




众所周知,一条SQL主要是对数据进行增删改查,那么Oracle在运行一条SQL的时候主要会涉及到Oracle的哪些东西?
| sql语句分类 |
增删改查对应的sql关键词分别是:insert delete update select
select的主要作用是对已存在的数据进行查询,不对数据进行任何变动操作,所以可以单独分为一类————查询语句
insert的主要作用是将新的数据插入到数据库的表中进行保存,要将新数据放进已存在的表中
delete的主要作用是删除表中的某些数据
update的主要作用是将表中的某些数据进行修改更新
由此可见,insert delete update都在一定程度上对表做了变动更新,所以这三者可以为一类————更新语句
既然对于数据是否变动可以将sql语句分为两类,也就意味这Oracle在接受到这两种SQL而做出的处理会有不同。
-- 举例的查询sql语句
select name from record where id = 12;
-- 举例的更新sql语句
update record set id = 52 where id = 12;
| 体系结构图的回顾 |
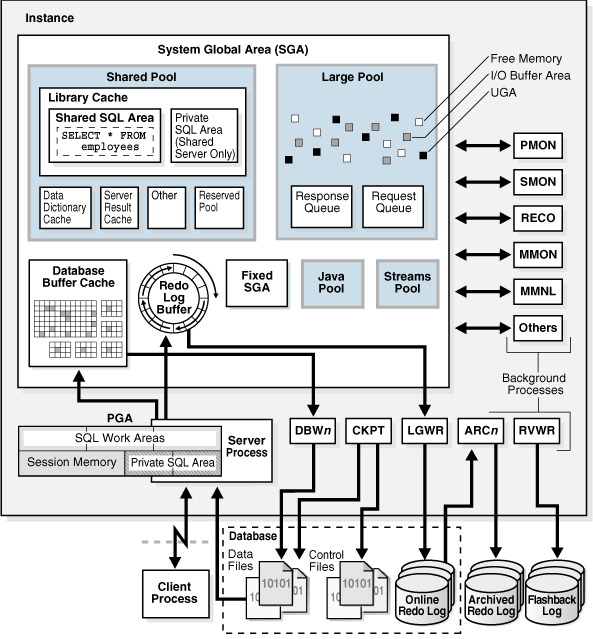
以上是一张官方的Oracle体系结构图,由此可见实例是系统分配给Oracle的内存和一堆进程的结合体,这里主要回顾执行sql语句会涉及到的几个部分:SGA中的shared pool、database buffer cache、redo log buffer,进程中的DBWn、LGWR以及PGA中的Hash Area、Private SQL Area
| SGA |
All server processes that execute on behalf of users can read information in the instance SGA. Several processes write to the SGA during database operation.
Each database instance has its own SGA. Oracle Database automatically allocates memory for an SGA at instance startup and reclaims the memory at instance shutdown.
| shared pool |
The shared pool caches various types of program data.
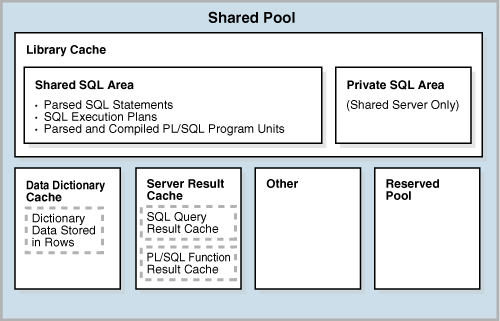
本文主要涉及到的shared pool区域是上图中的 Library Cache、Data Dictionary Cache 和 Server Result Cache
Library Cache 主要用于储存可执行的SQL和PL/SQL代码
Data Dictionary Cache 主要用于缓存数据字典的相关数据,该缓存区域对所有服务进程共享
Server Result Cache 主要用于保存SQL和PL/SQL执行产生的结果集
| database buffer cache |
The database buffer cache, also called the buffer cache, is the memory area that stores copies of data blocks read from data files.
database buffer cache 主要用于缓存一部分属于物理数据文件的数据备份以及在更新数据时用于暂时保存更新后的数据(dirty data)
| redo log buffer |
The redo log buffer is a circular buffer in the SGA that stores redo entries describing changes made to the database.
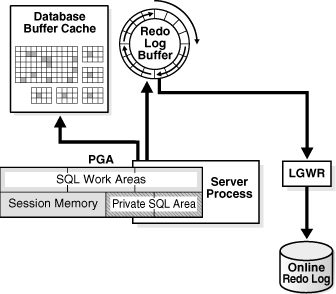
用户所做的所有操作都会被保存到 redo log buffer 中,以用于数据库崩溃时的数据恢复,在这里所有的操作记录被称为 redo record ,一条 redo record 刚好对应用户执行的一句操作语句
| 进程 |
| DBWn |
The database writer process (DBW) writes the contents of database buffers to data files. DBW processes write modified buffers in the database buffer cache to disk.
DBWn 主要用于 database buffer cache 有脏数据且达到一定条件时将缓存中的数据写入到数据文件中,以防数据库因故宕机导致的缓存清空
上述的“一定条件”主要包含两个情况:
- 当缓存区中的脏数据数量达到缓存区的一定比例,即达到缓存区的特定阈值时,DBWn 会执行写入
- DBWn 也会定期将缓存区的脏数据写入到数据文件中
| LGWR |
The background process responsible for redo log buffer management—writing the redo log buffer to the online redo log. LGWR writes all redo entries that have been copied into the buffer since the last time it wrote.
LGWR 主要用于将 redo log buffer 中的记录写入到日志文件中
LGWR 主要在以下几种情况时写入:
- 用户执行commit时
- online redo log 发生切换时
- 每三秒自动写入一次
- redo log buffer 已满1/3或者有1 MB的缓冲数据时
- DBWn 执行数据写入之前
| PGA |
A PGA is a nonshared memory region that contains data and control information exclusively for use by an Oracle process. Oracle Database creates the PGA when an Oracle process starts.
One PGA exists for each server process and background process. The collection of individual PGAs is the total instance PGA, or instance PGA. Database initialization parameters set the size of the instance PGA, not individual PGAs.
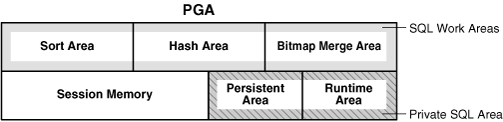
本文主要涉及到的PGA区域是上图中属于 SQL Work Area 的 Hash Area 和 Private SQL Area
Hash Area 主要用于执行SQL时,保存用于连接相关表的hash值
Private SQL Area 主要用于保存已解析的SQL语句信息和查询执行状态信息。例如,运行时在全表扫描中检索到的行数。
| 查询sql语句运行过程 |
SQL> set autotrace on
SQL> set timing on
SQL> select name from record where id = 12;
NAME
--------------------
Hzz
Elapsed: 00:00:00.01
Execution Plan
----------------------------------------------------------
Plan hash value: 2141715379
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 25 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| RECORD | 1 | 25 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ID"=12)
Note
-----
- dynamic statistics used: dynamic sampling (level=2)
Statistics
----------------------------------------------------------
60 recursive calls
0 db block gets
79 consistent gets
0 physical reads
0 redo size
547 bytes sent via SQL*Net to client
399 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
5 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> select name from record where id = 12;
NAME
--------------------
Hzz
Elapsed: 00:00:00.00
Execution Plan
----------------------------------------------------------
Plan hash value: 2141715379
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 25 | 3 (0)| 00:00:01 |
|* 1 | TABLE ACCESS FULL| RECORD | 1 | 25 | 3 (0)| 00:00:01 |
----------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - filter("ID"=12)
Note
-----
- dynamic statistics used: dynamic sampling (level=2)
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
8 consistent gets
0 physical reads
0 redo size
547 bytes sent via SQL*Net to client
399 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
上述是基于一个无索引的record表的连续两次查询得到的统计信息:由此可见,两次查询花的时间不一样,第二次查询该信息的时候所花的时间要比第一次查询要少,其次从两次查询的统计信息可以看出,第二次查询似乎比第一次查询要少做一些事。造成此结果的原因则是两次查询在Oracle内部所引起的反应不一样。
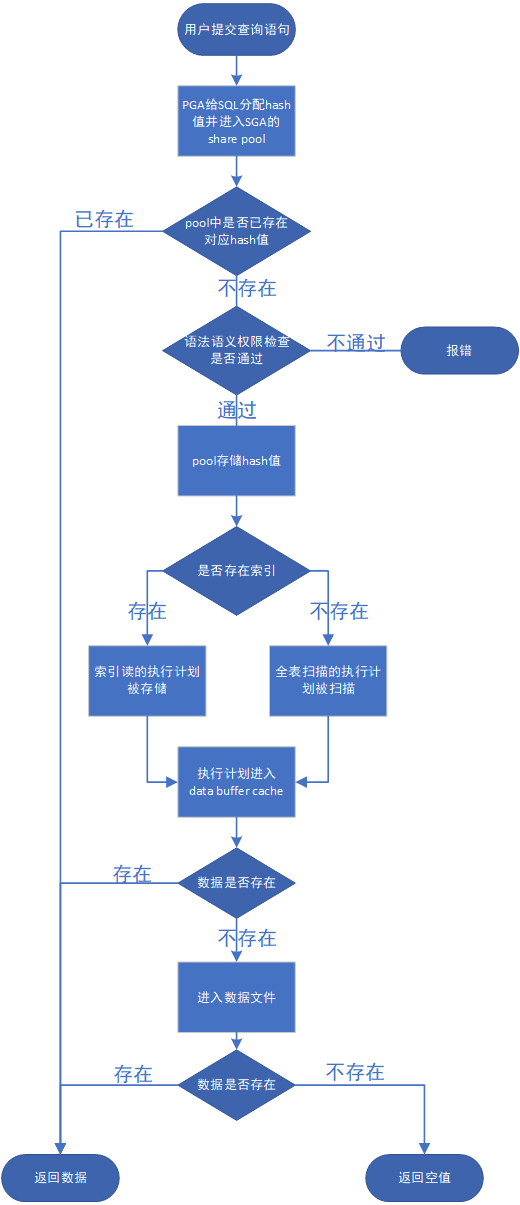
| 第一次查询 |
用户提交一条查询语句之后,Oracle会立即在PGA的 Hash Area 中生成一个对应该查询语句的hash值,作为该查询语句接下来在Oracle中深入的凭证,之后,SQL语句进入到SGA,首先进入到 share pool ,在这里SQL语句会寻找池中是否有存储有对应的hash值,这里也就是第一次查询和第二次查询的步骤分界点。
如果池中没有存储对应的hash值,SQL语句就需要更深入查找,在此之前,它需要对自己做一番检查:
- 语句的语法是否正确(关键字是否书写错误)
- 语句的语义是否正确(查询的列名是否存在)
- 语句的权限是否拥有(用户是否可以查询该表)
检查完毕后,SQL语句会将hash值存储在 share pool 中,然后进行下一步解析。
这一步要对SQL语句进行解析:是否存在索引,如果索引存在是使用索引读还是全表扫描?Oracle会根据对SQL语句执行两种的代价(Cost)进行估算,选择Cost低的一种方案进行扫描(一般情况下,索引读的代价会比全表扫描的代价低很多,但也有几种特殊情况会存在选择全表扫描而放弃索引读,具体的情况可自行查询学习)。当代价更低的方案被Oracle认定之后,索引读的这个执行计划会被存储起来,并与hash值绑定在一起。
接下来,SQL语句会带着这个执行计划进入到 data buffer cache 通过索引在缓存中查找对应id=12的数据,如果缓存区存在该数据,则直接提取返回,如果没有,就得依靠缓存区派去跑腿去数据文件中查找。
如果在数据文件中找到该数据,跑腿就会将数据带回到缓存区,然后缓存区留下该数据的副本后将其交给SQL语句返回;如果跑腿在数据文件中未找到对应的数据,则只能空手回到缓存区,SQL语句因此返回为空。
| 第二次查询 |
第二次查询其实和第一次查询的主要不同就是 share pool 中是否存在对应hash值,如果存在则代表该查询是第二次或者多次查询,hash值对应上之后,会直接从 data buffer cache 中返回查询的数据。其中主要有三个点省去了像第一次查询那样的流程:
- PGA中还存在用户连接信息和相关权限信息,如果再次执行的时候SESSION没有断开,连接信息和相关权限信息就可以从PGA内存中直接获取,避免了物理读。
- 当再次执行该SQL指令时,由于该 SQL指令的hash值和共享池里保存的相匹配,所以之前的硬解析动作无须再做,不仅跳过了相关语法语义检查,对于该选取哪种执行计划也无须考虑,直接拿来就好。
- 首次执行该 SQL 指令时,数据一般不在SGA 的数据缓存区里(除非被别的 SQL读入内存了),只能从磁盘中获取,不可避免地产生了物理读,但是由于获取后会保存在数据缓存区里,再次执行时可直接从数据缓存区里获取,完全避免了物理读
| 总结 |
| 更新sql语句运行过程 |
The database updates data blocks in the cache and stores metadata about the changes in the redo log buffer. After a COMMIT, the database writes the redo buffers to the online redo log but does not immediately write data blocks to the data files.
更新SQL其实是在查询的基础上对数据进行更新操作的,所以其实前半部分的经历和查询基本一致,例子中使用的 update record set id = 52 where id = 12 也要先对id=12的数据进行查找之后再对其进行id=52的修改,所以查询和更新语句的过程不一样是从跑腿找到数据回到 data buffer cache 开始的,查询的下一步就是返回数据给用户,更新的下一步却不一样。
data buffer cache 将id=12改成id=52,然后这一操作行为会被隔壁的 redo log buffer 记录下来,在这之后如果用户执行commit提交数据,会先由LGWR将 redo log buffer 里的数据写入到 online redo log 中,并在后续由ARCH写入到磁盘中的日志文件中进行保存。LGWR做完写入操作后,达到工作标准的DBWn会将 data buffer cache 中的脏数据写入到数据文件中进行保存,到此,Oracle更新SQL的执行才算结束。
