




点击蓝字 关注我们

导读
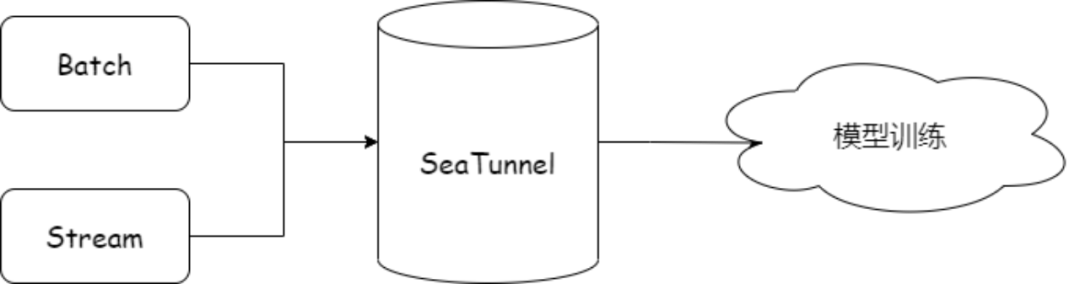
本文将以 OpenMLDB 为例,详细讲解如何使用 Apache SeaTunnel 进行异构数据源同步,以及如何使用 SeaTunnel API 快速接入数据源。
概要:
Apache SeaTunnel 简介
Apache SeaTunnel 原理和架构演进
Apache SeaTunnel Source & Sink 开发
OpenMLDB Source 连接器示例
如何快速参与贡献
SeaTunnel简介
1
Apache SeaTunnel 特性
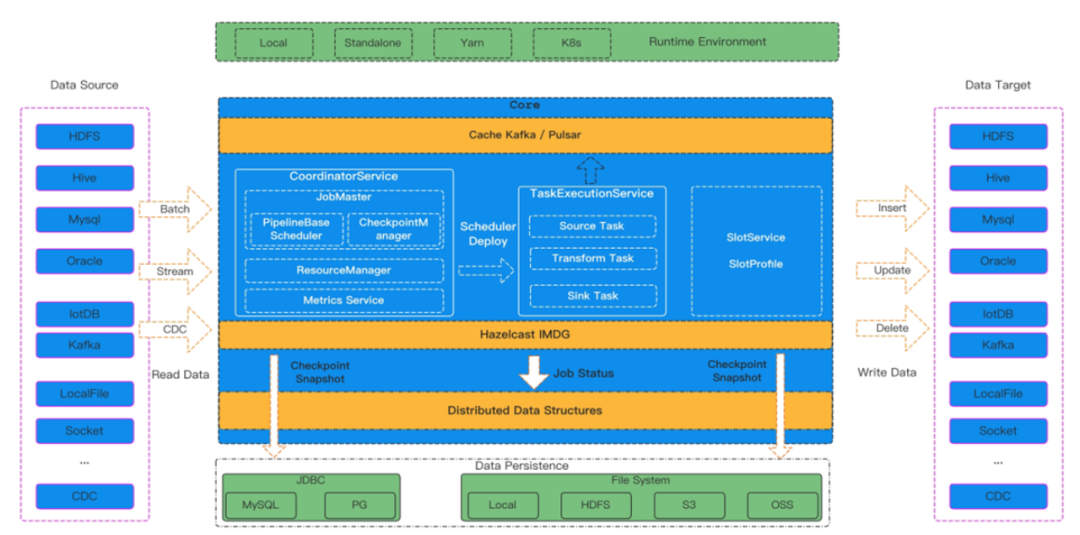
简单易用,无需开发:SeaTunnel 做数据集成无需开发,只需要写入配置文件和配置项,即可快速生成一个数据同步任务; 批流一体架构:既支持批任务,又支持流任务; 异构多数据源支持:包括 HDFS、MySQL、Oracle、IoTDB 等,支持多异构数据源之间同步 支持Spark2.4.X+、Flink1.13.X:不仅有自己的计算引擎 Zeta,也支持 Spark2.4.X+、Flink1.13.X 版本,企业内部使用这些引擎可以无缝接入 SeaTunnel; 模块化和插件化,易于扩展:预留了丰富的接口更好地处理数据请求; 自研计算引擎,减少部署成本:自研计算引擎 Zeta,2.3.0 版本中有了很大的改进,保证稳定性和性能,系统在 Java 环境下可以直接部署,减少部署成本; 支持CDC:无缝接入 CDC,目前支持的 CDC数据源包括 MySQL、SQLServer 等。
原理和架构演进
1
Apache SeaTunnel 核心理念
上层不依赖底层,两者都依赖抽象 流程代码与业务逻辑应该分离

2
Apache SeaTunnel 内核原理
3
Apache SeaTunnel 架构演进
V1 架构
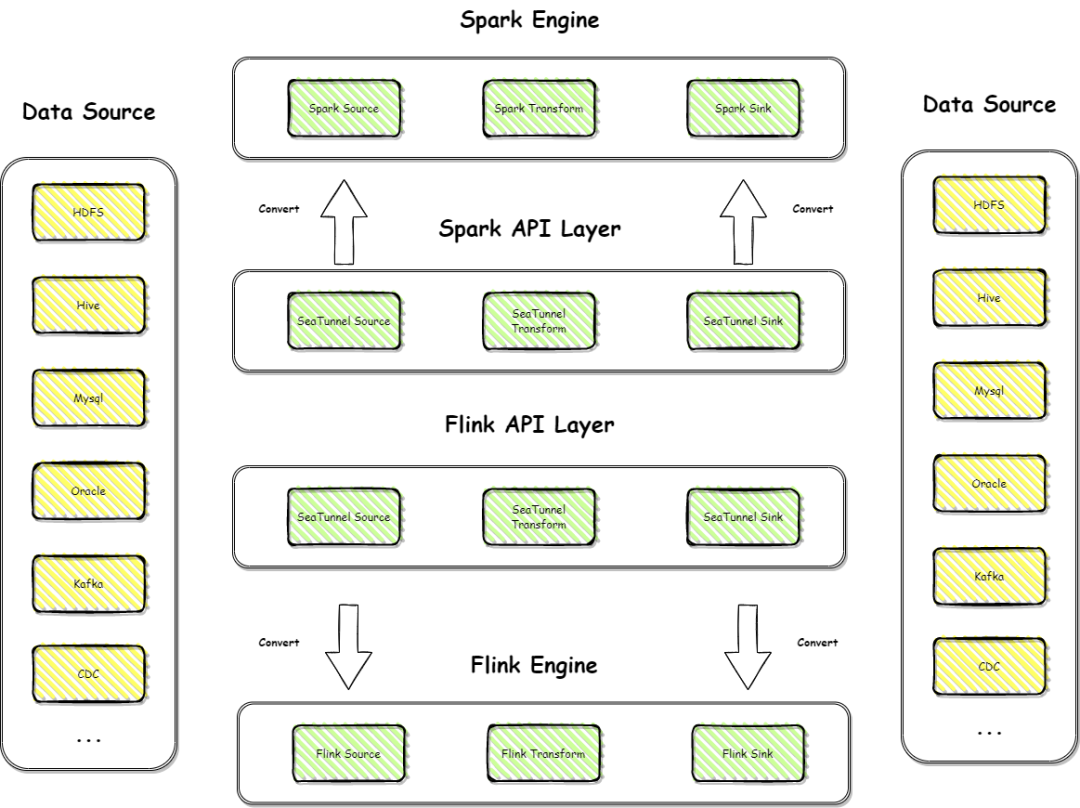
V2架构
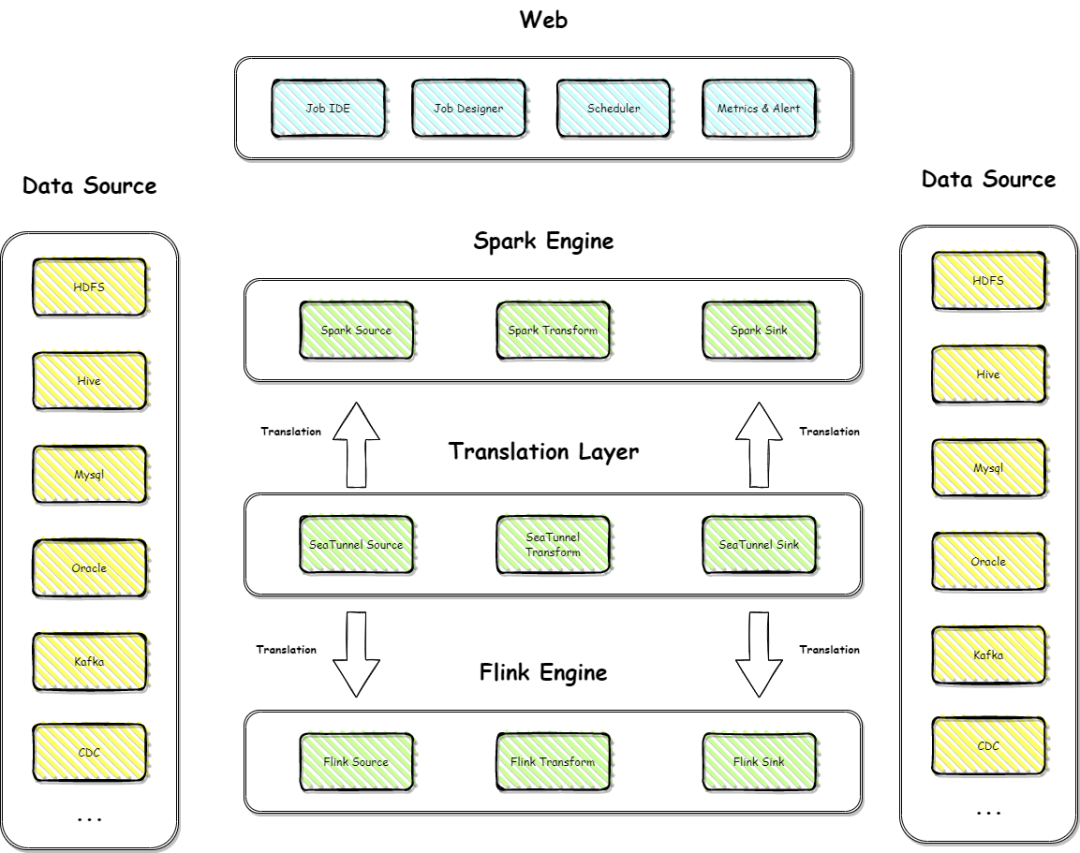
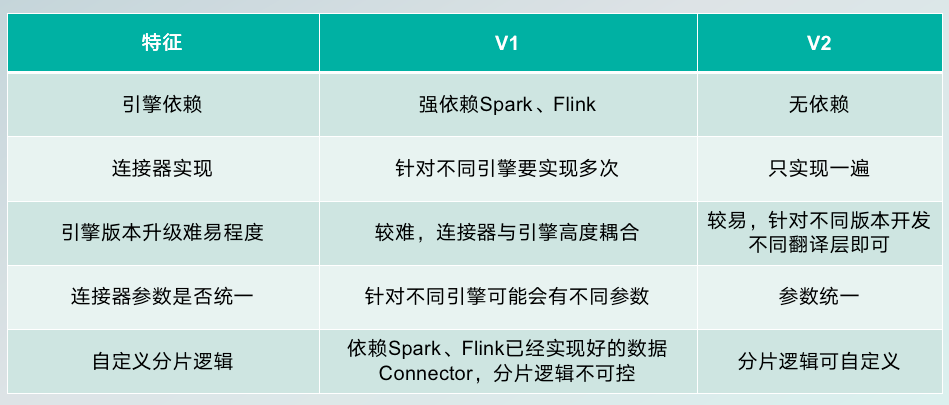
V2架构新特性

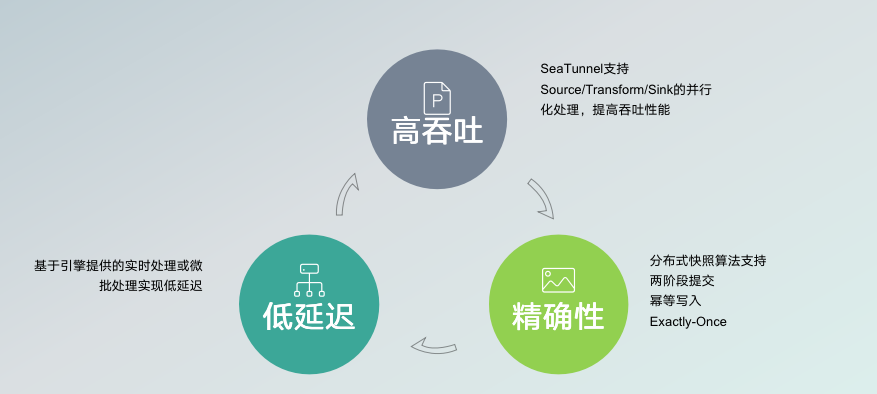
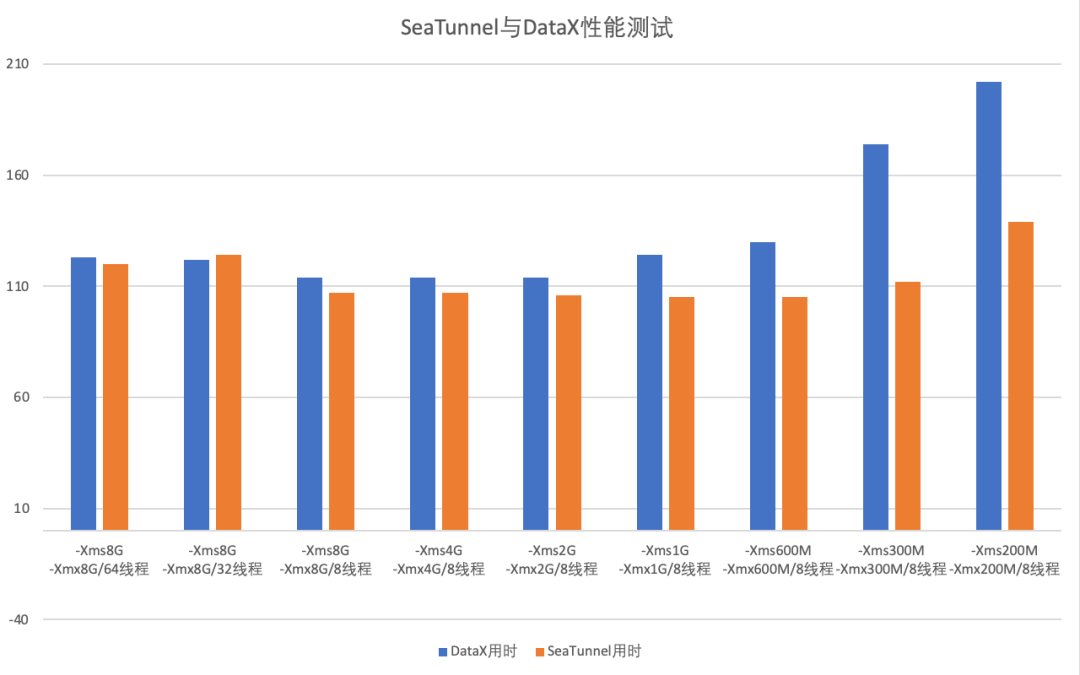
Source&Sink开发
1
连接器API相关模块
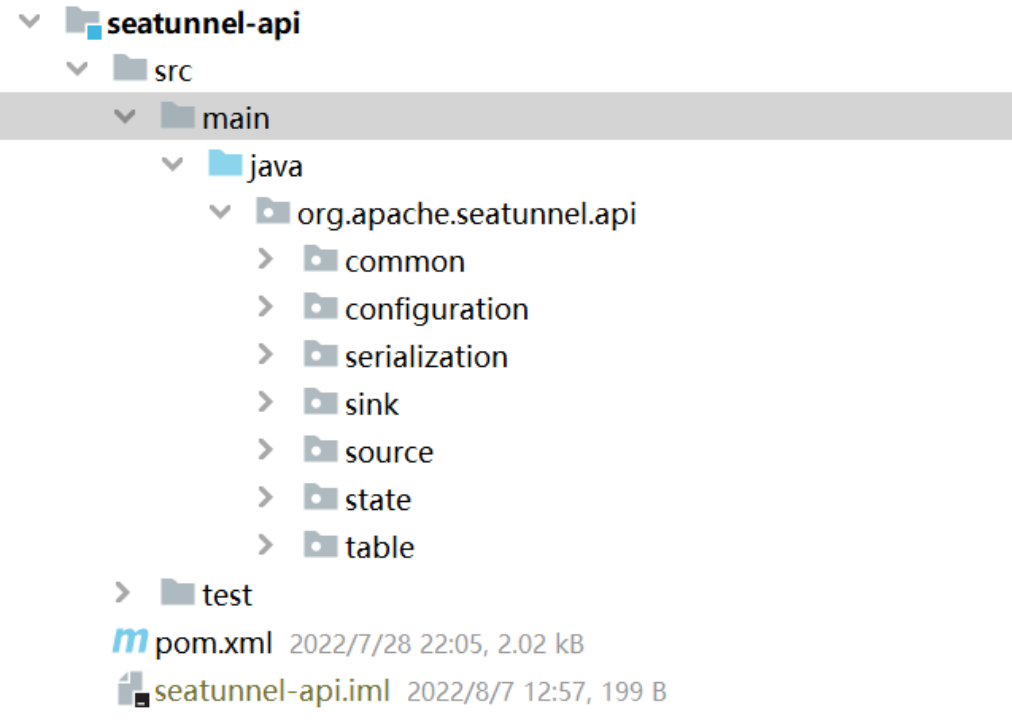

2
连接器API数据抽象
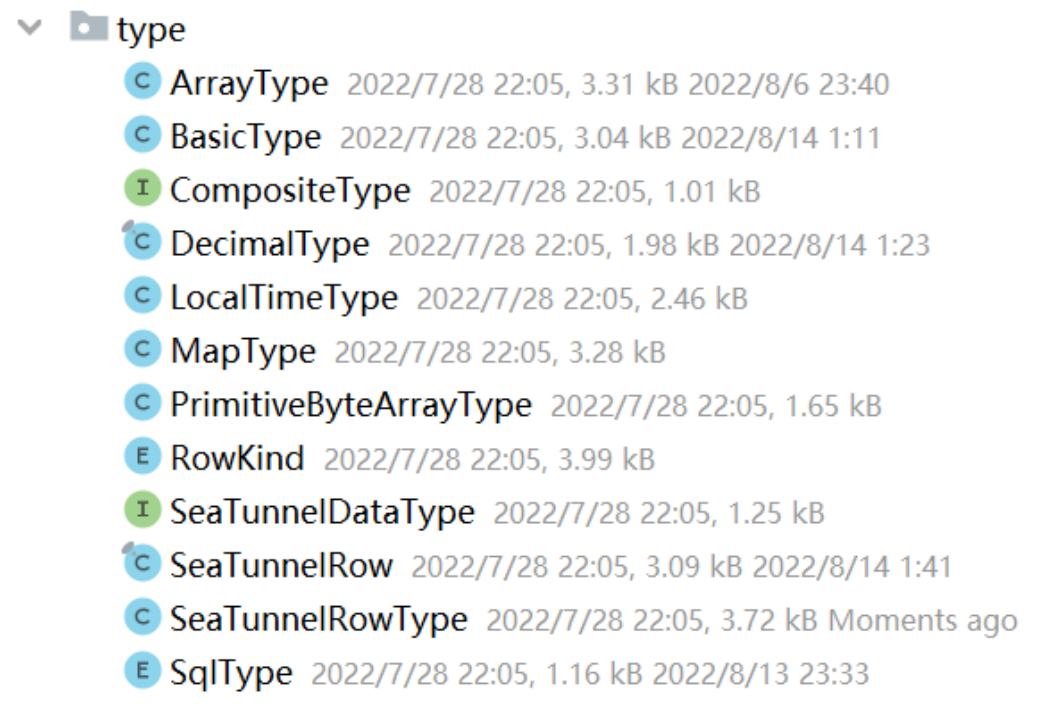
3
连接器 API Common
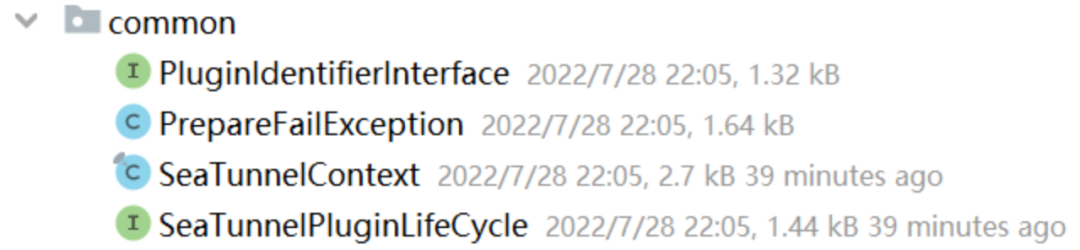
4
连接器 API Source
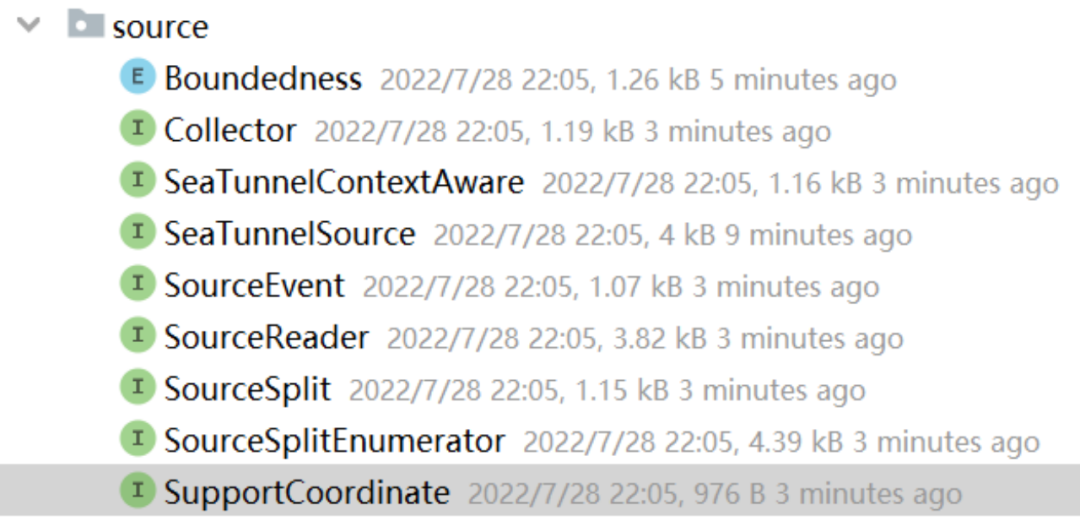
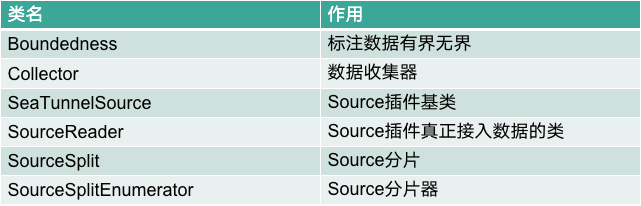
5
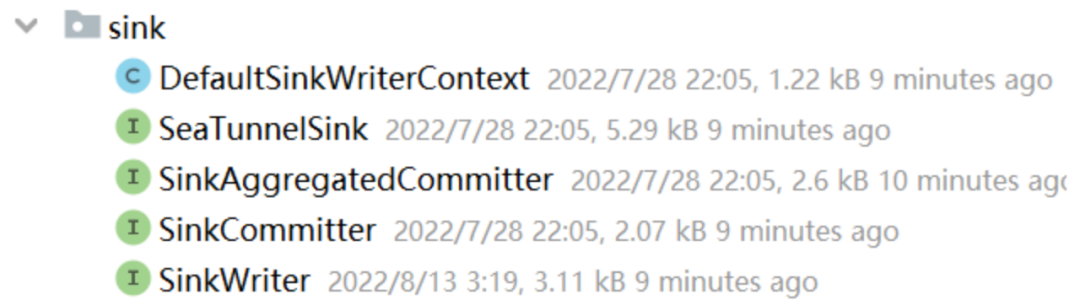
连接器 API Sink
OpenMLDB Source示例
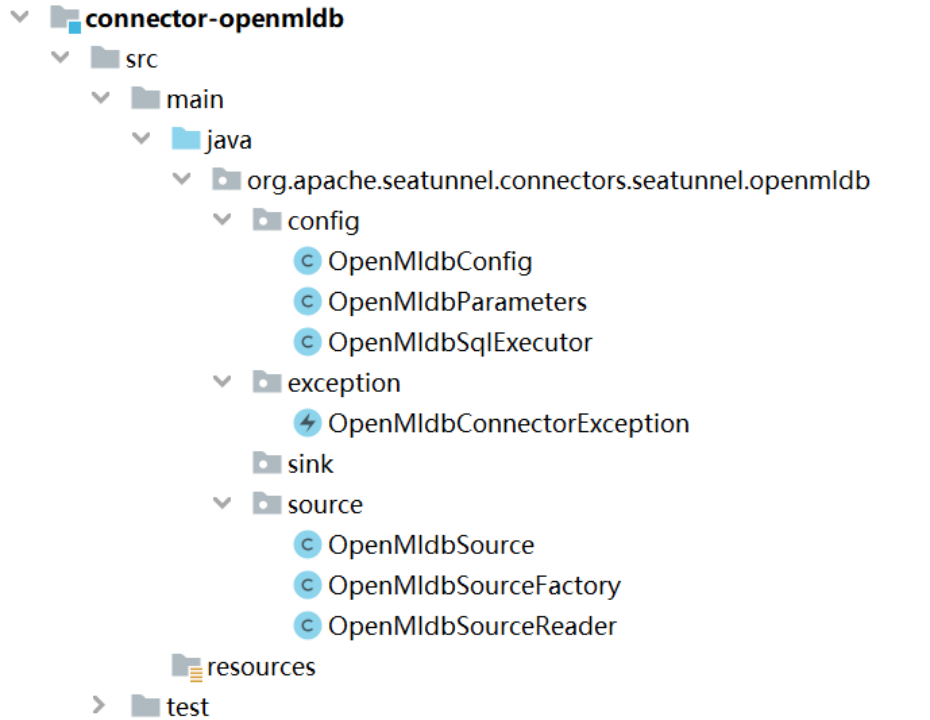
OpenMLDB Source 配置
env {job.name = “openmldb_to_console”job.mode = “BATCH”}source {OpenMldb {host = "172.17.0.2"port = 6527sql = "select * from demo_table1"database = "demo_db"cluster_mode = false}}sink {Console {}}
如何快速参与贡献


Apache SeaTunnel

往期推荐
分享、点赞、在看,给个3连击呗!

文章转载自SeaTunnel,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
