




点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!
Redis是典型的单线程架构,所有的读写操作都是在一条主线程中完成的。当redis用于高并发场景时,这个线程就变的非常重要。如果出现阻塞,即使是时间很短,对应用也可能产生很大的影响。本文将一一分析导致阻塞的原因。
不合理地使用API或数据结构
127.0.0.1:6379> SLOWLOG GET 3
1- 1) (integer) 14 # 唯一性(unique)的日志标识符
2) (integer) 1522808219 # 被记录命令的执行时间点,以 UNIX 时间戳格式表示
3) (integer) 16 # 查询执行时间,以微秒为单位
4) 1) "keys" # 执行的命令,以数组的形式排列
2) "*" # 这里完整的命令是 "keys *"
2- 1) (integer) 13
2) (integer) 1522808215
3) (integer) 7
4) 1) "set"
2) "name"
3) "baicai"
3- 1) (integer) 12
2) (integer) 1522808198
3) (integer) 101
4) 1) "set"
2) "age"
3) "25"
[root@ecs-7e58 add-nomal-key]# redis-cli --bigkeys -h 127.0.0.1 -p 6379
# Scanning the entire keyspace to find biggest keys as well as
# average sizes per key type. You can use -i 0.1 to sleep 0.1 sec
# per 100 SCAN commands (not usually needed).
[00.00%] Biggest zset found so far '"zset_32_4769"' with 10 members
[00.00%] Biggest set found so far '"set_32_1808"' with 10 members
[00.00%] Biggest list found so far '"list_32_3402"' with 10 items
[00.00%] Biggest string found so far '"string_32_1957"' with 32 bytes
[00.00%] Biggest hash found so far '"hash_32_1481"' with 10 fields
-------- summary -------
Sampled 50000 keys in the keyspace!
Total key length in bytes is 604470 (avg len 12.09)
Biggest list found '"list_32_3402"' has 10 items
Biggest hash found '"hash_32_1481"' has 10 fields
Biggest string found '"string_32_1957"' has 32 bytes
Biggest set found '"set_32_1808"' has 10 members
Biggest zset found '"zset_32_4769"' has 10 members
10000 lists with 100000 items (20.00% of keys, avg size 10.00)
10000 hashs with 100000 fields (20.00% of keys, avg size 10.00)
10000 strings with 320000 bytes (20.00% of keys, avg size 32.00)
0 streams with 0 entries (00.00% of keys, avg size 0.00)
10000 sets with 100000 members (20.00% of keys, avg size 10.00)
10000 zsets with 100000 members (20.00% of keys, avg size 10.00)
[root@localhost src]# redis-cli -h 127.0.0.1 --stat
------- data ------ --------------------- load -------------------- - child -
keys mem clients blocked requests connections
3789785 3.62G 601 0 8867956733 (+1) 555884
3789785 3.62G 601 0 8867956734 (+63904) 555884
3789785 3.62G 601 0 8867956733 (+62091) 555884
3789785 3.62G 601 0 8867956734 (+66999) 555884
3789785 3.62G 601 0 8867956398 (+65987) 555884
3789785 3.62G 601 0 8867956733 (+69876) 555884
Cmdstat_hset:calls =198757512,usec=27021957243,usec_per_call=135.95
根本原因为实例为了追求低内存消耗,过度放宽ziplist使用条件(修改了hash-max-ziplist-entries和hash-max-ziplist-value配置)。进程内的hash对象平均存储着上万个元素,而针对ziplist的操作算法复杂度在O(n)到O(n^2)之间。虽然用ziplist编码后hash结构内存占用会变小,但是操作变得更慢且更消耗CPU。
持久化阻塞
fork阻塞 fork操作发生在RDB和AOF重写时,redis主线程调用fork操作产生共享内存的子进程,由子进程完成持久化文件的重写工作。如果fork操作本身耗时过长,必然后导致主线程的阻塞。 可以执行info stats命令获取到latest_fork_usec指标,表示redis最近一次fork操作耗时,如果耗时很大,超过1秒,则需要做出优化调整,如避免使用过大的内存实例和规避fork缓慢的操作系统等。
aof刷盘阻塞 当我们开启AOF刷盘功能时,文件刷新的方式一般是采用每秒一次,后台线程每秒对AOF文件做fsync操作。当硬盘压力过大时,fsync操作需要等待,直到写入完成。如果主线程发现距离上一次的fsync成功超过2秒,为了数据安全性它会阻塞直到后台线程执行fsync操作完成。这种阻塞方式行为主要是硬盘压力引起。可以查看redis日志识别出这种情况。也可以查看info persistence统计中的AOF_DELAYED_FSYNC指标,每次发生fdatasync阻塞主线程时会累加。
hugepage写操作阻塞 子进程在执行重写其间利用linux写时复制技术降低内存的开销,因此只有写操作时redis才复制要修改的内存页。对于开启透明大页操作操作系统,每次写命令引起的复制内存页单位由4K变为2MB,放大了512倍,会拖慢写操作的执行时间,导致大量写操作慢查询。比如简单的incr命令也会出现在慢查询中。
CPU竞争
因此对于开启了持久化或参与复制的主节点不建议绑定CPU。
内存交换
识别redis内存交换的检查方法如下:
查询redis进程号 redis-cli -p 6379 info server |grep process_id 或者 ps -ef|grep redis 根据进程号查询内存交换信息 cat proc/4476/smaps|grep -i swap
如果交换量都是0kb或者个别的是4KB,则是正常现象,说明redis进程内存没有被交换,预防内存交换的方法有:
保证机器有充足的物理可用内存。 设置redis最大可用内存,防止极端情况下redis内存不可控增长。 降纸swap优化级。如:echo 10>/proc/sys/vm/swappiness。
网络问题
Redis-cli -p 6379 info stats |grep rejected_connections
Rejected_connections:10
进程限制
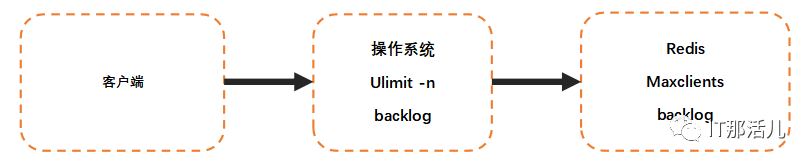
客户端能成功连接上Redis服务需要操作系统和redis的限制都通过才可以成功。操作系统一般会对进程使用的资源做限制,其中一项是对进程可打开最大文件数控制,通过ulimit -n 查看,默认是1024。由于linux系统对TCP连接也定义为一个文件句柄,因此对于支撑大量连接的redis需要调整ulimit值。一般建议为65535,防止too many open files错误。
Backlog队列溢出
1031 times the listen queue of a socket overflowed
网络延迟取决于客户端到redis服务器之间的网络环境。主要包括它们之间的物理拓扑和带宽占用情况。
常见的物理拓扑按网络延迟由快到慢可分为:同物理机>同机架>跨机架>同机房>同城机房>异地机房。
Redis提供了测量机器之间网络延迟的工具,在redis-cli 命令后加入参数进行测试:
--latency:持续进行测试,分别统计:最小值,最大值,平均值,采样次数。 --latency-history:同latency,但15s统计一次,可通过-i参数设置开始时间。 --latency-dist :用统计图形式展示延迟统计,每1秒进行采样一次。
本文作者:鲁伟锋(上海新炬中北团队)
本文来源:“IT那活儿”公众号

