




七、Oracle集群管理软件的启动顺序
(一) OHAS层面
该层面主要负责启动集群的初始化资源和进程,具体的过程如下。
1. /etc/inittab中的以下行被调用
h1:35:respawn:/etc/init.d/init.ohasd run >/dev/null 2>&1 </dev/null
2. 操作系统进程init.ohasd run被启动,该进程负责启动ohasd.bin守护进程
[grid@test1 rc3.d]$ ps -ef | grep hasd
root 2720 1 0 Nov18 ? 00:00:00 /bin/sh /etc/init.d/init.ohasd run
而init.ohasd在启动ohasd.bin守护进程之前需要执行以下的操作。
1) 集群自动启动是否被禁用
2) GI home所在文件系统是否被正常挂载
3) 管道文件(npohasd)是否能够被访问
[grid@test1 .oracle]$ ls -l /var/tmp/.oracle
total 4
srwxr-xr-x 1 grid oinstall 0 Nov 26 09:30 mdnsd
-rw-r--r-- 1 grid oinstall 6 Nov 26 09:30 mdnsd.pid
prw-r--r-- 1 root root 0 Oct 3 2013 npohasd
对于ohasd.bin它需要经过以下过程才能够正常运行。
- 确认OLR存在而且能够被正常访问
[grid@test1 cdata]$ pwd
/u01/app/11.2.0/grid/cdata
[grid@test1 cdata]$ ls -l
total 266772
drwxr-xr-x 2 grid oinstall 4096 Sep 19 10:45 localhost
drwxr-xr-x 2 grid oinstall 4096 Nov 16 13:18 test1
-rw------- 1 root root 272756736 Nov 29 01:52 test1.olr
- ohasd所使用的套接字文件(socket file)存在
[grid@test1 cdata]$ ls -l /var/tmp/.oracle/*HAS*
srwxrwxrwx 1 root root 0 Nov 26 09:30 /var/tmp/.oracle/stest1DBG_OHASD
srwxrwxrwx 1 root root 0 Nov 26 09:30 /var/tmp/.oracle/sOHASD_IPC_SOCKET_11
-rw-r--r-- 1 root root 0 Nov 26 06:54 /var/tmp/.oracle/sOHASD_IPC_SOCKET_11_lock
srwxrwxrwx 1 root root 0 Nov 26 09:30 /var/tmp/.oracle/sOHASD_UI_SOCKET
- ohasd对应的日志文件能够被正常访问
[grid@test1 ohasd]$ pwd
/u01/app/11.2.0/grid/log/test1/ohasd
[grid@test1 ohasd]$ ls -l
total 67652
......
-rw-r--r-- 1 root root 6028807 Nov 29 05:12 ohasd.log
-rw-r--r-- 1 root root 21456 Nov 26 09:30 ohasdOUT.log
如果大家发现init.ohasd进程没有出现,那么说明操作系统进程没有成功地调用/etc/init.d/init.ohasd run命令,比较常见的原因可能如下。
原因1:操作系统运行在了错误的runlevel(可使用who–r查看当前的运行级别)。
原因2:/etc/rc
原因3:GI的自动启动功能被关闭(crsctl disable crs)。
而对应的解决办法如下。
办法1:重新启动操作系统到正确的运行级别。
办法2:手动运行init.ohasd脚本(例如:#nohup/etc/init.d/init.ohasd run&)。
办法3:启动GI自动启动功能(crsctl enable crs)。
如果大家发现init.ohasd已经启动,但是ohasd.bin没有被正常启动,比较常见的原因如下。原因1:OLR不能被访问或者已经丢失。例如:
2010-01-24 22:59:10.470: [default][1373676464] Initializing OLR
2010-01-24 22:59:10.472: [OCROSD][1373676464]utopen:6m':failed in stat OCR file/disk /u01/app/11.2.0/cdata/test1.olr,errno=2,os err string=No such file or directory
2010-01-24 22:59:10.472: [OCROSD][1373676464]utopen:7:failed to open any OCR file/disk,errno=2,os err string=No such file or directory
2010-01-24 22:59:10.473: [OCRRAW][1373676464]proprinit: Could not open raw device
原因2:ohasd对应的套接字文件无法访问或者已经丢失。
原因3:ohasd对应的日志文件无法被访问,例如:
Feb 20 10:47:08 test1 OHASD[9566]: OHASD exiting; Directory /u01/app/11.2.0/log/test1/ohasd not found.
而对应的解决办法如下。
办法1:从OLR备份中恢复OLR(默认情况下,在集群安装结束后,OLR会备份到
#<gi_home>/bin/ocrconfig -local -restore <OLR备份文件>
办法2:重新启动GI,以便重建套接字文件。
#<gi_home>/bin/crsctl stop crs #<gi_home>/bin/crsctl start crs
办法3:修改ohasd日志文件的属性,确认它能够被访问到。当然,如果遇到了其他问题,那就需要查看ohasd.log来进行问题分析了。
-rw-r--r-- 1 root root 6028807 Nov 29 05:12 ohasd.log
3. ohasd.bin开始启动集群的初始化资源和进程
根据前面章节的介绍,ohasd.bin会启动4个代理进程来启动所有的集群初始化资源。
- oraagent:启动ora.asm、ora.evmd、ora.gipcd、ora.gpnpd、ora.mdnsd等。
- orarootagent:启动ora.crsd、ora.ctssd、ora.cluster_interconnect.hai、ora.crf等。
- cssdagent:启动ora.cssd。
- cssdmonitor:启动ora.cssdmonitor。
如果对应的代理进程无法启动的话,那么以上的集群初始化资源也就无法启动,而代理进程无法启动的主要原因有以下两种。
原因1:代理进程对应的二进制文件损坏,例如:
2011-05-03 11:11:13.189
[ohasd(25303)]CRS-5828:Could not start agent '/u01/app/11.2.0/bin/orarootagent_grid'. Details at (:CRSAGF00130:) {0:0:2} in /u01/app/11.2.0/log/test1/ohasd/ohasd.log.
2011-05-03 12:03:17.491: [AGFW][1117866336] {0:0:184} Created alert : (:CRSAGF00130:) : Failed to start the agent /u01/app/11.2.0/bin/orarootagent_grid
原因2:代理进程的日志文件无法访问,例如:
[grid@test1 oraagent_grid]$ ls -l
total 110956
-rw-r--r-- 1 root root 8194187 Nov 29 06:02 oraagent_grid.log
对应解决的办法如下。
办法1:将有问题节点的代理进程二进制文件和健康节点的文件进行比较,发现不同后,把健康节点的文件复制到问题节点的对应位置。
办法2:确认代理进程的日志文件能够被对应的用户访问,例如:
[grid@test1 oraagent_grid]$ ls -l
total 110956
......
-rw-r--r-- 1 grid oinstall 8194187 Nov 29 06:02 oraagent_grid.log
4.集群的初始化资源开始启动
虽然ohasd的代理进程会同时启动所有的集群初始化资源,但是它们之间还是有依赖关系的。
对于基本的依赖关系,已在第4章做了介绍,在这里作者把更多的初始化资源加入了进来,进行以下总结。大家可以通过下面的图片简单了解一下这些集群初始化资源的启动依赖关系。
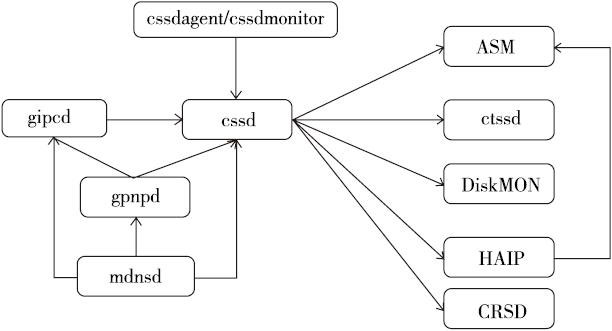
注意
有些对集群不重要的初始化资源,在上图中并没有显示从上面的图中大家可以看到gipcd、gpnpd、mdnsd负责完成集群的bootstrap过程;
cssdagent和cssdmonitor负责启动和监控cssd守护进程;而集群的其他初始化资源都要依赖于cssd。
下面我们对集群的bootstrap过程进行简单的介绍:
1)mdnsd守护进程被启动,并启动mdns服务,以便gpnpd能够通过mdns在节点之间传输gpnp profile文件。
2)gpnpd守护进程被启动,gpnpd开始读取本地节点的gpnp profile,之后和远程节点的gpnpd守护进程通信,以便获得集群中最新的gpnp profile信息。
3)gpnpd启动完毕,向本地节点的其他集群初始化资源提供gpnp profile服务。
4)gipcd守护进程被启动,从gpnpd守护进程获得集群的私网信息,并和远程节点的gipcd守护进程通信,最后开始监控本地节点的私网。
5)cssdagent代理进程启动ocssd.bin守护进程。
6)cssdmonitor守护进程启动,并开始监控ocssd.bin守护进程的状态。
在整个过程中,可能导致集群的bootstrap过程无法成功的主要原因如下。
原因1:集群中有其他的mdns软件运行(例如:avahi),这会导致GI的mdnsd服务无法正常工作。例如:
Oct 6 22:52:58 test1?avahi-daemon[22477]: Withdrawing address record?for *.*.*.* on bond1.
Oct 6 22:52:58 test1?avahi-daemon[22477]: Leaving mDNS multicast group on interface?bond1.IPv4 with address *.*.*.*.
Oct 6 22:52:58 test1?avahi-daemon[22477]: Joining mDNS multicast group on interface?bond1.IPv4 with address 169.254.180.94.
Oct 6 22:52:58 test1 avahi-daemon[22477]: Withdrawing address record for 169.254.180.94 on bond1.
Oct 6 22:52:58 test1?avahi-daemon[22477]: Interface bond1.IPv4 no longer relevant for mDNS.
原因2:gpnp profile文件中的信息出现错误,这会导致集群的bootstrap过程无法完成。例如:
[grid@test1 oraagent_grid]$ gpnptool get
Warning: some command line parameters were defaulted. Resulting command line:
/u01/app/11.2.0/grid/bin/gpnptool.bin get -o-
......
gpnp-profile.xsd" ProfileSequence="13" ClusterUId="7d414c4a930cdfc4ff23e150c9acd5e0" ClusterName="test-cluster" PALocation=""><gpnp:Network-Profile><gpnp:HostNetwork id="gen" HostName="*">
<gpnp:Network id="net2" IP="*.*.*.0" Adapter="eth88" Use="cluster_interconnect"/> <<<<<私网网卡信息错误
<gpnp:Network id="net1" Adapter="eth0" IP="*.*.*.0" Use="public"/>
原因3:节点之间的网络通信存在问题,这会导致gpnp profile无法正常传输。
原因4:gpnp的一些线程被挂起,这会导致gpnpd守护进程无法成功完成启动任务。
原因5:集群的私网网卡出现问题,这会导致gipcd无法和其他节点的gipcd进行通信或者集群没有可用的私网进行通信。
原因6:gipcd存在问题,这会导致它错误地认为集群私网网卡存在问题。
原因7:以上守护进程的套接字文件丢失。而对应的解决方法如下。
方法1:停止并禁用其他的mdns软件。例如:
# /etc/rc.d/init.d/avahi-dnsconfd stop
# /etc/rc.d/init.d/avahi-daemon stop
# chkconfig avahi-dnsconfd off
# chkconfig avahi-daemon off
方法2:如果gpnp profile只是在集群的某一个节点上出现了错误,可以从集群的其他节点将其复制过来。如果集群所有节点的gpnp profile都出现了问题,那么就需要使用gpnp工具来进行修正。下面的例子演示了如何使用gpnp tool修改集群的私网信息。
1)检查当前的gpnp profile,确认gpnpd能够通过mdns找到集群的其他节点。
$<gi_home>/bin/gpnptool get
$<gi_home>/bin/gpnptool find
2)创建一个工作路径以用于编辑gpnp profile。
$mkdir /home/grid/gpnp
$export GPNPDIR=/home/grid/gpnp
$<gi_home>/bin/gpnptool get -o=$GPNPDIR/profile.original
3)创建一个用于修改的gpnp profile副本。
$cp $GPNPDIR/profile.original $GPNPDIR/p.xml
4)查看gpnp profile的序列号和私网信息。
$<gi_home>/bin/gpnptool getpval -p=$GPNPDIR/p.xml -prf_sq -o-
$<gi_home>/bin/gpnptool getpval -p=$GPNPDIR/p.xml -net -o-
5)修改集群私网的网卡信息。
$<gi_home>/bin/gpnptool edit -p=$GPNPDIR/p.xml -o=$GPNPDIR/p.xml -ovr -prf_sq=<当前序列号+1> -net<私网编号>:net_ada=<私网网卡名>
6)确认之前的修改。
$<gi_home>/bin/gpnptool sign -p=$GPNPDIR/p.xml -o=$GPNPDIR/p.xml -ovr -w=cw-fs:peer
7)将修改后的gpnp profile应用到gpnpd守护进程中。
$<gi_home>/bin/gpnptool put -p=$GPNPDIR/p.xml
8)将改变后的gpnp profile推送到集群的其他节点。
$<gi_home>/bin/gpnptool find -c=<集群名>
$<gi_home>/bin/gpnptool rget -c=<集群名>
方法3:确认集群私网通信正常(例如:使用ping、traceroute等命令确认集群私网的连通性)。
方法4:在操作系统层面重新启动gpnp守护进程,例如:kill-9<gpnpd进程ID>。
注意
当gpnpd守护进程被终止之后,对应的ohasd代理进程会及时发现这一情况,并启动新的gpnpd守护进程。
