




本章节将引导您快速熟悉StellarDB,并为您初步介绍如何通过KG Explorer和beeline客户端操作StellarDB。其中,"StellarDB初探"一节通过构建一张人物关系图,从零介绍如何在StellarDB进行基本操作;"StellarDB进阶"一节为您提供了内置于StellarDB的《哈利·波特》人物关系图,帮助您进一步探索StellarDB。
1. StellarDB初探
1.1. 使用KG Explorer构建图
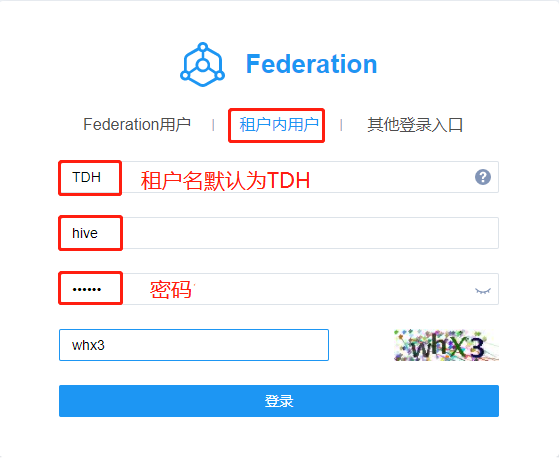
- 从TDH Manager页面进入KG Explorer页面。若KG Explorer开启了单点登录,会自动跳转Federation登录页面,选择“租户内用户”,并提供相对应的用户名和密码按如图方式登录:
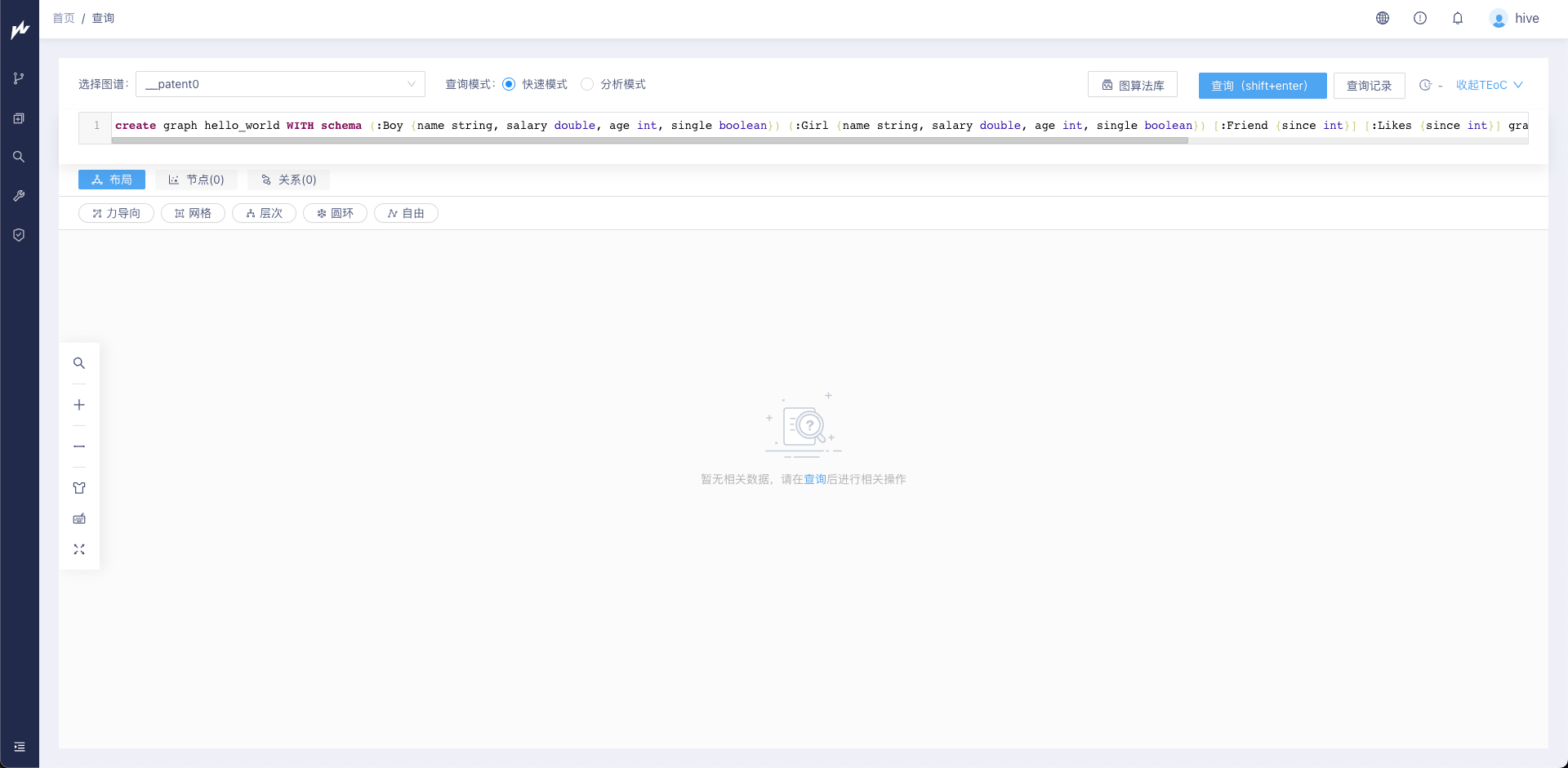
- 点击 登录 后进入KG Explorer主页面。在语句查询输入框中输入如下建图语句构建图"hello_world"的schema。(该语句创建了一个分区为3,服本数为3,名称为"hello_world"的图。图中包含Boy和Girl两种类型的点,两个点均包含name、salary、age、single四个属性,对于每个属性设定相应的数据类型。图中包含Friend和Likes类型的边,边属性均为since,数据类型为int)
- create graph hello_world WITH schema (:Boy {name string, salary double, age int, single boolean}) (:Girl {name string, salary double, age int, single boolean}) [:Friend {since int}] [:Likes {since int}] graphproperties:{`graph.shard.number`:3, `graph.replication.number`:3};
- 点击 查询 按钮,完成"hello_world"的图schema的创建。
- 创建"hello_world"的schema后,在查询语句输入框中输入并执行如下语句设置"hello_world"图为当前使用中的图。
- use graph hello_world;
- 在"hello_world"图中插入点数据。请在查询语句输入框中分别输入、执行下列语句。
- # 插入一个类型为Girl的点,并对属性赋值,__uid为1
create (:Girl {name:"Kitty", age:23, salary:4250.95, single:true, __uid:"1"});
# 插入两个点,类型分别为Girl和Boy,不对属性赋值,__uid分别为2和1
create (:Girl {__uid: "2"}), (:Boy {__uid:"1"});
# 插入一个点,类型为Girl,对name属性赋值Lisa,__uid为3,设置点标签为human和student
create (:Girl {__uid: "3", name: "Lisa", __tags: ["human", "student"]});
- 在"hello_world"图中插入边数据。请在查询语句输入框中分别输入、执行下列语句。
- # 插入一条类型为Likes的由John指向Rose有向边,插入边的同时插入两个点,类型分别为Boy和Girl,并且对name属性赋值,__uid分别为2和4
create (:Boy {__uid:"2", name:"John"})-[:Likes]->(:Girl {__uid: "4", name: "Rose"});
# 插入一条类型为Likes的由Amy指向John有向边,插入边的同时插入一个点,类型为Girl,并且对name属性赋值Amy,__uid为5
match (a:Boy {__uid:"2"}) create (a)<-[:Likes]-(:Girl {__uid:"5", name: "Amy"});
# 插入一条类型为Friend的连接John和__uid为1的Boy节点的无向边
match (a:Boy {__uid:"1"}),(b:Boy {__uid:"2"}) create (a)-[:Friend]-(b);
# 插入两条类型为Friend的有向边,其中一条是从__uid为1的Girl类型节点指向__uid为2的Girl类型节点,另外一条是从__uid为3的Girl类型节点指向__uid为2的Girl类型节点
match (a:Girl {__uid:"1"}),(b:Girl {__uid:"2"}),(c:Girl {__uid:"3"}) create (a)-[:Friend]->(b),(b)<-[:Friend]-(c);
# 直接创建uid为1的Boy到uid为3的Girl的单向边,并指定边的__uid为relation_1
create [:Likes {__uid:"relation_1",__usid:"1",__udid:"3",__uslabels:["Boy"],__udlabels:["Girl"]}];
- 图查询:在查询输入框中输入并执行下列查询语句。
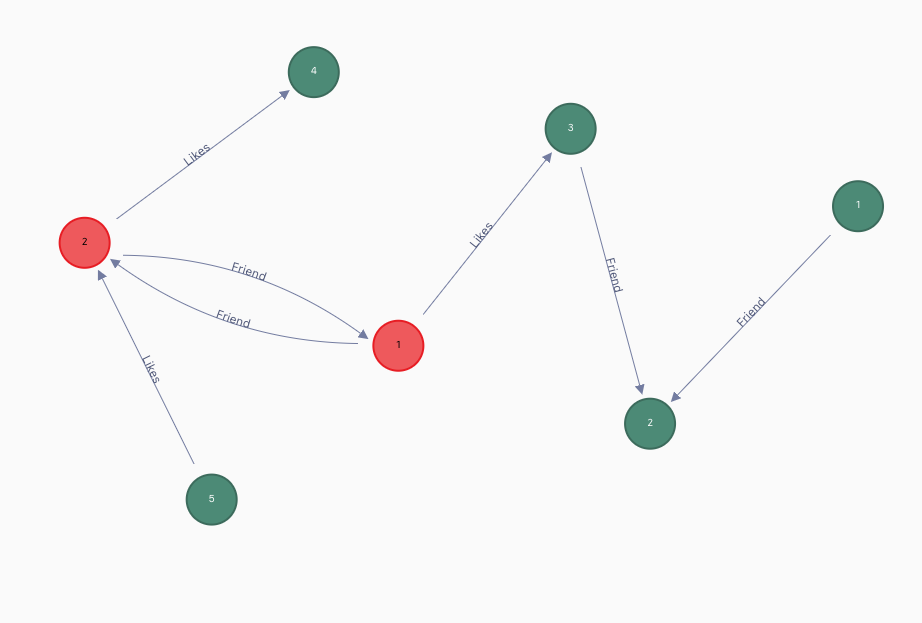
- 查询图中所有相连的点,并返回所有点和边。
- match (m)-[f]-(n) return m,f,n;
- 查询结果如图示:
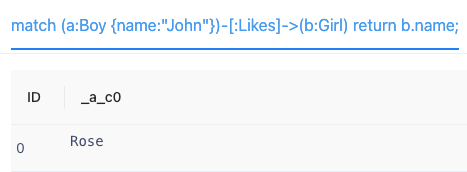
- 查询John喜欢的人的名字。
- match (a:Boy {name:"John"})-[:Likes]->(b:Girl) return b.name;
- 查询结果如图示:
- 查询John的朋友的朋友的名字。
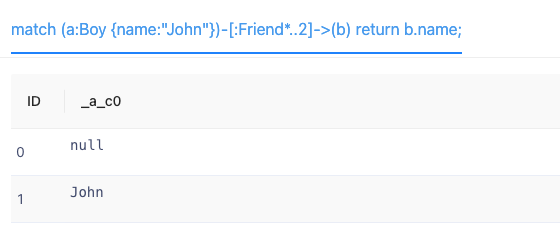
- match (a:Boy {name:"John"})-[:Friend*..2]->(b) return b.name;
- 查询结果如图所示。(该语句执行结果返回两个Boy类型的点,是因为在创建__uid为1的Boy类型点时没有对name属性赋值,所以显示null)
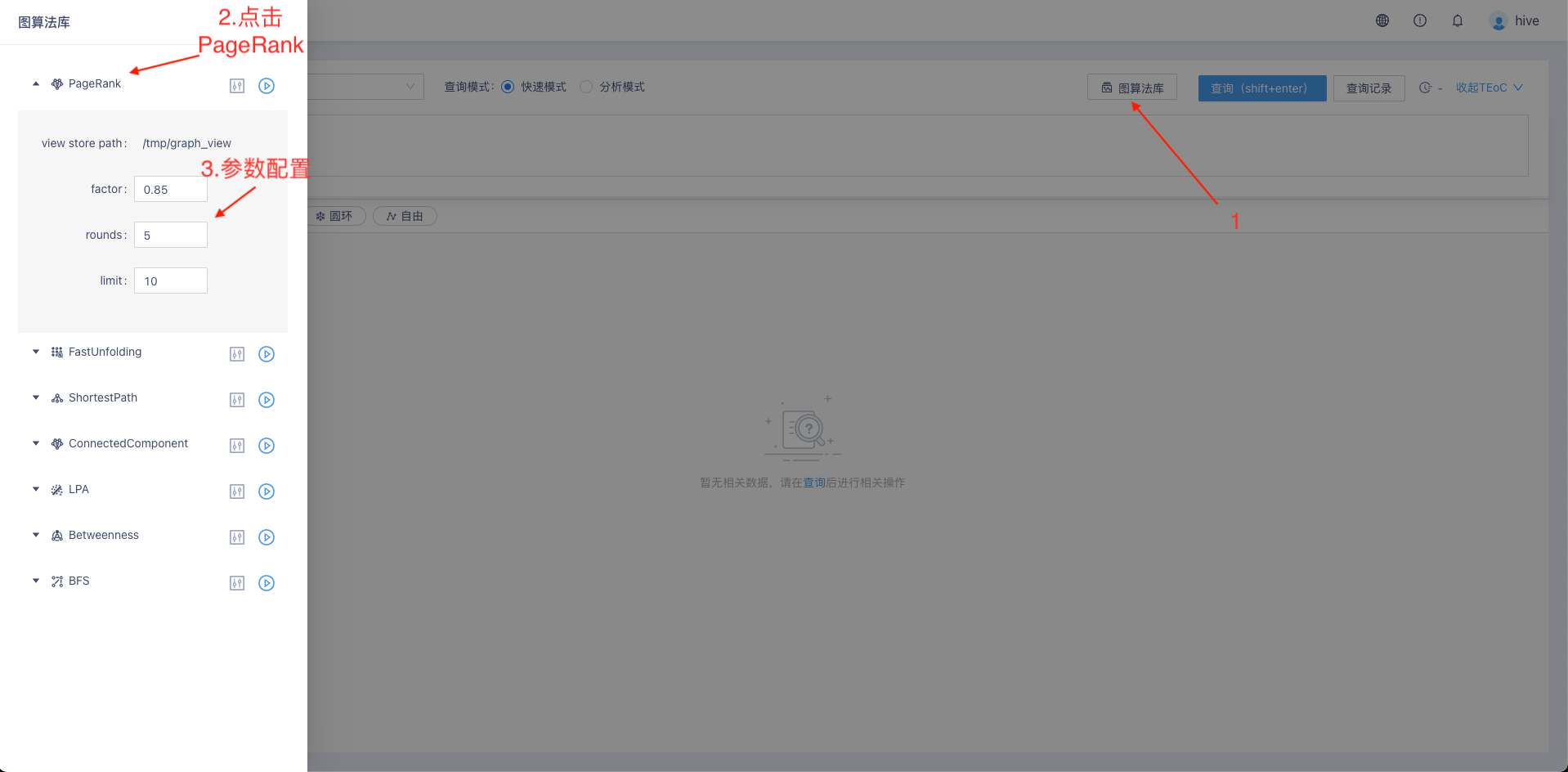
- 算法调用(以PageRank为例)
- 使用KG Explorer图算法库调用:如图示,在KG Explorer界面进入图示图算法库界面。点击 PageRank 算法,并且配置相应参数,点击 执行 按钮执行算法。
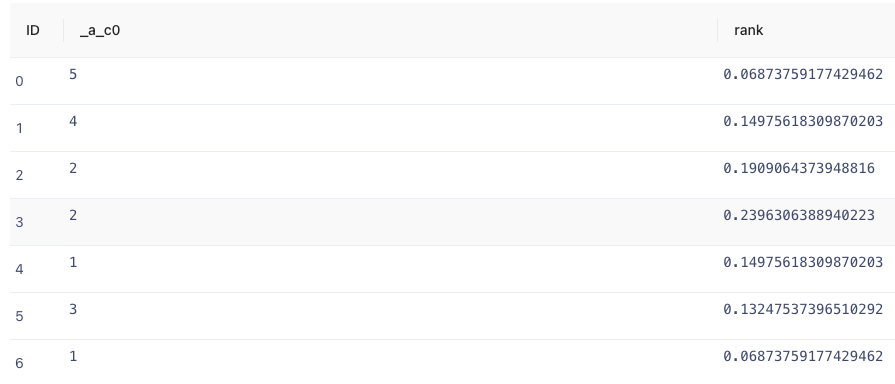
- 或使用TEoC语句调用:在查询输入框中输入并执行下列语句。
- create query temporary graph view hello_world_sample as (v) [e] with graph_pagerank(@hello_world_sample,"/tmp/hello_world_view", '{factor: 0.85, rounds: 10, limit: 10}') as unapply(vertex, rank) return node_rk_to_uid(vertex), rank;
- 执行结果如图示。
- 删除数据
- 在查询语句输入框中输入并执行下列语句进行删除操作。
- 删除name属性为Amy的点。
- match (a) where a.name="Amy" delete a;
- 删除label为Likes的边。
- match [f:Likes] delete f;
- 数据导入
- 在计算机本地准备如下所示包含点和边的CSV数据文件,并按照后文所述使用KG Explorer将数据导入至StellarDB中。(NA表示该属性空缺)
- 表 1. 点数据表
uid | ulabel | name | salary | age | single |
|---|---|---|---|---|---|
10 | Boy | Bob | 5000 | 23 | true |
10 | Girl | Beth | NA | NA | NA |
- 表 2. 边数据表
usid | uslabel | udid | udlabel | uelabel | since |
|---|---|---|---|---|---|
10 | Boy | 10 | Girl | Friend | 10 |
1 | Boy | 2 | Girl | Likes | NA |
- 登入KG Explorer,将鼠标移动至如下图所示图标 位置1 ,待菜单弹出后,点击图示按钮2 从CSV文件导入。
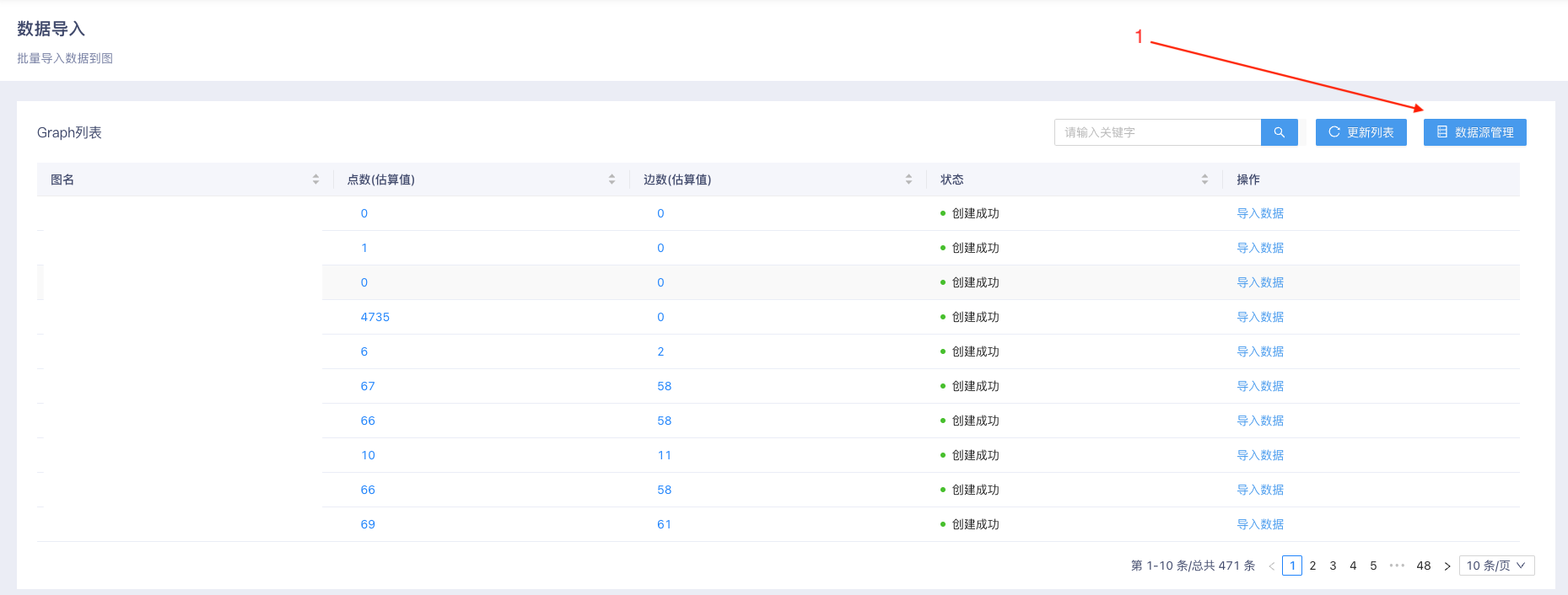
- 进入 数据导入 管理页面,点击图示 数据源管理 按钮1。
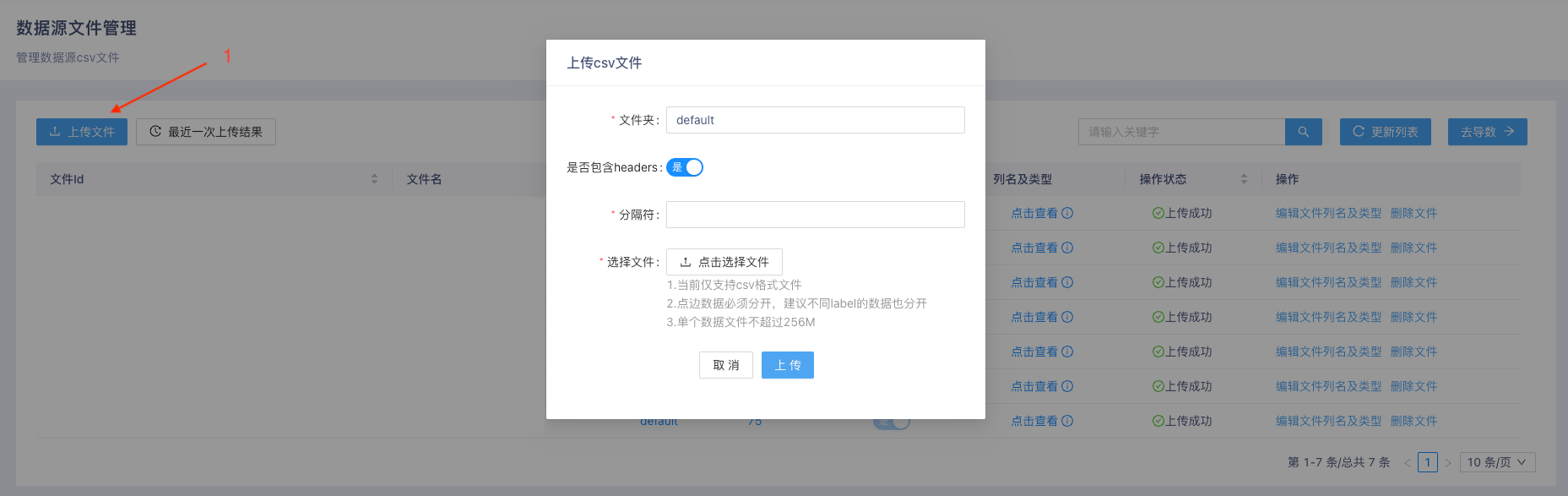
- 在 数据源文件管理 页面,点击图示 上传文件 按钮1,打开 上传CSV文件 窗口,配置 分隔符 并且选择本地上传文件。
|
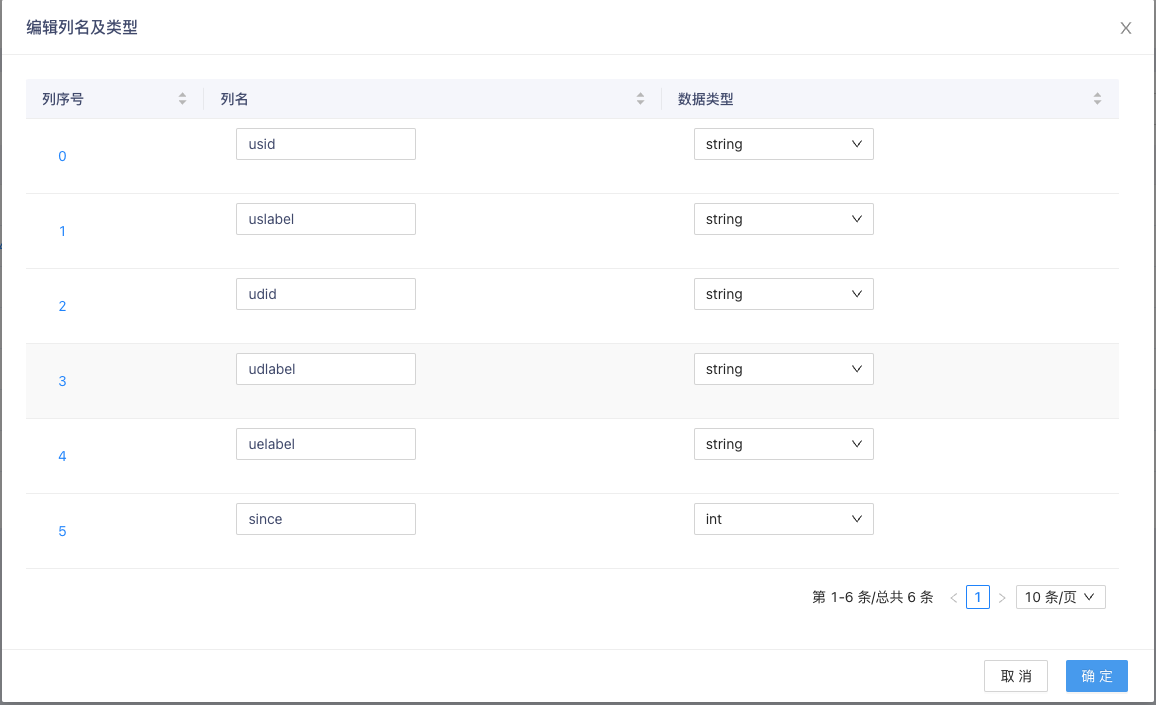
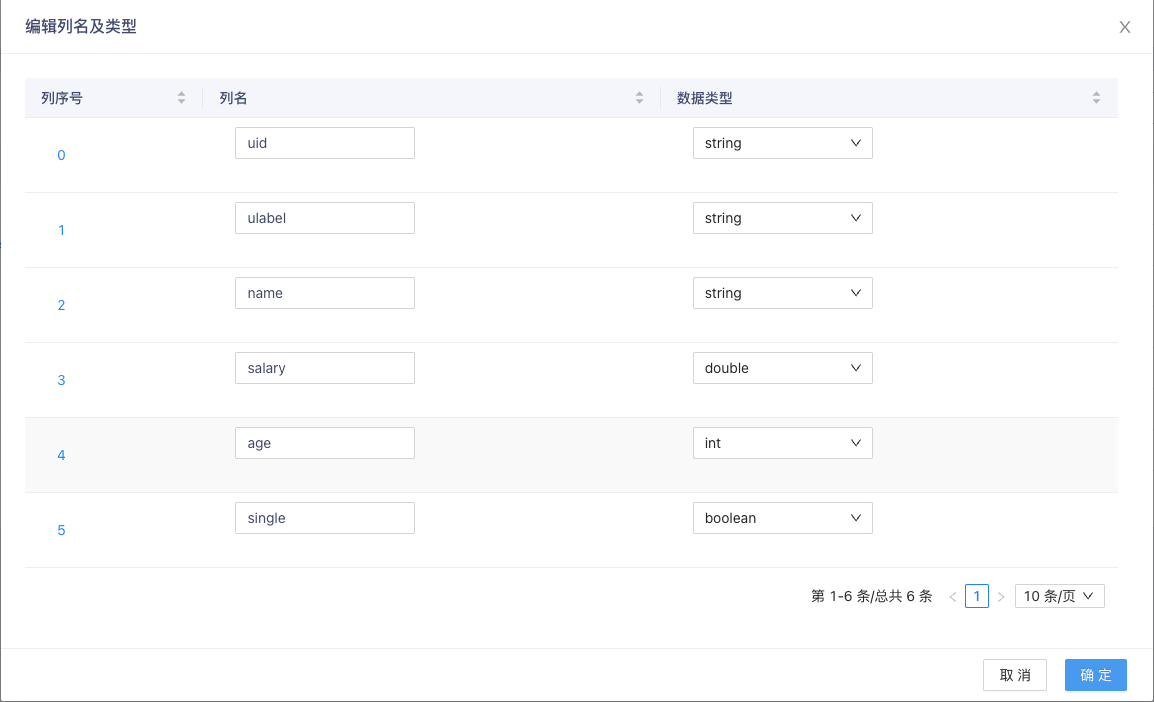
- 上传点和边的CSV文件后,点击 编辑文件列名及类型 按钮,对点和边文件中的列名和类型进行配置。本例只需要依据图创建语句修改列对应的数据类型。
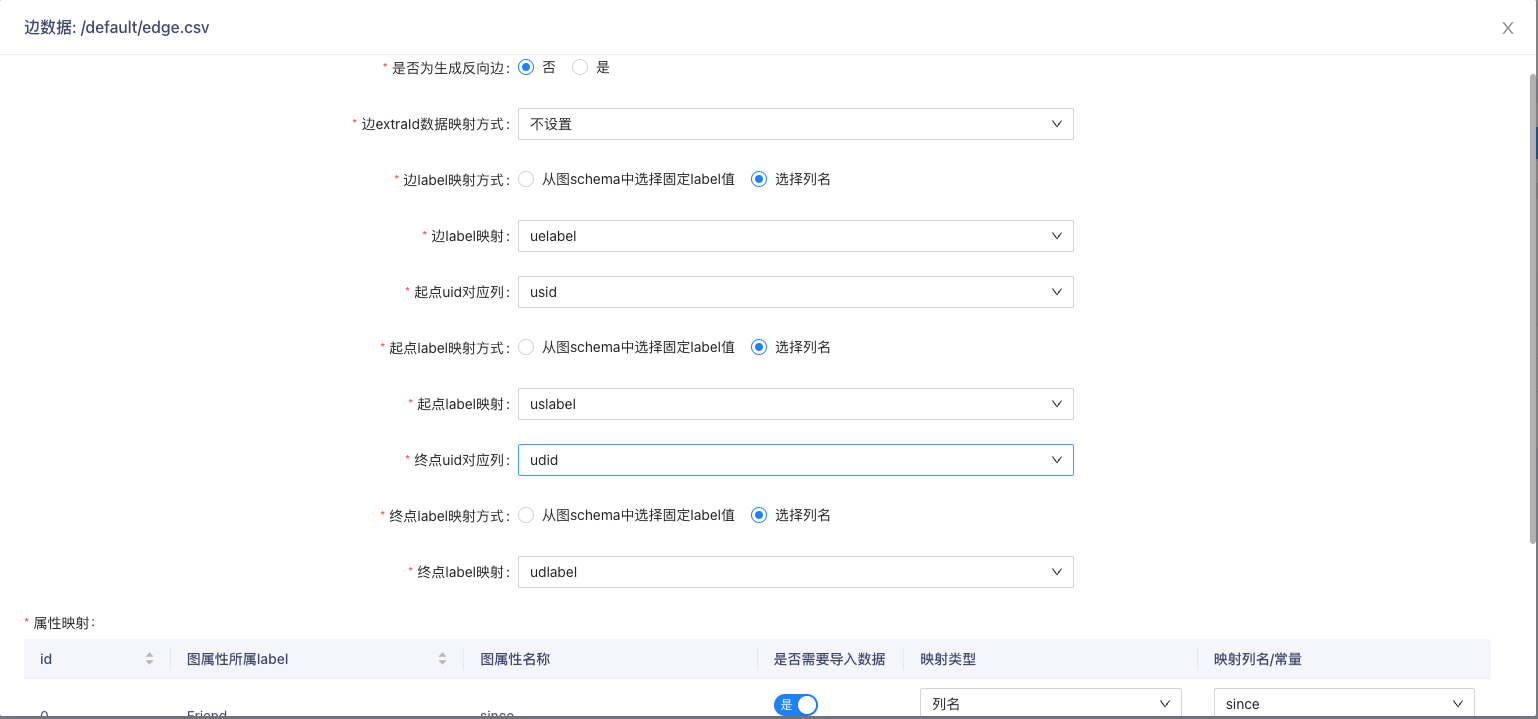
- 依据图示修改边数据表中的since列数据类型为int。
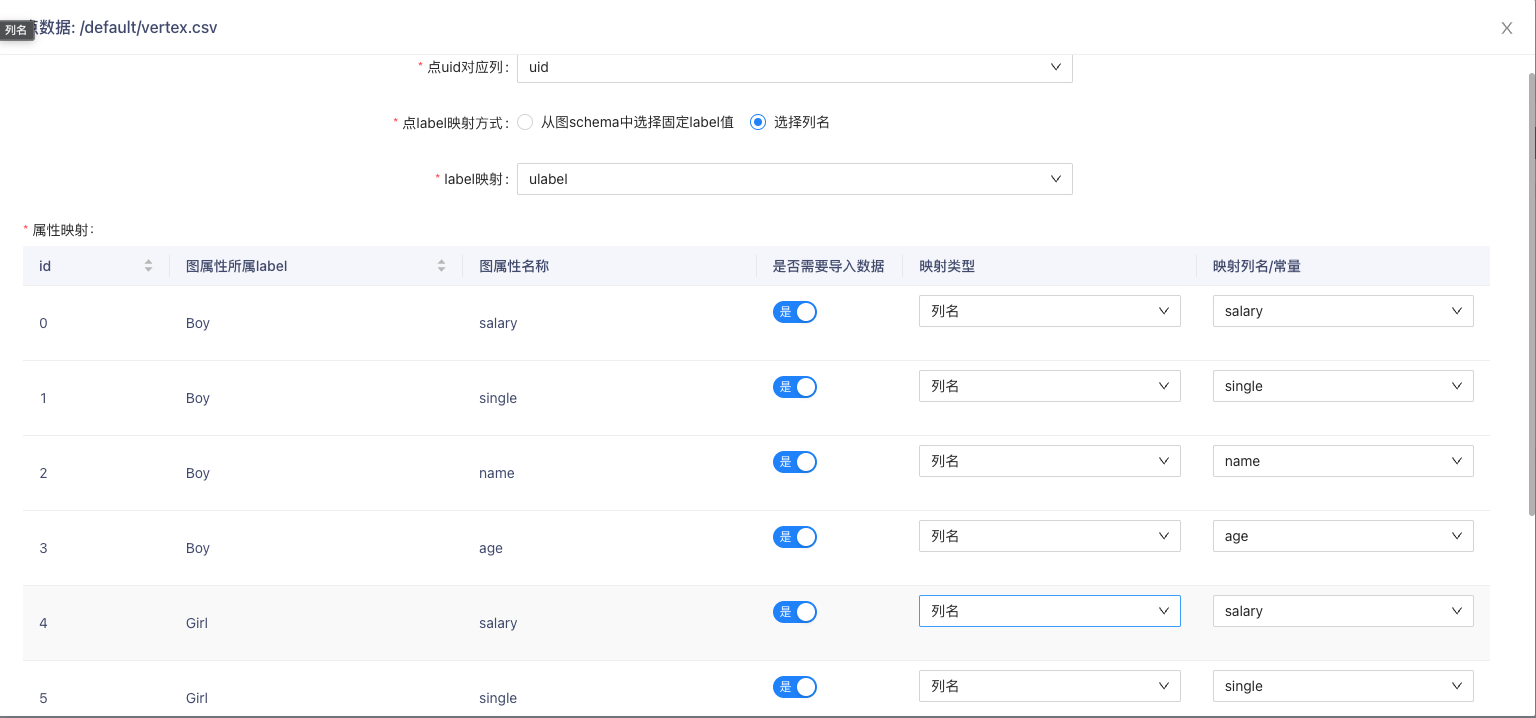
- 依据图示修改点数据表中的salary列数据类型为double,age列数据类型为int,single列数据类型为boolean。
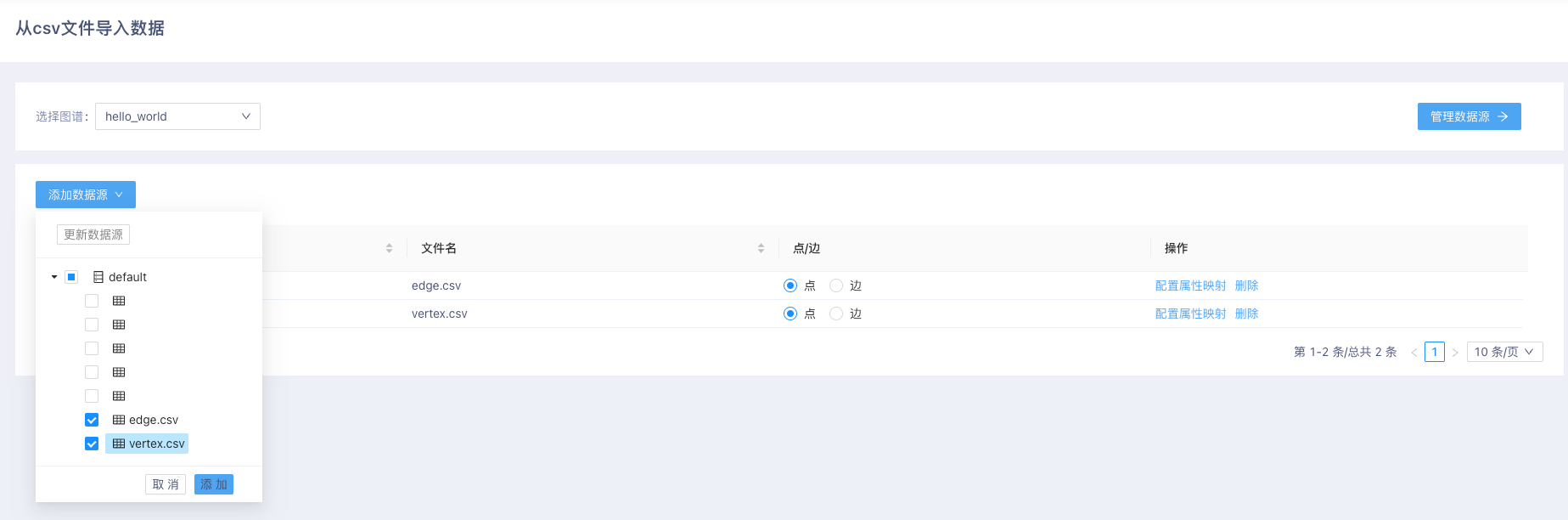
- 配置列名和列对应数据类型后,点击 去导数 按钮进入 从CSV文件导入数据 页面。点击 添加数据源 按钮,选择点、边数据表。在表单中 点/边 列点选对应的点或者边选项。
- 之后,点击 配置属性映射 进行属性配置。配置方法见下图。
- 配置边:
- 配置点:
- 应用所有配置后,在页面右下方点击 导入 按钮,等待数据导入。
- 上传点和边的CSV文件后,点击 编辑文件列名及类型 按钮,对点和边文件中的列名和类型进行配置。本例只需要依据图创建语句修改列对应的数据类型。
- 数据导出
- 这里通过在查询输入框中执行下列语句,并且将结果以CSV格式导出。
- match (n)-[f:Friend]-(m) return n, m, f;
- 在查询输入框中输入并且执行上述语句,点击图示 结果相关 按钮,鼠标移动至 导出图谱,点击 导出CSV 按钮,待文件导出完毕。

- 删除图
- 在查询输入框中输入并且执行下列语句删除"hello_world"图。
- drop graph hello_world;
4.1.2. 使用beeline构建图
在进入命令行之前,请用户确保已经在当前的操作节点上已安装TDH Client。具体步骤请参考 《TDH安装手册》。
- 进入命令行
- 在本小节中,将使用 server_ip|hostname 来指代Quark Server所在的节点名称或ip。Quark Server所在节点可以通过管理界面的Quark角色页面查看。
- 用户可以选择用不同的安全认证方式在任意一台服务器上登录beeline客户端,登陆方式如下:
安全认证方式 | 登录指令 |
没有安全认证 | beeline -u "jdbc:hive2://<server_ip/hostname>:10000/" |
LDAP认证 | beeline -u "jdbc:hive2://<server_ip/hostname>:10000/<database_name>" -n <username> -p <password> |
Kerberos认证 | beeline -u "jdbc:hive2://<server_ip/hostname>:10000/<database_name>;principal=<princpal_name>" |
TIP | (1). 使用客户端前请执行source /<tdh-client_install_path>/TDH-Client/init.sh (2). 关于安全认证的详细介绍请参考 Transwarp Guardian手册 |
- 登陆beeline客户端成功后,执行下列语句将查询语言切换为TEoC。
- config query.lang cypher;
- 执行下列语句查看是否有"hello_world"同名的图,若有,请在后续操作中按需修改查询语句,或删除原"hello_world"图,再进行后续操作。
- show stellargraphs;
- 参照前文步骤2-4进行图数据库创建和图数据的填充。这里不再赘述。
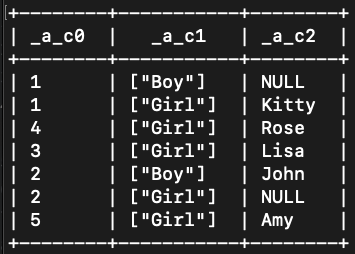
- 执行下列查询语句,校验"hello_world"点数据是否正确填充。
- match (n) return n.__uid,labels(n),n.name;
- 查询结果如图示:
- 执行下列查询,校验"hello_world"边数据是否正确填充。
- match [f] return f.__uid,labels(f),startid(f),endid(f);
- 查询结果如图示:

- 图查询
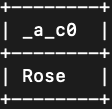
- 查询John喜欢的女孩的名字。
- match (a:Boy {name:"John"})-[:Likes]->(b:Girl) return b.name;
- 结果如图示:
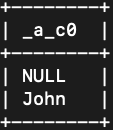
- 查询John的朋友的朋友的名字。
- match (a:Boy {name:"John"})-[:Friend*..2]->(b) return b.name;
- 结果如图示:
- 算法调用(以PageRank算法为例)
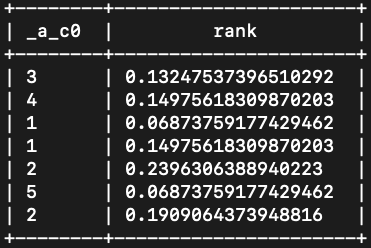
- 在beeline客户端中输入并执行下列语句调用PageRank算法,其他算法使用方法和所示方法相同。
- create query temporary graph view hello_world_sample as (v) [e] with graph_pagerank(@hello_world_sample,"/tmp/hello_world_view", '{factor: 0.85, rounds: 10, limit: 10}') as unapply(vertex, rank) return node_rk_to_uid(vertex), rank;
- 结果如图示:
- 删除数据
- 删除name属性为Amy的节点。
- match (a) where a.name="Amy" delete a;
- 删除label为Likes的边。
- match [f:Likes] delete f;
- 删除图"hello_world"
- drop graph hello_world;
