排行
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
中国数据库
向量数据库
时序数据库
实时数据库
搜索引擎
空间数据库
图数据库
数据仓库
大调查
2021年报告
2022年报告
年度数据库
2020年openGauss
2021年TiDB
2022年PolarDB
2023年OceanBase
首页
资讯
活动
大会
学习
课程中心
推荐优质内容、热门课程
学习路径
预设学习计划、达成学习目标
知识图谱
综合了解技术体系知识点
课程库
快速筛选、搜索相关课程
视频学习
专业视频分享技术知识
电子文档
快速搜索阅览技术文档
文档
问答
服务
智能助手小墨
关于数据库相关的问题,您都可以问我
数据库巡检平台
脚本采集百余项,在线智能分析总结
SQLRUN
在线数据库即时SQL运行平台
数据库实训平台
实操环境、开箱即用、一键连接
数据库管理服务
汇聚顶级数据库专家,具备多数据库运维能力
数据库百科
核心案例
行业报告
月度解读
大事记
产业图谱
我的订单
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
资讯
活动
大会
课程
文档
排行
问答
我的订单
首页
专家团队
智能助手
在线工具
SQLRUN
在线数据库即时SQL运行平台
数据库在线实训平台
实操环境、开箱即用、一键连接
AWR分析
上传AWR报告,查看分析结果
SQL格式化
快速格式化绝大多数SQL语句
SQL审核
审核编写规范,提升执行效率
PLSQL解密
解密超4000字符的PL/SQL语句
OraC函数
查询Oracle C 函数的详细描述
智能助手小墨
关于数据库相关的问题,您都可以问我
精选案例
新闻资讯
云市场
登录后可立即获得以下权益
免费培训课程
收藏优质文章
疑难问题解答
下载专业文档
签到免费抽奖
提升成长等级
立即登录
登录
注册
登录
注册
首页
专家团队
智能助手
精选案例
新闻资讯
云市场
7
微信扫码
复制链接
新浪微博
分享数说
采集到收藏夹
分享到数说
首页
/
如何才能看明白AWR报告中的数据
如何才能看明白AWR报告中的数据
白鳝的洞穴
2021-05-01
6811
搞ORACLE数据库的必须会看AWR报告,现在的AWR报告内容越来越详细,也越来越易懂了。一些其他的数据库,也在学习Oracle的AWR报告,华为的Gaussdb/opengauss数据库提供WDR报告,瀚高数据库也提供了一个类似的报告。针对某一段时间内数据库的一些核心状态指标按照数据库内部运行的一些分类方法进行展示。
这些报告都是无论你的水平多高,能力多强,都能从AWR报告中看到一些你能看懂的东西。为了更好的让人理解这些数据,Oracle还搞了一个ADDM报告,自动的从AWR数据中发现一些问题,并以报告的形式显示出来,让使用者更好的理解这些数据库状态数据。ADDM报告的内容在12c数据库中已经集成到了AWR报告中。
实际上AWR报告所能表现出来的数据库的情况,远比我们能解读出的多。十多年前,老白经常通过AWR帮用户分析系统中可能存在的隐患,寻找优化改进方案(当然那时候AWR还比较少,更多的是STATSPACK报告,二者的内容差别不是很大)。那时候认真解读一份AWR报告大概需要4-8个小时,期间可能还会和客户要一些额外的数据,从而确定发现的问题。
可能有朋友会觉得惊讶,一份AWR报告能看上一天,这是什么鬼?实际上,从报告的头开始,AWR里就蕴含了十分丰富的信息。如果我们能够沉下心来解读这些报告数据,可能会有很好的发现。
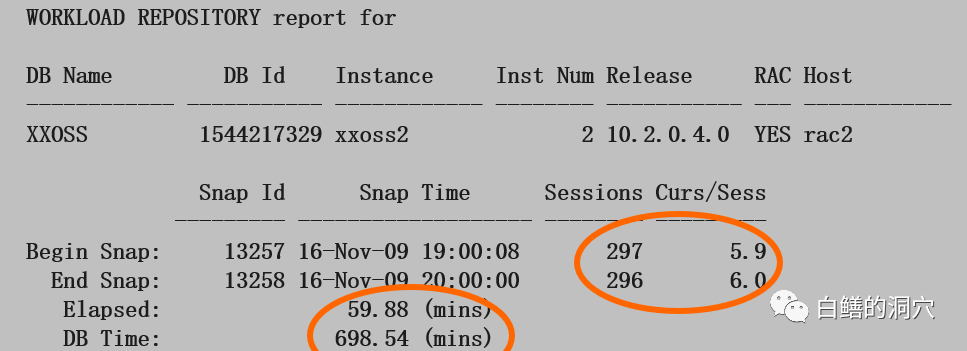
这仅仅是AWR的头,其中就蕴含了十分丰富的信息。不说前面的数据库版本,是否RAC,仅仅从老白画圈的这三个数据,就蕴含了十分丰富的内容。Sessions的数据是报告的两个采样点的会话数量,curs/sess是每个SESSION平均打开的CURSOR的数量。从这两个指标的绝对值以及两个SNAP之间的变化就可以看出会话变化的一些细节。会话数是高是低,变化趋势等信息。而每个会话打开的CURSOR数量则说明会话执行SQL的情况,以及可能对共享池产生的影响,同时可以用于分析OPEN_CURSOR参数与session_cached_cursors参数是否合理。也可以看到数据库在这个阶段里的负载的情况以及这个报告的分析时段起始与结束时负载的变化情况。
DB Time是另外一个十分重要的指标,DB TIME与ELAPSED的比值可以看出系统的负载或者等待事件的情况。这个值的高低和活跃会话的数量也有十分大的关系。老白贴出的案例中大概是10左右。到底这个值是多少才是合理的?这个恐怕要和你的系统的基线有一定的关系了。如果你是经常维护这套系统,那么你可以每天都关注下业务最高峰时候这个指标的情况,如果这个比值出现了较大的偏差,那么你就需要认真的阅读这份报告,找到为什么会出现这样的异常了。
我们再继续看看下面的数据,关于CACHE的数据,大家可能觉得没那么重要。实际上我们看看buffer cache和shared pool size在BEGIN END两个SNAP的差异,也能发现一些问题:
上面的案例是没变化,从中看不出异常来,如果BEGIN/END有差异,而且差异比较大,那么我们就要关注SGA的性能是否存在问题了,是否存在SGA抖动了。11g以后的版本的AWR报告中就有SGA RESIZE的情况,你可以在后面去查看,如果是10g的数据库,那么,可以到相关的视图中国去查看SGA RESIZE的情况。
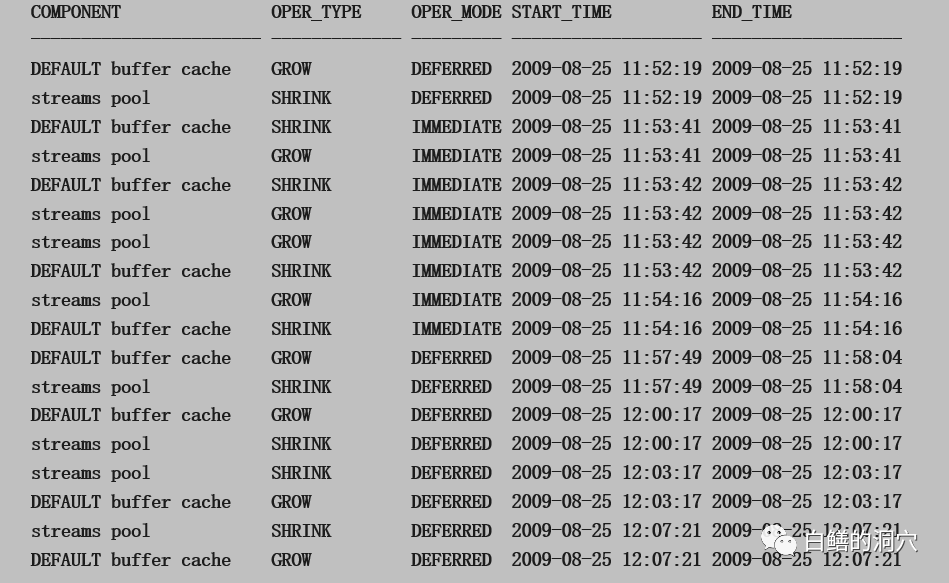
如果出现下面的情况:
你就要注意了,要查查SGA出现这样的变化的原因是什么。上面的例子很可能是由于STREAMS复制,EXPDB等操作导致的STREAMS POOL的增长。
今天我们没办法完整的介绍如何去解读一份AWR报告,不过在这里,老白也表达了一个观点,就是要通过我们所掌握的基线去分析某个指标是不是合理的,如果某个指标不合理,那么就需要把这个指标相关的AWR数据都找出来,进行仔细的分析,验证这个问题,或者更深入的去查找指标异常的原因。要做到这一点就需要你不断地去积累运维经验。如果你是一个企业的DBA,那么你可以对你的企业的数据库进行建模,形成着一些关键指标的模型,通过对这些模型变化的监控,你可以发现系统是否出现了一些异常。而再通过你对这些异常日常处理的经验,就可以对这些异常进行下钻分析,从而找到系统的隐患。
D-SMART大师问诊工具就是根据这个思路开发的,不过D-SMART并不基于AWR的数据(AWR的采样点为1小时或者30分钟,采样周期太长),而是基于一些1分钟,3分钟,5分钟、10分钟的采样数据进行分析,同时把类似AWR的数据对数据库的总体评价分为了操作系统、IO、并发、负载、性能、集群、总体健康等数个维度建立了一个健康模型,通过健康模型来提醒运维人员系统可能存在隐患,然后针对发现隐患的维度,收集相关的数据进行综合分析和问题溯源。通过这种基于运维知识与基线的自动化的分析手段,帮助DBA去监控这些系统,让DBA不用盯着这些系统,提高运维效率。前几天我们帮一个金融用户对D-SMART中采集的近一个月的数据进行分析,完成了一次远程巡检。一个DBA对50多套数据库,100多个实例的数据进行分析,花了2天时间,找到了43大类的数百个问题,并完成了问题溯源,大部分问题都提供了优化方案,可以用于系统优化与改进。
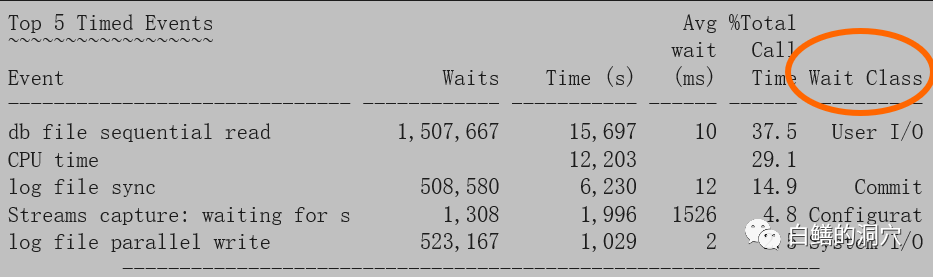
无论怎么做,要想实现人工监控还是自动化监控,都基于一个重要的东西,那就是指标与基线。这个基线可能在DBA的心里,实际上,更好的做法是在一个数据库中,这样我们可以通过统计学的方法去计算各种统计值,比如最小,最高,平均,方差,标准差,稳定性等。通过同一个数据库实例的基线数据对比,就能更好的反映出系统存在的问题。如果当前没有某个实例的历史数据,那么我们就需要根据“常识基线”来确定某个指标是否正常。比如下面的数据:
我们可以看出,db file sequential read的平均值是10毫秒,有点高,但是还算正常,是处于正常值的高值,可能IO对数据库有一定的影响,但是不一定致命。而中间的Streams capture:waiting for 这个指标是异常的,这个数据与上面的SGA RESIZE出于同一份AWR报告,也就说明了,当时可能是STREAMS捕获进程存在一些问题,导致了SGA RESIZE,抑或是SGA RESIZE导致了STREAMS捕获进程产生了一些不必要的等待。这样我们就又有了一个相对明确的分析方向了。
数据库
文章转载自
白鳝的洞穴
,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
评论
领墨值
有奖问卷
意见反馈
客服小墨