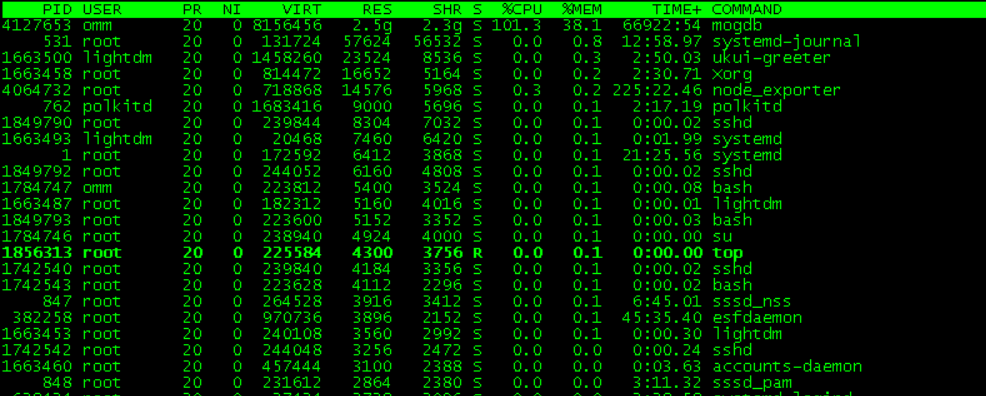
小技巧:top可以按照进行CPU,MEM,SWAP等排序,按f,选择需要排序的选项,按s固定,esc退出即可
故障诊断
1、检查数据库内存使用情况
既然确定是mogdb占用了大量内存,开始从数据库角度排查问题,先检查数据库进程使用的内存情况。
openGauss=# select * from DBE_PERF.MEMORY_NODE_DETAIL;
ERROR: unsupported view for memory protection feature is disabled.
使用dbe_perf.memory_node_detail查看数据库节点所有内存的使用情况,但是很可惜,由于服务器本身内存太小,导致数据库特性没有开启,无法记录数据库内存使用。
小提示:memory protection feature特性可以使用参数memory_protection_feature开启,但是需要注意的是,该参数的使用有一定的限制,关于参数的配置使用,请自行参考文档
换个思路,通过检查数据库总内存设置,及数据库动态内存使用情况确定是否存在数据库内存设置不当,甚至于存在内存溢出等问题。
--查看内存设置
openGauss=# show max_process_memory;
max_process_memory
--------------------
4GB
(1 row)
openGauss=# show shared_buffers;
shared_buffers
----------------
1GB
(1 row)
openGauss=# show cstore_buffers;
cstore_buffers
----------------
16MB
(1 row)
file_manage=# show wal_buffers;
wal_buffers
-------------
1GB
(1 row)
file_manage=# show work_mem;
work_mem
----------
16MB
(1 row)
file_manage=# show maintenance_work_mem;
maintenance_work_mem
----------------------
1GB
(1 row)
--查看动态内存使用情况
file_manage=# select contextname,pg_size_pretty(sum(totalsize)),pg_size_pretty(sum(freesize))
from gs_session_memory_detail
group by contextname
order by sum(totalsize) desc
limit 10;
contextname | pg_size_pretty | pg_size_pretty
---------------------------+----------------+----------------
TwoPhase Cleaner | 96 MB | 7710 kB
SessionCacheMemoryContext | 49 MB | 11 MB
gs_signal | 24 MB | 1695 kB
ThreadTopMemoryContext | 10 MB | 781 kB
CBBTopMemoryContext | 10013 kB | 2335 kB
DefaultTopMemoryContext | 9012 kB | 1708 kB
StorageTopMemoryContext | 7686 kB | 977 kB
PLpgSQL function cache | 6083 kB | 8496 bytes
Timezones | 2527 kB | 86 kB
CachedPlan | 2231 kB | 1187 kB
(10 rows)
可以发现无论数据库内存参数设置和动态内存的使用都不大,继续检查数据库连接,查看数据库会话信息
openGauss=# select datname,usename,state,count(*) from pg_stat_activity group by datname,usename,state order by 4 desc;
datname | usename | state | count
-------------+-------------+--------+-------
postgres | db_exporter | idle | 4
postgres | omm | active | 3
file_manage | db_exporter | idle | 2
postgres | omm | idle | 2
file_manage | root | idle | 2
(5 rows)
可以发现数据库的连接数也非常小,甚至于业务进程几乎没有,至此可以确定数据库没有明显占用内存的行为。
2、检查系统内存占用
再次使用free -g检查数据库内存占用,注意到一个细节,大量的内存并不是被used,而是被buffer/cache了

linux处理句柄的方式暂且不提,我们直接看结果,既然buffer/cache大,那么会不会是mogdb占用了大量的句柄,可以使用lsof命令查看句柄的使用。
[root@DBDZDADB ~]# ps -ef|grep mogdb
root 1861416 1849793 0 14:37 pts/1 00:00:00 grep mogdb
omm 4127653 1 46 2022 ? 46-13:25:46 /dbdata/app/mogdb/bin/mogdb -D /dbdata/data
[root@DBDZDADB ~]# lsof -p 4127653|wc -l
436055
[root@DBDZDADB ~]#

果然,mogdb占用了大量的句柄资源,接下来,确定哪个文件占用了句柄。
[root@DBDZDADB ~]# lsof -p 4127653|sed '1d'|awk '{print $9,$10}'| sort | uniq -c | sort -rn|head -10
435717 protocol: TCPv6
67 pipe
2 /var/lib/sss/mc/passwd
1 /usr/lib/locale/locale-archive
1 /usr/lib64/libtinfo.so.6.2
1 /usr/lib64/librt-2.28.so
1 /usr/lib64/libresolv-2.28.so
1 /usr/lib64/libpthread-2.28.so
1 /usr/lib64/libnuma.so.1.0.0
1 /usr/lib64/libnss_sss.so.2

可以看到大量的tcpv6连接占用了系统句柄,目前已经到43万。
基本上到此,我们可以确定是由于频繁连接数据库导致的内存占用吃紧问题。正常情况,连接句柄可以正常释放,但是在故障场景下明显释放没有积累的快,导致最终形成43万个连接句柄。
故障成因
将问题提交给二线后,确定为bug,该bug在3.0.1及以下版本存在,目前在3.0.2已修复,建议升级到3.0.3长期支持版本规避类似问题。
汇总及拾遗
之后了解到,除了以上的故障现象外,在数据库运行DML时,也会出现类似failed to allocate a zone的报错,同为该bug的故障现象。临时解决方案可以重启数据库实例,长期解决方案仍需要将数据库到升级3.0.3版本。

