




首先我们模拟写入1000万数据。图1这个由于我存储过程中写了一些运算,所以以每秒不到5000条的速度写入,这个性能未达到最佳。
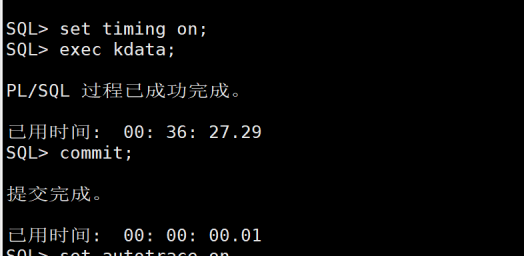
图1
我们的表是无主键无索引。如下面连续3副图。
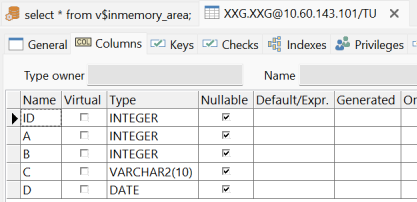
我们来看一下全表查询的消耗。1000万需要2秒。因为大量读取了磁盘IO。
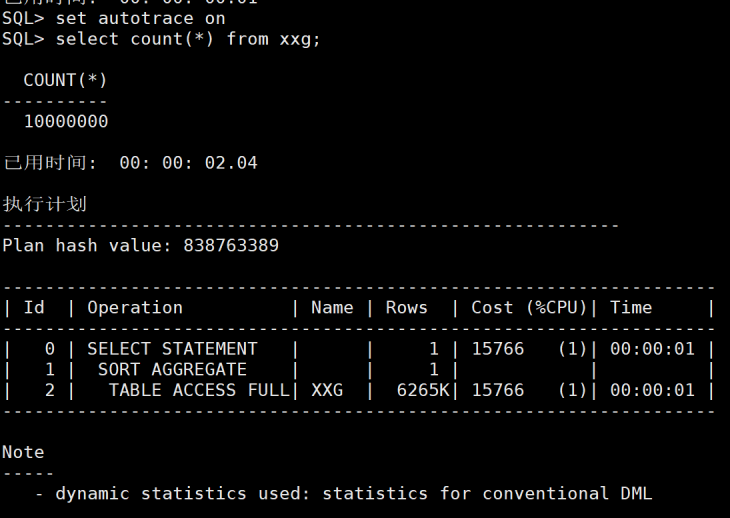
图2
再一次执行这句,只要470毫秒,0.47秒完成。因为都在缓存处理了,所以没有physical reads磁盘读,只有一致性读。
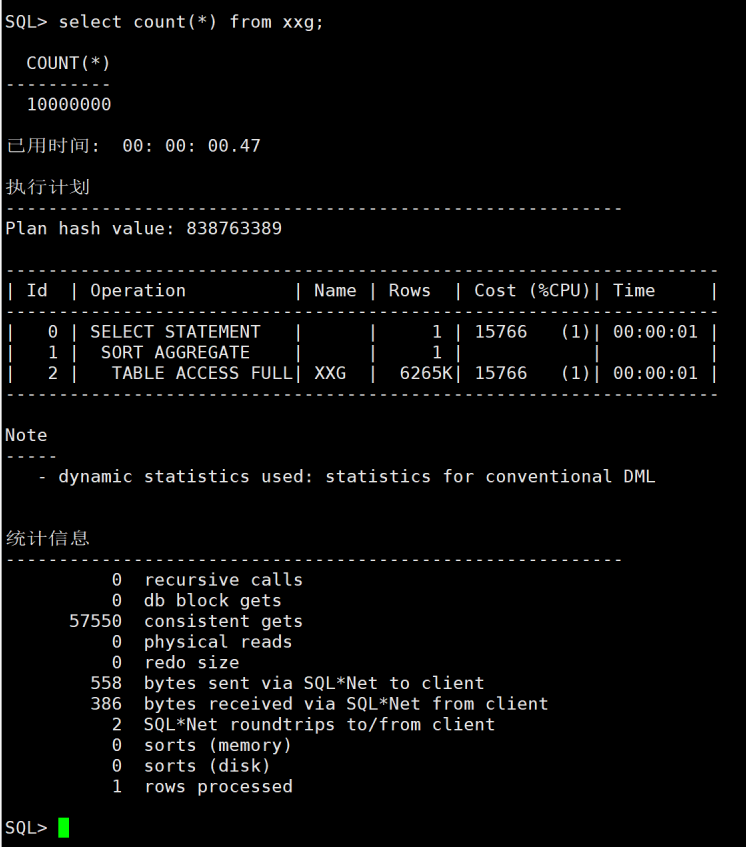
图3
当我换了一列的适合这是是count(a)而不是count(*).那么还是产生了一些磁盘读。如图4
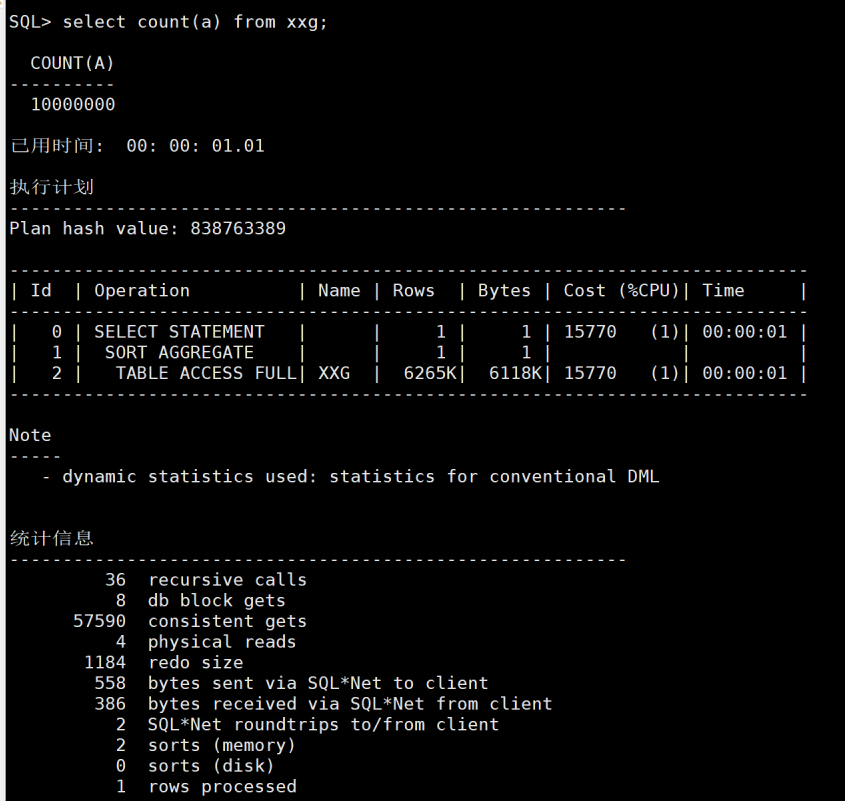
图4
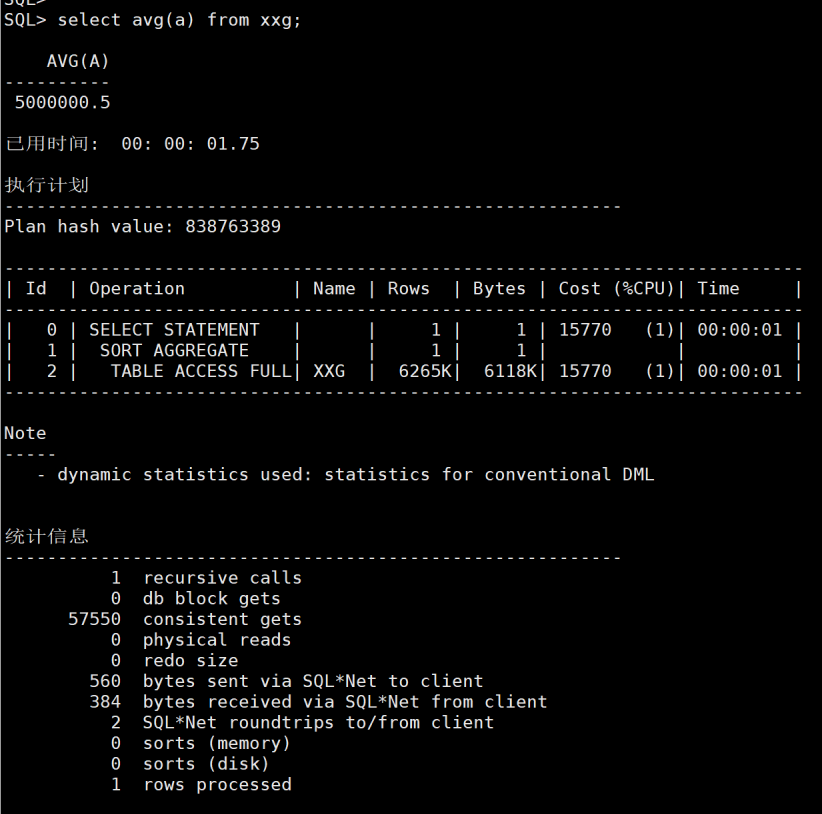
我再SUM一下a列,全是一致性读,没有磁盘读。如图5

图5
对a列做其他的聚合,效果一样。如图6
这个时候我们把缓存清掉。再查询。如图7,会发现physical reads多了,而且执行的时间也到1.7秒,慢了很多。因为清除缓存重新加载需要时间。
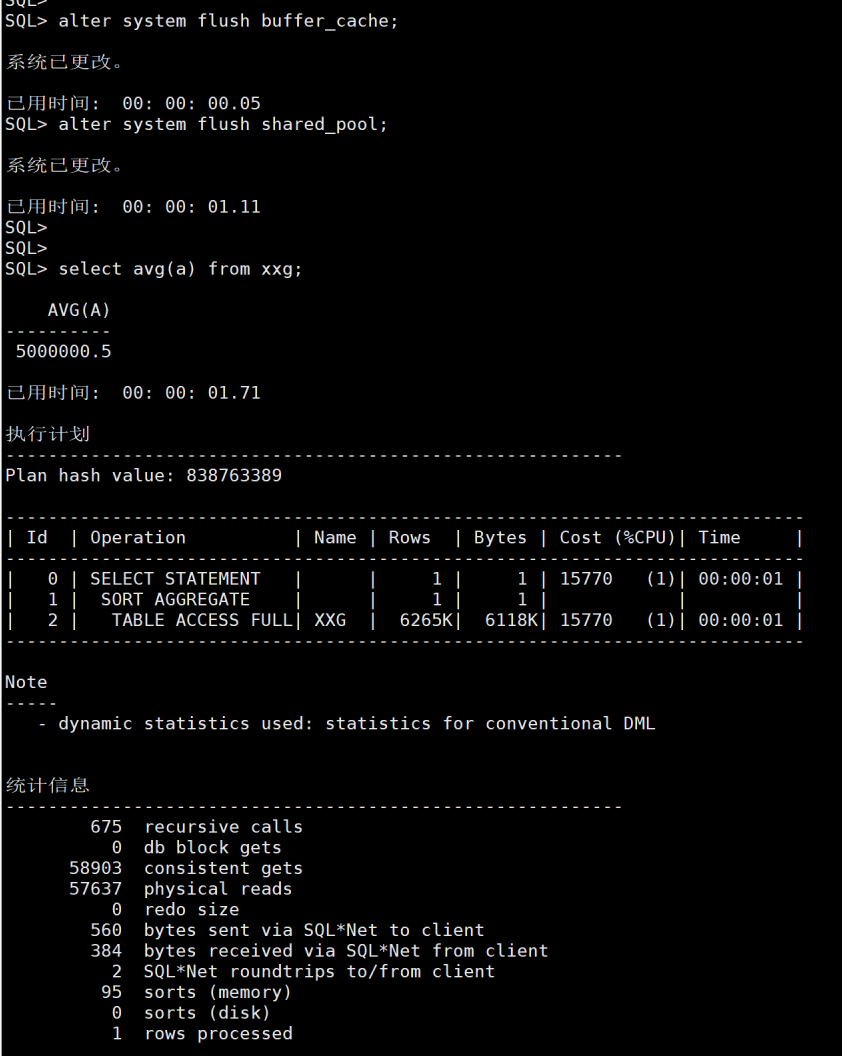
图7
打开inmemory,设置参数3G,并且开启多个进程加载。如图8
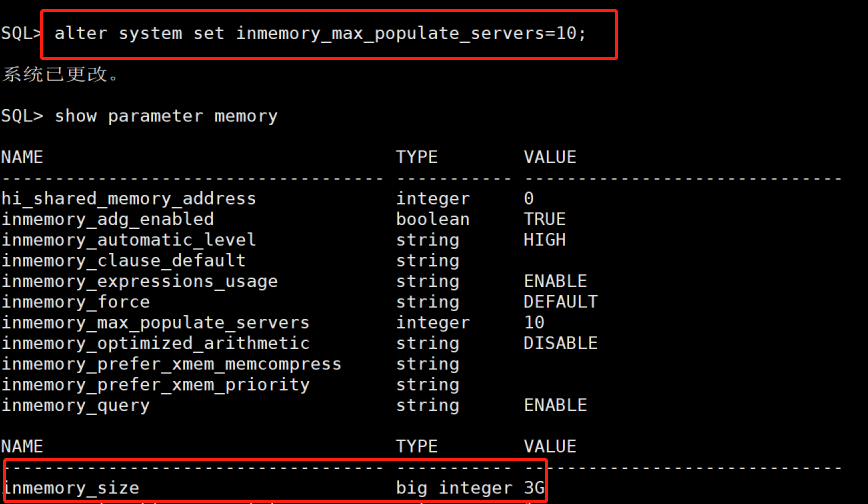
图8
把xxg的表加载到inmemory中去。如图9

图9
然后再次执行全表聚合。780毫秒完成。一致性读只有9了。比起之前的5万多,可以说忽略不计。如图10
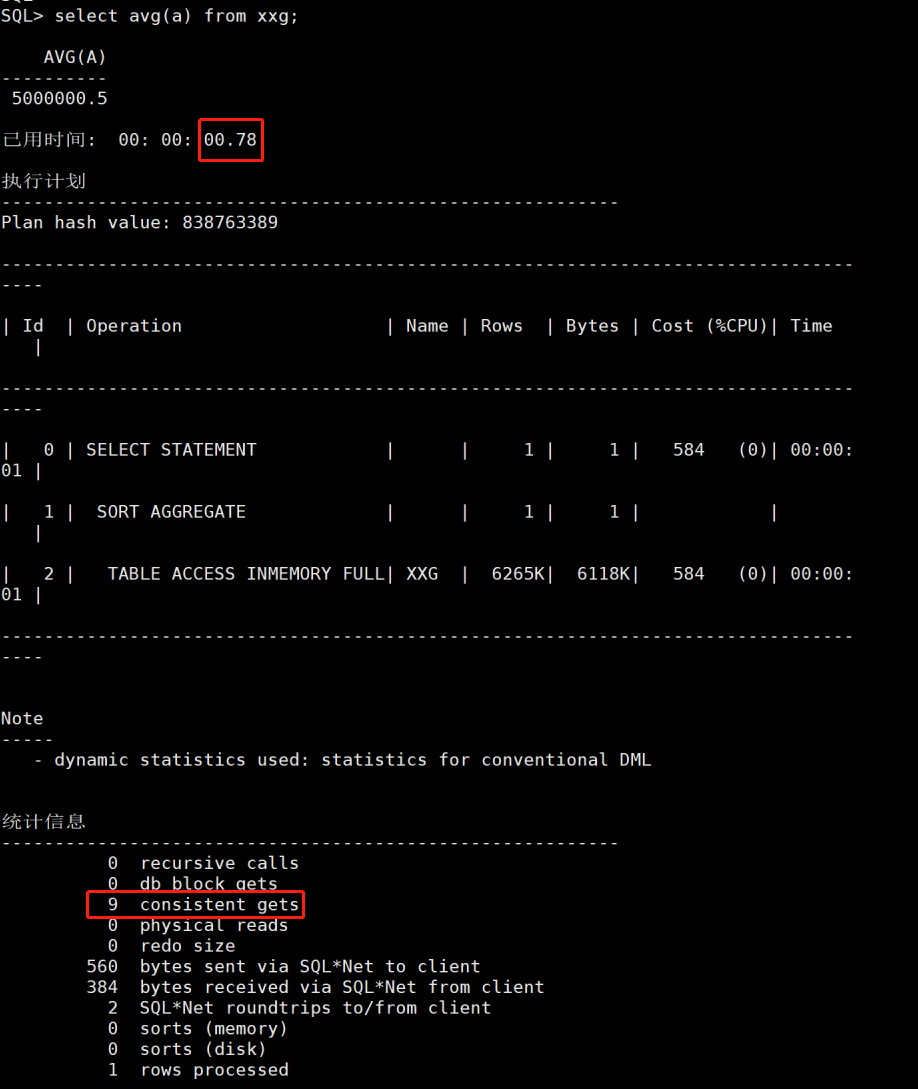
图10
换其他列,发现也是如此。如图11
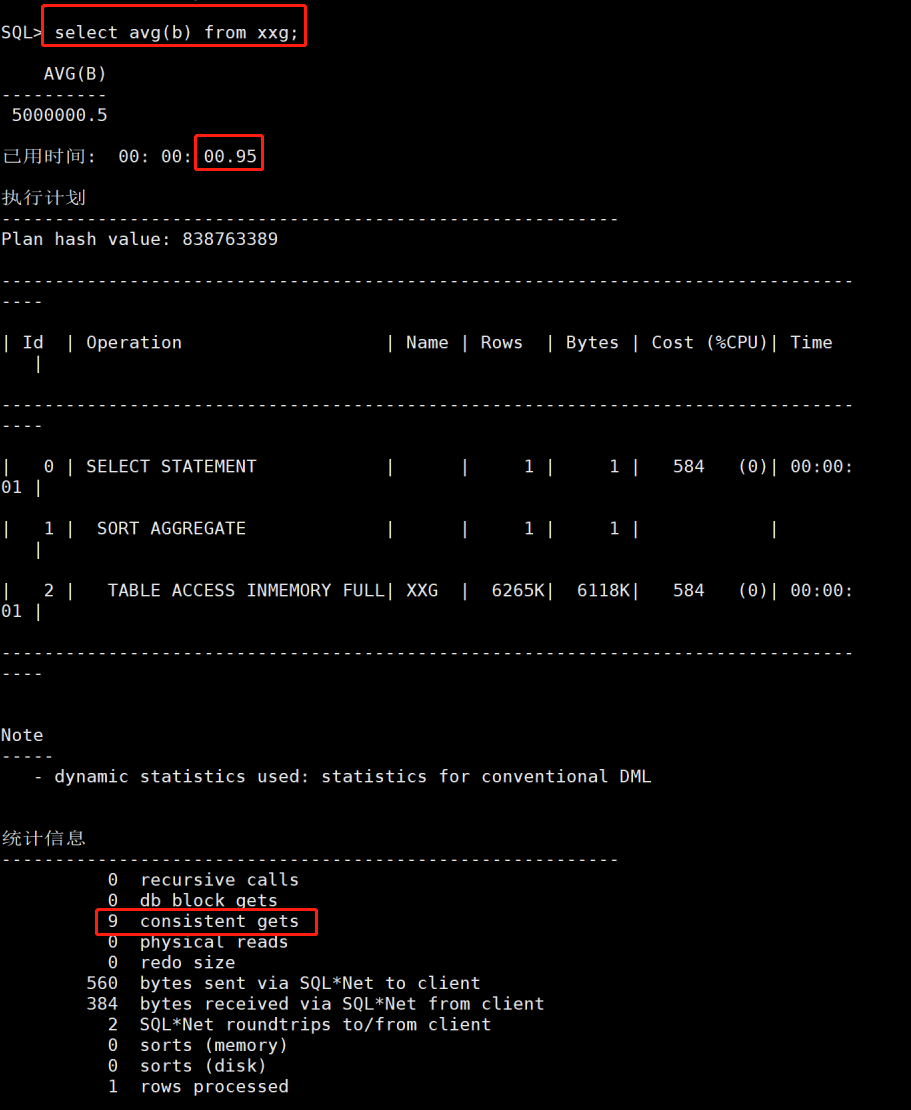
图11
这个时候最好收集一下统计信息,如图12

图12
然后做极值函数的测试。如图13 14。可以看出max min都很稳定20毫秒(全表无索引的情况下) 统计信息的rows也准了。
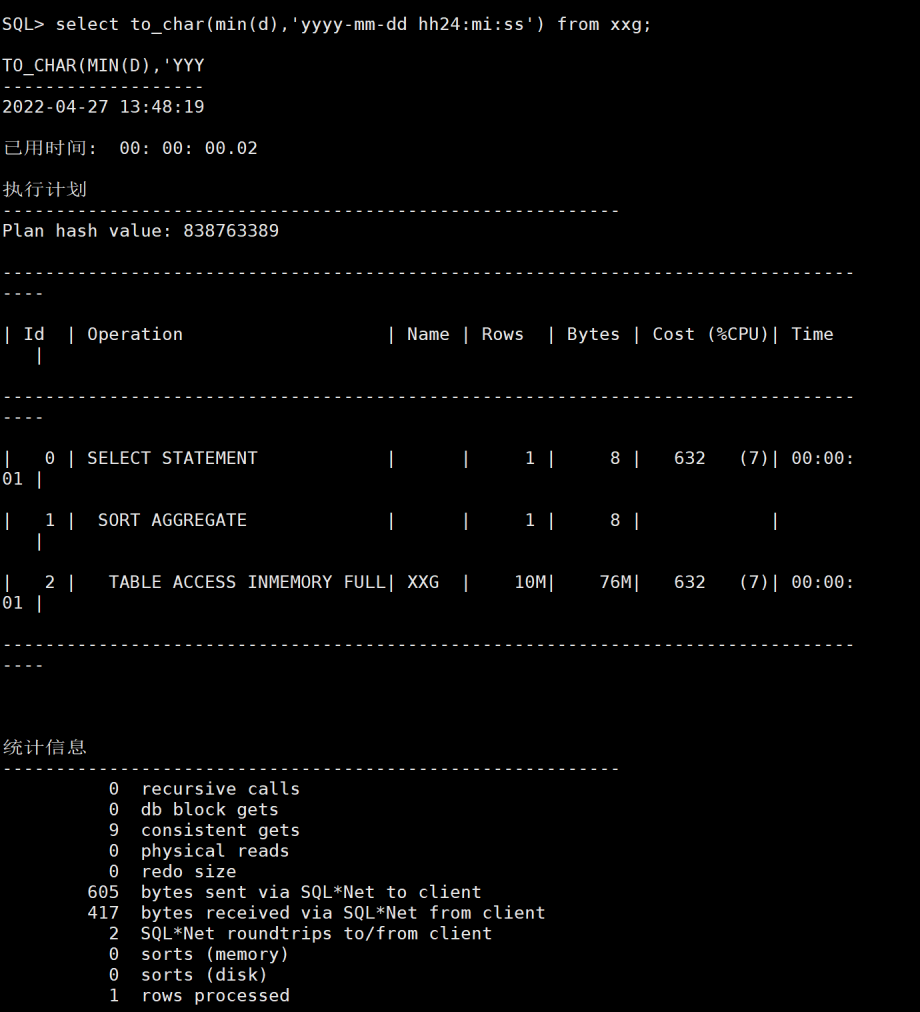
图13
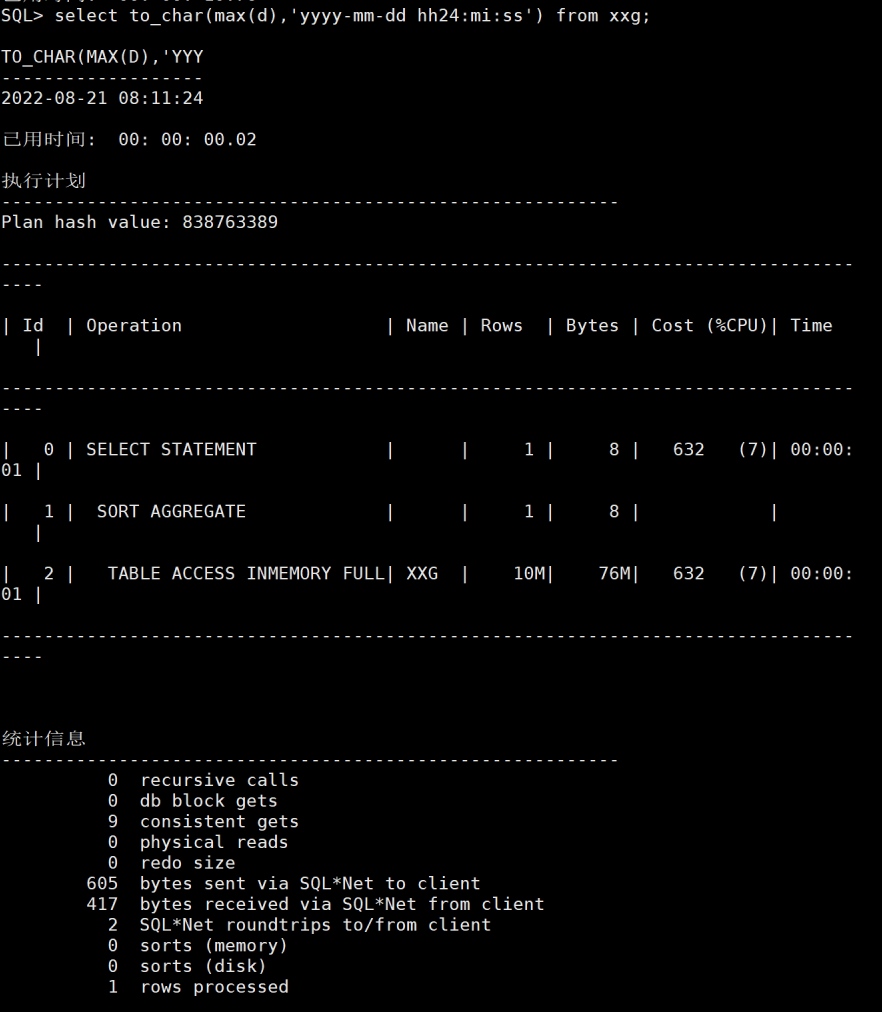
图14
然后这个时候去count这个表,全表。如图15也只有20毫秒。和之前图2的全磁盘2秒,图3的全内存470毫秒都是较大的提升。图2和图3都没有使用inmemory,也没有收集统计信息。
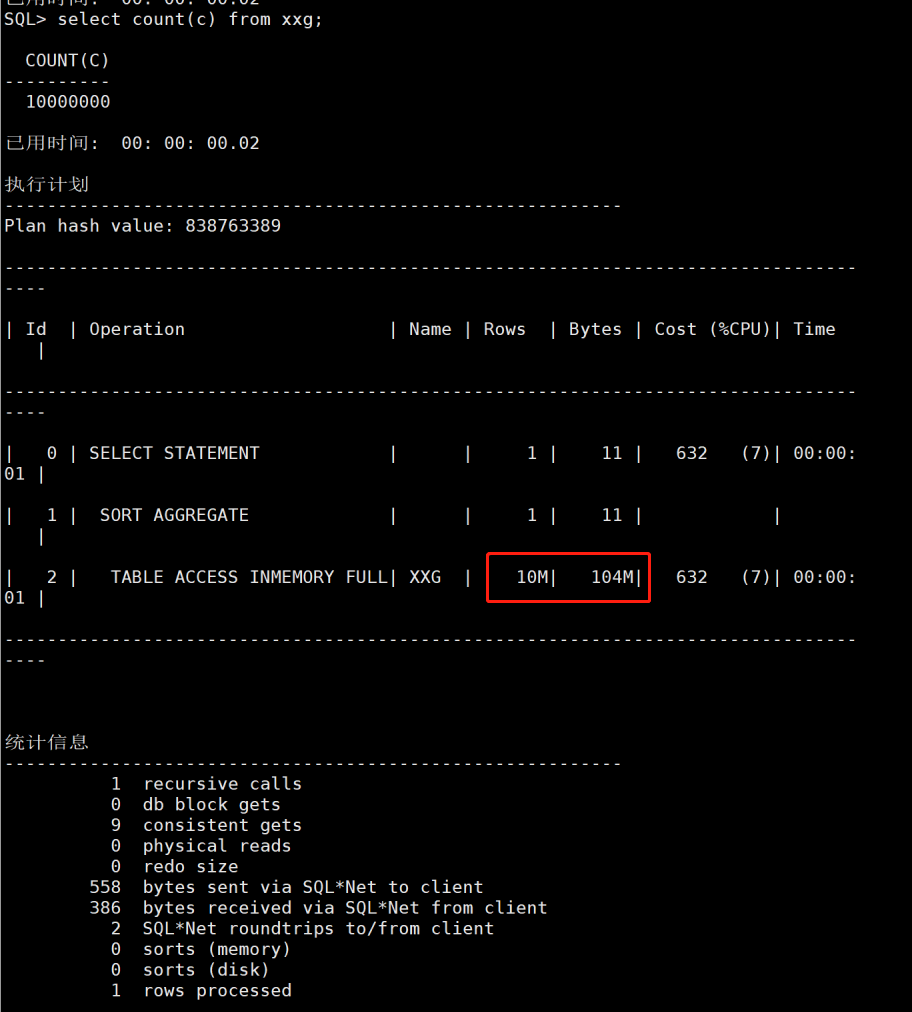
图15
这个时候也像刚才一样清空缓存如图16.会发现重新执行inmemory表的聚合,这里是count c列也会产生磁盘读,但是是48,比起原来没有inmemory清空缓存的5万多来说,也可以说忽略不计了。

图16
这个时候去count其他列这里是count a列,如图17。1000万单表的聚合是10-20毫秒。所以1亿的单表聚合也在1秒左右这都是正常的。
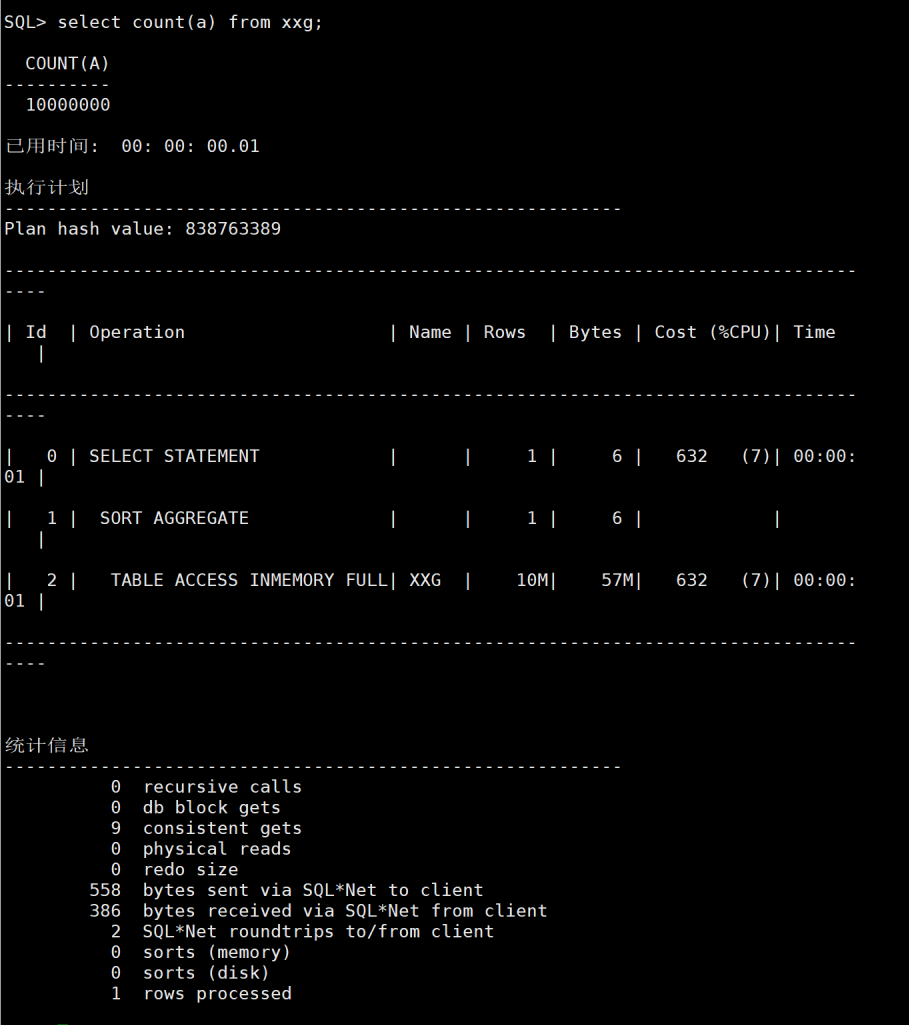
图17
小结:刷新缓存对传统来说有较大影响,对加载到inmemory的表影响很小。
