





摘要
点击查看「顶会论文解读」
1.背景
● KV存储系统具有灵活的数据模型,数据表示为KV对形式,为任意数据类型,且长度不定;
● KV存储的访存接口非常简单,向外提供Put、Get、Scan等简单的接口进行数据读写;

2、目前主流的持久化KV存储系统都采用LSM-tree(log-structured merge tree)架构作为存储引擎,其具有高效的写入效率,但同时存在严重的读写放大问题。
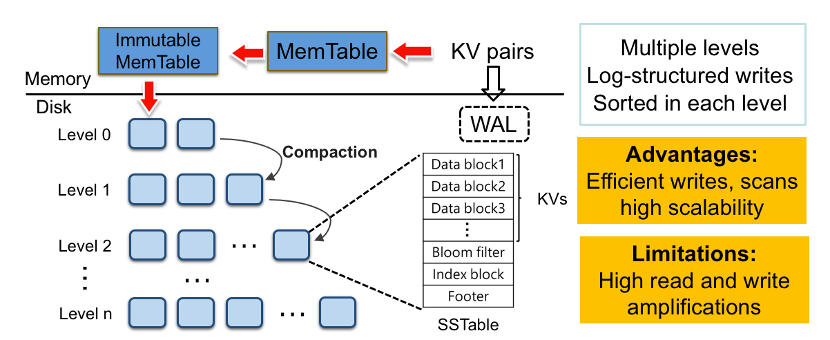
3、分布式KV存储系统被广泛应用,以支持大规模的数据存储。
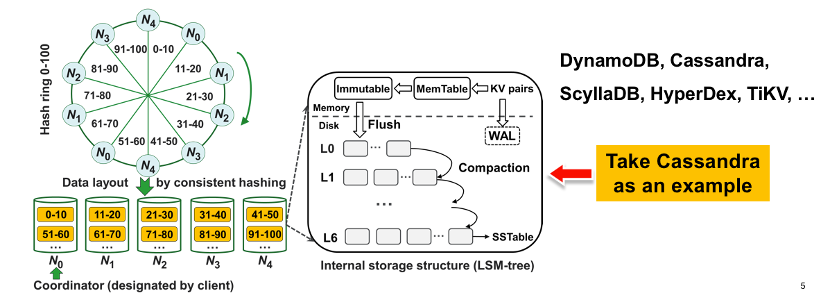
如图,KV数据首先基于Key的一致性哈希进行分区,图中有五个物理节点,每个节点有两个虚拟节点,因此整个哈希环被划分成十个范围段。图中0到100的范围段被划分成0-10、11-20、21-30等十个范围段,并且每个范围段都与顺时针方向最近的虚拟节点和相对应的物理节点相关联。比如0-10、51-60这两个范围段被划分到节点0;11-20和61-70这两个范围段被划分到节点1。
● 主副本:指通过一致性哈希划分策略划分到节点上的数据;
● 冗余副本:指通过复制策略发送到节点上的冗余数据;
● 统一索引:对于节点上的主副本和冗余副本,现有KV存储系统都采用统一的多副本管理方案,也就是把主副本和冗余副本统一存储在一个LSM-tree中,如下图。
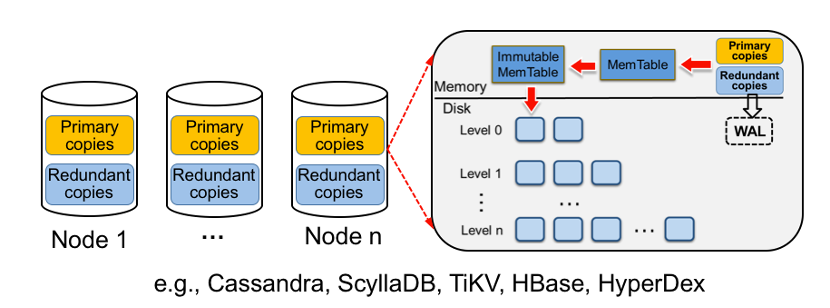
考虑到LSM-tree架构本身存在严重的读写放大问题,而统一的索引方案又会极大的增加LSM-tree中存储的数据量,因此会进一步加剧LSM-tree的读写放大问题。
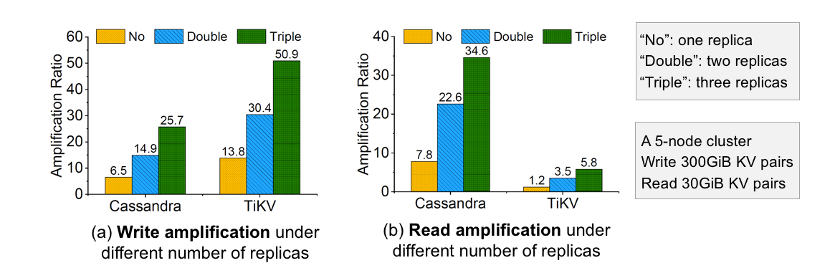
如图,在五个节点构成的本地存储集群上进行实验,客户端首先写入300GB的KV数据,然后从集群中读出30GB的KV数据,KV大小为1KB,这里分别统计了分布式KV系统Cassandra和TiKV在不同副本数量下的读写放大系数,图(a)展示了写放大系数,图(b)展示了读放大系数。
2.设计
为解决分布式KV系统中统一多副本管理导致的问题,接下来介绍解决方案。
2.1 设计思想
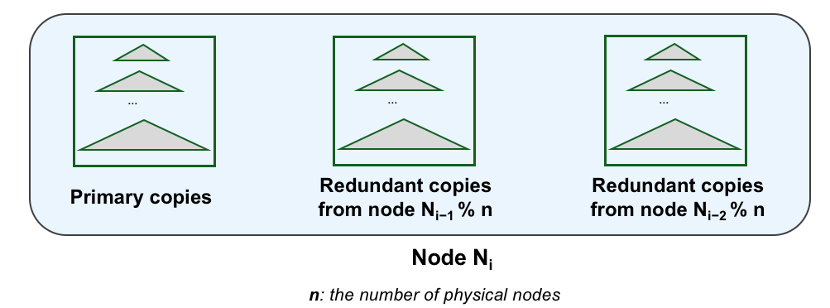
如图,当系统配置为三副本时,在每个存储节点上使用一个LSM-tree来存储主副本,另外两个LSM-tree来分别存储来自其他两个节点的冗余副本。这种方案的想法及实现都非常简单,但是存在着一些典型的问题。
2.2 mLSM的两个主要限制
● 多个LSM-tree会导致K倍的内存开销,因为每个LSM-tree都需要在内存中维护一个MemTable;
2.3 设计方案
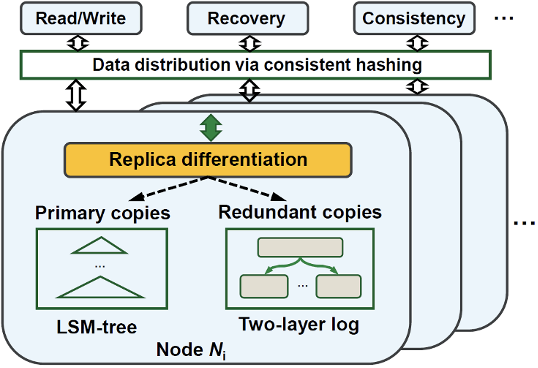
2.4 方案挑战
a. 挑战一:如何设计副本区分机制
实现主副本和冗余副本的解耦,下图是一个轻量级的副本区分机制。
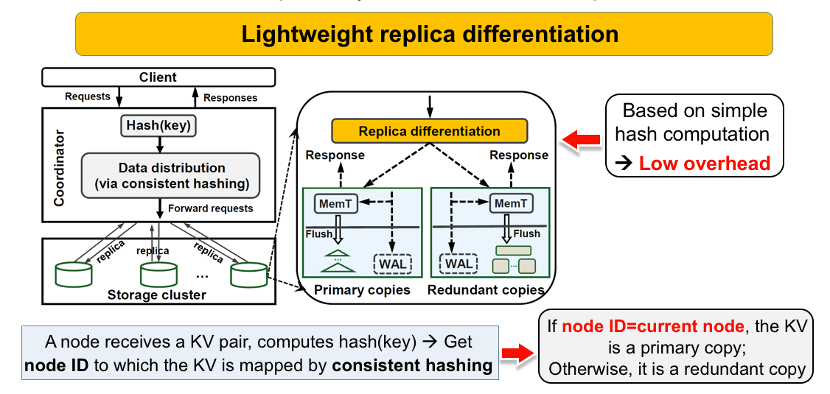
如图,当一个节点收到KV数据后,采用和Coordinator相同的步骤,首先计算Key的哈希值,然后根据一致性哈希数据分布机制,可以映射得到该KV划分到的节点ID。
如果计算得到的节点ID等于当前节点,那么就说明这个KV数据是通过一致性哈希机制映射到当前节点的,则该KV数据会被识别为主副本,并且存储在LSM-tree当中,否则这个KV数据就是通过复制策略从其他节点发送过来的冗余数据,则当前节点将其识别为冗余副本,并且存储在两层日志当中。
该解耦方案仅仅基于简单的哈希计算,因此是低开销的。此外,它在每个存储节点上独立执行,因此不会影响上层的数据分布机制以及一致性协议。
b. 挑战二:如何设计有序度可调的两层日志架构
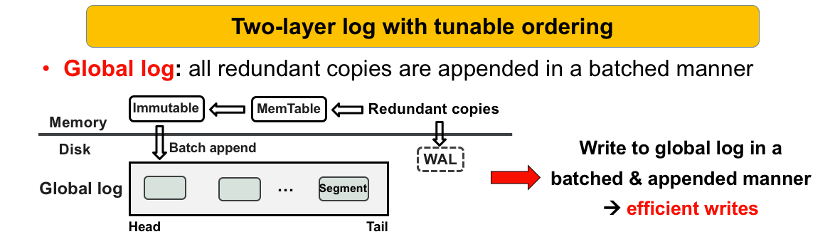
如上图,当节点收到冗余副本后,首先以批量追加的方式将冗余副本快速写入到全局日志中,形成一个segment文件,这里的segment文件类似于LSM-tree当中的SSTable文件,从而保证冗余副本可以高效的写入磁盘。
(2) 然后使用一个后台线程,将全局日志中的数据分割到不同的本地日志中,如下图。
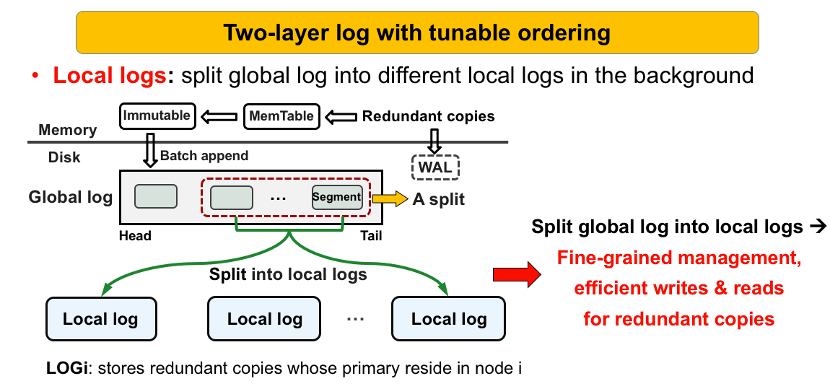
需要注意的是,每个本地日志用来存储一类冗余副本,他们所对应的主副本存储在相同的节点,比如这里本地日志LOGi,就用来存储对应主副本在节点i的这类冗余副本。
这样做的好处是可以实现细粒度的冗余副本管理,对于不同节点发送过来的冗余副本,使用不同的本地日志进行独立管理,从而可以保证高效的冗余副本读写性能,并且当恢复数据时,只需要读取相应的本地日志,避免了扫描所有的冗余副本,也可以提高数据恢复的效率。
(3) 其次,对于本地日志内部的数据管理也需要详细设计。
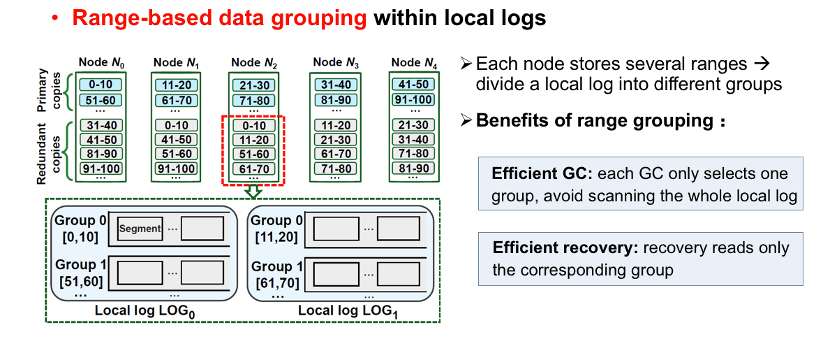
考虑到根据一致性哈希数据分布策略,每个节点会负责若干范围段的数据,基于该特征,进一步设计了基于范围的数据分组机制。
根据定义的范围段,将本地日志进一步划分成不同的独立组,不同组之间的数据没有重叠。比如节点2中的本地日志LOG0专门用来存储对应主副本在节点0上的冗余副本,又考虑到节点0中的主副本包含0-10、51-60等范围段,因此节点2中的本地日志LOG0被划分为Group 0[0-10]和Group 1[51-60]等若干组。
数据分组可以有效提高数据GC以及恢复性能,因为GC和数据恢复操作只需要读取相应的组即可,避免了扫描整个的本地日志。
(4) 对于每个组内的数据组织进行详细的设计。
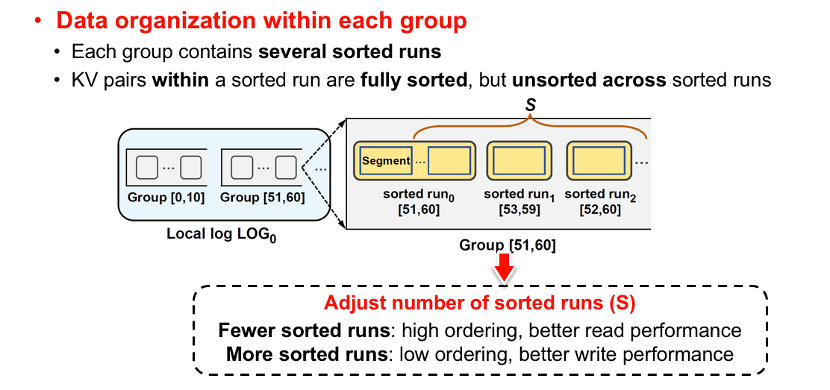
每个组会包含若干个sorted run文件,当分割全局日志时,每次分割操作都会在第2层的本地日志的组内产生一个sorted run文件,这些sorted run文件内部的KV数据是完全有序的,但sorted run文件之间的KV数据并未排序。因此,可以通过调整组内sorted run文件的个数来决定两层日志的有序度,从而在读写性能之间做权衡。
比如,当组内的sorted run文件个数越少,则两层日志的有序度越高,这时候读操作需要检查的sorted run的文件个数也就越少,因此读性能会越好,但需要执行更频繁的合并排序操作,从而导致写性能会越差;反之,两层日志的有序度越低,合并排序开销越少,则写性能会越好,但读操作需要检查的sorted run文件个数也就越多,导致读性能会越差。
(5)如何设置两层日志的有序度。
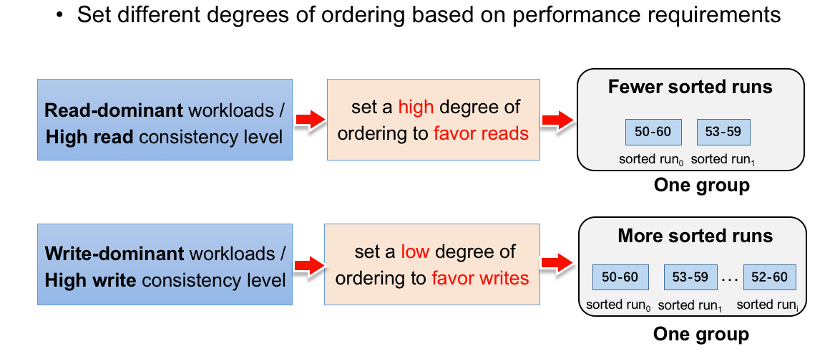
考虑到有序度会决定系统的读写性能,因此可根据上层应用的性能需求,来设置不同的有序度。
比如对于读密集型应用,或者系统配置为高的读一致性等级,则可以通过减少组内sorted run文件的个数来将两层日志设置为高有序度,以保证好的读性能;否则可以通过增加组内sorted run文件的个数,来将两层日志设置为低有序度,从而保证好的写性能。
c. 挑战三:副本解耦后如何加速数据恢复操作
副本解耦后,通过一种并行的恢复机制,以利用数据解耦存储的特征来加速数据恢复操作。
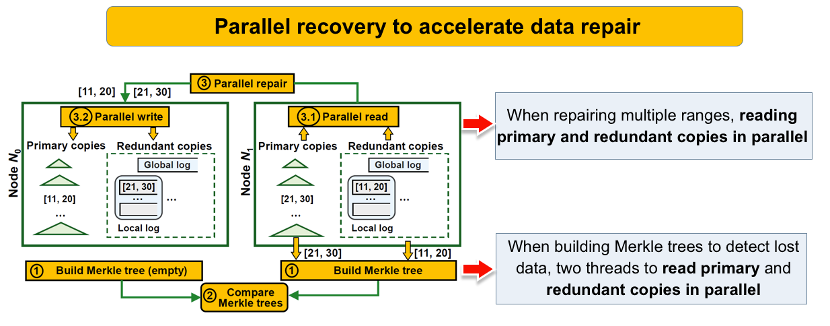
如图步骤①中,当为节点上的数据构建Merkle tree以检测丢失的数据时,使用两个线程,并行地从LSM-tree的主副本和两层日志的冗余副本中读数据。
3.实验
3.1 实验设置
 实验服务器硬件配置
实验服务器硬件配置● 在6个节点(5个存储节点,1个客户端节点)组成的本地集群中运行所有实验, 10 Gb/s以太网交换机;
● 工作负载:使用YCSB 0.15.0来生成工作负载,KV对大小为1KB,生成的工作负载服从Zipf分布 (0.99);
3.2 比较
● Cassandra v3.11.4 VS multiple LSM-trees (mLSM) VS DEPART
● DEPART builds on Cassandra v3.11.4
在开源的分布式KV存储系统Cassandra上实现了原型系统DEPART,同时也实现了多个LSM-tree的简单解耦方案。将DEPART与Cassandra、多个LSM-tree的解耦方案分别进行性能比较,以展示系统DEPART的设计优势。
实验一分别测试了不同KV系统的写、读、范围查询和更新操作的吞吐量。
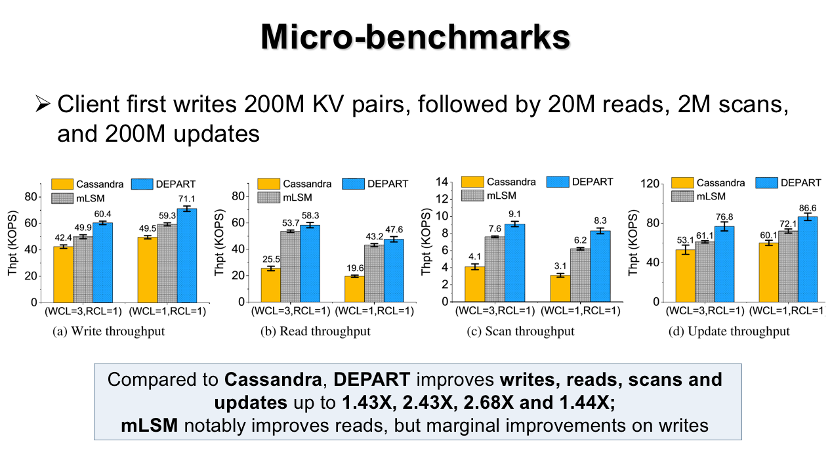
由实验结果可知,相比于Cassandra,系统DEPART可以显著提升所有操作的吞吐量。而对于多个LSM-tree的解耦方案,其可以较好地提升Cassandra的读性能,但对Cassandra的写性能提升非常有限。主要原因是多个LSM-tree的解耦方案会导致解耦出的每个LSM-tree仍然需要执行频繁的Compaction操作,以维护每层数据的完全有有序,从而导致总的Compaction开销仍然非常严重。
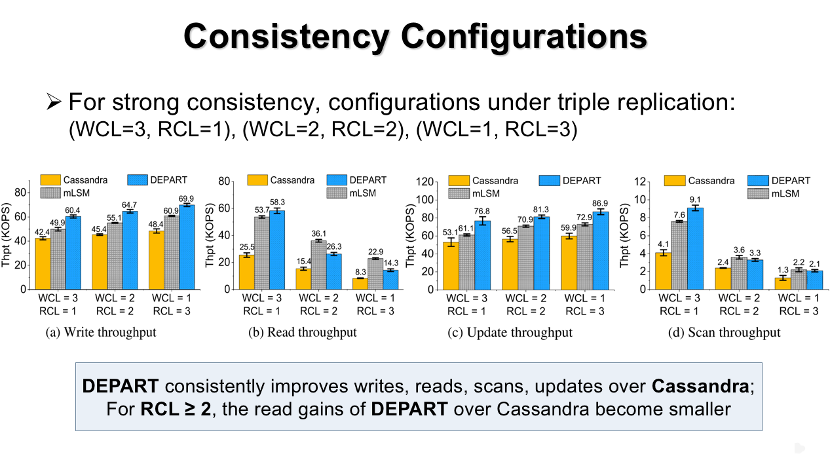
由实验结果可知,与Cassandra相比。系统DEPART可以在不同一致性配置下均可以提高所有操作的吞吐量,并且相比于多个LSM-tree的解耦方案,DEPART可以有效提高写入和更新操作的吞吐量。
然而,当读一致性等级(RCL)配置为大于1时,与Cassandra相比,DEPART的读性能收益会变小,并且DEPART的读性能还要略差于多个LSM-tree的解耦方案。其主要原因是,在这种读一致性配置下,每个读请求需要成功访问至少两个副本,因此必须搜索两层日志当中的冗余副本;又由于两层日志中的冗余副本并未完全排序,因此读取两层日志的性能要低于读取完全排序的LSM-tree的主副本。
注意,DEPART的读性能仍然要好于Cassandra,因为副本解耦后,DEPART搜索的数据量更少,但是DEPART的读性能要差于多个LSM-tree,因为多个LSM-tree保持冗余副本完全有序。
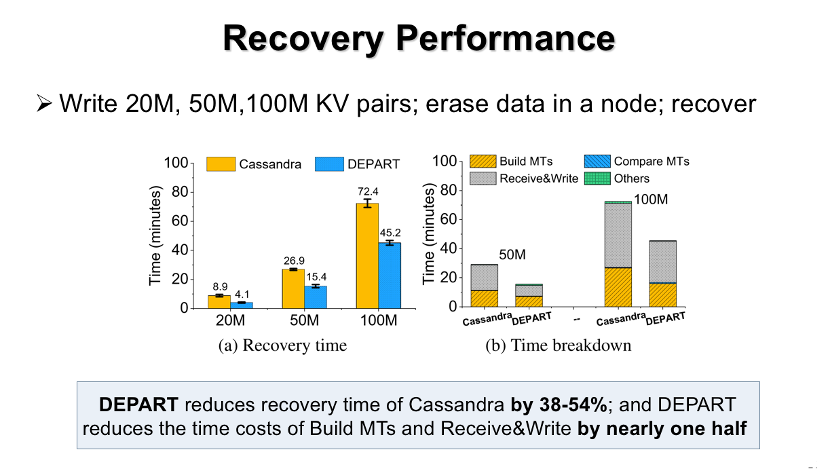
实验三:数据恢复性能
分别测试当恢复不同数据量时所需要的时间。
实验四:有序度参数S对系统读写性能的影响
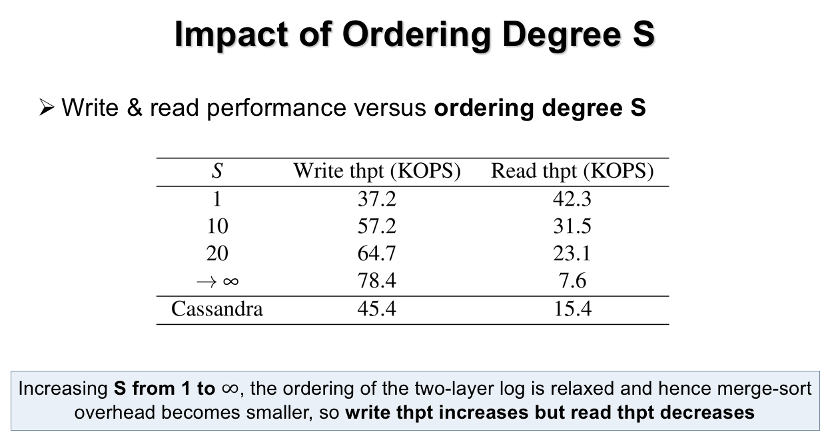
如表格所示,当S的值为1时,两层日志会变为两层LSM-tree,KV数据是完全有序的,因此它可以获得最高的读吞吐量。但由于频繁的合并排序操作,这时候写吞吐量是最低的。
当S的值从1不断增大时,两层日志的有序度会不断降低,故合并排序开销逐渐减小,因此写性能会不断增加,而读性能会不断降低。
4.总结
更多详细的结果和分析见论文,源码地址:https://github.com/ustcadsl/depart
KV研究热点总结与展望
首先,目前KV领域的绝大部分工作都集中在优化KV存储引擎上,例如改进LSM-tree架构,以减轻读写放大问题,以及结合新型硬件来重新设计KV存储引擎等等。
但在KV系统的数据容错层,相关研究极少,我们进行了初步探索,观察到当前统一的多副本管理会极大加剧KV系统的读写放大,因此研究设计了基于副本解耦的多副本差异化管理框架,极大提升了系统性能。这项工作基于Cassandra开源平台实现,并可以应用在TiKV等一系列基于LSM-tree的分布式KV存储系统中。
对于KV系统未来的研究方向,可以结合应用层的需求和缓存特征来进行特定的KV系统设计。例如,研究设计一种属性感知的内存KV系统,使其在存储结构上能够支持对数据属性值的高效读写,最终部署到云存储平台,以高效支撑SQL数据库等应用。此外也可以结合上层应用的其他特征和需求来设计针对性的KV存储系统。

# 抽奖TIME #
「阿里云瑶池数据库」送福利啦!





定制款通勤双肩包
定制款旅行睡眠套装
限量版T恤
定制保温杯
数据线
精美礼品限量放送~
即可参与抽奖
开奖时间:3月3日中午12点
👇👇👇




 点击「阅读原文」查阅论文原文
点击「阅读原文」查阅论文原文
