




D语言教程
D编程语言是一种面向对象的多范型系统编程语言。 D编程实际上是通过重新设计的C + +编程语言开发的,但它是不同的编程语言,它不仅发生在C + +中的一些功能,而且引入其他其它语言,如Java,C#,Python和Ruby的某些功能。
本教程将涵盖各种主题包括:D编程语言及其在各种应用范围的基础知识。
D编程语言是由Digital火星Walter Bright开发的面向对象的多范型系统编程语言。它的发展始于1999年,并于2001年首次发布,D(1.0)的主要版本发布于2007年,目前有D2版本的D语言
D是有语法是C风格,并使用静态类型语言。有C和C ++的许多功能在D中使用,但也有一些功能从D.一些值得注意添加到D包括这些不包括语言部分,
- 单元测试
- True 模块
- 垃圾回收
- 第一级数组
- 免费开放
- 关联数组
- 动态数组
- 内部类
- 闭包
- 匿名函数
- 懒计算/加载
多范式
D是一个多范式编程语言。多重范式包括,
- 继承
- 面向对象
- 元编程
- 函数化
- 并发
示例代码:
import std.stdio;
void main(string[] args)
{
writeln("Hello World!");
}
学习D语言
学习D语言时,需要做的最重要的事情是把重点放在概念,而不是迷失在语言技术细节。
学习一种编程语言的目的是要成为一个更好的程序员;也就是说,要成为更有效地设计和实施新系统和维护旧的。
D语言适用范围
D语言编程有一些有趣的功能,并在官方D语言编程网站声称,D语言方便容易,强大而高效。 D编程增加了许多功能,其中C语言标准库,如可调整大小的数组和字符串函数的形式提供了核心语言。 D语言是中高级程序员的一个很好的第二语言。 D编程在处理和内存管理,更好地解决了C+ +指针的麻烦。
D语言编程的目的主要是对新的方案,转换现有方案。它提供了内置的测试和验证的适用于大型新项目,将通过大型团队写入数百万行的代码。
读者
本教程是为所有那些正在寻找学习D语言人所准备的,我们涵盖的主题适用于初学者和高级用户。
必备条件
在继续学习本教程前,建议了解计算机编程的基本知识概念。但本教程能够学习D语言的各种概念,即使是一个初学者。只需要拥有一个简单的文本编辑器和命令行工具。
D语言概述,D语言是什么? - D语言教程
D编程语言是由Digital火星Walter Bright开发的面向对象的多范型系统编程语言。它的发展始于1999年,并于2001年首次发布,D(1.0)的主要版本发布于2007年,目前有D2版本的D语言
D是有语法是C风格,并使用静态类型语言。有C和C ++的许多功能在D中使用,但也有一些功能从D.一些值得注意添加到D包括这些不包括语言部分,
- 单元测试
- True 模块
- 垃圾回收
- 第一级数组
- 免费开放
- 关联数组
- 动态数组
- 内部类
- 闭包
- 匿名函数
- 懒计算/加载
多范式
D是一个多范式编程语言。多重范式包括,
- 继承
- 面向对象
- 元编程
- 函数化
- 并发
示例代码:
import std.stdio;
void main(string[] args)
{
writeln("Hello World!");
}
学习D语言
学习D语言时,需要做的最重要的事情是把重点放在概念,而不是迷失在语言技术细节。
学习一种编程语言的目的是要成为一个更好的程序员;也就是说,要成为更有效地设计和实施新系统和维护旧的。
D语言适用范围
D语言编程有一些有趣的功能,并在官方D语言编程网站声称,D语言方便容易,强大而高效。 D编程增加了许多功能,其中C语言标准库,如可调整大小的数组和字符串函数的形式提供了核心语言。 D语言是中高级程序员的一个很好的第二语言。 D编程在处理和内存管理,更好地解决了C+ +指针的麻烦。
D语言编程的目的主要是对新的方案,转换现有方案。它提供了内置的测试和验证的适用于大型新项目,将通过大型团队写入数百万行的代码。
D语言开发环境设置 - D语言教程
本地开发环境设置
如果愿意设置您的D编程语言环境,需要在计算机上准备以下两个软件,(一)文本编辑器,(二)D编译器。
文本编辑器
这将被用来键入程序。几个编辑的例子包括Windows记事本,操作系统Edit命令,Emacs和VIM或VI。
名称和版本的文本编辑器可以改变不同的操作系统上。例如,记事本将用在Windows,和vim或VI可以在Windows上使用,以及Linux或UNIX。
编辑器中创建的文件称为源文件和包含程序的源代码。对于D程序源文件以扩展名为 ".d".
在开始编程之前,请确保有适当一个文本编辑器,并有足够的经验,编写计算机程序,它保存在一个文件中,构建它,最后执行它。
D编译器
大多数当前D语言实现直接编译成机器代码开提高执行效率。
我们拥有多种D编译器可用,它包括以下。
- DMD - Digital Mars D编译器是官方的D编译器通过Walter Bright提供。
- GDC - 一个前端为GCC的后端,建立了使用开放式的DMD编译器源代码。
- LDC - 基于DMD的前端使用LLVM作为它的编译器后端编译器。
上述不同的编译器可以从以下网址下载 D 下载
我们将使用D版2,我们建议不要下载D1。
让我们来helloWorld.d如下。我们将以此作为我们运行在选择的平台的第一个程序。
import std.stdio;
void main(string[] args)
{
writeln("Hello World!");
}
在Windows上安装
下载Windows的installer。
运行下载的可执行文件来安装,可以按照屏幕上的指示来完成对D的安装。
现在我们可以构建和运行文件,通过切换到文件夹使用cd进入包含该文件,然后使用下面的步骤执行helloWorld.d
C:DProgramming> DMD helloWorld.d
C:DProgramming> helloWorld
我们可以看到下面的输出。
hello world
C: DProgramming是文件夹,使用来保存代码。可以将其更改为已保存的D程序的文件夹。
安装在Ubuntu/Debian
下载debian installer.
运行下载的可执行文件来安装,可以通过下面的屏幕上intructions完成。
现在我们可以构建和运行文件,通过切换到文件夹使用cd进入包含该文件,然后使用下面的步骤执行helloWorld.d
$ dmd helloWorld.d
$ ./helloWorld
我们可以看到下面的输出。
$ hello world
安装在Mac OS X
下载 Mac installer.
运行下载的可执行文件来安装,可以按照屏幕上的指示来完成。
现在我们可以构建和运行文件,通过切换到文件夹使用cd进入包含该文件,然后使用下面的步骤执行helloWorld.d
$ dmd helloWorld.d
$ ./helloWorld
我们可以看到下面的输出。
$ hello world
安装 Fedora
下载 fedora installer.
运行下载的可执行文件来安装,可以按照屏幕上的指示来完成。
现在我们可以构建和运行文件,通过切换到文件夹使用cd进入包含该文件,然后使用下面的步骤执行helloWorld.d
$ dmd helloWorld.d
$ ./helloWorld
我们可以看到下面的输出。
$ hello world
安装在OpenSUSE
下载OpenSUSE installer.
运行下载的可执行文件来安装,可以按照屏幕上的指示来完成。
现在我们可以构建和运行文件,通过切换到文件夹使用cd进入包含该文件,然后使用下面的步骤执行helloWorld.d
$ dmd helloWorld.d
$ ./helloWorld
我们可以看到下面的输出。
$ hello world
D IDE
我们在大多数情况下,对于D IDE支持的插件的形式。这包括
- Visual D plugin是Visual Studio2005-13 的一个插件
- DDT 是一个Eclipse插件,它提供代码完成,用GDB调试。
- Mono-D 代码完成,重构与DMD/ LDC/ GDC支持。它一直是GSoC2012的一部分。
- 代码块 是一个支持开发项目的创建,突出显示和调试多平台的IDE。
D语言基本语法 - D语言教程
D语言是相当简单易学的,让我们开始创建我们的第一个D程序!
第一个D程序
让我们写一个简单的D程序。所有d文件将具有扩展名.d。所以,把下面的源代码保存在test.d文件中。
import std.stdio;
void main(string[] args)
{
writeln("test!");
}
假设,D正确设置环境,让运行使用的编程:
$ dmd test.d
$ ./test
我们将得到下面的输出。
test
现在,让我们看到了D程序的基本结构,轻松了解D编程语言的基本构建块。
导入D中
程序库这是可重用的程序部分的集合,可以提供给我们的项目导入的帮助。在这里,我们导入了标准IO库,它提供了基本的I/O操作。 writeln这是用来在上述程序是在D的标准库函数。它是用于打印一行文本。在D库内容被分成模块,是基于他们打算执行的任务的类型。这个程序使用的唯一模块是std.stdio,它处理数据的输入和输出。
main函数
主函数是在程序的开始,它决定执行和如何程序的其它部分应该被执行的顺序。
D中的令牌
D程序由不同的令牌和令牌可以是一个关键字,标识符,常量,字符串文字或符号。例如,下面的Lua语句由四个标记:
writeln("test!");
单个标记是:
writeln
(
"test!"
)
;
注释
注释就像帮助文本在D程序,它们会被编译器忽略。多行注释以/开始,并以/终止,如下图所示的字符:
/* my first program in D */
单注释在注释的开头使用//
// my first program in D
标识符
D标识符是用于标识变量,函数,或任何其它用户定义的项目的名称。一个标识符开始于一个字母A到Z或a到z或下划线_后跟零个或多个字母,下划线和数字(0〜9)。
D不容许标识符中的标点符号,如@,$和%。 D是区分大小写的编程语言。因此,Manpower和manpower都在Lua两个不同的标识符。这里是可接受的标识符的一些例子:
mohd zara abc move_name a_123
myname50 _temp j a23b9 retVal
关键词
下面的列表显示了一些这些保留字不能用作常量或变量或任何其他标识符的名称,在D中的保留字。
abstract | alias | align | asm |
assert | auto | body | bool |
byte | case | cast | catch |
char | class | const | continue |
dchar | debug | default | delegate |
deprecated | do | double | else |
enum | export | extern | false |
final | finally | float | for |
foreach | function | goto | if |
import | in | inout | int |
interface | invariant | is | long |
macro | mixin | module | new |
null | out | override | package |
pragma | private | protected | public |
real | ref | return | scope |
short | static | struct | super |
switch | synchronized | template | this |
throw | true | try | typeid |
typeof | ubyte | uint | ulong |
union | unittest | ushort | version |
void | wchar | while | with |
D中空格
仅包含空格,可能与注释,被称为一个空行,D编译器线完全忽略它。
空白在D用来描述空格,制表符,换行符和注释的术语。空格分隔从另一个语句的一部分,使解释,以确定其中在一份声明中,如int,一个元素的结束和下一个元素开始。因此,在下面的语句:
local age
必须有至少一个空白字符(通常是一个空格)local 和 age 之间的解释器能够区分它们。另一方面,如下面的陈述。
int fruit = apples + oranges //get the total fruits
空格字符是非必要的,在 fruit 和=之间,或=和apples,是自由使用的。
D语言变量 - D语言教程
变量是什么,但考虑到一个存储区域,我们的程序可以操纵的名称。在D语言中的各变量具有特定的类型,它决定了变量的存储器的大小和布局;能该存储器内存储的值的范围;和设置操作,可以被应用到变量中。
变量的名称可以由字母,数字和下划线字符。它必须以字母或下划线。大写和小写字母是不同的,因为D语言是区分大小写的。根据这个基本类型在前面的章节中解释的那样,会有以下几个基本变量类型:
Type | 描述 |
char | 通常一个八位字节(1字节)。这是一个整数类型。 |
int | 最自然的机器的整数大小。 |
float | 单精度浮点值。 |
double | 双精度浮点值。 |
void | 表示不存在类型。 |
D编程语言还允许定义各种其他类型的变量,我们将覆盖像枚举,指针,数组,结构,联合,等后面的章节对于本章中,我们只学习基本的变量类型。
在D语言中变量定义:
变量的定义是指,告诉编译器在哪里和多少来创建存储的变量。变量定义指定了数据类型,并且包含的该类型的一个或多个变量如下的列表:
type variable_list;
在这里,类型必须是包括char, wchar, int, float, double, bool或任何用户定义的对象等有效D语言的数据类型,并且variable_list可能包含由逗号分隔的一个或多个标识符名称。一些有效的声明如下所示:
int i, j, k;
char c, ch;
float f, salary;
double d;
该行int i, j, k; 既声明并定义了变量i,j和K;这指示编译器创建一个 int类型的 i, j 和 k变量。
变量可以被初始化在他们的声明中(分配一个初始值)。在初始化由一个等号后面的常量表达式如下:
type variable_name = value;
一些实例是:
extern int d = 3, f = 5; // declaration of d and f.
int d = 3, f = 5; // definition and initializing d and f.
byte z = 22; // definition and initializes z.
char x = 'x'; // the variable x has the value 'x'.
对于没有初始化的定义:具有静态存储变量与隐式初始化为NULL(所有字节的值为0);所有其他变量的初始值是不确定的。
在D中的变量声明:
变量声明所提供的保证编译器,一个变量与给定的类型和名称的现有从而使编译器进行进一步的编辑,而不需要对变量了解完整细节。变量声明有其意义在编译的时候,编译器只需要实际的变量声明在程序链接的时候。
示例
试试下面的例子,其中的变量都在顶部被声明,但他们已经定义并初始化主函数中:
import std.stdio;
int a = 10, b =10;
int c;
float f;
int main ()
{
writeln("Value of a is : ", a);
/* variable re definition: */
int a, b;
int c;
float f;
/* Initialization */
a = 30;
b = 40;
writeln("Value of a is : ", a);
c = a + b;
writeln("Value of c is : ", c);
f = 70.0/3.0;
writeln("Value of f is : ", f);
return 0;
}
让我们编译和运行上面的程序,这将产生以下结果:
Value of a is : 10
Value of a is : 30
Value of c is : 70
Value of f is : 23.3333
在D语言中左值和右值:
D中有两种类型的表达式:
- lvalue : 这是一个左值的表达式可能会出现无论是左值或右值。
- rvalue : 这是一个右值表达式可以出现在赋值的右值而不是左值。
变量是左值,因此可能会出现在赋值的左值。数值常量是右值,所以不得转让,不能出现在左值。下面是一个有效的语句:
int g = 20;
但以下情况不属有效的语句,并会产生编译时错误:
10 = 20;
D语言数据类型 - D语言教程
在D编程语言,数据类型是指用于不同类型的声明变量或函数的全面系统。一个变量的类型决定了空间占用的存储,以及如何存储的比特模式的解释。
D中的类型可分类如下:
S.N. | 类型和说明 |
1 | 基本类型: 此算术类型并包含三种类型:(一)整数类型,(B)浮点类型(三)字符类型 |
2 | 枚举类型: 此算术类型和它们用于定义可以只在整个节目被分配若干离散的整数值的变量。 |
3 | void类型: 此类型说明符无效表示没有值可用。 |
4 | 派生类型: 它们包括(一)指针类型,(B)数组类型,(三)结构类型,(四)联合的类型及(e)函数类型。 |
数组类型和结构类型统称为聚合类型。一个函数的类型指定函数的返回值的类型。我们会看到基本类型在下面的部分,而其他类型将包括在下一章节。
整数类型
下表提供了有关其存储大小和值范围标准的整数类型的详细信息:
类型 | 存储大小 | 值范围 |
bool | 1 byte | false or true |
byte | 1 byte | -128 to 127 |
ubyte | 1 byte | 0 to 255 |
int | 4 bytes | -2,147,483,648 to 2,147,483,647 |
uint | 4 bytes | 0 to 4,294,967,295 |
short | 2 bytes | -32,768 to 32,767 |
ushort | 2 bytes | 0 to 65,535 |
long | 8 bytes | -9223372036854775808 to 9223372036854775807 |
ulong | 8 bytes | 0 to 18446744073709551615 |
为了得到一个类型或一个变量的确切大小,可以使用 sizeof 运算符。表达式类型(的sizeof),得到以字节为单位的对象或类型的存储大小。下面是一个示例得到任何机器上int型的大小:
import std.stdio;
int main()
{
writeln("Length in bytes: ", ulong.sizeof);
return 0;
}
当编译并执行上面的程序,它会产生以下结果:
Length in bytes: 8
浮点类型
下表提供了有关使用存储大小和值范围标准浮点数类型及其用途的详细信息
类型 | 存储大小 | 值范围 | 目的 |
float | 4 bytes | 1.17549e-38 to 3.40282e+38 | 6 位小数 |
double | 8 bytes | 2.22507e-308 to 1.79769e+308 | 15 位小数 |
real | 10 bytes | 3.3621e-4932 to 1.18973e+4932 | 硬件支持无论是最大浮点型或双;较大者为准 |
ifloat | 4 bytes | 1.17549e-38i to 3.40282e+38i | 浮虚值类型 |
idouble | 8 bytes | 2.22507e-308i to 1.79769e+308i | double虚值类型 |
ireal | 10 bytes | 3.3621e-4932 to 1.18973e+4932 | 实虚值类型 |
cfloat | 8 bytes | 1.17549e-38+1.17549e-38i to 3.40282e+38+3.40282e+38i | 由两个浮点数复数类型 |
cdouble | 16 bytes | 2.22507e-308+2.22507e-308i to 1.79769e+308+1.79769e+308i | 由两个双复数类型 |
creal | 20 bytes | 3.3621e-4932+3.3621e-4932i to 1.18973e+4932+1.18973e+4932i | 由两个实数,复数类型 |
下面的例子将打印所采用的是一个float类型及其范围值的存储空间:
import std.stdio;
int main()
{
writeln("Length in bytes: ", float.sizeof);
return 0;
}
当编译并执行上述程序,它产生在Linux下面的结果:
Storage size for float : 4
字符类型
下表提供了有关与存储大小,其目的标准字符类型的详细信息。
类型 | 存储大小 | 目的 |
char | 1 byte | UTF-8 code unit |
wchar | 2 bytes | UTF-16 code unit |
dchar | 4 bytes | UTF-32 code unit and Unicode code yiibai |
下面的例子将打印用一个char类型的存储空间。
import std.stdio;
int main()
{
writeln("Length in bytes: ", char.sizeof);
return 0;
}
当编译并执行上面的程序,它会产生以下结果:
Storage size for float : 1
void类型
void类型指定任何值可用。这是用在两种情况:
S.N. | 类型及描述 |
1 | 函数返回 void 在D语言中的各种函数没有返回值,也可以说他们返回void。没有返回值的函数的返回类型为void。例如, void exit (int status); |
2 | 函数参数为 void 有D中的各种功能不接受任何参数。不带参数的函数可以接受一个空白。例如, int rand(void); |
void类型在这一点上可能不被理解,所以让我们继续,我们将在后面的章节这些概念。
D语言枚举Enums - D语言教程
枚举用于定义命名常量的值。枚举类型是使用enum关键字声明的。
枚举语法
枚举定义的最简单的形式是这样的:
enum enum_name {
enumeration list
}
那么,
- enum_name指定枚举类型名称。
- 枚举列表是一个逗号分隔的标识符列表。
每个枚举列表中的符号代表一个整数值,比它前面的符号一个更大的。默认情况下,第一个枚举符号的值是0,例如:
enum Days { sun, mon, tue, wed, thu, fri, sat };
示例:
下面的示例演示使用枚举变量:
import std.stdio;
enum Days { sun, mon, tue, wed, thu, fri, sat };
int main(string[] args)
{
Days day;
day = Days.mon;
writefln("Current Day: %d", day);
writefln("Friday : %d", Days.fri);
return 0;
}
当上面的代码被编译并执行,它会产生以下结果:
Current Day: 1
Friday : 5
在上面的程序中,我们可以看到如何枚举都可以使用。最初,我们创建用户定义的枚举Days,一个命名的变量day。然后,我们将它使用点运算符设置为mon。需要使用writefln方法打印周一的是被存储的值。您还需要指定类型。在这里,它的整数类型,所以我们使用%d。
命名枚举的属性
在上面的例子中使用了名称为Days枚举,被称为命名枚举。这些命名枚举具有以下性质
- init 初始化枚举中的第一个值。
- min 返回枚举的最小值。
- max 返回枚举的最大值。
- size 返回存储的大小为枚举。
让我们修改前面的例子来使用属性。
import std.stdio;
// Initialized sun with value 1
enum Days { sun =1, mon, tue, wed, thu, fri, sat };
int main(string[] args)
{
writefln("Min : %d", Days.min);
writefln("Max : %d", Days.max);
writefln("Size of: %d", Days.sizeof);
return 0;
}
让我们编译和运行上面的程序,这将产生以下结果:
Min : 3
Max : 9
Size of: 4
匿名枚举
枚举没有名字叫做匿名枚举。匿名枚举的例子如下。
import std.stdio;
// Initialized sun with value 1
enum { sun , mon, tue, wed, thu, fri, sat };
int main(string[] args)
{
writefln("Sunday : %d", sun);
writefln("Monday : %d", mon);
return 0;
}
让我们编译和运行上面的程序,这将产生以下结果:
Sunday : 0
Monday : 1
匿名枚举工作几乎与命名枚举方式一样,但不具有最大值,最小值和sizeof属性。
用枚举的基本类型
基类型为枚举的语法如下所示。
enum :baseType {
enumeration list
}
一些基本类型包括 long, int和string。使用long的例子如下所示。
import std.stdio;
enum : string {
A = "hello",
B = "world",
}
int main(string[] args)
{
writefln("A : %s", A);
writefln("B : %s", B);
return 0;
}
让我们编译和运行上面的程序,这将产生以下结果:
A : hello
B : world
更多功能
枚举在D语言中提供与多种类型的枚举像多个值的初始化功能。例子如下所示。
import std.stdio;
enum {
A = 1.2f, // A is 1.2f of type float
B, // B is 2.2f of type float
int C = 3, // C is 3 of type int
D // D is 4 of type int
}
int main(string[] args)
{
writefln("A : %f", A);
writefln("B : %f", B);
writefln("C : %d", C);
writefln("D : %d", D);
return 0;
}
让我们编译和运行上面的程序,这将产生以下结果:
A : 1.200000
B : 2.200000
C : 3
D : 4
D语言常值 - D语言教程
被输入了该程序的源代码的部分恒定值称为 literals.
常值可以是任何基本数据类型,可以分为整数数字,浮点数字,字符,字符串和布尔值。
再次,文字将视为就像普通变量不同之处在于它们的值,不能在他们的定义后进行修改。
整数文字:
整数文字可以是如下类型:
- 十进制:使用与第一个数字是平日的定位表示不能为0作为数字被保留用于表示八进制。这不包括0自身:0是零。
- 八进制:使用0作为前缀码。
- 二进制:使用0b或0B作为前缀
- 十六进制:使用0x或0X作为前缀。
整数文字也可以有一个后缀为U和L的组合,对于无符号长分别。后缀可以是大写或小写,并且可以以任何顺序。
当你不使用后缀根据值的大小:int, uint, long 和 ulong 由编译器本身选择。
这里是整数常量的一些例子:
212 // Legal
215u // Legal
0xFeeL // Legal
078 // Illegal: 8 is not an octal digit
032UU // Illegal: cannot repeat a suffix
以下是不同类型的整型常量的其他例子:
85 // decimal
0213 // octal
0x4b // hexadecimal
30 // int
30u // unsigned int
30l // long
30ul // unsigned long
0b001 // binary
浮点文本:
浮点常量可以以十进制系统在1.568或十六进制被指定为0x91.bc.
在十进制系统中,指数可以通过将字符e或E和一个数字后表示。例如,2.3e4表示“2.3倍10到4的幂值”。 A +字符可能指数前值来指定,但没有效果。例如2.3e4和2.3E+4是相同的。- 字符前加指数的值改变了含义,“除以10的幂值”。例如,2.3E-2表示“2.3除以10,以2的幂”。
在十六进制系统,该值以任何0x或0X。该指数是由p或P指定的,而不是e或E的指数并不意味着“10的幂”,但“2的幂”。例如,在0xabc.defP4 P4的意思是“abc.de时间2到4的电源”。
下面是浮点常量的一些例子:
3.14159 // Legal
314159E-5L // Legal
510E // Illegal: incomplete exponent
210f // Illegal: no decimal or exponent
.e55 // Illegal: missing integer or fraction
0xabc.defP4 // Legal Hexa decimal with exponent
0xabc.defe4 // Legal Hexa decimal without exponent.
默认情况下,一个浮点字面的类型是double。f和F平均浮点值,以及L说明符是指真实的。
布尔文字:
有两个布尔文字,他们是标准的D关键字的一部分:
- 真实代表true值。
- 虚假表示false值。
不应该考虑true等于1值和false等于0值。
字符文字:
字符常量单引号括起来。
字符文字可以是一个普通的字符(e.g., 'x'), 转义序列 (e.g., ' '), ASCII 字符(e.g., 'x21'), Unicode 字符(e.g., 'u011e') 或作为命名字符 (e.g. '©','♥', '€' ).
有某些字符在D中,当他们前面加一个反斜杠,他们将有特殊的含义,它们是用来表示相同的换行符( n)或制表符( t)。在这里,有一些这样的转义序列代码的列表:
转义序列 | 含意 |
\\ | \ character |
\' | ' character |
\" | " character |
\? | ? character |
\a | Alert or bell |
\b | Backspace |
\f | Form feed |
\n | Newline |
\r | Carriage return |
\t | Horizontal tab |
\v | Vertical tab |
下面是例子来说明几个转义序列字符:
import std.stdio;
int main(string[] args)
{
writefln("Hello World%c
",'x21');
writefln("Have a good day%c",'x21');
return 0;
}
当上面的代码被编译并执行,它会产生以下结果:
Hello World!
Have a good day!
字符串文字:
字符串文本括在双引号中。一个字符串包含的字符类似于字符文字:普通字符,转义序列和通用字符。
可以打破一个长行到使用字符串文字多行,用空格分开。
下面是字符串字面量的例子。
import std.stdio;
int main(string[] args)
{
writeln(q"MY_DELIMITER
Hello World
Have a good day
MY_DELIMITER");
writefln("Have a good day%c",'x21');
auto str = q{int value = 20; ++value;};
writeln(str);
在上面的例子中,可以找到使用q“MY_DELIMITER MY_DELIMITER”来表示多行字符。此外,还可以看到q{}来表示一个D语言语句本身。
D语言运算符 - D语言教程
运算符是一个符号,它告诉编译器执行特定的数学或逻辑操作。 D语言是丰富的内置运算符和运算符提供的以下几种类型:
- 算术运算符
- 关系运算符
- 逻辑运算符
- 位运算符
- 赋值运算符
- 其它运算符
本教程将讲解算术,关系,逻辑,位,赋值等运算符。
算术运算符
下表列出了所有D语言支持的算术运算符。假设变量A=10和变量B=20,则:
运算符 | 描述 | 实例 |
+ | 两个数相加操作 | A + B = 30 |
- | 从第一中减去第二个操作数 | A - B = -10 |
* | 乘两个操作数 | A * B = 200 |
/ | 通过取消分子分裂分子 | B / A = 2 |
% | 模运算符和其余整数除法后 | B % A = 0 |
++ | 递增运算符相加1整数值 | A++ = 11 |
-- | 递减运算符通过减少1整数值 | A-- = 9 |
关系运算符
下表列出了所有D语言支持的关系运算符。假设变量A=10和变量B=20,则:
运算符 | 描述 | 实例 |
== | 检查如果两个操作数的值相等与否,如果是则条件为真。 | (A == B) =not true. |
!= | 检查如果两个操作数的值相等与否,如果值不相等,则条件变为真。 | (A != B) =true. |
> | 检查如果左操作数的值大于右操作数的值,如果是则条件为真。 | (A > B) =not true. |
< | 如果检查左操作数的值小于右操作数的值,如果是则条件为真。 | (A < B) =true. |
>= | 检查如果左操作数的值大于或等于右操作数的值,如果是则条件为真。 | (A >= B) = not true. |
<= | 如果检查左操作数的值小于或等于右操作数的值,如果是则条件为真。 | (A <= B) =true. |
逻辑运算符
下表列出了所有D语言支持的逻辑运算符。假设变量A=1和变量B=0,则:
操作符 | 描述 | 实例 |
&& | 所谓逻辑AND运算符。如果这两个操作数都为非零,则条件变为真。 | (A && B) = false. |
|| | 所谓逻辑或运算符。如果任何两个操作数为非零,则条件变为真。 | (A || B) = true. |
! | 所谓逻辑非运算符。使用反转其操作数的逻辑状态。如果条件为真,则逻辑NOT运算符将得到false。 | !(A && B) =true. |
位运算符
位运算符作用于位和执行逐位操作: &, |, 和 ^ :
p | q | p & q | p | q | p ^ q |
0 | 0 | 0 | 0 | 0 |
0 | 1 | 0 | 1 | 1 |
1 | 1 | 1 | 1 | 0 |
1 | 0 | 0 | 1 | 1 |
假设,如果A=60;及B =13;现在以二进制格式它们将会如下:
A = 0011 1100
B = 0000 1101
-----------------
A&B = 0000 1100
A|B = 0011 1101
A^B = 0011 0001
~A = 1100 0011
由D语言支持的位运算符列于下表中。假设变量A=60和变量B=13,则:
操作符 | 描述 | 实例 |
& | 二进制和拷贝操作了一下,如果它存在于两个操作数的结果。 | (A & B) = 12, 0000 1100 |
| | 二进制或运算符拷贝的位,如果它存在一个操作数中。 | (A | B) = 61, 0011 1101 |
^ | 二进位异或运算符拷贝位,如果它被设置在一个操作数,但不能同时使用。 | (A ^ B) = 49, 0011 0001 |
~ | 二进制的补码运算符是一元的,具有'翻转'位的效果。 | (~A ) = -61, 1100 0011 |
<< | 二进制左移位运算符。左操作数的值被移动由右操作数指定的位数向左移动。 | A << 2 = 240 , 1111 0000 |
>> | 二进制右移运算。左操作数的值是正确的由右操作数指定的位数移动。 | A >> 2 = 15 0000 1111 |
赋值运算符
有下列由D语言支持赋值操作符:
运算符 | 描述 | 示例 |
= | 简单赋值运算符,分配从右侧操作数的值,以左侧操作数 | C = A + B will assign value of A + B into C |
+= | 添加和赋值操作符,它增加了右操作数为左操作数和结果分配给左操作数 | C += A is equivalent to C = C + A |
-= | 减和赋值操作符,它减去右边的操作数从左边的操作数,并将结果赋值给左操作数 | C -= A is equivalent to C = C - A |
*= | 乘法和赋值操作符,它乘以右边的操作数与左操作数和结果分配给左操作数 | C = A is equivalent to C = C A |
/= | 除和赋值操作符,它分为左操作数与右边的操作数,并将结果赋值给左操作数 | C /= A is equivalent to C = C / A |
%= | 模量和赋值操作符,它采用模使用两个操作数和结果分配给左操作数 | C %= A is equivalent to C = C % A |
<<= | 左移位并赋值运算符 | C <<= 2 is same as C = C << 2 |
>>= | 向右移位并赋值运算符 | C >>= 2 is same as C = C >> 2 |
&= | 按位AND赋值运算符 | C &= 2 is same as C = C & 2 |
^= | 按位异或和赋值运算符 | C ^= 2 is same as C = C ^ 2 |
|= | OR运算和赋值运算符 | C |= 2 is same as C = C | 2 |
其它运算符↦的sizeof&三元
还有其他一些重要的运算符,包括的sizeof和? :用D语言的支持。
操作符 | 描述 | 实例 |
sizeof() | 返回一个变量的大小。 | sizeof(a),,其中a是整数,将返回4。 |
& | 返回一个变量的地址。 | &a; 将给变量的实际地址。 |
* | 指向变量的指针。 | *a; 将为指针变量。 |
? : | 条件表达式 | 如条条件为 true ? 那么傎为 X : 否则值为 Y |
D语言运算符优先级
运算符优先级决定的条款在表达式中的分组。这会影响一个表达式如何计算。某些运算符的优先级高于其他;例如,乘法运算符的优先级比加法运算符高。
例如X =7 +3 2;这里,x被赋值13,而不是20,因为运算符的优先级高于+,所以它首先被乘以3 * 2,然后加到7。
这里,具有最高优先级的操作出现在表的顶部,那些具有最低出现在底部。在表达式中,优先级较高的运算符将首先计算。
分类 | 操作符 | 关联 |
Postfix | () [] -> . ++ - - | Left to right |
Unary | + - ! ~ ++ - - (type)* & sizeof | Right to left |
Multiplicative | * / % | Left to right |
Additive | + - | Left to right |
Shift | << >> | Left to right |
Relational | < <= > >= | Left to right |
Equality | == != | Left to right |
Bitwise AND | & | Left to right |
Bitwise XOR | ^ | Left to right |
Bitwise OR | | | Left to right |
Logical AND | && | Left to right |
Logical OR | || | Left to right |
Conditional | ?: | Right to left |
Assignment | = += -= *= /= %=>>= <<= &= ^= |= | Right to left |
Comma | , | Left to right |
D语言循环 - D语言教程
可能有一种情况,当需要执行几个代码块多次。在一般情况下,语句顺序执行:在一个函数的第一条语句,首先执行,然后是第二个,等等。
编程语言提供了各种控制结构,使它能执行更复杂的路径。
循环语句可以让我们执行一个语句或语句组多次,下面是在大多数编程语言中的循环语句的一般形式为:
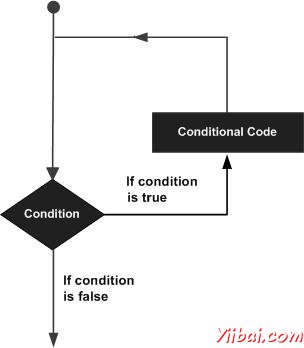
D编程语言提供了循环来循环处理要求以下类型。点击以下链接,查看其详细信息。
循环类型 | 描述 |
重复语句语句或一组,而给定的条件为真。它测试的条件执行循环体之前。 | |
执行语句多次序列,并简略地管理该循环变量的代码。 | |
像一个while语句,除了它测试的条件在循环体的结束 | |
可以使用一个或多个循环内的任何其他while,或do .. while循环。 |
循环控制语句:
循环控制语句从它的正常顺序更改执行。当执行离开一个范围,在该范围内创建的所有自动对象被销毁。
D支持以下控制语句。点击以下链接,查看其详细信息。
控制语句 | 描述 |
终止循环或switch语句,并将执行的语句紧随循环或switch。 | |
导致循环跳过它的主体的其余部分,并立即重新测试它的条件,在重申之前。 |
无限循环:
一个循环变得如果条件永远变为false的无限循环。 for循环是传统上用于此目的。由于没有形成在for循环的三个表达式都是必需的,可以留条件表达式为空时作为一个死循环。
import std.stdio;
int main ()
{
for( ; ; )
{
writefln("This loop will run forever.");
}
return 0;
}
当条件表达式为不存在,它被假定为真。可能有一个初始化和增量表达,而D程序员更普遍使用for(;;)结构来表示一个无限循环。
注意:可以通过按Ctrl + C键终止一个无限循环。
D语言决策语句 - D语言教程
决策结构需要程序员指定一个或多个条件由程序进行评估或测试,以及要执行的语句或语句如果条件被确定为true,并选择,要执行其他语句如果条件被确定为false。
下面是在大多数编程语言中一个典型的决策结构的一般形式为:
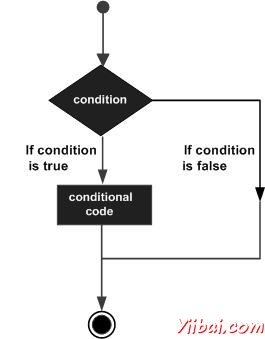
D编程语言假设任何非零和非空值作为true,如果是零或null,则假定为false。
D编程语言提供了以下类型的决策列表。点击以下链接,查看其详细信息。
语句 | 描述 |
if语句由一个布尔表达式后跟一个或多个语句。 | |
一个if语句后面可以跟一个可选的else语句,该语句执行时的布尔表达式为false。 | |
可以使用一个if或else if语句在另一个if或else if语句。 | |
switch语句允许一个变量来对值的列表平等进行测试。 | |
可以使用一个switch语句在另一个switch语句。 |
? : 操作符:
我们已经覆盖条件运算符? :在前面的章节中,可以用来代替if...else 语句。它具有如下一般形式:
Exp1 ? Exp2 : Exp3;
当Exp1, Exp2, 和Exp3是一个表达式。注意到冒号使用和放置。
a值 ? 表达这样的决定: Exp1 被计算, 如果为true, 那么Exp2 被评估,并且变成整个的值。 ? 表达式. 如果Exp1 为false, 那么 Exp3 被评估,并将其值变成表达式的值。
D语言函数 - D语言教程
基本函数的定义
return_type function_name( parameter list )
{
body of the function
}
一个基本的函数定义由函数头和函数体。这里是一个函数的所有部分:
- Return Type: 函数可以返回一个值。该return_type是函数返回值的数据类型。有些函数没有返回值执行所需的操作。在这种情况下,return_type是关键字void.
- Function Name: 这是函数的实际名称。函数名和参数列表一起构成了函数签名。
- Parameters: 参数是像一个占位符。当调用一个函数,传递一个值给该参数。这个值被称为实际参数或参数。参数列表是指类型,顺序和一个函数的参数的数目。参数是可选的;也就是说,一个功能可以包含任何参数。
- Function Body: 函数体包含了定义函数语句的集合。
调用函数
我们可以调用函数使用下面的语法
function_name(parameter_values)
函数类型
D编程支持广泛的函数,它们如下面列出。
- 纯函数
- 抛出异常函数
- 参考函数
- 自动函数
- 可变参数函数
- inout函数
- 属性函数
各种函数功能说明。
纯函数
纯函数是无法通过他们的论据访问全局或静态的,可变的状态保存函数。这可以基于一个事实,即一个纯函数是保证变异不被传递给它什么,并在情况下,编译器可以保证纯函数不能改变它的参数,它可以启用完整,功能纯度(启用优化即保证该函数总是返回相同的结果为相同的参数)。
import std.stdio;
int x = 10;
immutable int y = 30;
const int* p;
pure int purefunc(int i,const char* q,immutable int* s)
{
//writeln("Simple print"); //cannot call impure function 'writeln'
debug writeln("in foo()"); // ok, impure code allowed in debug statement
// x = i; // error, modifying global state
// i = x; // error, reading mutable global state
// i = *p; // error, reading const global state
i = y; // ok, reading immutable global state
auto myvar = new int; // Can use the new expression:
return i;
}
void main()
{
writeln("Value returned from pure function : ",purefunc(x,null,null));
}
当我们运行上面的程序,我们会得到下面的输出。
Value returned from pure function : 30
抛出异常函数
抛出异常函数不会抛出从类Exception派生的任何异常。抛出异常函数是协变与抛出。
抛出异常保证函数不发出任何异常。
import std.stdio;
int add(int a, int b) nothrow
{
//writeln("adding"); This will fail because writeln may throw
int result;
try {
writeln("adding"); // compiles
result = a + b;
}
catch (Exception error) { // catches all exceptions
}
return result;
}
void main()
{
writeln("Added value is ", add(10,20));
}
When we run the above program, we will get the following output.
adding
Added value is 30
参考函数
参考函数允许函数按引用返回。这类似于文献的功能参数。
import std.stdio;
ref int greater(ref int first, ref int second)
{
return (first > second) ? first : second;
}
void main()
{
int a = 1;
int b = 2;
greater(a, b) += 10;
writefln("a: %s, b: %s", a, b);
}
当我们运行上面的程序,我们会得到下面的输出。
a: 1, b: 12
自动函数
自动功能可以返回任何类型的值。有什么类型的要返回的任何限制。一个简单的例子功能自动类型如下。
import std.stdio;
auto add(int first, double second)
{
double result = first + second;
return result;
}
void main()
{
int a = 1;
double b = 2.5;
writeln("add(a,b) = ", add(a, b));
}
当我们运行上面的程序,我们会得到下面的输出。
add(a,b) = 3.5
可变参数函数
可变参数函数是其中一个函数参数的数量,在运行时确定的函数。在C中,存在具有ATLEAST一个参数的限制。但在D编程,不存在这样的限制。一个简单的例子如下所示。
import std.stdio;
import core.vararg;
void printargs(int x, ...) {
for (int i = 0; i < _arguments.length; i++)
{
write(_arguments[i]);
if (_arguments[i] == typeid(int))
{
int j = va_arg!(int)(_argptr);
writefln(" %d", j);
}
else if (_arguments[i] == typeid(long))
{
long j = va_arg!(long)(_argptr);
writefln(" %d", j);
}
else if (_arguments[i] == typeid(double))
{
double d = va_arg!(double)(_argptr);
writefln(" %g", d);
}
}
}
void main()
{
printargs(1, 2, 3L, 4.5);
}
当我们运行上面的程序,我们会得到下面的输出。
int 2
long 3
double 4.5
inout函数
INOUT既可以用于函数的参数和返回类型中使用。这就像为可变的,常量,和不变的模板。可变性属性从参数即inout的转让推导可变性属性的返回类型推断。一个简单的例子说明如何易变性得到改变如下所示。
import std.stdio;
inout(char)[] qoutedWord(inout(char)[] phrase)
{
return '"' ~ phrase ~ '"';
}
void main()
{
char[] a = "test a".dup;
a = qoutedWord(a);
writeln(typeof(qoutedWord(a)).stringof," ", a);
const(char)[] b = "test b";
b = qoutedWord(b);
writeln(typeof(qoutedWord(b)).stringof," ", b);
immutable(char)[] c = "test c";
c = qoutedWord(c);
writeln(typeof(qoutedWord(c)).stringof," ", c);
}
当我们运行上面的程序,我们会得到下面的输出。
char[] "test a"
const(char)[] "test b"
string "test c"
属性函数
属性允许使用像成员变量成员函数。它使用@property关键字。该属性相关联函数,返回基于值联系在一起。一个简单的例子属性如下所示。
import std.stdio;
struct Rectangle
{
double width;
double height;
double area() const @property
{
return width*height;
}
void area(double newArea) @property
{
auto multiplier = newArea / area;
width *= multiplier;
writeln("Value set!");
}
}
void main()
{
auto rectangle = Rectangle(20,10);
writeln("The area is ", rectangle.area);
rectangle.area(300);
writeln("Modified width is ", rectangle.width);
}
当我们运行上面的程序,我们会得到下面的输出。
The area is 200
Value set!
Modified width is 30
D语言字符 - D语言教程
字符是字符串的基石。文字系统的任何符号称为字符:字母,数字,标点符号,空格字符等字母令人困惑的是,字符本身的基石也被称为字符。
小写a的整数值是97,数字1的整数值是49,这些数值已经仅仅指派当ASCII码表的设计惯例。
下表提供了有关与存储大小,其目的标准字符类型的详细信息。
字符由char类型,它只能容纳256个不同的值来表示。如果熟悉其他语言的字符类型,可能已经知道这不是大到足以支持许多书写系统的符号。
类型 | 存储大小 | 目的 |
char | 1 byte | UTF-8 code unit |
wchar | 2 bytes | UTF-16 code unit |
dchar | 4 bytes | UTF-32 code unit and Unicode code yiibai |
一些有用的字符函数列表如下
- isLower:是小写字符?
- isUpper:是否为大写字母?
- isAlpha: 是一个Unicode字母数字字符(通常,一个字母或数字)?
- isWhite:是一个空白字符?
- toLower: 给定字符转为小写
- toUpper: 给定字符转为大写
import std.stdio;
import std.uni;
void main()
{
writeln("Is ğ lowercase? ", isLower('ğ'));
writeln("Is Ş lowercase? ", isLower('Ş'));
writeln("Is İ uppercase? ", isUpper('İ'));
writeln("Is ç uppercase? ", isUpper('ç'));
writeln("Is z alphanumeric? ", isAlpha('z'));
writeln("Is new-line whitespace? ", isWhite('
'));
writeln("Is underline whitespace? ", isWhite('_'));
writeln("The lowercase of Ğ: ", toLower('Ğ'));
writeln("The lowercase of İ: ", toLower('İ'));
writeln("The uppercase of ş: ", toUpper('ş'));
writeln("The uppercase of ı: ", toUpper('ı'));
}
当我们运行上面的程序,我们会得到下面的输出
Is ğ lowercase? true
Is Ş lowercase? false
Is İ uppercase? true
Is ç uppercase? false
Is z alphanumeric? true
Is new-line whitespace? true
Is underline whitespace? false
The lowercase of Ğ: ğ
The lowercase of İ: i
The uppercase of ş: Ş
The uppercase of ı: I
读取字符
我们可以用readf如下所示读取字符。
readf(" %s", &letter);
由于D编程支持unicode,为了读取unicode字符,我们需要读两遍,写两次,得到预期的结果。例子如下所示。
import std.stdio;
void main()
{
char firstCode;
char secondCode;
write("Please enter a letter: ");
readf(" %s", &firstCode);
readf(" %s", &secondCode);
writeln("The letter that has been read: ",
firstCode, secondCode);
}
当我们运行上面的程序,我们会得到下面的输出
Please enter a letter: ğ
The letter that has been read: ğ
D语言字符串-String - D语言教程
D语言提供了以下两种类型的字符串表示:
- 字符数组。
- 核心语言字符串。
字符数组
我们可以表示两种形式,如下所示的一个字符数组。第一种形式直接提供的大小和第二种形式使用它创建字符串的可写副本“Good morning”的dup方法。
char[9] greeting1= "Hello all";
char[] greeting2 = "Good morning".dup;
下面是使用上述简单的字符数组的形式一个简单的例子。
import std.stdio;
void main(string[] args)
{
char[9] greeting1= "Hello all";
writefln("%s",greeting1);
char[] greeting2 = "Good morning".dup;
writefln("%s",greeting2);
}
当上面的代码被编译并执行,它会产生一些结果如下:
Hello all
Good morning
核心语言字符串
字符串是内置在D核心语言,这些字符串是互操作与上面显示的字符数组。下面的例子显示了一个简单的字符串表示形式。
string greeting1= "Hello all";
下面是一个简单的例子。
import std.stdio;
void main(string[] args)
{
string greeting1= "Hello all";
writefln("%s",greeting1);
char[] greeting2 = "Good morning".dup;
writefln("%s",greeting2);
string greeting3= greeting1;
writefln("%s",greeting3);
}
当上面的代码被编译并执行,它会产生一些结果如下:
Hello all
Good morning
Hello all
字符串连接
D编程语言的字符串连接使用符号(〜)符号。一个简单的字符串连接示例如下所示。
import std.stdio;
void main(string[] args)
{
string greeting1= "Good";
char[] greeting2 = "morning".dup;
char[] greeting3= greeting1~" "~greeting2;
writefln("%s",greeting3);
string greeting4= "morning";
string greeting5= greeting1~" "~greeting4;
writefln("%s",greeting5);
}
当上面的代码被编译并执行,它会产生一些结果如下:
Good morning
Good morning
字符串的长度
字符串的字节长度可以length功能的帮助下检索。一个简单的例子如下所示。
import std.stdio;
void main(string[] args)
{
string greeting1= "Good";
writefln("Length of string greeting1 is %d",greeting1.length);
char[] greeting2 = "morning".dup;
writefln("Length of string greeting2 is %d",greeting2.length);
}
当上面的代码被编译并执行,它会产生一些结果如下:
Length of string greeting1 is 4
Length of string greeting2 is 7
字符串比较
字符串比较在D语言编程中相当容易。可以使用==,<和>运算符进行字符串比较。一个简单的例子如下所示。
import std.stdio;
void main()
{
string s1 = "Hello";
string s2 = "World";
string s3 = "World";
if (s2 == s3)
{
writeln("s2: ",s2," and S3: ",s3, " are the same!");
}
if (s1 < s2)
{
writeln("'", s1, "' comes before '", s2, "'.");
}
else
{
writeln("'", s2, "' comes before '", s1, "'.");
}
}
当上面的代码被编译并执行,它会产生一些结果如下:
s2: World and S3: World are the same!
'Hello' comes before 'World'.
替换字符串
我们可以使用string[]替换字符串。一个简单的例子如下所示。
import std.stdio;
import std.string;
void main()
{
char[] s1 = "hello world ".dup;
char[] s2 = "sample".dup;
s1[6..12] = s2[0..6];
writeln(s1);
}
当上面的代码被编译并执行,它会产生一些结果如下:
hello sample
索引方法
索引方法在字符串的indexOf包括和lastIndexOf子串的位置,在下面的例子来说明。
import std.stdio;
import std.string;
void main()
{
char[] s1 = "hello World ".dup;
writeln("indexOf of llo in hello is ",std.string.indexOf(s1,"llo"));
writeln(s1);
writeln("lastIndexOf of O in hello is"
,std.string.lastIndexOf(s1,"O",CaseSensitive.no));
}
当上面的代码被编译并执行,它会产生一些结果如下:
indexOf of llo in hello is 2
hello World
lastIndexOf of O in hello is 7
处理大小写
用于改变大小的方法示于下面的例子。
import std.stdio;
import std.string;
void main()
{
char[] s1 = "hello World ".dup;
writeln("Capitalized string of s1 is ",capitalize(s1));
writeln("Uppercase string of s1 is ",toUpper(s1));
writeln("Lowercase string of s1 is ",toLower(s1));
}
当上面的代码被编译并执行,它会产生一些结果如下:
Capitalized string of s1 is Hello world
Uppercase string of s1 is HELLO WORLD
Lowercase string of s1 is hello world
限制字符
在字符串限制字符显示在下面的例子。
import std.stdio;
import std.string;
void main()
{
string s = "H123Hello1";
string result = munch(s, "0123456789H");
writeln("Restrict trailing characters:",result);
result = squeeze(s, "0123456789H");
writeln("Restrict leading characters:",result);
s = " Hello World ";
writeln("Stripping leading and trailing whitespace:",strip(s));
}
当上面的代码被编译并执行,它会产生一些结果如下:
Restrict trailing characters:H123H
Restrict leading characters:ello1
Stripping leading and trailing whitespace:Hello World
D语言数组 - D语言教程
D编程语言提供了一种数据结构,数组用于存储相同类型的元素的一个固定大小的连续集合。数组是用于存储数据的集合,但它往往认为阵列为相同类型的变量的集合。
相反声明个别变数,如number0, number1, ..., 和number99,声明一个数组变量,如使用数字numbers[0], numbers[1], 和..., numbers[99]来表示各个变量。在数组中的特定元素是通过索引来访问。
所有阵列组成的连续的存储单元。最低的地址对应于所述第一元素,而最高地址的最后一个元素。
声明数组:
在D编程语言声明数组,程序员指定的元素和如下由阵列所需元素的数量的类型:
type arrayName [ arraySize ];
这就是所谓的单维数组。arraySize必须是整数常量大于零且类型可以是任何有效的D编程语言数据类型。例如,要声明一个10个元素的数组为double类型,使用此语句:
double balance[10];
初始化数组:
可以初始化D编程语言的数组元素或者一个接一个,或使用一个单独的语句如下:
double balance[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
方括号内[]的值的个数在右边不能比,我们的声明方括号[]之间的数组元素的个数较大。下面是一个示例来指定数组的单个元素:
如果省略数组的大小,创建数组的大小刚好能容纳初始化。因此,如果编写:
double balance[] = [1000.0, 2.0, 3.4, 17.0, 50.0];
将创建完全相同的数组,和在前面的例子中那样。
balance[4] = 50.0;
上述声明数组的值50.0在指定元素数第5位。与第四索引数组将是第五次,即最后一个元素,因为所有的数组都是让 0作为他们的第一个元素,也被称为基本索引的索引。以下是我们上面讨论的相同阵列的图案表现出来:

访问数组元素:
元素是由索引数组名访问。这是通过将一个元素的索引数组的名称之后方括号内进行。例如:
double salary = balance[9];
上面的语句将第10元素从数组并赋值给变量salary。下面是一个例子,这将使用所有上述三个概念即:声明,赋值和访问数组:
import std.stdio;
void main()
{
int n[ 10 ]; // n is an array of 10 integers
// initialize elements of array n to 0
for ( int i = 0; i < 10; i++ )
{
n[ i ] = i + 100; // set element at location i to i + 100
}
writeln("Element Value");
// output each array element's value
for ( int j = 0; j < 10; j++ )
{
writeln(j," ",n[j]);
}
}
让我们编译和运行上面的程序,这将产生以下结果:
Element Value
0 100
1 101
2 102
3 103
4 104
5 105
6 106
7 107
8 108
9 109
静态数组与动态数组
当在程序被写入所指定的数组的长度,该阵列是一个静态数组。当长度可以在程序的执行过程中发生变化,该阵列是一个动态数组。
定义动态数组不是定义固定长度的阵列,因为省略长度使得一个动态数组简单:
int[] dynamicArray;
数组属性
属性 | 描述 |
.init | 静态数组返回一个数组字面量的字面即数组元素类型。初始化属性中的每个元素。 |
.sizeof | 静态数组返回数组的长度乘以每个数组元素的字节数,而动态数组返回动态数组的引用,在32位版本大小为8,在64位版本的大小为16。 |
.length | 静态数组返回,而动态数组是用来获取/设置数组中的元素个数数组中元素的个数。长度的类型为size_t。 |
.ptr | 返回一个指向数组的第一个元素。 |
.dup | 创建同样大小的动态数组及数组中的内容复制到其中。 |
.idup | 创建同样大小的动态数组及数组中的内容复制到其中。该副本的类型为是不可变的。 |
.reverse | 在当前位置倒转数组中的元素的顺序。返回数组。 |
.sort | 在这里各种阵列中的元素的顺序。返回数组。 |
下面的例子说明可用于数组的各种属性。
import std.stdio;
void main()
{
int n[ 5 ]; // n is an array of 5 integers
// initialize elements of array n to 0
for ( int i = 0; i < 5; i++ )
{
n[ i ] = i + 100; // set element at location i to i + 100
}
writeln("Initialized value:",n.init);
writeln("Length: ",n.length);
writeln("Size of: ",n.sizeof);
writeln("Yiibaier:",n.ptr);
writeln("Duplicate Array: ",n.dup);
writeln("iDuplicate Array: ",n.idup);
n = n.reverse.dup;
writeln("Reversed Array: ",n);
writeln("Sorted Array: ",n.sort);
}
让我们编译和运行上面的程序,这将产生以下结果:
Initialized value:[0, 0, 0, 0, 0]
Length: 5
Size of: 20
Yiibaier:7FFF5A373920
Duplicate Array: [100, 101, 102, 103, 104]
iDuplicate Array: [100, 101, 102, 103, 104]
Reversed Array: [104, 103, 102, 101, 100]
Sorted Array: [100, 101, 102, 103, 104]
多维数组
D编程允许多维数组。这里是一个多维数组声明的一般形式为:
type name[size1][size2]...[sizeN];
例如,下面的声明创建一个三维: 5 . 10 . 4整数数组:
int threedim[5][10][4];
二维数组:
多维数组的最简单的形式是二维阵列。二维阵列在本质上是一维阵列的列表。声明大小为x,y的二维整型数组,编写如下:
type arrayName [ x ][ y ];
其中type可以是任何有效的D编程的数据类型和arrayName中会是一个有效的D编程标识符。
一个二维数组可以想作是一个表,有行和列:x行y列的数量,它包含三行四列可以如下所示:
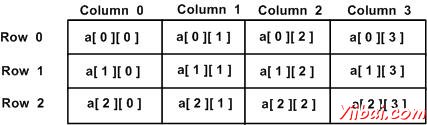
因此,在数组每个元素是确定的形式的元素名为[i][j]时,其中a是数组的名称,并且i和j是用来唯一地标识每一个元素的下标。
初始化二维数组:
多维阵列可以通过指定每一行括号内的值进行初始化。以下是3行,每行一个数组有4列。
int a[3][4] = [
[0, 1, 2, 3] , /* initializers for row indexed by 0 */
[4, 5, 6, 7] , /* initializers for row indexed by 1 */
[8, 9, 10, 11] /* initializers for row indexed by 2 */
];
嵌套的括号,这表明预定的行,是可选的。下面的初始化等同于前面的例子:
int a[3][4] = [0,1,2,3,4,5,6,7,8,9,10,11];
访问二维数组元素:
在2维数组的元素是通过使用下标,即行索引和所述阵列的列索引的访问。例如:
int val = a[2][3];
上面的语句将第4个元素的数组的第三排。可以在上面双字母组合验证。
import std.stdio;
void main ()
{
// an array with 5 rows and 2 columns.
int a[5][2] = [ [0,0], [1,2], [2,4], [3,6],[4,8]];
// output each array element's value
for ( int i = 0; i < 5; i++ )
for ( int j = 0; j < 2; j++ )
{
writeln( "a[" , i , "][" , j , "]: ",a[i][j]);
}
}
让我们编译和运行上面的程序,这将产生以下结果:
a[0][0]: 0
a[0][1]: 0
a[1][0]: 1
a[1][1]: 2
a[2][0]: 2
a[2][1]: 4
a[3][0]: 3
a[3][1]: 6
a[4][0]: 4
a[4][1]: 8
常见的数组操作
数组分片
我们经常用一个数组的一部分,切片阵列往往是相当有用的。一个简单的例子数组切片如下所示。
import std.stdio;
void main ()
{
// an array with 5 elements.
double a[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
double[] b;
b = a[1..3];
writeln(b);
}
让我们编译和运行上面的程序,这将产生以下结果:
[2, 3.4]
数组复制
我们还使用复制数组。一个简单的例子,适用于阵列的复制如下所示。
import std.stdio;
void main ()
{
// an array with 5 elements.
double a[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
double b[5];
writeln("Array a:",a);
writeln("Array b:",b);
b[] = a; // the 5 elements of a[5] are copied into b[5]
writeln("Array b:",b);
b[] = a[]; // the 5 elements of a[3] are copied into b[5]
writeln("Array b:",b);
b[1..2] = a[0..1]; // same as b[1] = a[0]
writeln("Array b:",b);
b[0..2] = a[1..3]; // same as b[0] = a[1], b[1] = a[2]
writeln("Array b:",b);
}
让我们编译和运行上面的程序,这将产生以下结果:
Array a:[1000, 2, 3.4, 17, 50]
Array b:[nan, nan, nan, nan, nan]
Array b:[1000, 2, 3.4, 17, 50]
Array b:[1000, 2, 3.4, 17, 50]
Array b:[1000, 1000, 3.4, 17, 50]
Array b:[2, 3.4, 3.4, 17, 50]
数组设定
一个简单的例子数组中的设定值如下所示。
import std.stdio;
void main ()
{
// an array with 5 elements.
double a[5];
a[] = 5;
writeln("Array a:",a);
}
当上面的代码被编译并执行,它会产生以下结果:
Array a:[5, 5, 5, 5, 5]
数组连接
一个简单的例子对两个数组的并置如下所示。
import std.stdio;
void main ()
{
// an array with 5 elements.
double a[5] = 5;
double b[5] = 10;
double [] c;
c = a~b;
writeln("Array c: ",c);
}
让我们编译和运行上面的程序,这将产生以下结果:
Array c: [5, 5, 5, 5, 5, 10, 10, 10, 10, 10]
D语言关联数组 - D语言教程
关联数组有一个索引,并不一定是一个整数。该指数的关联数组被称为键,它的类型就是所谓的关键字类型。
关联数组是通过将关键字类型的[]数组声明中声明。一个简单的例子为关联数组,如下所示。
import std.stdio;
void main ()
{
int[string] e; // associative array b of ints that are
e["test"] = 3;
writeln(e["test"]);
string[string] f;
f["test"] = "Tuts";
writeln(f["test"]);
writeln(f);
f.remove("test");
writeln(f);
}
当上面的代码被编译并执行,它会产生以下结果:
3
Tuts
["test":"Tuts"]
[]
初始化
关联数组的一个简单的初始化如下所示。
import std.stdio;
void main ()
{
int[string] days =
[ "Monday" : 0, "Tuesday" : 1, "Wednesday" : 2,
"Thursday" : 3, "Friday" : 4, "Saturday" : 5,
"Sunday" : 6 ];
writeln(days["Tuesday"]);
}
当上面的代码被编译并执行,它会产生以下结果:
1
属性
属性 | 描述 |
.sizeof | 返回引用关联数组的大小;32位版本的4位,在64位版本为8位。 |
.length | 返回关联数组中的值的数目。不同于动态数组,它是只读的。 |
.dup | 创建相同大小的新关联数组和关联数组中的内容复制到其中。 |
.keys | 返回动态数组,它的元素是关联数组中的键。 |
.values | 返回动态数组,它的元素是关联数组中的值。 |
.rehash | 重组的关联数组到位,使查找更高效。翻版时生效,例如,程序加载完成了一个符号表,现在需要快速查找它。返回一个引用到重组后的数组。 |
.byKey() | 返回委托适合用作一个聚合到ForeachStatement这将遍历关联数组的键。 |
.byValue() | 返回委托适合用作一个聚合到ForeachStatement这将遍历关联数组的值。 |
.get(Key key, lazy Value defVal) | 查找键;如果存在相应的值则返回,否则求值,并返回defVal。 |
.remove(Key key) | 删除一个对象的键。 |
利用上述特性,例如,如下所示。
import std.stdio;
void main ()
{
int[string] array1;
array1["test"] = 3;
array1["test2"] = 20;
writeln("sizeof: ",array1.sizeof);
writeln("length: ",array1.length);
writeln("dup: ",array1.dup);
array1.rehash;
writeln("rehashed: ",array1);
writeln("keys: ",array1.keys);
writeln("values: ",array1.values);
foreach (key; array1.byKey) {
writeln("by key: ",key);
}
foreach (value; array1.byValue) {
writeln("by value ",value);
}
writeln("get value for key test: ",array1.get("test",10));
writeln("get value for key test3: ",array1.get("test3",10));
array1.remove("test");
writeln(array1);
}
当上面的代码被编译并执行,它会产生以下结果:
sizeof: 8
length: 2
dup: ["test2":20, "test":3]
rehashed: ["test":3, "test2":20]
keys: ["test", "test2"]
values: [3, 20]
by key: test
by key: test2
by value 3
by value 20
get value for key test: 3
get value for key test3: 10
["test2":20]
D语言指针 - D语言教程
D编程指针是很容易和有趣学习。一些D编程任务的指针进行更容易和其他D编程任务,如动态存储器分配,不能没有它们来执行。一个简单的指针如下所示。
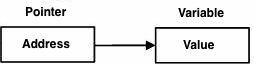
而不是直接指向变量一样,指针所指向的值赋给变量的地址。正如你所知道的每个变量是一个内存位置和每个存储单元都有其定义的地址,可以使用符号来访问(&)运算,是指在存储器中的地址。认为这将打印中定义的变量的地址如下:
import std.stdio;
void main ()
{
int var1;
writeln("Address of var1 variable: ",&var1);
char var2[10];
writeln("Address of var2 variable: ",&var2);
}
当上面的代码被编译并执行,它会产生什么结果如下:
Address of var1 variable: 7FFF52691928
Address of var2 variable: 7FFF52691930
什么是指针?
指针是一个变量,它的值是另一个变量的地址。如同任何变量或常量,必须声明一个指针,然后才能使用它。一个指针变量声明的一般形式是:
type *var-name;
其中,type是指针的基本类型;它必须是一个有效的编程类型和var-name是指针变量的名称。用来声明一个指针的星号是用于乘法相同的星号。然而,在这个语句中的星号是被用来指定一个变量的指针。以下是有效的指针声明:
int *ip; // yiibaier to an integer
double *dp; // yiibaier to a double
float *fp; // yiibaier to a float
char *ch // yiibaier to character
所有指针的值的实际数据类型,整数,浮点数,字符,或以其他方式是否是相同的,代表一个内存地址的十六进制数。不同数据类型的指针之间的唯一区别是变量或常数,该指针指向的数据类型。
D编程语言使用指针:
有几个重要的业务,我们将与指针做的非常频繁。 (a)我们定义一个指针变量(b)分配一个变量的地址的指针(c)在指针变量中可用的地址最终进入的值。这是通过使用一元运算符*,返回位于其操作数指定的地址变量的值来完成。下面的示例使用这些操作:
import std.stdio;
void main ()
{
int var = 20; // actual variable declaration.
int *ip; // yiibaier variable
ip = &var; // store address of var in yiibaier variable
writeln("Value of var variable: ",var);
writeln("Address stored in ip variable: ",ip);
writeln("Value of *ip variable: ",*ip);
}
当上面的代码被编译并执行,它会产生什么结果如下:
Value of var variable: 20
Address stored in ip variable: 7FFF5FB7E930
Value of *ip variable: 20
Null 指针
它始终是一个好习惯,对NULL指针分配给案件的指针变量你没有确切的地址进行分配。这样做是在变量声明的时候。分配空指针被称为空指针(null)。
空指针是一个常数为零的几个标准库,包括iostream中定义的值。考虑下面的程序:
import std.stdio;
void main ()
{
int *ptr = null;
writeln("The value of ptr is " , ptr) ;
}
让我们编译和运行上面的程序,这将产生以下结果:
The value of ptr is null
在大多数的操作系统,程序不允许在地址0访问内存,因为内存是由操作系统保留。然而,存储器地址0具有特殊的意义;它表明,该指针不旨在指向一个可访问的存储器位置。但按照惯例,如果一个指针包含空(零)值,它被假定为不指向什么东西。
要检查空指针,可以使用一个if语句如下:
if(ptr) // succeeds if p is not null
if(!ptr) // succeeds if p is null
因此,如果所有未使用的指针被赋予空值,并且避免使用空指针,能避免未初始化的指针的意外误操作。很多时候,未初始化的变量举行一些垃圾值,就很难调试程序。
指针运算
可以对指针的使用加减乘除四则运算符: ++, --, +, -
为了理解指针的算术运算,让我们认为,ptr是一个整数的指针,假设它32位指向的地址1000整数,让我们上的指针执行以下算术运算:
ptr++
ptr将指向位置1004,因为每次ptr递增,它会指向下一个整数。此操作将指针移动到下一个内存位置,而不在内存中的位置影响实际值。如果ptr指向一个字符的地址是1000,那么上面的操作将指向位置1001,因为下一个字符将在1001。
递增一个指针:
我们优选使用在我们的程序,而不是一个数组的指针,因为变量指针可以递增,这是不能被增加,因为它是一个常量指针数组名不同。下面的程序将变量指针来访问数组中的每个元素成功:
import std.stdio;
const int MAX = 3;
void main ()
{
int var[MAX] = [10, 100, 200];
int *ptr = &var[0];
for (int i = 0; i < MAX; i++, ptr++)
{
writeln("Address of var[" , i , "] = ",ptr);
writeln("Value of var[" , i , "] = ",*ptr);
}
}
当上面的代码被编译并执行,它会产生一些结果如下:
Address of var[0] = 18FDBC
Value of var[0] = 10
Address of var[1] = 18FDC0
Value of var[1] = 100
Address of var[2] = 18FDC4
Value of var[2] = 200
指针与数组
指针和数组有很大的关系。然而,指针和数组不完全互换。例如,考虑下面的程序:
import std.stdio;
const int MAX = 3;
void main ()
{
int var[MAX] = [10, 100, 200];
int *ptr = &var[0];
var.ptr[2] = 290;
ptr[0] = 220;
for (int i = 0; i < MAX; i++, ptr++)
{
writeln("Address of var[" , i , "] = ",ptr);
writeln("Value of var[" , i , "] = ",*ptr);
}
}
在上面的程序中,可以看到var.ptr[2]来设置第二个元素和ptr[0]这是用来设置第零个元素。递增运算符可以使用ptr但不使用var。
当上面的代码被编译并执行,它会产生一些结果如下:
Address of var[0] = 18FDBC
Value of var[0] = 220
Address of var[1] = 18FDC0
Value of var[1] = 100
Address of var[2] = 18FDC4
Value of var[2] = 290
指针的指针
一个指针,指针是多个间接或链指针的一种形式。通常情况下,一个指针包含一个变量的地址。当我们定义一个指向指针的指针,第一指针包含第二指针,它指向包含实际值如下所示的位置的地址。

一个变量,它是一个指向指针的指针必须被声明为此类。这是通过把一个附加星号在其名称前完成。例如,以下是声明来声明一个指向int类型的指针:
int **var;
当目标值被间接地通过一个指向指针指向的,访问该值要求的星号运算符被应用两次,如下面的例子所示:
import std.stdio;
const int MAX = 3;
void main ()
{
int var = 3000;
writeln("Value of var :" , var);
int *ptr = &var;
writeln("Value available at *ptr :" ,*ptr);
int **pptr = &ptr;
writeln("Value available at **pptr :",**pptr);
}
让我们编译和运行上面的程序,这将产生以下结果:
Value of var :3000
Value available at *ptr :3000
Value available at **pptr :3000
指针传递给函数
D编程允许将一个指针传递给一个函数。要做到这一点,只需声明该函数的参数为指针类型。
下面一个简单的例子,我们传递一个指向函数的指针。
import std.stdio;
void main ()
{
// an int array with 5 elements.
int balance[5] = [1000, 2, 3, 17, 50];
double avg;
avg = getAverage( &balance[0], 5 ) ;
writeln("Average is :" , avg);
}
double getAverage(int *arr, int size)
{
int i;
double avg, sum = 0;
for (i = 0; i < size; ++i)
{
sum += arr[i];
}
avg = sum/size;
return avg;
}
当上面的代码一起编译和执行时,它会产生下列结果:
Average is :214.4
返回指针的函数
考虑下面的函数,它将使用第一个数组元素的指针,即,地址返回数字10。
import std.stdio;
void main ()
{
int *p = getNumber();
for ( int i = 0; i < 10; i++ )
{
writeln("*(p + " , i , ") : ",*(p + i));
}
}
int * getNumber( )
{
static int r [10];
for (int i = 0; i < 10; ++i)
{
r[i] = i;
}
return &r[0];
}
当上面的代码一起编译并执行,它会产生一些结果如下:
*(p + 0) : 0
*(p + 1) : 1
*(p + 2) : 2
*(p + 3) : 3
*(p + 4) : 4
*(p + 5) : 5
*(p + 6) : 6
*(p + 7) : 7
*(p + 8) : 8
*(p + 9) : 9
指向数组的指针
数组名是一个常量指针数组的第一个元素。因此,声明:
double balance[50];
balance是一个指针,指向与balance[0],这是阵列平衡的第一个元素的地址。因此,下面的程序片段分配p为balance的第一个元素的地址:
double *p;
double balance[10];
p = balance;
它是合法的,使用数组名作为常量指针,反之亦然。因此,*(balance + 4) 处于访问balance[4]数据的一种合法方法。
一旦存储p中第一个元素的地址,可以使用 p(p +1),*(p+2)等访问数组元素。下面是该例子,以显示所有上面讨论的概念:
import std.stdio;
void main ()
{
// an array with 5 elements.
double balance[5] = [1000.0, 2.0, 3.4, 17.0, 50.0];
double *p;
p = &balance[0];
// output each array element's value
writeln("Array values using yiibaier " );
for ( int i = 0; i < 5; i++ )
{
writeln( "*(p + ", i, ") : ", *(p + i));
}
}
让我们编译和运行上面的程序,这将产生以下结果:
Array values using yiibaier
*(p + 0) : 1000
*(p + 1) : 2
*(p + 2) : 3.4
*(p + 3) : 17
*(p + 4) : 50
D语言元组 - D语言教程
元组用于组合多个值作为单个对象。元组包含的元素的序列。元素可以是类型,表达式或别名。元组的数目和元件固定在编译时,它们不能在运行时改变。
元组有两个结构和数组的特性。元组元素可以是不同的类型,如结构的。该元素可以通过索引数组一样访问。它们是由从std.typecons模块的元组模板实现为一个库功能。元组利用TypeTuple从一些业务的std.typetuple模块。
使用元组tuple()
元组可以由函数tuple()来构造。一个元组的成员由索引值访问。一个例子如下所示。
import std.stdio;
import std.typecons;
void main()
{
auto myTuple = tuple(1, "Tuts");
writeln(myTuple);
writeln(myTuple[0]);
writeln(myTuple[1]);
}
当上面的代码被编译并执行,它会产生以下结果:
Tuple!(int, string)(1, "Tuts")
1
Tuts
使用元组元组模板
元组也可以由元组模板而不是tuple()函数直接构造。每个成员的类型和名称被指定为两个连续的模板参数。它可以通过属性使用模板创建的时候访问的成员。
import std.stdio;
import std.typecons;
void main()
{
auto myTuple = Tuple!(int, "id",string, "value")(1, "Tuts");
writeln(myTuple);
writeln("by index 0 : ", myTuple[0]);
writeln("by .id : ", myTuple.id);
writeln("by index 1 : ", myTuple[1]);
writeln("by .value ", myTuple.value);
}
当上面的代码被编译并执行,它会产生以下结果:
Tuple!(int, "id", string, "value")(1, "Tuts")
by index 0 : 1
by .id : 1
by index 1 : Tuts
by .value Tuts
扩展属性和函数参数
元组的成员可以通过.expand扩展属性或通过切片进行扩展。这种扩展/切片值可以作为函数的参数列表。一个例子如下所示。
import std.stdio;
import std.typecons;
void method1(int a, string b, float c, char d)
{
writeln("method 1 ",a," ",b," ",c," ",d);
}
void method2(int a, float b, char c)
{
writeln("method 2 ",a," ",b," ",c);
}
void main()
{
auto myTuple = tuple(5, "my string", 3.3, 'r');
writeln("method1 call 1");
method1(myTuple[]);
writeln("method1 call 2");
method1(myTuple.expand);
writeln("method2 call 1");
method2(myTuple[0], myTuple[$-2..$]);
}
当上面的代码被编译并执行,它会产生以下结果:
method1 call 1
method 1 5 my string 3.3 r
method1 call 2
method 1 5 my string 3.3 r
method2 call 1
method 2 5 3.3 r
TypeTuple
TypeTuple在std.typetuple模块中定义。值和类型的逗号分隔的列表。使用TypeTuple一个简单的例子如下。 TypeTuple用于创建参数列表,模板列表和数组文本列表。
import std.stdio;
import std.typecons;
import std.typetuple;
alias TypeTuple!(int, long) TL;
void method1(int a, string b, float c, char d)
{
writeln("method 1 ",a," ",b," ",c," ",d);
}
void method2(TL tl)
{
writeln(tl[0]," ", tl[1] );
}
void main()
{
auto arguments = TypeTuple!(5, "my string", 3.3,'r');
method1(arguments);
method2(5, 6L);
}
当上面的代码被编译并执行,它会产生以下结果:
method 1 5 my string 3.3 r
5 6
D语言结构体 - D语言教程
D语言数组允许定义类型的变量,可容纳同类但是结构体几个数据项,它允许结合不同类型的数据项提供另一种用户定义的数据类型。
结构用来表示一个记录,假设要跟踪图书馆中的书籍。可能希望跟踪了解每本书的以下属性:
- 书名
- 作者
- 科目
- 书籍编号ID
定义一个结构体
要定义一个结构,必须使用结构体struct语句。该结构语句定义了一个新的数据类型,项目不止一个成员。该结构语句的格式是这样的:
struct [structure tag]
{
member definition;
member definition;
...
member definition;
} [one or more structure variables];
结构体标签是可选的,每个成员的定义是正常的变量定义,比如int i; or float f; 或任何其他有效的变量定义。在该结构的定义的结尾,最后的分号之前,可以指定一个或多个结构变量,但它是可选的。这里是将声明书的结构体:
struct Books
{
char [] title;
char [] author;
char [] subject;
int book_id;
};
访问结构成员
要访问一个结构的任何成员,我们使用成员访问运算符(.)成员访问运算编码为结构体变量名,而我们希望访问结构成员之间的时间段。可以使用struct关键字来定义结构类型的变量。下面是例子来说明结构的用法:
import std.stdio;
struct Books
{
char [] title;
char [] author;
char [] subject;
int book_id;
};
void main( )
{
Books Book1; /* Declare Book1 of type Book */
Books Book2; /* Declare Book2 of type Book */
/* book 1 specification */
Book1.title = "D Programming".dup;
Book1.author = "Raj".dup;
Book1.subject = "D Programming Tutorial".dup;
Book1.book_id = 6495407;
/* book 2 specification */
Book2.title = "Lua Programming".dup;
Book2.author = "Raj".dup;
Book2.subject = "Lua Programming Tutorial".dup;
Book2.book_id = 6495700;
/* print Book1 info */
writeln( "Book 1 title : ", Book1.title);
writeln( "Book 1 author : ", Book1.author);
writeln( "Book 1 subject : ", Book1.subject);
writeln( "Book 1 book_id : ", Book1.book_id);
/* print Book2 info */
writeln( "Book 2 title : ", Book2.title);
writeln( "Book 2 author : ", Book2.author);
writeln( "Book 2 subject : ", Book2.subject);
writeln( "Book 2 book_id : ", Book2.book_id);
}
当上面的代码被编译并执行,它会产生以下结果:
Book 1 title : D Programming
Book 1 author : Raj
Book 1 subject : D Programming Tutorial
Book 1 book_id : 6495407
Book 2 title : Lua Programming
Book 2 author : Raj
Book 2 subject : Lua Programming Tutorial
Book 2 book_id : 6495700
结构作为函数的参数
可以传递一个结构非常类似的方式函数作为参数传递任何其他变量或指针。访问在上面的例子已经使用类似的方式的结构变量:
import std.stdio;
struct Books
{
char [] title;
char [] author;
char [] subject;
int book_id;
};
void main( )
{
Books Book1; /* Declare Book1 of type Book */
Books Book2; /* Declare Book2 of type Book */
/* book 1 specification */
Book1.title = "D Programming".dup;
Book1.author = "Raj".dup;
Book1.subject = "D Programming Tutorial".dup;
Book1.book_id = 6495407;
/* book 2 specification */
Book2.title = "Lua Programming".dup;
Book2.author = "Raj".dup;
Book2.subject = "Lua Programming Tutorial".dup;
Book2.book_id = 6495700;
/* print Book1 info */
printBook( Book1 );
/* Print Book2 info */
printBook( Book2 );
}
void printBook( Books book )
{
writeln( "Book title : ", book.title);
writeln( "Book author : ", book.author);
writeln( "Book subject : ", book.subject);
writeln( "Book book_id : ", book.book_id);
}
当上面的代码被编译并执行,它会产生以下结果:
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495407
Book title : Lua Programming
Book author : Raj
Book subject : Lua Programming Tutorial
Book book_id : 6495700
结构体初始化
结构可以有两种形式,可使用构造函数和其他使用{}格式进行初始化。一个例子如下所示。
import std.stdio;
struct Books
{
char [] title;
char [] subject = "Empty".dup;
int book_id = -1;
char [] author = "Raj".dup;
};
void main( )
{
Books Book1 = Books("D Programming".dup, "D Programming Tutorial".dup, 6495407 );
printBook( Book1 );
Books Book2 = Books("Lua Programming".dup, "Lua Programming Tutorial".dup, 6495407,"Raj".dup );
printBook( Book2 );
Books Book3 = {title:"Obj C programming".dup, book_id : 1001};
printBook( Book3 );
}
void printBook( Books book )
{
writeln( "Book title : ", book.title);
writeln( "Book author : ", book.author);
writeln( "Book subject : ", book.subject);
writeln( "Book book_id : ", book.book_id);
}
当上面的代码被编译并执行,它会产生以下结果:
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 6495407
Book title : Lua Programming
Book author : Raj
Book subject : Lua Programming Tutorial
Book book_id : 6495407
Book title : Obj C programming
Book author : Raj
Book subject : Empty
Book book_id : 1001
静态成员
静态变量初始化一次。例如有这本书唯一的ID,我们可以使book_id静态和递增书籍ID。一个例子如下所示。
import std.stdio;
struct Books
{
char [] title;
char [] subject = "Empty".dup;
int book_id;
char [] author = "Raj".dup;
static int id = 1000;
};
void main( )
{
Books Book1 = Books("D Programming".dup, "D Programming Tutorial".dup,++Books.id );
printBook( Book1 );
Books Book2 = Books("Lua Programming".dup, "Lua Programming Tutorial".dup,++Books.id);
printBook( Book2 );
Books Book3 = {title:"Obj C programming".dup, book_id:++Books.id};
printBook( Book3 );
}
void printBook( Books book )
{
writeln( "Book title : ", book.title);
writeln( "Book author : ", book.author);
writeln( "Book subject : ", book.subject);
writeln( "Book book_id : ", book.book_id);
}
当上面的代码被编译并执行,它会产生以下结果:
Book title : D Programming
Book author : Raj
Book subject : D Programming Tutorial
Book book_id : 1001
Book title : Lua Programming
Book author : Raj
Book subject : Lua Programming Tutorial
Book book_id : 1002
Book title : Obj C programming
Book author : Raj
Book subject : Empty
Book book_id : 1003
D语言范围 - D语言教程
范围是存取元素的抽象。这种抽象使得在容器类型的大量使用算法大量出现。范围强调如何容器元素的访问,而不是如何在容器中实现。范围是一个是基于是否一个类型定义某组的成员函数非常简单的概念。
D语言范围片恰巧是最强大RandomAccessRange实现不可或缺的一部分,而且有很多的功能使用范围。许多算法返回的临时对象范围。例如filter(),它选择了大于10下面的代码元素,实际上返回一个范围对象,而不是一个数组:
数字范围
数量范围是相当常用的这些数字范围是int类型。对于数量范围的一些例子如下所示
// Example 1
foreach (value; 3..7)
// Example 2
int[] slice = array[5..10];
福波斯范围
关于结构和类接口的范围是福波斯的范围。 Phobos是正式运行库和标准库自带的D语言编译器。
有多种类型的范围,其中包括,
- InputRange
- ForwardRange
- BidirectionalRange
- RandomAccessRange
- OutputRange
InputRange
最简单的范围的输入范围。在其他范围带来他们是基于一系列的顶部更高的需求。有三个函数InputRange需求,
- empty: 指定的范围内是否为空;当范围被认为是空的,它必须返回true,否则返回false
- front: 提供对元素的范围的开始
- popFront(): 通过去除所述第一元件从一开始就缩短了范围
import std.stdio;
import std.string;
struct Student
{
string name;
int number;
string toString() const
{
return format("%s(%s)", name, number);
}
}
struct School
{
Student[] students;
}
struct StudentRange
{
Student[] students;
this(School school)
{
this.students = school.students;
}
@property bool empty() const
{
return students.length == 0;
}
@property ref Student front()
{
return students[0];
}
void popFront()
{
students = students[1 .. $];
}
}
void main(){
auto school = School( [ Student("Raj", 1), Student("John", 2) , Student("Ram", 3) ] );
auto range = StudentRange(school);
writeln(range);
writeln(school.students.length);
writeln(range.front);
range.popFront;
writeln(range.empty);
writeln(range);
}
当上面的代码被编译并执行,它会产生以下结果:
[Raj(1), John(2), Ram(3)]
3
Raj(1)
false
[John(2), Ram(3)]
ForwardRange
ForwardRange还需要保存成员函数部分来自其他三个功能InputRange和返回时保存函数被调用的范围内的一个副本。
import std.array;
import std.stdio;
import std.string;
import std.range;
struct FibonacciSeries
{
int first = 0;
int second = 1;
enum empty = false; // infinite range
@property int front() const
{
return first;
}
void popFront()
{
int third = first + second;
first = second;
second = third;
}
@property FibonacciSeries save() const
{
return this;
}
}
void report(T)(const dchar[] title, const ref T range)
{
writefln("%s: %s", title, range.take(5));
}
void main()
{
auto range = FibonacciSeries();
report("Original range", range);
range.popFrontN(2);
report("After removing two elements", range);
auto theCopy = range.save;
report("The copy", theCopy);
range.popFrontN(3);
report("After removing three more elements", range);
report("The copy", theCopy);
}
当上面的代码被编译并执行,它会产生以下结果:
Original range: [0, 1, 1, 2, 3]
After removing two elements: [1, 2, 3, 5, 8]
The copy: [1, 2, 3, 5, 8]
After removing three more elements: [5, 8, 13, 21, 34]
The copy: [1, 2, 3, 5, 8]
BidirectionalRange
BidirectionalRange进行附加在ForwardRange的成员函数提供了两个成员函数。回调函数,它类似于front,提供了访问该范围的最后一个元素。 popBack functiom类似于popFront功能状况和它消除了最后一个元素的范围。
import std.array;
import std.stdio;
import std.string;
struct Reversed
{
int[] range;
this(int[] range)
{
this.range = range;
}
@property bool empty() const
{
return range.empty;
}
@property int front() const
{
return range.back; // reverse
}
@property int back() const
{
return range.front; // reverse
}
void popFront()
{
range.popBack();
}
void popBack()
{
range.popFront();
}
}
void main()
{
writeln(Reversed([ 1, 2, 3]));
}
当上面的代码被编译并执行,它会产生以下结果:
[3, 2, 1]
无穷大RandomAccessRange
opIndex()相较于ForwardRange是进行附加是必需的。另外要在编译时empty函数的值为false。一个简单的例子进行说明用的正方形的范围如下所示。
import std.array;
import std.stdio;
import std.string;
import std.range;
import std.algorithm;
class SquaresRange
{
int first;
this(int first = 0)
{
this.first = first;
}
enum empty = false;
@property int front() const
{
return opIndex(0);
}
void popFront()
{
++first;
}
@property SquaresRange save() const
{
return new SquaresRange(first);
}
int opIndex(size_t index) const
{
/* This function operates at constant time */
immutable integerValue = first + cast(int)index;
return integerValue * integerValue;
}
}
bool are_lastTwoDigitsSame(int value)
{
/* Must have at least two digits */
if (value < 10) {
return false;
}
/* Last two digits must be divisible by 11 */
immutable lastTwoDigits = value % 100;
return (lastTwoDigits % 11) == 0;
}
void main()
{
auto squares = new SquaresRange();
writeln(squares[5]);
writeln(squares[10]);
squares.popFrontN(5);
writeln(squares[0]);
writeln(squares.take(50).filter!are_lastTwoDigitsSame);
}
让我们编译和运行上面的程序,这将产生以下结果:
25
100
25
[100, 144, 400, 900, 1444, 1600, 2500]
有限RandomAccessRange
opIndex()和length相比双向范围都需要进行附加。这是详细的例子,它使用的斐波那契数列和前面使用正方形范围。这个例子工作原理以及在正常的D编译器,但不会对在线编译工作。
import std.array;
import std.stdio;
import std.string;
import std.range;
import std.algorithm;
struct FibonacciSeries
{
int first = 0;
int second = 1;
enum empty = false; // infinite range
@property int front() const
{
return first;
}
void popFront()
{
int third = first + second;
first = second;
second = third;
}
@property FibonacciSeries save() const
{
return this;
}
}
void report(T)(const dchar[] title, const ref T range)
{
writefln("%40s: %s", title, range.take(5));
}
class SquaresRange
{
int first;
this(int first = 0)
{
this.first = first;
}
enum empty = false;
@property int front() const
{
return opIndex(0);
}
void popFront()
{
++first;
}
@property SquaresRange save() const
{
return new SquaresRange(first);
}
int opIndex(size_t index) const
{
/* This function operates at constant time */
immutable integerValue = first + cast(int)index;
return integerValue * integerValue;
}
}
bool are_lastTwoDigitsSame(int value)
{
/* Must have at least two digits */
if (value < 10) {
return false;
}
/* Last two digits must be divisible by 11 */
immutable lastTwoDigits = value % 100;
return (lastTwoDigits % 11) == 0;
}
struct Together
{
const(int)[][] slices;
this(const(int)[][] slices ...)
{
this.slices = slices.dup;
clearFront();
clearBack();
}
private void clearFront()
{
while (!slices.empty && slices.front.empty) {
slices.popFront();
}
}
private void clearBack()
{
while (!slices.empty && slices.back.empty) {
slices.popBack();
}
}
@property bool empty() const
{
return slices.empty;
}
@property int front() const
{
return slices.front.front;
}
void popFront()
{
slices.front.popFront();
clearFront();
}
@property Together save() const
{
return Together(slices.dup);
}
@property int back() const
{
return slices.back.back;
}
void popBack()
{
slices.back.popBack();
clearBack();
}
@property size_t length() const
{
return reduce!((a, b) => a + b.length)(size_t.init, slices);
}
int opIndex(size_t index) const
{
/* Save the index for the error message */
immutable originalIndex = index;
foreach (slice; slices) {
if (slice.length > index) {
return slice[index];
} else {
index -= slice.length;
}
}
throw new Exception(
format("Invalid index: %s (length: %s)",
originalIndex, this.length));
}
}
void main(){
auto range = Together(FibonacciSeries().take(10).array,
[ 777, 888 ],
(new SquaresRange()).take(5).array);
writeln(range.save);
}
让我们编译和运行上面的程序,这将产生以下结果:
[0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 777, 888, 0, 1, 4, 9, 16]
OutputRange
OutputRange代表流元件的输出,类似于发送字符到stdout。 OutputRange要求对put(range, element)操作支持。put()是std.range模块中定义的函数。它确定范围和元件,在编译时,并使用最合适的方法,可用来输出的元素。一个简单的例子如下所示。
import std.algorithm;
import std.stdio;
struct MultiFile
{
string delimiter;
File[] files;
this(string delimiter, string[] fileNames ...)
{
this.delimiter = delimiter;
/* stdout is always included */
this.files ~= stdout;
/* A File object for each file name */
foreach (fileName; fileNames) {
this.files ~= File(fileName, "w");
}
}
void put(T)(T element)
{
foreach (file; files) {
file.write(element, delimiter);
}
}
}
void main(){
auto output = MultiFile("
", "output_0", "output_1");
copy([ 1, 2, 3], output);
copy([ "red", "blue", "green" ], output);
}
让我们编译和运行上面的程序,这将产生以下结果:
[1, 2, 3]
["red", "blue", "green"]
D语言别名 - D语言教程
别名,正如它的名字是指为现有名称的替代名称。别名的语法如下所示。
alias new_name = existing_name;
以下是较旧的语法,以防万一指定一些较旧的格式的例子。不推荐使用。
alias existing_name new_name;
还有用于与表达,它是下面给出中,我们可以直接使用,而不是表达的别名另一种语法。
alias expression alias_name ;
可能了解,typedef增加了创建新类型的能力。别名可以作为一个typedef类似的工作,甚至更多。一个简单的例子,使用别名,如下图所示,使用std.conv头,它提供了类型转换的能力。
import std.stdio;
import std.conv:to;
alias to!(string) toString;
void main()
{
int a = 10;
string s = "Test"~toString(a);
writeln(s);
}
当上面的代码被编译并执行,它会产生什么结果如下:
Test10
在上面的例子,而不是使用!string(a),我们已经分配给它的别名的toString使其更方便和更容易理解,我们。
元组别名
让我们来看看另一个例子,我们可以为一个元组设置别名。
import std.stdio;
import std.typetuple;
alias TypeTuple!(int, long) TL;
void method1(TL tl)
{
writeln(tl[0]," ", tl[1] );
}
void main()
{
method1(5, 6L);
}
当上面的代码被编译并执行,它会产生结果如下:
5 6
在上面的示例中,类型的元组被分配给变量的别名,它简化了的方法的定义和变量的访问。当我们尝试重用这种类型的元组的这种访问是更加有用。
别名数据类型
很多时候,我们可以定义一个需要在整个应用程序中使用通用数据类型。当多个程序员编写一个应用程序,它可以是情况下,一个人使用整型,另一双等。为了避免这种冲突,我们经常使用类型的数据类型。一个简单的例子如下所示。
import std.stdio;
alias int myAppNumber;
alias string myAppString;
void main()
{
myAppNumber i = 10;
myAppString s = "TestString";
writeln(i,s);
}
当上面的代码被编译并执行,它会产生什么结果如下:
10TestString
类变量别名
如果不熟悉的类和继承的概念,看看关于classesand继承教程开始本节之前。往往有规定,我们需要访问的子类父类的成员变量,这可以成为可能的别名,可能以不同的名称。一个简单的例子如下所示。
import std.stdio;
class Shape
{
int area;
}
class Square : Shape
{
string name() const @property
{
return "Square";
}
alias Shape.area squareArea;
}
void main()
{
auto square = new Square;
square.squareArea = 42;
writeln(square.name);
writeln(square.squareArea);
}
当上面的代码被编译并执行,它会产生结果如下:
10TestString
this别名
这个别名提供了用户自定义类型的自动类型转换的能力。其语法如下所示,其中的关键字的别名,这都写在成员变量或者成员函数的两侧。
alias member_variable_or_member_function this;
一个例子如下所示,显示此别名的能力。
import std.stdio;
struct Rectangle
{
long length;
long breadth;
double value() const @property
{
return cast(double) length * breadth;
}
alias value this;
}
double volume(double rectangle, double height)
{
return rectangle * height;
}
void main()
{
auto rectangle = Rectangle(2, 3);
writeln(volume(rectangle, 5));
}
在上面的例子中,可以看到,结构矩形转换为double值,在别名的帮助下这个方法。此代码被编译并执行,它会产生结果如下:
30
D语言混合类型 - D语言教程
混合类型的结构,使所生成的代码中混合类型的源代码。混合类型可以是以下类型。
- String 混合类型
- Template 混合类型
- 混合命名空间
String 混合类型
D语言有字符串在编译时插入代码串的能力。字符串混合类型的语法如下所示。
mixin (compile_time_generated_string)
一个简单字符串混合类型的例子如下所示。
import std.stdio;
void main()
{
mixin(`writeln("Hello World!");`);
}
当上面的代码被编译并执行,它会产生结果如下:
Hello World!
这里是另一个例子,我们可以通过在字符串中的编译时间,以便混合类型可以使用函数来重用代码。它如下所示。
import std.stdio;
string print(string s)
{
return `writeln("` ~ s ~ `");`;
}
void main()
{
mixin (print("str1"));
mixin (print("str2"));
}
当上面的代码被编译并执行,它会产生结果如下:
str1
str2
模板混合类型
D语言模板定义通用的代码模式,让编译器来生成该模式的实际情况。模板可以生成功能,结构,联合,类,接口,以及任何其他合法D代码。模板混合类型的语法如下所示。
mixin a_template!(template_parameters)
一个简单的例子字符串混合类型如下所示,我们创建一个类系和一个混合类型实例化一个模板一个模板,从而使得该功能的setName和printNames可用的结构college。
import std.stdio;
template Department(T, size_t count)
{
T[count] names;
void setName(size_t index, T name)
{
names[index] = name;
}
void printNames()
{
writeln("The names");
foreach (i, name; names)
{
writeln(i," : ", name);
}
}
}
struct College
{
mixin Department!(string, 2);
}
void main()
{
auto college = College();
college.setName(0, "name1");
college.setName(1, "name2");
college.printNames();
}
当上面的代码被编译并执行,它会产生结果如下:
The names
0 : name1
1 : name2
混入名称空间
混入的名称空间是用来避免在模板中混合类型含糊不清。例如,可以有两个变量,一个在主显式定义,而另一个是混合的。当混合在名称相同的名称是在周边范围内,则认为是在周围范围的名称得到使用。这个例子显示如下。
import std.stdio;
template Person()
{
string name;
void print()
{
writeln(name);
}
}
void main()
{
string name;
mixin Person a;
name = "name 1";
writeln(name);
a.name = "name 2";
print();
}
当上面的代码被编译并执行,它会产生结果如下:
name 1
name 2
D语言模板 - D语言教程
模板是泛型编程,涉及编写代码的方式,独立于任何特定类型的基础。
模板是蓝图或公式创建一个泛型类或函数。
模板的功能,允许描述的代码作为一种模式,让编译器自动生成的程序代码。的源代码部分可留至要填充,直到该部分是在程序实际使用的编译器。编译器填补了缺失的部分。
函数模板:
定义一个函数作为模板离开一个或多个使用作为非特定的类型,可以由编译器后面推导出来。正在未指定的类型模板形参表上,它的函数的名称,函数参数列表之间进行定义。出于这个原因,函数模板有两个参数列表:模板形参表和函数参数列表:
import std.stdio;
void print(T)(T value)
{
writefln("%s", value);
}
void main()
{
print(42);
print(1.2);
print("test");
}
如果我们编译并运行上面的代码,这会产生以下结果:
42
1.2
test
函数模板与多个类型参数
可以有多个参数类型和它示出被显示在下面的例子。
import std.stdio;
void print(T1, T2)(T1 value1, T2 value2)
{
writefln(" %s %s", value1, value2);
}
void main()
{
print(42, "Test");
print(1.2, 33);
}
如果我们编译并运行上面的代码,这会产生以下结果:
42 Test
1.2 33
类模板
正如我们可以定义函数模板,我们也可以定义类模板。下面是例子定义类Stack和实现泛型方法,推动并从弹出堆栈中的元素。
import std.stdio;
import std.string;
class Stack(T)
{
private:
T[] elements;
public:
void push(T element)
{
elements ~= element;
}
void pop()
{
--elements.length;
}
T top() const @property
{
return elements[$ - 1];
}
size_t length() const @property
{
return elements.length;
}
}
void main()
{
auto stack = new Stack!string;
stack.push("Test1");
stack.push("Test2");
writeln(stack.top);
writeln(stack.length);
stack.pop;
writeln(stack.top);
writeln(stack.length);
}
如果我们编译并运行上面的代码,这会产生以下结果:
Test2
2
Test1
1
D语言常量 - D语言教程
我们经常使用的是可变的变量,但可以有很多场合是不需要可变。不可变的变量可以在这样的情况下被使用。几个例子下面给出其中不可改变的变量都可以使用。
- 像圆周率是永远不变的数学常数。
- 阵列,其中我们希望保留的值,这是不突变的要求。
不变性使得它可以用于理解变量是不可变的或可变的低保某些操作不改变某些变量。它也减少某些类型的程序的错误的风险。 D语言的不变性概念是由const和不可改变的关键字来表示。虽然这两个词本身词义相近,它们在程序的责任是不同的,有时却是不兼容的。
不可变的变量的类型
有三种类型的限定,可以从未被可变的变量。
- 枚举常量
- 不可变的变量
- const的变量
枚举常量
枚举常量使我们能够与常数值为有意义的名称。一个简单的例子如下所示。
import std.stdio;
enum Day{
Sunday = 1,
Monday,
Tuesday,
Wednesday,
Thursday,
Friday,
Saturday
}
void main()
{
Day day;
day = Day.Sunday;
if (day == Day.Sunday)
{
writeln("The day is Sunday");
}
}
如果我们编译并运行上面的代码,这会产生以下结果:
The day is Sunday
不可变的变量
不可变的变量可以在程序的执行过程中确定。它只是指示的初始化后,它成为不可改变的编译器。一个简单的例子如下所示。
import std.stdio;
import std.random;
void main()
{
int min = 1;
int max = 10;
immutable number = uniform(min, max + 1);
// cannot modify immutable expression number
// number = 34;
typeof(number) value = 100;
writeln(typeof(number).stringof, number);
writeln(typeof(value).stringof, value);
}
如果我们编译并运行上面的代码,这会产生以下结果:
immutable(int)4
immutable(int)100
可以在上面的例子中看到它是如何可能的数据类型传送到另一个变量,并使用stringof同时打印。
const 变量
const变量不能被修改类似不可改变的。不可变的变量可以传递给函数作为他们不变的参数,因此建议使用一成不变超过常量。前面使用的相同的例子被修改为常量,如下所示。
import std.stdio;
import std.random;
void main()
{
int min = 1;
int max = 10;
const number = uniform(min, max + 1);
// cannot modify const expression number|
// number = 34;
typeof(number) value = 100;
writeln(typeof(number).stringof, number);
writeln(typeof(value).stringof, value);
}
如果我们编译并运行上面的代码,这会产生以下结果:
const(int)7
const(int)100
不可改变的参数
常量删除对原变量是否是可变的或者不可变的,因此使用不可变使得它通过它的其他函数保留了原始类型的信息。一个简单的例子如下所示。
import std.stdio;
void print(immutable int[] array)
{
foreach (i, element; array)
{
writefln("%s: %s", i, element);
}
}
void main()
{
immutable int[] array = [ 1, 2 ];
print(array);
}
如果我们编译并运行上面的代码,这会产生以下结果:
0: 1
1: 2
D语言文件I/O - D语言教程
文件是由std.stdio模块的文件结构来表示。
一个文件代表一个字节序列,不要紧,如果它是一个文本文件或二进制文件。 D编程语言提供了高级功能的访问,以及较低的水平(操作系统级别)调用来处理存储设备的文件。
打开文件
标准输入和输出流stdin和stdout已经打开,当程序开始运行。他们已经准备好可以使用。另一方面,文件必须首先通过指定该文件的名称以及所需的访问权限打开。
File file = File(filepath, "mode");
在这里,文件名是字符串文字,用它来命名文件和访问模式可以有下列值之一:
Mode | 描述 |
r | 打开读取目的,现有的文本文件。 |
w | 打开写,如果它不存在,则创建一个新的文件的文本文件。在这里,程序将开始从文件的开头写的内容。 |
a | 打开写在追加模式,如果它不存在,则创建一个新的文件的文本文件。在这里,程序将启动附加在现有文件内容的内容。 |
r+ | 打开用于读取和写入文本文件。 |
w+ | 打开用于读取和写入两个文本文件。它首先截断该文件长度为零(如果存在),否则创建的文件,如果它不存在。 |
a+ | 打开用于读取和写入两个文本文件。如果它不存在,创建该文件。该读数将从头开始写,但只能追加。 |
关闭一个文件
要关闭一个文件,请使用file.close()函数所在文件存放文件的参考。这个函数的原型为:
file.close();
当程序使用完该文件已经打开一个程序的任何文件都必须关闭。在大多数情况下,文件不需要被明确地关闭;它们会自动关闭,当文件对象会自动终止。
写入文件
file.writeln是用来写一个打开的文件。
file.writeln("hello");
import std.stdio;
import std.file;
void main()
{
File file = File("test.txt", "w");
file.writeln("hello");
file.close();
}
当上面的代码被编译并执行,它会在它已开始下(在程序的工作目录)目录中的新文件test.txt。
读取文件
下面是一个简单的方法来从文件中读取一行:
string s = file.readln();
读取和写入一个完整的示例如下所示。
import std.stdio;
import std.file;
void main()
{
File file = File("test.txt", "w");
file.writeln("hello");
file.close();
file = File("test.txt", "r");
string s = file.readln();
writeln(s);
file.close();
}
当上面的代码被编译并执行,它在读取上一节中创建的文件,并产生以下结果:
hello
这里是另一个例子,用于读取文件,直到文件结束。
import std.stdio;
import std.string;
void main()
{
File file = File("test.txt", "w");
file.writeln("hello");
file.writeln("world");
file.close();
file = File("test.txt", "r");
while (!file.eof())
{
string line = chomp(file.readln());
writeln("line -", line);
}
}
当上面的代码被编译并执行,它在读取上一节中创建的文件,并产生以下结果:
line -hello
line -world
line -
可以在上面的例子中看到一个空的第三行,因为一旦它被执行writeln需要到下一行。
D语言并发 - D语言教程
并发性是使程序在同一时间运行一个以上的线程。并发程序的一个例子是在Web服务器响应多个客户端在同一时间。并发是容易与消息传递却很难,如果它们是基于数据共享的写入。
传递线程之间的数据被称为消息。消息可以由任何类型和任意数量的变量。每个线程都有一个ID,它是用于指定邮件的收件人。即启动另一个线程的任何线程被称为新线程的所有者。即启动另一个线程的任何线程被称为新线程的所有者。
启动线程
spawn() 接受一个函数指针作为参数,并从该函数启动一个新线程。正在开展的功能,包括它可能调用其他函数的任何操作,将在新的线程中执行。owner和worker开始独立执行的,好像他们是独立的程序:
import std.stdio;
import std.stdio;
import std.concurrency;
import core.thread;
void worker(int a)
{
foreach (i; 0 .. 4)
{
Thread.sleep(1);
writeln("Worker Thread ",a + i);
}
}
void main()
{
foreach (i; 1 .. 4)
{
Thread.sleep(2);
writeln("Main Thread ",i);
spawn(&worker, i * 5);
}
writeln("main is done.");
}
当上面的代码被编译并执行,它在读取上一节中创建的文件,并产生以下结果:
Main Thread 1
Worker Thread 5
Main Thread 2
Worker Thread 6
Worker Thread 10
Main Thread 3
main is done.
Worker Thread 7
Worker Thread 11
Worker Thread 15
Worker Thread 8
Worker Thread 12
Worker Thread 16
Worker Thread 13
Worker Thread 17
Worker Thread 18
线程标识符
thisTid变量是全局可用在模块级始终是当前线程的id。也可以收到重生时被调用threadid。一个例子如下所示。
import std.stdio;
import std.concurrency;
void printTid(string tag)
{
writefln("%s: %s, address: %s", tag, thisTid, &thisTid);
}
void worker()
{
printTid("Worker");
}
void main()
{
Tid myWorker = spawn(&worker);
printTid("Owner ");
writeln(myWorker);
}
当上面的代码被编译并执行,它在读取上一节中创建的文件,并产生以下结果:
Owner : Tid(std.concurrency.MessageBox), address: 10C71A59C
Worker: Tid(std.concurrency.MessageBox), address: 10C71A59C
Tid(std.concurrency.MessageBox)
消息传递
send() 发送的消息和receiveOnly()等待一个特定类型的消息。还有prioritySend(),receive()和receiveTimeout(),这将在后面进行说明。在下面的程序的所有者将其工作者int类型的消息,并等待来自double类型的工人消息。线程继续发送邮件来回,直到车主发出了一个负的int。一个例子如下所示。
import std.stdio;
import std.concurrency;
import core.thread;
import std.conv;
void workerFunc(Tid tid)
{
int value = 0;
while (value >= 0)
{
value = receiveOnly!int();
auto result = to!double(value) * 5;
tid.send(result);
}
}
void main()
{
Tid worker = spawn(&workerFunc,thisTid);
foreach (value; 5 .. 10) {
worker.send(value);
auto result = receiveOnly!double();
writefln("sent: %s, received: %s", value, result);
}
worker.send(-1);
}
当上面的代码被编译并执行,它在读取上一节中创建的文件,并产生以下结果:
sent: 5, received: 25
sent: 6, received: 30
sent: 7, received: 35
sent: 8, received: 40
sent: 9, received: 45
消息等待传递
一个简单的例子与传递与等待消息如下所示。
import std.stdio;
import std.concurrency;
import core.thread;
import std.conv;
void workerFunc(Tid tid)
{
Thread.sleep(dur!("msecs")( 500 ),);
tid.send("hello");
}
void main()
{
spawn(&workerFunc,thisTid);
writeln("Waiting for a message");
bool received = false;
while (!received)
{
received = receiveTimeout(dur!("msecs")( 100 ),
(string message){
writeln("received: ", message);
});
if (!received) {
writeln("... no message yet");
}
}
}
当上面的代码被编译并执行,它在读取上一节中创建的文件,并产生以下结果:
Waiting for a message
... no message yet
... no message yet
... no message yet
... no message yet
received: hello
D语言异常处理 - D语言教程
异常出了问题的程序的执行期间产生了。一个D程序异常是特殊情况一个程序运行时所产生,如试图除以零的响应。
异常提供了一种从程序的一部分控制权转移到另一个。 D程序异常处理是建立在三个关键词: try, catch, 及throw.
- throw: 一个程序抛出异常时,问题出现了。这是通过使用一个throw关键字。
- catch: 一种程序,在要处理该问题的计划中的地位异常处理程序捕获异常。catch关键字表示异常捕获。
- try: try块标识代码块的哪些特定的异常将被激活。它后跟一个或多个catch块。
假设一个块将抛出一个异常,一个方法捕获使用try和catch关键字的组合异常。try/ catch块放在围绕,可能产生异常的代码。try / catch块中的代码被称为受保护的代码,以及语法使用try/ catch语句如下所示:
try
{
// protected code
}
catch( ExceptionName e1 )
{
// catch block
}
catch( ExceptionName e2 )
{
// catch block
}
catch( ExceptionName eN )
{
// catch block
}
可以列出下多个catch语句来捕获不同类型的异常的情况下,try块在不同情况提出了多个异常。
引发异常:
异常可以在任何地方使用抛出在throw语句的代码块中。在throw语句的操作数确定一个类型的异常,可以是任何表达式,表达式的结果的类型决定抛出的异常的类型。
以下是零条件除法发生抛出异常的一个例子:
double division(int a, int b)
{
if( b == 0 )
{
throw new Exception("Division by zero condition!");
}
return (a/b);
}
捕获异常:
try块中的catch块下面的捕获的任何异常。可以指定想要什么类型的异常捕捉,这是由以下关键字捕捉出现在括号中的异常声明确定的。
try
{
// protected code
}
catch( ExceptionName e )
{
// code to handle ExceptionName exception
}
上面的代码将捕获一个异常的ExceptionName类型。如果您要指定一个catch块应该处理任何类型的被扔在一个try块中的异常,必须把省略号...,内附异常声明如下括号之间:
try
{
// protected code
}
catch(...)
{
// code to handle any exception
}
下面是一个例子,它抛出一个除零异常,我们捕获它在catch块。
import std.stdio;
import std.string;
string division(int a, int b)
{
string result = "";
try {
if( b == 0 )
{
throw new Exception("Cannot divide by zero!");
}
else
{
result = format("%s",a/b);
}
}
catch (Exception e)
{
result = e.msg;
}
return result;
}
void main ()
{
int x = 50;
int y = 0;
writeln(division(x, y));
y=10;
writeln(division(x, y));
}
当上面的代码被编译并执行,它在读取上一节中创建的文件,并产生以下结果:
Cannot divide by zero!
5
契约式编程 - D语言教程
在D编程中的契约编程是专注于提供错误处理一个简单易懂的手段。在D编程契约编程是由三种类型的代码块来实现:
- body 块
- in 块
- out 块
body 块
Body块包含执行的实际功能代码。 IN和OUT块是可选的而身体块是强制性的。一个简单的语法如下所示。
return_type function_name(function_params)
in
{
// in block
}
out (result)
{
// in block
}
body
{
// actual function block
}
块中预条件
块是用于简单的预条件验证输入参数是否是可以接受的,并在可以由代码处理范围。在块中的好处是,所有的进入条件可以保持在一起,并独立于该函数的实际主体。一个简单的先决条件用于验证密码,它的最小长度如下所示。
import std.stdio;
import std.string;
bool isValid(string password)
in
{
assert(password.length>=5);
}
body
{
// other conditions
return true;
}
void main()
{
writeln(isValid("password"));
}
当上面的代码被编译并执行,它在读取上一节中创建的文件,并产生以下结果:
true
外部块后置条件
该列块从函数返回值。它验证返回值是在预期范围。显示包含在国内外享有一个简单的例子如下,转换个月,一年一个组合的十进制年龄的形式。
import std.stdio;
import std.string;
double getAge(double months,double years)
in
{
assert(months >= 0);
assert(months <= 12);
}
out (result)
{
assert(result>=years);
}
body
{
return years + months/12;
}
void main ()
{
writeln(getAge(10,12));
}
当上面的代码被编译并执行,它在读取上一节中创建的文件,并产生以下结果:
12.8333
D语言条件编译 - D语言教程
条件编译:
条件编译是选择编译以及代码,代码无法编译类似的#if/#其他/#endif在C和C ++中。未在编译的任何声明仍然必须是语法正确。条件编译涉及到条件检查是在编译时计算。就像如果运行条件语句,为,而不是条件编译的功能。以下是D程序专门为条件编译的功能。
- debug
- version/p>
- static if
debug
调试程序开发过程中是非常有用的。标记为调试的表达式和语句被编译成只在调试编译器开关启用程序。
debug a_conditionally_compiled_expression;
debug
{
// ... conditionally compiled code ...
}
else
{
// ... code that is compiled otherwise ...
}
else子句是可选的。无论是单个表达式和上面的代码块只有当调试编译器开关启用编译。
而不是完全取消的,该行可以代替被标记为调试。
debug writefln("%s debug only statement", value);
这样的行都包含在仅在调试编译器开关启用程序。
dmd test.d -oftest -w -debug
debug(tag)
调试语句可以给出的名称(标签)被列入程序选择性。
debug(mytag) writefln("%s not found", value);
这样的行包含仅在调试编译器开关启用程序。
dmd test.d -oftest -w -debug=mytag
调试块也可以有标签。
debug(mytag)
{
//
}
这是可能的,以使多个调试标记的时间。
dmd test.d -oftest -w -debug=mytag1 -debug=mytag2
debug(level)
有时,调试语句通过数值级别关联是比较有用的。提高级别可以提供更详细的信息。
import std.stdio;
void myFunction()
{
debug(1) writeln("debug1");
debug(2) writeln("debug2");
}
void main()
{
myFunction();
}
调试表达式和块为低于或等于指定级别会被编译。
$ dmd test.d -oftest -w -debug=1
$ ./test
debug1
version(tag)and version(level)
版本是类似于调试,并用于以相同的方式。else子句是可选的。虽然版本的作品本质上是相同的调试,有单独的关键字可以帮助区分他们无关的用途。与调试,多个版本可以启用。
import std.stdio;
void myFunction()
{
version(1) writeln("version1");
version(2) writeln("version2");
}
void main()
{
myFunction();
}
调试表达式和块为低于或等于指定级别会被编译。
$ dmd test.d -oftest -w -version=1
$ ./test
version1
static if
static if 是编译时相当于if语句中。就像if语句,static if 需要一个逻辑表达式,并计算它。不同的是if语句,static if 不是关于执行流程;更确切地说,它确定一块代码是否应当包括在程序或不包括。
表达是无关的是运算符,我们已经看到在空值和操作是段落,既语法和语义。下表达式是在编译时计算。它产生一个int值,0或1;取决于在括号中指定的表达式。虽然,它需要表达的是不是一个逻辑表达式,该表达式是本身被用作一个编译时逻辑表达式。它是静态的特别有用的,如果条件和模板的约束。
import std.stdio;
enum Days
{
sun,
mon,
tue,
wed,
thu,
fri,
sat
};
void myFunction(T)(T mytemplate)
{
static if (is (T == class))
{
writeln("This is a class type");
}
else static if (is (T == enum))
{
writeln("This is an enum type");
}
}
void main()
{
Days day;
myFunction(day);
}
当我们编译和运行,我们将如下得到一些输出。
This is an enum type
D语言类和对象 - D语言教程
类是D编程的核心功能,它支持面向对象的编程和通常被称为用户定义的类型。
类是用来指定对象的形式,它结合了数据表示和操纵数据成一个整齐的包装方法。类中的数据和函数被称为类的成员。
D编程类的定义:
当定义一个类时,定义了一个数据类型。这实际上并不定义任何数据,但它并定义哪些类名表示,即是什么类的对象将包括与哪些操作可以在这样一个对象来执行。
类定义以关键字class后面的类名开头和类体,由一对花括号括起来。类定义必须要么跟一个分号或声明的列表。例如,我们定义使用关键字class如下框数据类型:
class Box
{
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
}
关键字public确定类跟在它后面的成员的访问属性。公共成员都可以从类的外部访问类对象的范围内的任何地方。也可以指定一个类的成员为private或protected,我们将在一个分节讨论。
定义D对象:
一类提供对象框架,所以基本上是一个对象从一个类创建的。我们声明一个类的对象与排序完全相同的声明我们声明基本类型的变量。下面的语句声明类Box的两个对象:
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type Box
两个对象Box1和Box2都会有自己的数据成员的副本。
访问数据成员:
一个类的对象的公共数据成员可以使用直接成员访问运算符进行访问(.)让我们试试下面的例子中,直观清楚:
import std.stdio;
class Box
{
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
}
void main()
{
Box box1 = new Box(); // Declare Box1 of type Box
Box box2 = new Box(); // Declare Box2 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
box1.height = 5.0;
box1.length = 6.0;
box1.breadth = 7.0;
// box 2 specification
box2.height = 10.0;
box2.length = 12.0;
box2.breadth = 13.0;
// volume of box 1
volume = box1.height * box1.length * box1.breadth;
writeln("Volume of Box1 : ",volume);
// volume of box 2
volume = box2.height * box2.length * box2.breadth;
writeln("Volume of Box2 : ", volume);
}
当上面的代码被编译并执行,它会产生以下结果:
Volume of Box1 : 210
Volume of Box2 : 1560
要注意的是私有和受保护成员不能直接使用直接成员访问运算符(.)进行访问是重要的。我们将学习private和protected成员如何可以访问。
类和对象的详细信息:
到目前为止,已经得到了类和对象非常基本的概念。有相关的为D编程中类和对象,我们将在下面列出各个子部分进一步讨论相关的概念:
Concept | 描述 |
一个类的成员函数是一个函数,它有它的定义或像任何其他变量在类定义中它的原型。 | |
类成员可以被定义为public,private或protected。默认情况下,成员将被假定为private。 | |
类的构造函数是在创建类的新对象时调用类中的特殊功能。析构函数也是一个特殊的功能,当创建的对象被删除时调用。 | |
每个对象都有一个特殊的指针this,它指向的对象本身。 | |
一个指针,指向类完成完全相同的方式指向一个结构。其实一个类实际上只是一个带有功能结构。 | |
这两个数据成员和类的成员函数可以被声明为静态。 |
D语言封装 - D语言教程
所有的D程序有以下两个基本要素:
- 程序语句(代码): 这是一个程序,它执行动作被称为函数的一部分。
- 程序数据:该数据是受程式功能的程序的信息。
封装是操作数据的数据和功能结合在一起的面向对象编程的概念,并保持既安全不受外界干扰和误用。数据封装导致数据隐藏重要的OOP概念。
数据封装是捆绑的数据的机制,以及使用它们和数据抽象的功能是仅暴露的接口和隐藏来自用户的执行细节的机制。
D支持封装和数据通过创建用户定义的类型,称为类隐藏的属性。我们已经研究了一类可以包含私有的,受保护的和公共的成员。默认情况下,在一个类中定义的所有项目都是私有的。例如:
class Box
{
public:
double getVolume()
{
return length * breadth * height;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
变量长度,宽度和高度都是私有的。这意味着,他们只能通过Box类的其他成员进行访问,而不是由你的程序的任何其他部分。这是封装的实现方式之一。
为了使一个类公开(即,访问程序的其他部分)的部分,则必须在public关键字后声明。所有定义的变量或函数是由程序中的所有其他函数访问。
使一个类的另一个好友暴露的实施细则,并降低了封装。理想的是保持尽可能多的各类别隐藏所有其他类尽可能的详细信息。
数据封装示例:
实现一个类的公共和私有成员的任何D程序是数据封装和数据抽象的例子。请看下面的例子:
import std.stdio;
class Adder{
public:
// constructor
this(int i = 0)
{
total = i;
}
// interface to outside world
void addNum(int number)
{
total += number;
}
// interface to outside world
int getTotal()
{
return total;
};
private:
// hidden data from outside world
int total;
}
void main( )
{
Adder a = new Adder();
a.addNum(10);
a.addNum(20);
a.addNum(30);
writeln("Total ",a.getTotal());
}
当上面的代码被编译并执行,它会产生以下结果:
Total 60
上面的类添加数相加,并返回总和。公共成员addNum和getTotal是外面的世界的接口,一个用户需要知道他们使用的类。私有成员total 是从外界隐藏的,但需要为类正常运作。
设计策略:
我们大多数人都通过痛苦经历教训,默认情况下类成员是私有的,除非我们真的要揭露他们。这只是良好的封装。
这种智慧是最常应用于数据成员,但它同样适用于所有成员,包括虚函数。
D语言接口 - D语言教程
接口是迫使从它继承的类必须实现某些功能或变量的方法。函数不能在一个接口来实现,因为它们在从接口继承的类总是执行。使用interface关键字代替,尽管两者在很多方面是相似的class关键字创建一个接口。当你想从一个接口继承和类已经从另一个类继承,那么需要单独的类的名称,并用逗号将接口的名称。
让我们来看一个简单的例子,说明使用的接口。
import std.stdio;
// Base class
interface Shape
{
public:
void setWidth(int w);
void setHeight(int h);
}
// Derived class
class Rectangle: Shape
{
int width;
int height;
public:
void setWidth(int w)
{
width = w;
}
void setHeight(int h)
{
height = h;
}
int getArea()
{
return (width * height);
}
}
void main()
{
Rectangle Rect = new Rectangle();
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
writeln("Total area: ", Rect.getArea());
}
当上面的代码被编译并执行,它会产生以下结果:
Total area: 35
Final和静态函数接口
一个接口可以有最终的和静态方法的定义应包括在接口本身。这些功能不能过度由派生类重载。一个简单的例子如下所示。
import std.stdio;
// Base class
interface Shape
{
public:
void setWidth(int w);
void setHeight(int h);
static void myfunction1()
{
writeln("This is a static method");
}
final void myfunction2()
{
writeln("This is a final method");
}
}
// Derived class
class Rectangle: Shape
{
int width;
int height;
public:
void setWidth(int w)
{
width = w;
}
void setHeight(int h)
{
height = h;
}
int getArea()
{
return (width * height);
}
}
void main()
{
Rectangle rect = new Rectangle();
rect.setWidth(5);
rect.setHeight(7);
// Print the area of the object.
writeln("Total area: ", rect.getArea());
rect.myfunction1();
rect.myfunction2();
}
让我们编译和运行上面的程序,这将产生以下结果:
Total area: 35
This is a static method
This is a final method
D语言抽象类 - D语言教程
抽象是指能够使一个抽象类在面向对象编程的能力。抽象类是不能被实例化。该类别的所有其他功能仍然存在,及其字段、方法和构造函数以相同的方式被访问的。不能创建抽象类的实例。
如果一个类是抽象的,不能被实例化,类没有多大用处,除非它是子类。这通常是在设计阶段的抽象类是怎么来的。父类包含子类的集合的通用功能,但父类本身是过于抽象而被单独使用。
抽象类
使用abstract关键字来声明一个类的抽象。关键字出现在类声明的地方class关键字前。下面显示了如何抽象类可以继承和使用的例子。
import std.stdio;
import std.string;
import std.datetime;
abstract class Person
{
int birthYear, birthDay, birthMonth;
string name;
int getAge()
{
SysTime sysTime = Clock.currTime();
return sysTime.year - birthYear;
}
}
class Employee : Person
{
int empID;
}
void main()
{
Employee emp = new Employee();
emp.empID = 101;
emp.birthYear = 1980;
emp.birthDay = 10;
emp.birthMonth = 10;
emp.name = "Emp1";
writeln(emp.name);
writeln(emp.getAge);
}
当我们编译并运行上面的程序,我们会得到下面的输出。
Emp1
34
抽象函数
类似的函数,类也可以做成抽象。这种功能的实现是不是在同级类中给出,但应在继承的类与抽象函数的类来提供。上述例子是用抽象的功能更新,并在下面给出。
import std.stdio;
import std.string;
import std.datetime;
abstract class Person
{
int birthYear, birthDay, birthMonth;
string name;
int getAge()
{
SysTime sysTime = Clock.currTime();
return sysTime.year - birthYear;
}
abstract void print();
}
class Employee : Person
{
int empID;
override void print()
{
writeln("The employee details are as follows:");
writeln("Emp ID: ", this.empID);
writeln("Emp Name: ", this.name);
writeln("Age: ",this.getAge);
}
}
void main()
{
Employee emp = new Employee();
emp.empID = 101;
emp.birthYear = 1980;
emp.birthDay = 10;
emp.birthMonth = 10;
emp.name = "Emp1";
emp.print();
}
当我们编译并运行上面的程序,我们会得到下面的输出。
The employee details are as follows:
Emp ID: 101
Emp Name: Emp1
Age: 34
D语言类和对象 - D语言教程
类是D编程的核心功能,它支持面向对象的编程和通常被称为用户定义的类型。
类是用来指定对象的形式,它结合了数据表示和操纵数据成一个整齐的包装方法。类中的数据和函数被称为类的成员。
D编程类的定义:
当定义一个类时,定义了一个数据类型。这实际上并不定义任何数据,但它并定义哪些类名表示,即是什么类的对象将包括与哪些操作可以在这样一个对象来执行。
类定义以关键字class后面的类名开头和类体,由一对花括号括起来。类定义必须要么跟一个分号或声明的列表。例如,我们定义使用关键字class如下框数据类型:
class Box
{
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
}
关键字public确定类跟在它后面的成员的访问属性。公共成员都可以从类的外部访问类对象的范围内的任何地方。也可以指定一个类的成员为private或protected,我们将在一个分节讨论。
定义D对象:
一类提供对象框架,所以基本上是一个对象从一个类创建的。我们声明一个类的对象与排序完全相同的声明我们声明基本类型的变量。下面的语句声明类Box的两个对象:
Box Box1; // Declare Box1 of type Box
Box Box2; // Declare Box2 of type Box
两个对象Box1和Box2都会有自己的数据成员的副本。
访问数据成员:
一个类的对象的公共数据成员可以使用直接成员访问运算符进行访问(.)让我们试试下面的例子中,直观清楚:
import std.stdio;
class Box
{
public:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
}
void main()
{
Box box1 = new Box(); // Declare Box1 of type Box
Box box2 = new Box(); // Declare Box2 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
box1.height = 5.0;
box1.length = 6.0;
box1.breadth = 7.0;
// box 2 specification
box2.height = 10.0;
box2.length = 12.0;
box2.breadth = 13.0;
// volume of box 1
volume = box1.height * box1.length * box1.breadth;
writeln("Volume of Box1 : ",volume);
// volume of box 2
volume = box2.height * box2.length * box2.breadth;
writeln("Volume of Box2 : ", volume);
}
当上面的代码被编译并执行,它会产生以下结果:
Volume of Box1 : 210
Volume of Box2 : 1560
要注意的是私有和受保护成员不能直接使用直接成员访问运算符(.)进行访问是重要的。我们将学习private和protected成员如何可以访问。
类和对象的详细信息:
到目前为止,已经得到了类和对象非常基本的概念。有相关的为D编程中类和对象,我们将在下面列出各个子部分进一步讨论相关的概念:
Concept | 描述 |
一个类的成员函数是一个函数,它有它的定义或像任何其他变量在类定义中它的原型。 | |
类成员可以被定义为public,private或protected。默认情况下,成员将被假定为private。 | |
类的构造函数是在创建类的新对象时调用类中的特殊功能。析构函数也是一个特殊的功能,当创建的对象被删除时调用。 | |
每个对象都有一个特殊的指针this,它指向的对象本身。 | |
一个指针,指向类完成完全相同的方式指向一个结构。其实一个类实际上只是一个带有功能结构。 | |
这两个数据成员和类的成员函数可以被声明为静态。 |
类继承 - D语言教程
在面向对象编程中一个最重要的概念就是继承。继承允许我们在另一个类,这使得它更容易创建和维护一个应用程序来定义一个类。这也提供了一个机会重用代码的功能和快速的实施时间。
当创建一个类,而不是完全写入新的数据成员和成员函数,程序员可以指定新的类要继承现有类的成员。这个现有的类称为基类,新类称为派生类。
继承的想法实现是有关系的。例如,哺乳动物IS-A动物,狗,哺乳动物,因此狗IS-A动物,等等。
基类和派生类:
一个类可以从多个类中派生的,这意味着它可以继承数据和函数从多个基类。要定义一个派生类中,我们使用一个类派生列表中指定的基类(ES)。一个类派生列表名称的一个或多个基类和具有形式:
class derived-class: base-class
考虑一个基类Shape和它的派生类Rectangle,如下所示:
import std.stdio;
// Base class
class Shape
{
public:
void setWidth(int w)
{
width = w;
}
void setHeight(int h)
{
height = h;
}
protected:
int width;
int height;
}
// Derived class
class Rectangle: Shape
{
public:
int getArea()
{
return (width * height);
}
}
void main()
{
Rectangle Rect = new Rectangle();
Rect.setWidth(5);
Rect.setHeight(7);
// Print the area of the object.
writeln("Total area: ", Rect.getArea());
}
当上面的代码被编译并执行,它会产生以下结果:
Total area: 35
访问控制和继承:
派生类可以访问它的基类的所有非私有成员。因此,基类成员,不应该访问的派生类的成员函数应在基类中声明为private。
派生类继承了所有基类方法有以下例外:
- 构造函数,析构函数和基类的拷贝构造函数。
- 基类的重载运算符。
多层次继承
继承可以是多级的,如下面的例子。
import std.stdio;
// Base class
class Shape
{
public:
void setWidth(int w)
{
width = w;
}
void setHeight(int h)
{
height = h;
}
protected:
int width;
int height;
}
// Derived class
class Rectangle: Shape
{
public:
int getArea()
{
return (width * height);
}
}
class Square: Rectangle
{
this(int side)
{
this.setWidth(side);
this.setHeight(side);
}
}
void main()
{
Square square = new Square(13);
// Print the area of the object.
writeln("Total area: ", square.getArea());
}
让我们编译和运行上面的程序,这将产生以下结果:
Total area: 169
重载 - D语言教程
D编程允许为一个函数名或在相同的范围内操作,这就是所谓的函数重载和运算符重载分别指定一个以上的定义。
重载声明的是,已被声明具有相同的名称,在同一范围内先前声明的声明的声明,除了这两个声明具有不同的参数和明显不同的定义(实现)。
当调用一个重载函数或运算符,编译器确定最合适的定义,通过比较你用来调用函数或运算符的定义中指定的参数类型的参数类型来使用。选择最合适的重载函数或运算符的过程被称为重载解析。
函数重载
可以有相同的函数名多个定义在相同的范围。该函数的定义必须由类型和/或参数在参数列表中的号码彼此不同。不能重载函数声明只相差返回类型。
以下是其中相同功能的print()被用于打印不同的数据类型的示例:
import std.stdio;
import std.string;
class printData
{
public:
void print(int i) {
writeln("Printing int: ",i);
}
void print(double f) {
writeln("Printing float: ",f );
}
void print(string s) {
writeln("Printing string: ",s);
}
};
void main()
{
printData pd = new printData();
// Call print to print integer
pd.print(5);
// Call print to print float
pd.print(500.263);
// Call print to print character
pd.print("Hello D");
}
让我们编译和运行上面的程序,这将产生以下结果:
Printing int: 5
Printing float: 500.263
Printing string: Hello D
运算符重载
可以重新定义或超载最多可用在D内置运算符因此程序员可以使用运算符与用户定义的类型也是如此。
运算符可以使用字符串运算其次是ADD,SUB超载等基于正被重载的运算符。我们可以重载运算符+,如下图所示添加两个箱子。
Box opAdd(Box b)
{
Box box = new Box();
box.length = this.length + b.length;
box.breadth = this.breadth + b.breadth;
box.height = this.height + b.height;
return box;
}
以下是该示例使用一个成员函数来显示运算符的重载的概念。在这里,一个对象作为参数传递,其属性将使用此对象来访问,这将调用this操作符的对象可以使用此运算符来访问,解释如下:
import std.stdio;
class Box
{
public:
double getVolume()
{
return length * breadth * height;
}
void setLength( double len )
{
length = len;
}
void setBreadth( double bre )
{
breadth = bre;
}
void setHeight( double hei )
{
height = hei;
}
Box opAdd(Box b)
{
Box box = new Box();
box.length = this.length + b.length;
box.breadth = this.breadth + b.breadth;
box.height = this.height + b.height;
return box;
}
private:
double length; // Length of a box
double breadth; // Breadth of a box
double height; // Height of a box
};
// Main function for the program
void main( )
{
Box box1 = new Box(); // Declare box1 of type Box
Box box2 = new Box(); // Declare box2 of type Box
Box box3 = new Box(); // Declare box3 of type Box
double volume = 0.0; // Store the volume of a box here
// box 1 specification
box1.setLength(6.0);
box1.setBreadth(7.0);
box1.setHeight(5.0);
// box 2 specification
box2.setLength(12.0);
box2.setBreadth(13.0);
box2.setHeight(10.0);
// volume of box 1
volume = box1.getVolume();
writeln("Volume of Box1 : ", volume);
// volume of box 2
volume = box2.getVolume();
writeln("Volume of Box2 : ", volume);
// Add two object as follows:
box3 = box1 + box2;
// volume of box 3
volume = box3.getVolume();
writeln("Volume of Box3 : ", volume);
}
当上面的代码被编译并执行,它会产生以下结果:
Volume of Box1 : 210
Volume of Box2 : 1560
Volume of Box3 : 5400
运算符重载类型:
基本上,有三种类型的操作符如下面列出重载。
S.N. | 重载类型 |
1 | |
2 | |
3 |
