





图编辑距离(GED)是一种经典的图相似度度量指标,可以延伸到许多实际应用中。我们提出了一种新的方法Noah,它将A*搜索算法和图神经网络相结合,优化了A*搜索算法的搜索空间和搜索方向,以更有效、更智能的方式计算近似图编辑距离。实验结果证明了我们的方法在多个任务上的有效性,并表明我们的方法明显优于现有方法。


问题背景
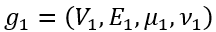 和
和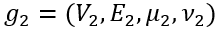 之间通过点和边的insert、delete、substitute操作完成相互转换所需要的最少操作数。GED问题是一个NPC问题,同时也是许多图上应用问题,比如图分类问题、图匹配问题、图相似度搜索问题的核心操作。
之间通过点和边的insert、delete、substitute操作完成相互转换所需要的最少操作数。GED问题是一个NPC问题,同时也是许多图上应用问题,比如图分类问题、图匹配问题、图相似度搜索问题的核心操作。
对于上图所示的样例中的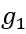 和
和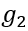 ,图编辑距离为3,可以通过上半部分的编辑路径和下半部分的结点替换来表示。值得一提的是,虽然编辑路径和结点替换不是一一对应的关系(编辑路径可以得到唯一的结点替换,但是结点替换无法得到唯一的编辑路径),但是最优编辑路径和最优结点替换(均不唯一)是可以一一对应的。
,图编辑距离为3,可以通过上半部分的编辑路径和下半部分的结点替换来表示。值得一提的是,虽然编辑路径和结点替换不是一一对应的关系(编辑路径可以得到唯一的结点替换,但是结点替换无法得到唯一的编辑路径),但是最优编辑路径和最优结点替换(均不唯一)是可以一一对应的。
之前的方法以及相应的问题都已经在图的编辑距离计算这篇文章中进行了阐述,(详见:论文导论|图的编辑距离计算)因此我们在这篇文章中主要介绍我们提出的方法。
方法概述

Noah工作流程图
上图是我们的方法Noah(Neural-optimized A* search algorithm的缩写)的工作流程图,它主要包括了训练和测试两部分。在训练部分,输入的训练数据(图对,graph pairs)首先由精确的图编辑距离计算算法得到预训练信息,这些预训练信息包括精确的图编辑距离以及对应的编辑路径。这些预训练信息会被用于模型训练。在测试部分,输入的测试数据(图对)会进入A*-Beamsearch算法,同时在初始化时,A*-Beamsearch算法的beam size由模型根据输入数据预测得到,并且在每一轮算法迭代的过程中,会对OPEN集合中的每一个路径预测他们的估计代价h(p)。经过多轮迭代之后,最终可以得到近似的图编辑距离。值得一提的是,在训练部分的训练数据都是小的图(结点数小于20),而在测试部分使用的测试数据可以是大图(结点数可以达到数百)。
网络结构

GPN架构图
上图是Noah中的核心部件,图路径网络框架(GPN,Graph Path Networks)。它主要分为三个模块,分别是预训练模块、图嵌入模块以及学习模块。预训练模块计算预训练信息(包括精确的图编辑距离和图编辑路径),然后根据预训练信息对数据进行增广,将一个图对变为一组子图对。图嵌入模块基于已有的图同构网络(Graph Isomorphism Network,GIN)进行设计。先将每个子图的结点转换为一个向量,这个向量聚集了它周围的邻居信息,同时在聚集的信息中我们利用了预训练信息,对结点替换这一信息进行了加强。在那之后,我们引入了一个注意力机制来得到最终的图嵌入信息。在学习模块,我们设计了适当的结构使得模型能够预测beam size和估计函数h(p)。接下来我们详细描述这三个模块的设计。
在预训练模块,首先我们考虑的不仅是图对之间的真实的图编辑距离,而且我们考虑到了精确算法中的编辑路径这一有效信息。考虑这种信息的主要原因是,我们可以通过使用A*算法得到的结点替换信息,将原来的图对,转换为一组子图对。因为我们在A*算法中需要对子图对的编辑距离进行估计,因此子图对的编辑距离信息相比于完整的图对我们的问题来说更加有效。同时,注意到对于同一个图对输入,A*算法也许能够得到多个最优解,我们只取其中一个最优解的信息作为我们的预训练信息。紧接着,我们根据A*算法中得到的编辑距离和编辑路径,根据编辑路径中的每一步变换信息将图对拆解成为一组子图对和他们对应的编辑距离,并且为了使得不同结点数量的子图对能够相互比较,进行了归一化处理。具体来说,模型的损失函数变化为

其中分子表示对每一个子图对都考虑他们和真实值之间的平方误差,分母表示对结点数量进行归一化。值得一提的是,我们选择结点替换信息,而不是对应的编辑路径信息(六个基本操作的序列化组合),两者的对应关系可由下图表示出来。之所以这么选择出于两方面考虑,第一,结点替换信息更符合A*算法的要求;第二,相比于编辑路径信息,结点替换信息拆解的子图对数量更小更有意义,有助于减少计算开销。
然后,我们考虑到,对于整体算法而言,每一次结点替换对于整体路径选择的作用并不是完全均衡的,也就是说一定会存在某些点的替换能够对于最终路径的选择起到更关键的作用,因此我们引入了注意力机制来给每一步结点替换赋予权重,权重的大小则由他们对整体的损失函数的影响来决定。具体来说,由下面的注意力函数来表示:



通过上述注意力机制,我们能够在最优的编辑路径中发现对最终路径的选择最重要的结点,使得我们对于估计函数h(p)的预测更加准确。
在图嵌入模块,首先我们使用了图同构网络层(Graph Isomorphism Network),它已经在理论上被证明是最强大的图神经网络之一。具体来说,它首先会对输入的特征进行初始化,使得它成为一个能够表示结点信息的向量,然后通过下面的表达式来对表示结点信息的向量进行更新:

然后我们在结点信息进行更新的过程中加入了图交叉信息。具体来说,我们将之前预训练的结点替换信息转化为一个0/1矩阵,每一个结点都会和另一个图内对应的结点进行替换,同时也会将替换结点的信息用于结点信息的更新。因此交叉信息可以表示为下式:

这样结点信息的更新就可以表示为:

在结点更新的过程中加入图交叉信息主要有以下两个主要的优势。第一,图交叉信息实际上表示的是结点和替换结点的差异,而这种差异会在网络训练迭代的过程中不断被放大,这样会使得模型对于这样的差异更加敏感,也就更好的学习到结点替换的策略。第二,图同构网络有一个缺点,就是当两个结点他们的邻居信息完全相同时,可能会使得整个网络无法收敛,而加入了图交叉信息之后,他们两个结点的替换结点一定不会是一样的,这样就可以使得他们在结点信息更新的时候不再是“镜像”的,这样我们的方法就能够收敛到一个可能的解。
接下来,我们需要将结点的嵌入信息转换为图的嵌入信息,我们没有简单的使用求和或者平均,而是使用了加权求和的方式。由于之前将图对转换为一组子图对,而这些子图对不一定是连通图,因此需要一个超点来将他们连通起来。这个超点在所有的子图中都有同样的标签,这样网络模型就能够识别出这样的超点,同时超点也能够在多次迭代之后提供子图的全局结构和特征信息。因此我们在加权求和的时候,采用了结点和超点的相似度来给他们赋予权重,具体表示为下式:

其中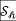 表示为一个相似度函数,可以是欧氏距离、余弦距离或者是通过一个全连接网络得到的相似度。通过这样的方式,我们就得到了最终的图嵌入表示。
表示为一个相似度函数,可以是欧氏距离、余弦距离或者是通过一个全连接网络得到的相似度。通过这样的方式,我们就得到了最终的图嵌入表示。
最后,在学习模块,我们主要需要对两部分进行预测,一个是beam size,另一个就是h(p)。我们使用了一个全连接网络对beam size进行预测,全连接网络的输入除了两个图的图嵌入信息之外,还有用户设置的one-hot编码信息,用户设置主要包括可允许的误差以及算法运行时间。在对h(p)预测的过程中,我们使用了神经张量网络(Neural Tensor Networks,NTN)来进一步的对两个图的交互进行建模,并最终通过一个全连接网络得到最终的h(p)。
实验验证
在实验方面,我们在AIDS,GREC和IMDB三个数据集上,比较了Noah和传统方法以及端到端的学习方法的性能。实验结果如表所示,可以看到,我们的方法在三个数据集上都能够取得最好或者第二好的表现。

另外在下两张表分别表示的扩展能力(从小图到大图的扩展)和学习能力(预测之前从来没有见过的样例)的实验上,我们的方法显著优于已有的端到端的学习方法。

下图的案例分析也能够表明,我们的方法相比于传统A*算法能够更加注意到图的结构信息,从而选取到更优的图编辑距离和编辑路径。

案例分析
更多的实验结果和分析,欢迎大家详细阅读论文。
论文贡献
我们是第一个提出使用神经网络优化传统A*算法来计算图编辑距离的,我们的方法noah在搜索方向和搜索空间上都对A*算法进行了优化。 我们进一步的提出了图路径网络,它通过引入基于注意力机制的预训练编辑路径信息以及其对应的图交叉信息来更好的对A*算法进行优化。 我们将我们的方法和已有方法在多个任务上进行了比较,实验结果表明我们的方法明显优于已有的其他方法。
 相 关 链 接
相 关 链 接论文导读 | 大图的普遍性以及图处理面临的挑战:一个扩展调查
北京大学重庆大数据研究院招聘 图数据库与知识图谱系统研发和工程人员


