





仿佛是一夜之间,ChatGPT横空出世,突然爆火,并且迅速火遍全球,在中外各大媒体平台掀起了一阵狂热之风。短短4天时间,ChatGPT用户量便达到百万级,注册用户之多一度导致服务器爆满。各行各业各路资本都争相入场、纷纷跟进,各路玩家对AI的投资布局狂潮盛况空前。在推出仅仅2个月后,ChatGPT的月活跃用户就突破了1个亿,用户增长速度在消费级应用里可以说是前无古人后无来者。

作为眼下当之无愧的流量收割机,ChatGPT不仅上知天文下知地理,博古通今学贯中西,还能客串编剧、作曲、码农…… 功能如此强大,以至于马斯克都认为,“我们离强大到危险的AI不远了”。
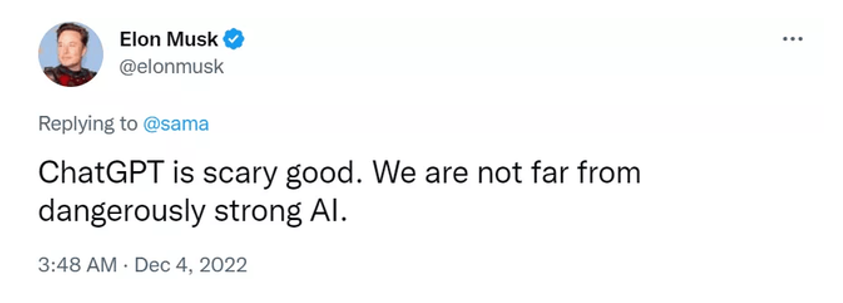
然而,即便是scary good的ChatGPT也仍然不是无所不能的,因为它只是一个泛用型聊天机器人——博,却不精。这就决定了它的专业知识是有限的,必定无法回答一定深度的专业问题。

准备工作
申请API keys
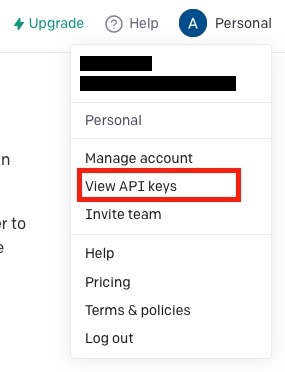
注册OpenAI账号后,需要用户手动申请API keys。通过下方入口前往
❗注意:务必牢记生成的密钥,后续如果忘记了就只能再重新申请一个了。
搭建本地环境
官方推荐使用Python或者node.js作为API调用的后台工具。考虑到方便进行后续安装cli的工作,这里我们推荐使用Python。
API测试
安装openai的python库:
pip install openai
然后在本地用python调用即可:
import os
import openai
openai.organization = "ORGANIZATION_CODE"
openai.api_key = os.getenv("OPENAI_API_KEY")
openai.Engine.list()
使用以上代码就可以获得所有开放给API用户的模型列表。
openai.Completion,之后在
engine处输入上面获得模型名字之一,将问题填入
prompt即可,之后就可以跑下python脚本调用API啦!
completion = openai.Completion.create(
engine="ENGINE_NAME",
prompt="PROMPT",
max_tokens=300,
temperature=0)
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
{"prompt": "<prompt text>", "completion": "<ideal generated text>"}
...
转成相应格式后可以借助OpenAI CLI工具转化为上传所需要的具体格式:
openai tools fine_tunes.prepare_data -f <LOCAL_FILE>
之后选择上一条命令生成的文件和模型即可训练:
openai api fine_tunes.create -t <TRAIN_FILE_ID_OR_PATH> -m <BASE_MODEL>
如果中间网络连接断开则可以用下列命令跟进进度:
openai api fine_tunes.follow -i <YOUR_FINE_TUNE_JOB_ID>
在完成训练后会收到一个模型id,将id和问题作为参数输入cli即可得到答案查看效果:
openai api completions.create -m <FINE_TUNED_MODEL> -p <YOUR_PROMPT>
大功告成!🎉🎉🎉
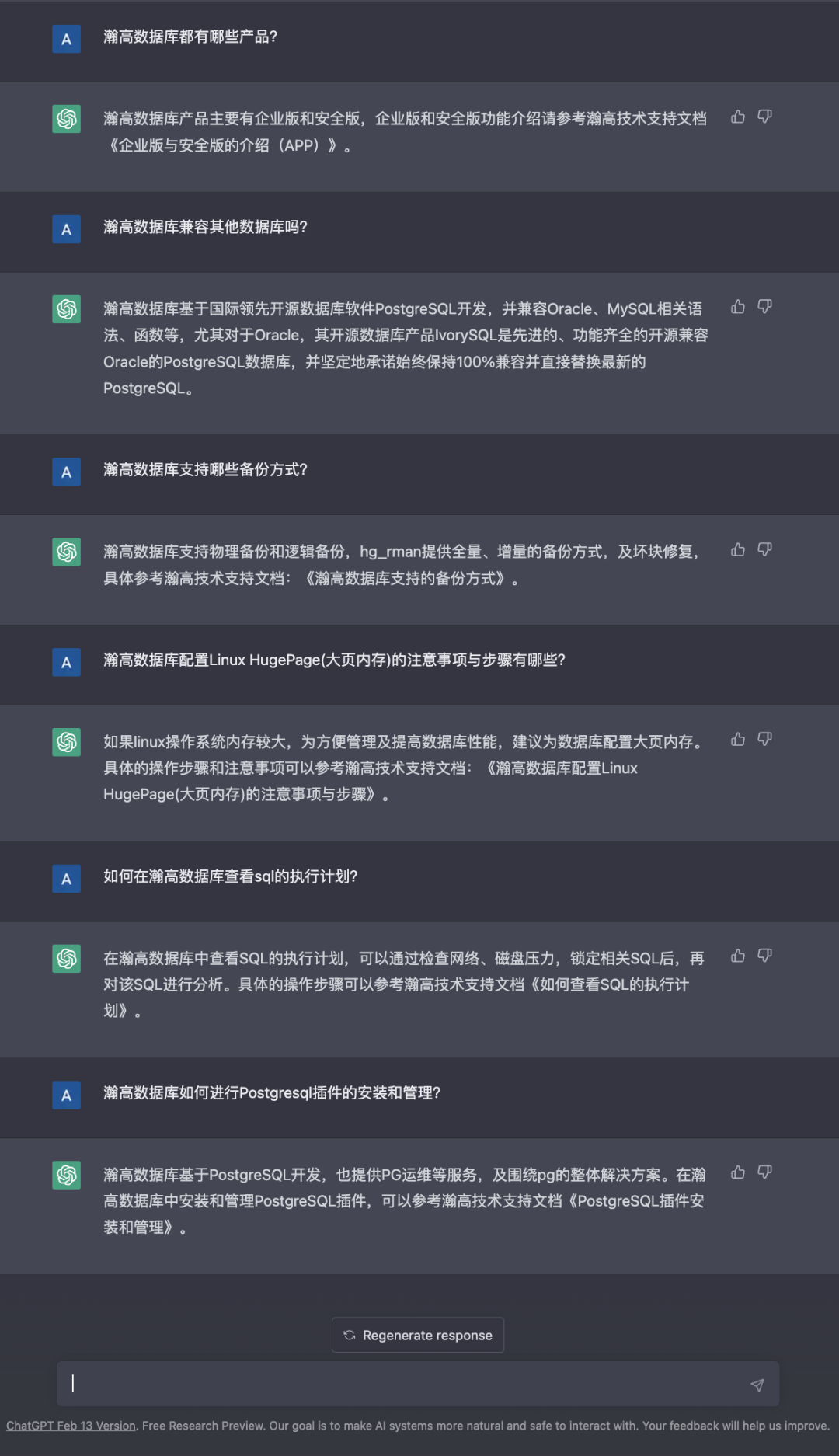
在OpenAI官方给出cookbook中也明确提到过一些修正方法:
虽然目前自定义模型并不是真正意义上的完全理解语言逻辑,但是这样的使用方式极大提高了回答的准确性。比如下图就是用HGDB信息提前输入后获得的对话结果:
结语
OpenAI API官方文档
OpenAI Github案例

