




yum install -y docker-ce docker-ce-cli containerd.io
安装完成后根据需要调整 docker 目录,防止后面目录空间写超。
(polardb) [root@sfx110008 polardb-test]# cat etc/docker/daemon.json{"exec-opts": ["native.cgroupdriver=systemd"],"data-root":"/opt/docker"}(polardb) [root@sfx110008 polardb-test]# ll opt/dockerlrwxrwxrwx 1 root root 20 Feb 13 16:28 opt/docker -> data/nvme1n1/docker(polardb) [root@sfx110008 polardb-test]#
拉取 PolarDB-PG docker 镜像并启动 3个容器。这里选择镜像 polardb_pg_binary:pfs 。
docker pull polardb/polardb_pg_binary:pfsdocker run -itd --cap-add=SYS_PTRACE --privileged=true --name polardb_pg_rw --shm-size=32g --memory=64g --cpus=16 polardb/polardb_pg_binary:pfsdocker run -itd --cap-add=SYS_PTRACE --privileged=true --name polardb_pg_ro1 --shm-size=32g --memory=64g --cpus=16 polardb/polardb_pg_binary:pfsdocker run -itd --cap-add=SYS_PTRACE --privileged=true --name polardb_pg_ro2 --shm-size=32g --memory=64g --cpus=16 polardb/polardb_pg_binary:pfs
部署后镜像和容器如下
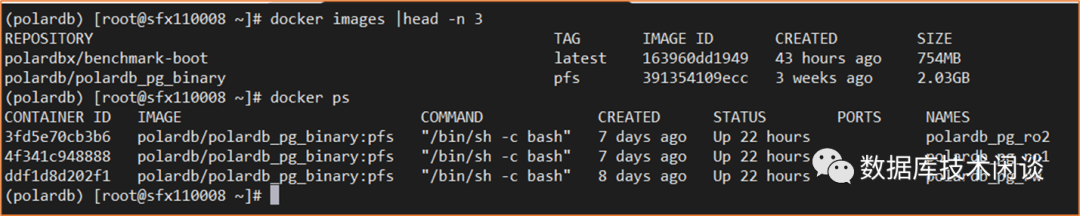
PolarFS 初始化
postgres@6b5fbf632daa:~$ sudo lsblk dev/nvme0n1NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINTnvme0n1 259:0 0 3.5T 0 disk`-nvme0n1p1 259:2 0 1000G 0 partpostgres@6b5fbf632daa:~$ sudo pfs -C disk mkfs nvme0n1p1pfs tool cmd record:mkfs nvme0n1p1[PFS_LOG] Feb 14 10:50:37.830967 INF [27] pfs build version:libpfs_version_("pfsd-build-desc-_-Tue Jan 31 22:56:28 CST 2023")[PFS_LOG] Feb 14 10:50:37.831035 INF [27] pid: 26, caller: sudo pfs -C disk mkfs nvme0n1p1[PFS_LOG] Feb 14 10:50:37.831056 INF [27] pid: 13, caller: bash[PFS_LOG] Feb 14 10:50:37.831078 INF [27] open device cluster disk, devname nvme0n1p1, flags 0x13[PFS_LOG] Feb 14 10:50:37.831090 INF [27] disk dev path: dev/nvme0n1p1[PFS_LOG] Feb 14 10:50:37.831092 INF [27] open local disk: open(/dev/nvme0n1p1, 0x4002)[PFS_LOG] Feb 14 10:50:37.831102 INF [27] ioctl status 0[PFS_LOG] Feb 14 10:50:37.831104 INF [27] pfs_diskdev_info get pi_pbdno 0, pi_rwtype 1, pi_unitsize 4194304, pi_chunksize 10737418240, pi_disksize 1073741824000[PFS_LOG] Feb 14 10:50:37.831107 INF [27] pfs_diskdev_info waste size: 0[PFS_LOG] Feb 14 10:50:37.831109 INF [27] disk size 0xfa00000000, chunk size 0x280000000[PFS_LOG] Feb 14 10:50:37.831194 ERR [27] chunk 0 pfs magic mismatch 0 vs 0x5046534348[PFS_LOG] Feb 14 10:50:37.831228 INF [27] mkfs PBD nvme0n1p1 isn't formattedInit chunk 0metaset 0/1: sectbda 0x1000, npage 80, objsize 128, nobj 2560, oid range [ 0, a00)metaset 0/2: sectbda 0x51000, npage 64, objsize 128, nobj 2048, oid range [ 0, 800)metaset 0/3: sectbda 0x91000, npage 64, objsize 128, nobj 2048, oid range [ 0, 800)Init chunk 1< …… >Init chunk 99metaset 63/1: sectbda 0xf780001000, npage 80, objsize 128, nobj 2560, oid range [ 63000, 63a00)metaset 63/2: sectbda 0xf780051000, npage 64, objsize 128, nobj 2048, oid range [ 31800, 32000)metaset 63/3: sectbda 0xf780091000, npage 64, objsize 128, nobj 2048, oid range [ 31800, 32000)Inited filesystem(1073741824000 bytes), 100 chunks, 2560 blktags, 2048 direntries, 2048 inodes per chunkmaking paxos fileinit paxos leasemaking journal filepfs mkfs succeeds!postgres@6b5fbf632daa:~$ sudo usr/local/polarstore/pfsd/bin/start_pfsd.sh -p nvme0n1p1 -w 2option workers 2option pbdname nvme0n1p1option server id 0option logconf usr/local/polarstore/pfsd/bin/../conf/pfsd_logger.confstarting pfsd[67] nvme0n1p1pfsdaemon nvme0n1p1 start success
测试一下文件系统的读写。
postgres@6b5fbf632daa:~$ pfs -C disk touch nvme0n1p1/hello.txtpostgres@6b5fbf632daa:~$ pfs -C disk ls nvme0n1p1/File 1 4194304 Tue Feb 14 10:50:38 2023 .pfs-paxosFile 1 1073741824 Tue Feb 14 10:50:38 2023 .pfs-journalFile 1 0 Tue Feb 14 10:58:52 2023 hello.txttotal 2105344 (unit: 512Bytes)
PFS 命令参考 :https://docs.polardbpg.com/1653230754878/PolarDB-FileSystem/PFS-File-System-Operation.html
postgres@6b5fbf632daa:~$ $HOME/tmp_basedir_polardb_pg_1100_bld/bin/initdb -D $HOME/primary-- 创建PG数据共享目录postgres@6b5fbf632daa:~$ sudo pfs -C disk mkdir nvme0n1p1/shared_datapostgres@6b5fbf632daa:~$ sudo $HOME/tmp_basedir_polardb_pg_1100_bld/bin/polar-initdb.sh $HOME/primary/ /nvme0n1p1/shared_data/pfs tool cmd record:cp -r home/postgres/primary//base nvme0n1p1/shared_data//[PFS_LOG] Feb 14 11:13:38.484330 INF [938] pfs build version:libpfs_version_("pfsd-build-desc-_-Tue Jan 31 22:56:28 CST 2023")[PFS_LOG] Feb 14 11:13:38.484396 INF [938] pid: 890, caller: /bin/bash home/postgres/tmp_basedir_polardb_pg_1100_bld/bin/polar-initdb.sh home/postgres/primary/ /nvme0n1p1/shared_data/[PFS_LOG] Feb 14 11:13:38.484420 INF [938] pid: 889, caller: sudo home/postgres/tmp_basedir_polardb_pg_1100_bld/bin/polar-initdb.sh home/postgres/primary/ /nvme0n1p1/shared_data/[PFS_LOG] Feb 14 11:13:38.484440 INF [938] pid: 13, caller: bash<……>init polarDB data dir success
修改 PG 的参数文件 postgresql.conf
postgres@6b5fbf632daa:~$ vim + ~/primary/postgresql.confport=5432polar_hostid=1polar_enable_shared_storage_mode=onpolar_disk_name='nvme0n1p1'polar_datadir='/nvme0n1p1/shared_data/'polar_vfs.localfs_mode=offshared_preload_libraries='$libdir/polar_vfs,$libdir/polar_worker'polar_storage_cluster_name='disk'logging_collector=onlog_line_prefix='%p\t%r\t%u\t%m\t'log_directory='pg_log'listen_addresses='*'max_connections=1000synchronous_standby_names='replica1'shared_buffers = 32GB # min 128kBbgwriter_delay = 10ms # 10-10000ms between roundssynchronous_commit = off # synchronization level;checkpoint_timeout = 30min # range 30s-1dmax_wal_size = 64GBmin_wal_size = 16GBcheckpoint_completion_target = 0.9 # checkpoint target duration, 0.0 - 1.0
修改权限访问控制配置文件 pg_hba.conf
postgres@6b5fbf632daa:~$ vim + ~/primary/pg_hba.confhost all all 172.17.0.0/16 trusthost replication postgres 0.0.0.0/0 trust
启动 PolarDB-PG 主实例。
postgres@6b5fbf632daa:~$ pg_ctl start -D $HOME/primary
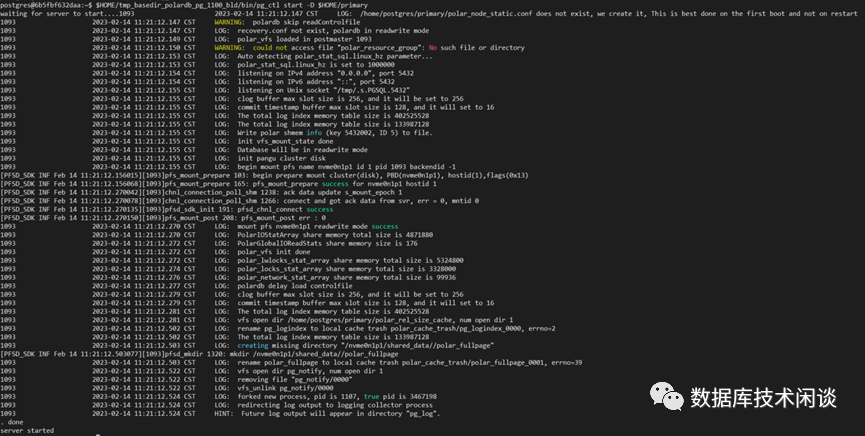
验证当前实例连接和版本。
postgres@6b5fbf632daa:~$ psql -p 5432 -d postgres -c 'select now(),version();'now | version-------------------------------+--------------------------------2023-02-14 11:23:13.473181+08 | PostgreSQL 11.9 (POLARDB 11.9)(1 row)
在读写节点上,为对应的只读节点创建相应的复制用的slot,用于只读节点的物理复制。
postgres@6b5fbf632daa:~$ psql -p 5432 -d postgres -c "SELECT pg_create_physical_replication_slot('replica1');"pg_create_physical_replication_slot-------------------------------------(replica1,)(1 row)postgres@6b5fbf632daa:~$ psql -p 5432 -d postgres -c "SELECT pg_create_physical_replication_slot('replica2');"pg_create_physical_replication_slot-------------------------------------(replica2,)(1 row)
postgres@5c15cd84e29e:~$ sudo usr/local/polarstore/pfsd/bin/start_pfsd.sh -p nvme0n1p1 -w 2option workers 2option pbdname nvme0n1p1option server id 0option logconf usr/local/polarstore/pfsd/bin/../conf/pfsd_logger.confstarting pfsd[130] nvme0n1p1pfsdaemon nvme0n1p1 start successpostgres@5c15cd84e29e:~$ mkdir -m 0700 $HOME/replica1postgres@5c15cd84e29e:~$ sudo ~/tmp_basedir_polardb_pg_1100_bld/bin/polar-replica-initdb.sh nvme0n1p1/shared_data/ $HOME/replica1/<……>init polarDB replica mode dir successpostgres@5c15cd84e29e:~$ sudo chown -R postgres.postgres replica1/postgres@5c15cd84e29e:~$ $HOME/tmp_basedir_polardb_pg_1100_bld/bin/initdb -D /tmp/replica1postgres@5c15cd84e29e:~$ cp /tmp/replica1/*.conf $HOME/replica1/
postgres@5c15cd84e29e:~$ vim + ~/replica1/postgresql.confport=5433polar_hostid=2polar_enable_shared_storage_mode=onpolar_disk_name='nvme0n1p1'polar_datadir='/nvme0n1p1/shared_data/'polar_vfs.localfs_mode=offshared_preload_libraries='$libdir/polar_vfs,$libdir/polar_worker'polar_storage_cluster_name='disk'logging_collector=onlog_line_prefix='%p\t%r\t%u\t%m\t'log_directory='pg_log'listen_addresses='*'max_connections=1000shared_buffers = 50GB # min 128kBpostgres@5c15cd84e29e:~$ vim + ~/replica1/recovery.confpolar_replica='on'recovery_target_timeline='latest'primary_slot_name='replica1'primary_conninfo='host=172.17.0.2 port=5432 user=postgres dbname=postgres application_name=replica1'
启动 PolarDB-PG 只读实例。
postgres@5c15cd84e29e:~$ $HOME/tmp_basedir_polardb_pg_1100_bld/bin/pg_ctl start -D $HOME/replica1
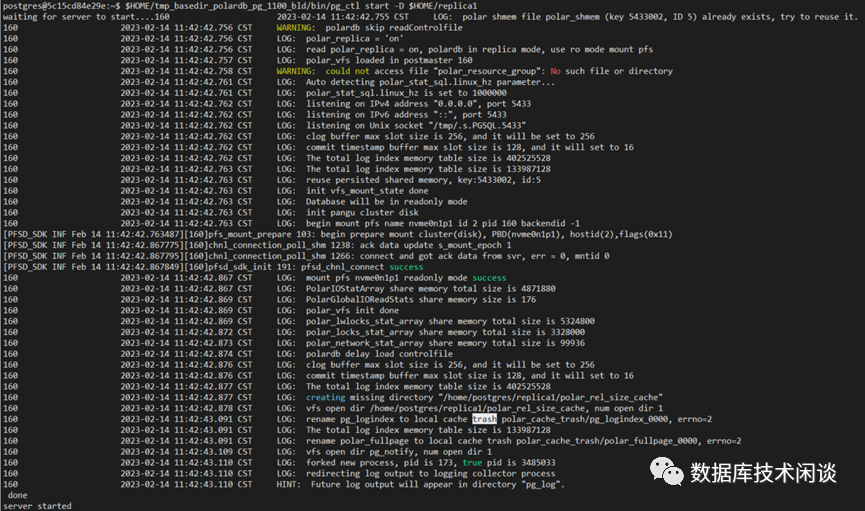
同样的方法部署第二个只读实例。然后在主实例上查看复制状态。
postgres=# select pid, usesysid, usename, application_name, client_addr, client_port, backend_start, state, write_lag, sync_priority, sync_state from pg_stat_replication ;pid | usesysid | usename | application_name | client_addr | client_port | backend_start | state | write_lag | sync_priority | sync_state--------+----------+----------+------------------+-------------+-------------+-------------------------------+-----------+-----------------+---------------+------------1151 | 10 | postgres | replica1 | 172.17.0.3 | 52316 | 2023-02-14 11:42:43.350244+08 | streaming | 00:00:00.000043 | 1 | sync345775 | 10 | postgres | replica2 | 172.17.0.4 | 48322 | 2023-02-14 13:54:16.52181+08 | streaming | 00:00:00.00005 | 0 | async(2 rows)
此时也可以在主实例创建数据库和表,并初始化数据,然后到只读实例里观察同步效果。
PolarDB-PG HTAP 读写分离测试
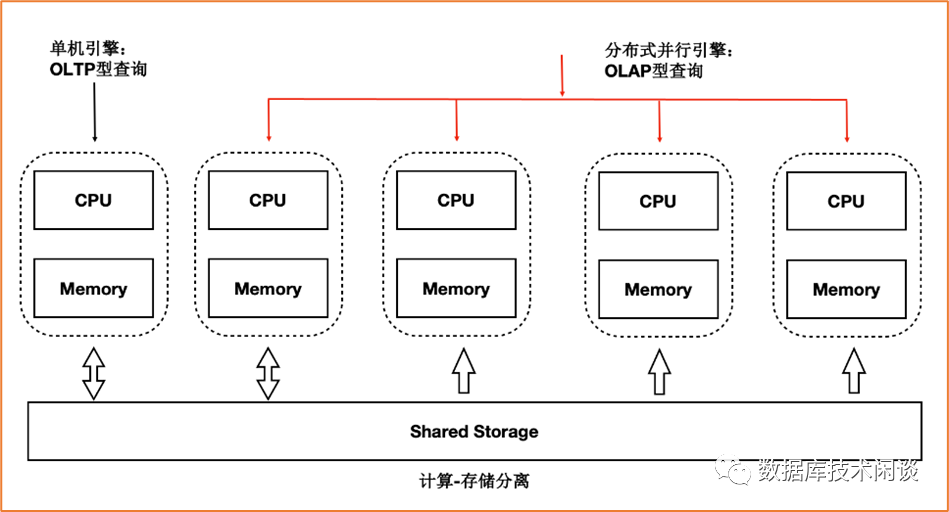
alter system set polar_cluster_map='replica1|172.17.0.3|5433,replica2|172.17.0.4|5433';alter system set polar_enable_px=on;alter system set polar_px_optimizer_enable_hashagg=off;alter system set polar_px_enable_partition =true;alter system set polar_px_optimizer_multilevel_partitioning = true;alter system set polar_px_dop_per_node =32;alter system set polar_px_max_workers_number=768;select pg_reload_conf();alter table supplier set (px_workers=500);alter table region set (px_workers=500);alter table partsupp set (px_workers=500);alter table part set (px_workers=500);alter table orders set (px_workers=500);alter table nation set (px_workers=500);alter table lineitem set (px_workers=500);alter table customer set (px_workers=500);
如下面 SQL (TPC-H Query3.sql)
[postgres@sfx110008 tpchdb]$cat sqls/3.sql-- using 1677059909 as a seed to the RNGselectl_orderkey,sum(l_extendedprice * (1 - l_discount)) as revenue,o_orderdate,o_shippriorityfromcustomer,orders,lineitemwherec_mktsegment = 'FURNITURE'and c_custkey = o_custkeyand l_orderkey = o_orderkeyand o_orderdate < date '1995-03-22'and l_shipdate > date '1995-03-22'group byl_orderkey,o_orderdate,o_shippriorityorder byrevenue desc,o_orderdate;
执行计划如下:

当最下方执行计划中有提示“Optimizer: PolarDB PX Optimizer”,就表示这是个跨机的并行执行计划。当有只读实例时,这个执行计划会被发往只读实例执行。
PolarDB-PG 提供了 TPC-H 的初始化脚本。
git clone https://github.com/HBKO/tpch-dbgen.gitcd tpch-dbgenvi build.shpg_user=tpchpg_database=tpchdbpg_host=172.17.0.4pg_port=5432data_scale=10is_run=-1test_case=18sh build.sh
执行脚本之前需要提前创建好数据库和账号。
create user tpch with password 'scaleflux';create database tpchdb owner tpch;grant all privileges on database tpchdb to tpch
然后写一个脚本,顺序批量运行 TPC-H 22个查询。
[postgres@sfx110008 tpchdb]$cat polardb_pg_tpch_test.sh#!/bin/bashexport PGHOST=172.17.0.4export PGPORT=5432export PGUSER=tpchexport PGPASSWORD=scalefluxexport PGDATABASE=tpchdbechoecho "tpch queries begin at "`date "+%Y%m%d%H%M%S"`echofor i in `seq 22`;doecho " tpch query : " $i " at "`date "+%Y%m%d%H%M%S"`;/bin/cp -f /data/nvme1n1/tpch-dbgen/finals/$i*.sql ./output/time psql -f /data/nvme1n1/tpch-dbgen/finals/$i.explain.sql -L ./output/$i.explain.sql.log 1>/dev/null ;time psql -f /data/nvme1n1/tpch-dbgen/finals/$i.sql -L ./output/$i.sql.log 1>/dev/null ;echo " tpch query : " $i " end "`date "+%Y%m%d%H%M%S"`;echo#echo " sleep 10 seconds ..."#sleep 10;echodone;echo "tpch queries end at "`date "+%Y%m%d%H%M%S"`echo
当运行TPC-H 查询的时候,可以观察 PolarDB-PG 的容器 CPU 资源消耗,只读实例 CPU 明显高于主实例,说明读写分离起作用了。

其他参考
文章转载自数据库技术闲谈,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
