




前两期中,我们为大家展示了如何用 Window Join、Asof Join 引擎将逐笔成交数据与快照数据进行关联分析,以及使用 Left Semi Join 补充原始委托信息,这些都是金融中常见的应用场景,感兴趣的小伙伴可以点击下方跳转阅读。


Equal Join
不同数据源的
分钟指标实时合并
// create tableshare streamTable(1:0, `Sym`TradeTime`Side`TradeQty, [SYMBOL, TIME, INT, LONG]) as tradesshare streamTable(1:0, `UpdateTime`Sym`BuyTradeQty`SellTradeQty, [TIME, SYMBOL, LONG, LONG]) as tradesMinshare streamTable(1:0, `Sym`Time`Bid1Price`Bid1Qty, [SYMBOL, TIME, DOUBLE, LONG]) as snapshotshare streamTable(1:0, `UpdateTime`Sym`AvgBid1Amt, [TIME, SYMBOL, DOUBLE]) as snapshotMinshare streamTable(1:0, `UpdateTime`Sym`AvgBid1Amt`BuyTradeQty`SellTradeQty, [TIME, SYMBOL, DOUBLE, LONG, LONG]) as output// create engine:eqJoinEngine = createEqualJoinEngine(name="EqualJoin", leftTable=tradesMin, rightTable=snapshotMin, outputTable=output, metrics=<[AvgBid1Amt, BuyTradeQty, SellTradeQty]>, matchingColumn=`Sym, timeColumn=`UpdateTime)// create engine:tsEngine1 = createTimeSeriesEngine(name="tradesAggr", windowSize=60000, step=60000, metrics=<[sum(iif(Side==1, 0, TradeQty)), sum(iif(Side==2, 0, TradeQty))]>, dummyTable=trades, outputTable=getLeftStream(eqJoinEngine), timeColumn=`TradeTime, keyColumn=`Sym, useSystemTime=false, fill=(0, 0))// create engine:tsEngine2 = createTimeSeriesEngine(name="snapshotAggr", windowSize=60000, step=60000, metrics=<[avg(iif(Bid1Price!=NULL, Bid1Price*Bid1Qty, 0))]>, dummyTable=snapshot, outputTable=getRightStream(eqJoinEngine), timeColumn=`Time, keyColumn=`Sym, useSystemTime=false, fill=(0.0))// subscribe topicsubscribeTable(tableName="trades", actionName="minAggr", handler=tsEngine1, msgAsTable=true, offset=-1, hash=1)subscribeTable(tableName="snapshot", actionName="minAggr", handler=tsEngine2, msgAsTable=true, offset=-1, hash=2)
首先用两个独立的时序聚合引擎(createTimeSeriesEngine)对原始的快照和成交数据流按数据中的时间戳做实时聚合,输出每一分钟的指标;然后通过引擎级联的方式,将两个时序聚合引擎的输出分别作为左右表注入连接引擎。
// generate data: snapshott1 = table(`A`B`A`B`A`B as Sym, 10:00:52.000+(3 3 6 6 9 9)*1000 as Time, (3.5 7.6 3.6 7.6 3.6 7.6) as Bid1Price, (1000 2000 500 1500 400 1800) as Bid1Qty)// generate data: tradet2 = table(`A`A`B`A`B`B`A`B`B`A as Sym, 10:00:54.000+(1..10)*700 as TradeTime, (1 2 1 1 1 1 2 1 2 2) as Side, (1..10) * 10 as TradeQty)// inputtrades.append!(t2)snapshot.append!(t1)
关联得到的结果表 output 如下:

Lookup Join
根据快照数据
实时匹配历史日频指标
// create tableshare streamTable(1:0, `Sym`Time`Open`High`Low`Close, [SYMBOL, TIME, DOUBLE, DOUBLE, DOUBLE, DOUBLE]) as snapshothistoricalData = table(`A`B as Sym, (0.8 0.2) as PreWeight, (3.1 7.6) as PreClose)share table(1:0, `Sym`Time`Open`High`Low`Close`PreWeight`PreClose, [SYMBOL, TIME, DOUBLE, DOUBLE, DOUBLE, DOUBLE, DOUBLE, DOUBLE]) as output// create enginelookupJoinEngine = createLookupJoinEngine(name="lookupJoin", leftTable=snapshot, rightTable=historicalData, outputTable=output, metrics=<[Time, Open, High, Low, Close, PreWeight, PreClose]>, matchingColumn=`Sym, checkTimes=10s)// subscribe topicsubscribeTable(tableName="snapshot", actionName="appendLeftStream", handler=getLeftStream(lookupJoinEngine), msgAsTable=true, offset=-1)
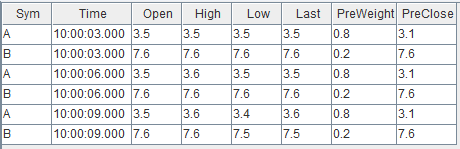
构造数据写入作为引擎左表输入的流数据表 snapshot:
// generate data: snapshott1 = table(`A`B`A`B`A`B as Sym, 10:00:00.000+(3 3 6 6 9 9)*1000 as Time, (3.5 7.6 3.5 7.6 3.5 7.6) as Open, (3.5 7.6 3.6 7.6 3.6 7.6) as High, (3.5 7.6 3.5 7.6 3.4 7.5) as Low, (3.5 7.6 3.5 7.6 3.6 7.5) as Close)snapshot.append!(t1)
输入数据与关联关系如下:

结果在左表数据到达引擎时立刻输出,关联得到的结果表 output 如下:
Left Semi Join
实时计算股票与某指数的
分钟收益率相关性
// create tableshare streamTable(1:0, `Sym`Time`Close, [SYMBOL, TIME, DOUBLE]) as stockKlineshare streamTable(1:0, `Sym`Time`Close, [SYMBOL, TIME, DOUBLE]) as indexKlineshare streamTable(1:0, `Time`Sym`Close`Index1Close, [TIME, SYMBOL, DOUBLE, DOUBLE]) as stockKlineAddIndex1share streamTable(1:0, `Sym`Time`Close`Index1Close`Index1Corr, [SYMBOL, TIME, DOUBLE, DOUBLE, DOUBLE]) as output// create engine: calculate correlationrsEngine = createReactiveStateEngine(name="calCorr", dummyTable=stockKlineAddIndex1, outputTable=output, metrics=[<Time>, <Close>, <Index1Close>, <mcorr(ratios(Close)-1, ratios(Index1Close)-1, 3)>], keyColumn="Sym")// create engine: left join Index1ljEngine1 = createLeftSemiJoinEngine(name="leftJoinIndex1", leftTable=stockKline, rightTable=indexKline, outputTable=getStreamEngine("calCorr"), metrics=<[Sym, Close, indexKline.Close]>, matchingColumn=`Time)// subscribe topicdef appendIndex(engineName, indexName, msg){tmp = select * from msg where Sym = indexNamegetRightStream(getStreamEngine(engineName)).append!(tmp)}subscribeTable(tableName="indexKline", actionName="appendIndex1", handler=appendIndex{"leftJoinIndex1", "idx1"}, msgAsTable=true, offset=-1, hash=1)subscribeTable(tableName="stockKline", actionName="appendStock", handler=getLeftStream(ljEngine1), msgAsTable=true, offset=-1, hash=0)
这里连接引擎的输出会直接注入响应式状态引擎进行下一步计算,多个引擎之间采用了引擎级联的方式处理。
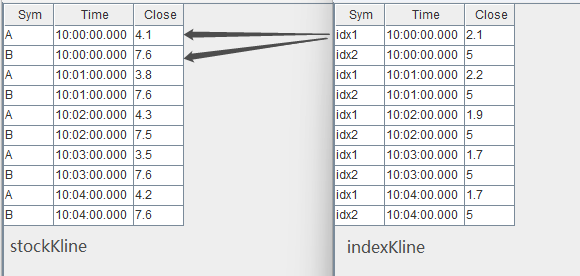
// generate data: stock Klinet1 = table(`A`B`A`B`A`B`A`B`A`B as Sym, 10:00:00.000+(0 0 1 1 2 2 3 3 4 4)*60000 as Time, (4.1 7.6 3.8 7.6 4.3 7.5 3.5 7.6 4.2 7.6) as Close)// generate data: index Klinet2 = table(`idx1`idx2`idx1`idx2`idx1`idx2`idx1`idx2`idx1`idx2 as Sym, 10:00:00.000+(0 0 1 1 2 2 3 3 4 4)*60000 as Time, (2.1 5 2.2 5 1.9 5 1.7 5 1.7 5) as Close)// input dataindexKline.append!(t2)stockKline.append!(t1)
输入数据与关联关系如下:
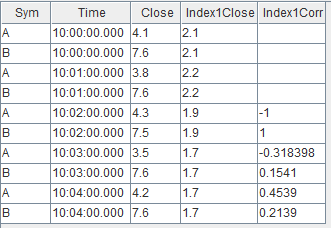
关联得到的结果表 output 如下:

💡大家还有哪些关心的话题,
💡或想了解的解决方案呢?
Explore More




文章转载自DolphinDB智臾科技,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
