




3 分布表+分布表
分布表+分布表的查询,分为数据落在相同 HG 上和不同 HG 上两种类型。
数据落在相同 HG 上时原理如下:
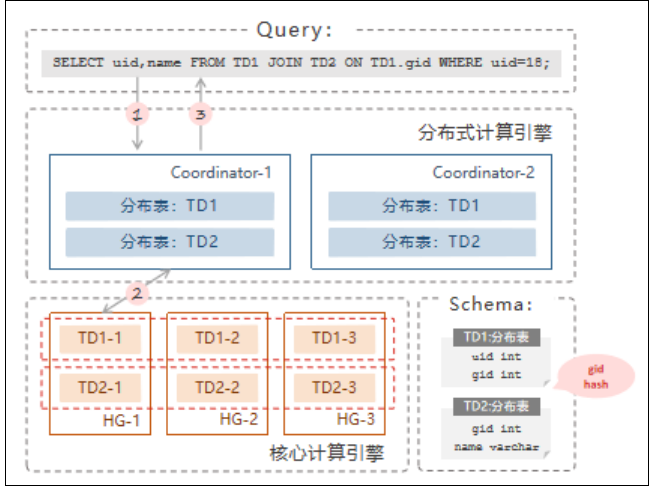
TD1 和 TD2 皆为分布表,以 uid 为分片列:
1. CN 接收到 SQL 后,根据集群元数据存储的分片规则,确认此次查询仅涉
及 HG-1;
2. 把 SQL 语句直接发送给 HG-1,获得执行结果;
3. CN 将结果返回给用户。
这类查询性能高,无冗余操作,支持高并发,性能线性提升。
数据落在相同 HG 上时原理如下:
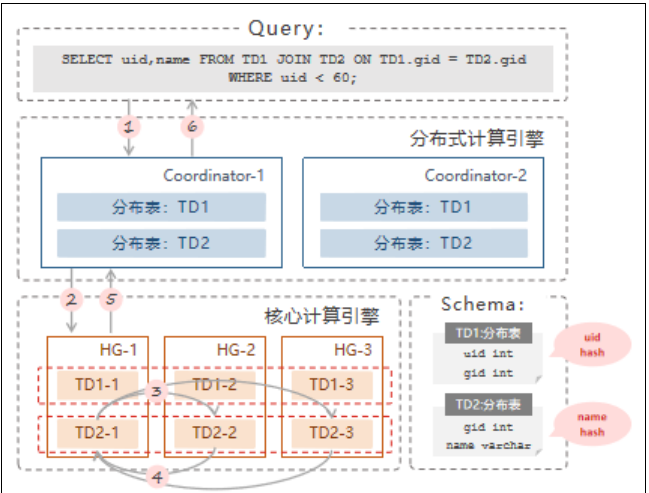
TD1 和 TD2 皆为分布表,以 uid 为分片列:
1. CN 接收到 SQL 后,根据集群元数据存储的分片规则,根据 TD1 表的分片
规则,生成分布 SQL 语句;
2. 把 SQL 语句发送给 HG-1 数据引擎执行;
3. HG-1 拉取其他 HG 上 TD2 表 uid<60 的数据;
4. 进行 JOIN 查询计算;
5. HG-1 将结果返回给 CN;
6. CN 返回给用户。
这类查询性能较差,涉及数据移动,跨节点拉数据,网络传输是瓶颈。
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
