本文不局限于对某一篇论文的详细介绍,而是通过对一系列工作的概括性叙述,帮助读者从直观上对知识图谱质量控制领域有一个大体的了解。数据的数量和质量宛如一枚硬币的两面,对数据管理同样重要。随着以4v 为特征的大数据时代的到来,人们往往更关注数据的数量,集中于对高速变化的海量异构数据的处理和分析,例如从异构数据中构建知识库、提升从海量数据中进行查询优化的算法等,对数据质量的研究并没有那么重视。但是,现实世界的数据往往是脏的,会存在不一致、不准确、不完整、过时、重复等问题。如果不能对数据质量进行合理的评估,并针对发现的问题进行改进和修复,无论怎样优化数据处理和查询算法,都不能得到准确的答案和对获取的数据实现有效利用。数据质量研究在大数据时代相当重要。
传统关系数据常用的一种质量控制方法是函数依赖(对于关系模式R(U)的任意两个可能的关系r1、r2,若r1[x]=r2[x],则r1[y]=r2[y])及其变体,而知识图谱由于其无模式性,更难利用有效的规则进行质量控制。近年来知识图谱的构建技术方兴未艾,但其质量问题并没有得到很好的重视。

评估数据质量需要确定一组质量维度和相应的度量方式,但是对知识图谱的质量尚未形成一套统一的维度标准,并且针对不同的下游任务和不同的数据集往往会有不同的质量要求。对数据质量评估的一个宽泛定义是“fit for use”,即只要适用于具体任务即可;而从技术上理解,可以从“free of defects”的角度,即机器找不出错误。虽然不同的工作给出了不同的质量维度,但是除去用户交互和表征等外部维度,数据本身的质量维度大致可以归纳为准确性、一致性、完整性、时效性、重复性五类。并且可以明确的是,不同质量维度之间往往存在相关性,在实际使用时需要权衡。
下面两图给出了两套质量维度框架,更多内容可以参考[1][2]。
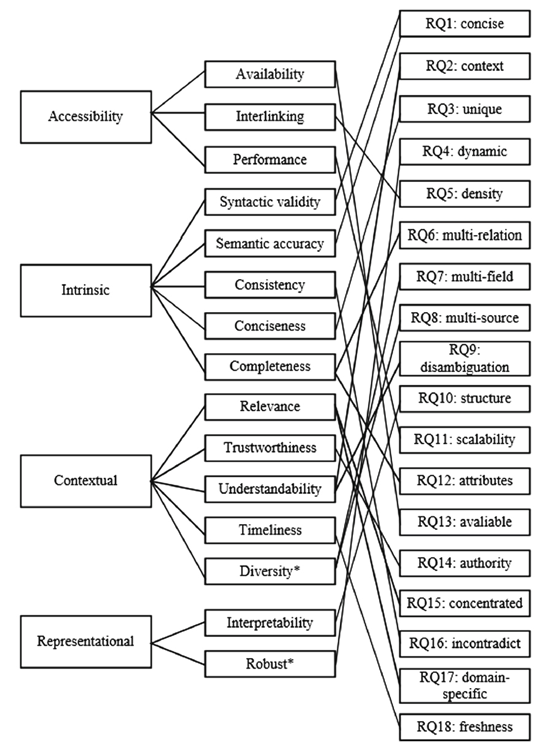
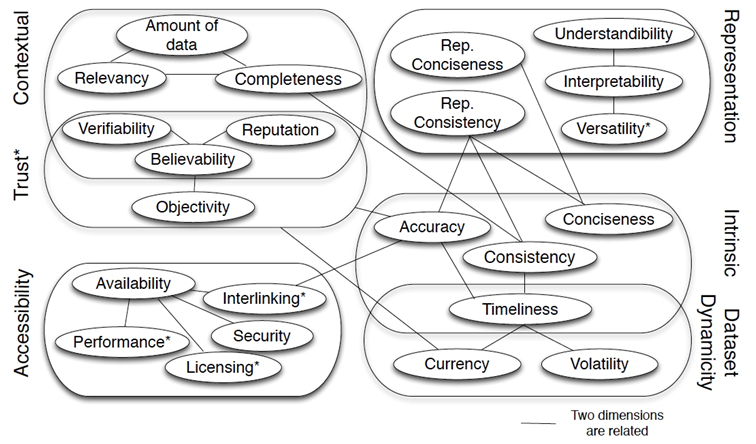
从整体上,知识图谱质量研究的主要工作包括质量评估、问题发现和质量提升三类,从方法上可以分为基于统计、人工和规则推理三种。下面主要对基于人工抽样进行质量评估和基于规则的质量控制框架展开叙述。

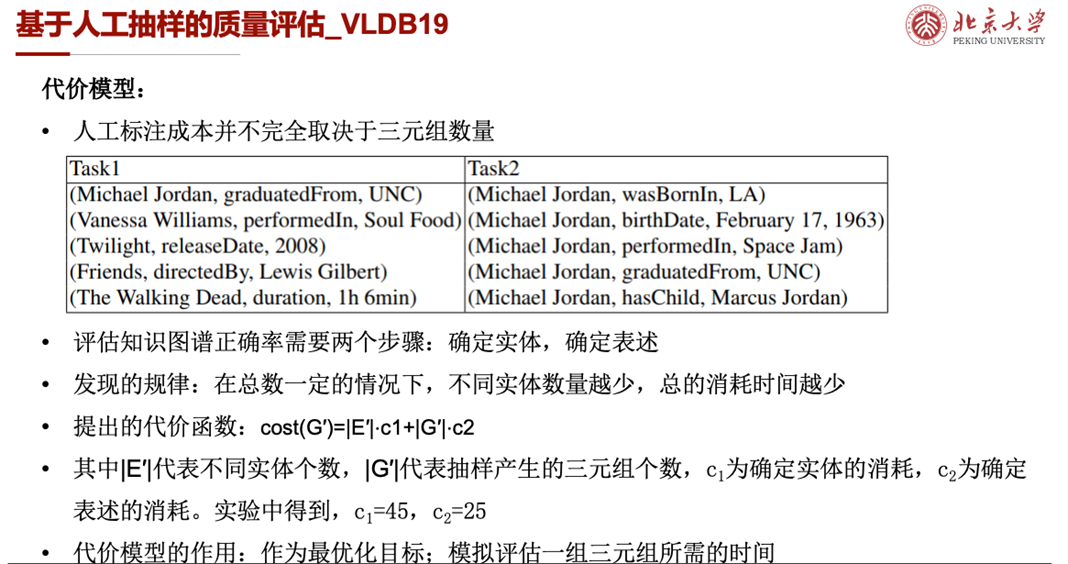
这里介绍一篇2019年VLDB的工作[3],它对使用人工抽样进行知识图谱质量评估的研究很有代表性。评估知识图谱的准确率,即正确的三元组所占的比例,最自然的方式是人工检测。但对于大规模知识图谱,人工检测所有条目并不现实,这就需要进行抽样,用样本的准确率均值来估计总体的准确率。但抽样数量过少,可能会使估计结果与真实值之间存在偏差,这就存在一个怎么抽样和抽样多少的问题,即怎么在尽可能降低人工标注成本的情况下获得具有统计意义的结果。这篇文章提出了一个迭代的评估框架,每次抽取小批量样本进行人工评估,当误差率满足要求时迭代停止;提出了若干种抽样方法,以及增量评估的两种抽样方法;进行了详实的理论分析和大量的实验验证,是第一个在静态和动态图上进行高效质量评估并可得到无偏和有效置信度的质量估计的工作。本文所要保证的统计意义,包括无偏性和置信区间两个。前者保证估计量的数值在真实值附近摆动,且无系统误差;后者衡量了在给定置信度的情况下,参数真实值落在测量结果周围的程度。因为知识图谱正确率的评估需要包括确定实体和确定表述两个步骤,作者在实践中发现标注成本并不完全取决于待标注三元组数量,还与需要标注的实体数量有关:在总数一定的情况下,不同实体的数量越少,总的消耗时间越少。因而提出cost(G′)=|E′|⋅c1+|G′|⋅c2作为代价函数,并在后续实验中得到c1=45,c2=25。这个代价模型不仅可以作为任务的优化目标,还可以用来模拟评估一组三元组所需的时间。进而作者把任务建模成一个最优化问题,目标是最小化标注代价,约束条件是两个统计意义,即无偏估计和置信区间长度界限。对于静态知识图谱的评估,作者提出了简单随机抽样、聚类抽样、两阶段加权聚类抽样、分层抽样等五种抽样方式,并对它们的统计特征进行了详实的理论分析。以简单随机抽样为例,我们可以看到,使用这种方式抽样,可以保证无偏性,即样本准确率均值的期望与真实的知识图谱准确率相等。并且在对代价分析的过程中,可以得到理论的采样数量与知识图谱大小无关、而只与图谱的准确率有关的结论。这一结论说明理论采样数量并不会随着知识图谱规模的扩张而无限增大,这表明了采样在实际应用中的可行性。需要注意的是,这个理论采样数量并不是实际中一次性采样的数量,因为公式中的μ是未知的。这个公式的意义在于,在迭代过程中,可以通过判断采样数量是否达到了理论最小采样数量,来确定迭代是否可以停止。除了对静态知识图谱进行抽样的五种方法,针对图谱动态变化的任务,作者还提出了两种增量抽样评估方式,希望能够尽可能多的利用已标注样本得到对新图谱的准确率度量。第一种方法借鉴了经典水塘抽样的思路,将增量batch中每个实体的所有元组视为整体,根据三元组个数进行加权,计算key值确定选取的样本,并通过理论分析确定新抽取的样本数量不会太多。第二种是分层增量评估,将图谱的增量视为一个单独的层,在其上使用两阶段加权抽样后与之前若干层的结果加权,直到置信区间小于阈值。这种方法的优点在于完全利用了前面所有的评估结果,因而效率更高。除了抽样方法的介绍和理论的分析,作者还在真实数据集上做了大量实验验证。在同样的准确率要求下,比较不同采样方法的标注代价,并验证了数据集、置信度、置信区间阈值、采样数、图谱大小和簇分布等第三变量的影响。更多内容可以查看原文[3].这篇文章将对知识图谱准确率的抽样评估引入统计学框架,使得不仅能估计kg的准确率,还对抽样应该何时停止有了明确界限,并且使得结果更加可信。理论分析和实验验证部分都很完备,是一篇很有价值的文章。但与此同时,在抽样粒度、人工评测等部分还有很多可以深入研究的点。
前述的基于人工抽样的方法,可以用来评估知识图谱的质量,但是难以有效实现错误检测和纠正。而基于规则的方法,则可以将质量评估、问题发现和问题修复三大任务置于统一的框架中实现。
规则的形式不唯一,有sparql规则、形式逻辑、图函数依赖等,选用规则时需要考虑在复杂性和表达能力之间寻求平衡。规则的研究框架主要包括规则的发现、规则集的验证、使用规则进行错误探查和进行错误修复四个步骤。
这里主要介绍爱丁堡大学Wenfei Fan院士团队所做的图函数依赖[5-10]和莱比锡大学aksw团队的一系列开源工具[11-14],前者注重理论分析和并行算法研究,后者更注重实际使用。
(1)图函数依赖
依赖是关系数据库研究的经典问题,例如函数依赖,可以帮助进行数据库模式设计、查询优化和数据清洗等,是进行数据质量控制的重要方法。图函数依赖作为一种指定数据完整性和语义约束的方法,可用于一致性检查、kb扩充、欺诈检测等任务中,但是其研究尚处于起步阶段。
[5,6,7]参照关系数据的依赖定义及其变体,给出了图函数依赖的定义及其扩展形式。图函数依赖包含了由图模式Q施加的拓扑约束和由属性依赖(X ⇒ Y)施加的属性约束,与关系数据的函数依赖相比,具有更强的表达能力和更高的复杂度。

参照关系函数依赖的研究范式,作者对图函数依赖的推理进行了详尽的理论分析,给出了可满足性、蕴含问题、验证问题三个经典推理问题的复杂性,并且参照Armstrong公理系统给出了一套6个正确且完备的图函数依赖推理规则,将图函数依赖的研究迈出了扎实的一步。
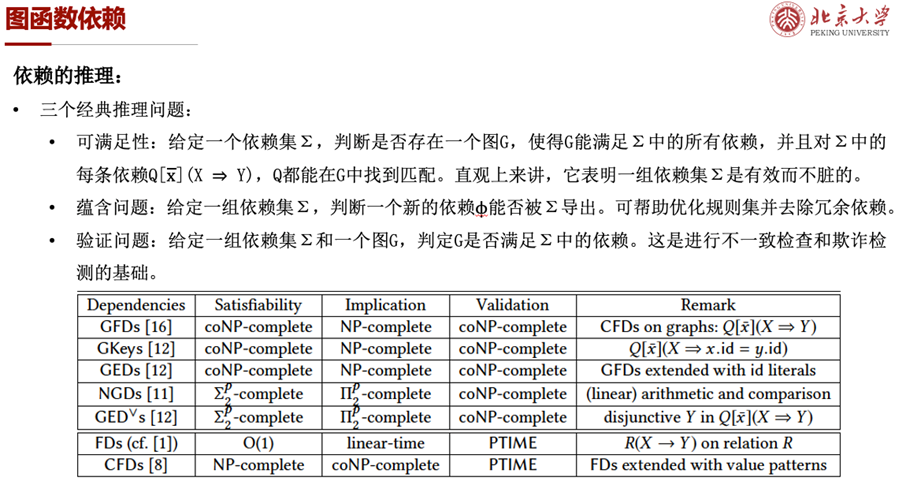

对于图函数依赖的实际应用,作者对依赖的发现和使用依赖进行错误检测进行了一些并行可扩展算法的初步研究[6,8,10]。而对于利用依赖进行错误修复的问题,因为其复杂度较高,还未得以实现。
图函数依赖的系列工作大致开始于2015年,尚处于起步阶段。Wenfei Fan院士团队参照关系数据上的依赖定义给出了图函数依赖的定义及其扩展,对依赖的推理进行了扎实的理论研究,并对实际应用的算法进行了一些并行可扩展的尝试。未来,在更多行之有效的并行和近似算法、人机结合的规则发现等领域还有待更多的工作推进。

(2)aksw团队的检错系统
德国aksw团队(官网:https://aksw.org)致力于语义网的方法、技术和工具,有大量优秀的开源项目,其中也包括DBpedia等超高影响力的项目的开发和维护。这里主要介绍其在知识图谱质量控制方面的几个代表性工作,从人工检错[11],到利用规则检错[12],再到规则的学习和生成[13]。
第一个项目是TripleCheckMate[11](官网:http://aksw.org/Projects/TripleCheckMate.html),它专门针对DBpedia进行错误发现和质量评估。在正式开始前,专家检测常见的质量问题并制定了一套错误分类,然后使用手动和半自动的方式进行质量评估。手动方式提供了用户界面,允许用户选择感兴趣的内容并评估单个资源的正确性,半自动的方式则通过自动生成规则[14]+人工验证规则的方式进行。
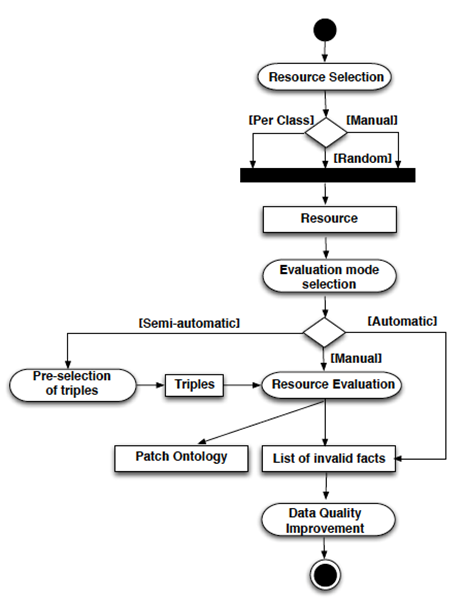
文章还给出了一个通用的质量控制框架,包括资源选择、评估模式选择、资源评估和数据质量提升四个步骤,见下图。
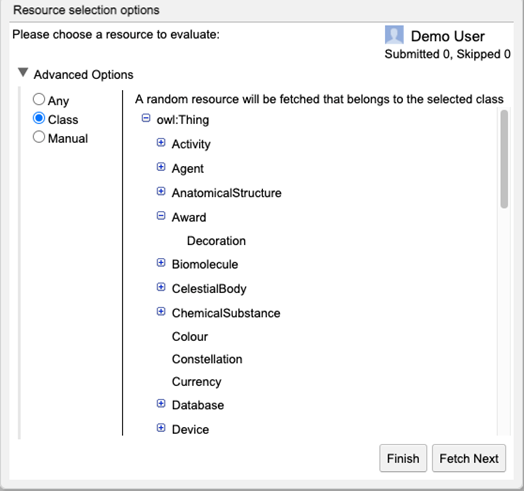
下面几张图给出了用户评估界面的展示,大体流程是用户选择要评估的数据类型,然后每个页面呈现一个实体及其待标注三元组,用户对每条数据进行判断并选择错误类型,还可以写下错误原因和修复建议。读者可以查看演示视频(http://www.youtube.com/watch?v=l-StthTvjFI)和系统demo(http://nl.dbpedia.org:8080/TripleCheckMate-Demo/)进行深入尝试。
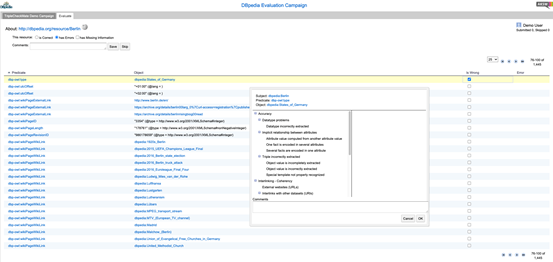
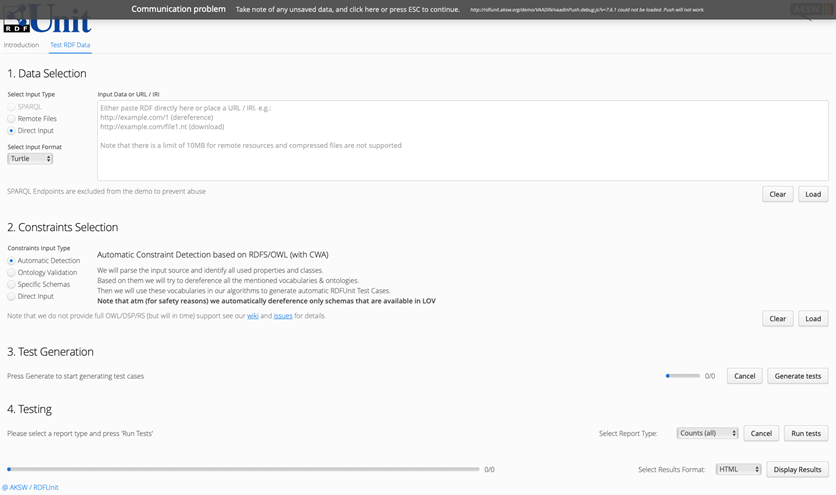
第二个工作是RDFUnit[12],相关文章发表于WWW14。它给出了基于测试驱动的数据质量评估框架,使用一套sparql查询作为规则以发现数据中的问题。其中规则主要来源于用户标注和已存在的schema,因而包含了本体转换、本体扩充、用户手动编写等五种规则构造方式。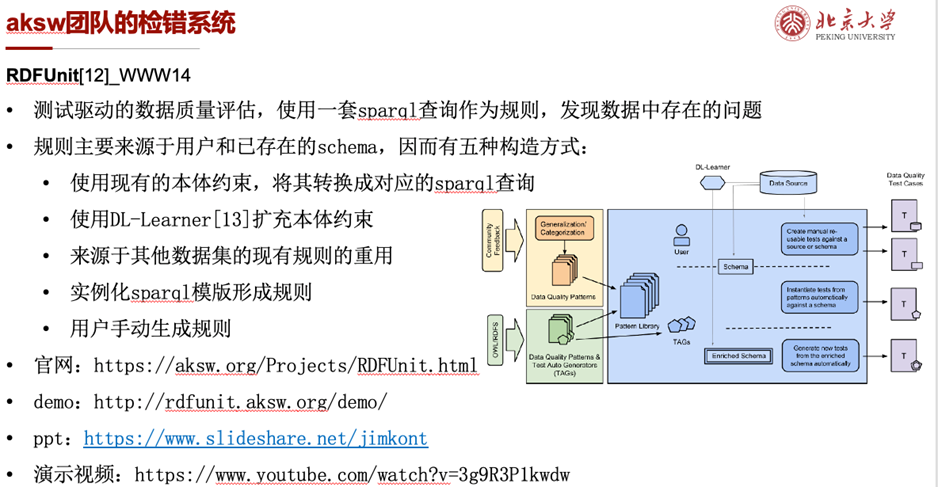
它通过对dbpedia的错误分析,构造了一组17个sparql规则模版,基本上能涵盖知识图谱中可能存在的各种数据错误;并使用LOV的词汇表实例化规则模版,生成了一套包含297个谓词32293个规则的规则库并开源。通过实验验证,其规则能够有效发现真实KB中存在的问题。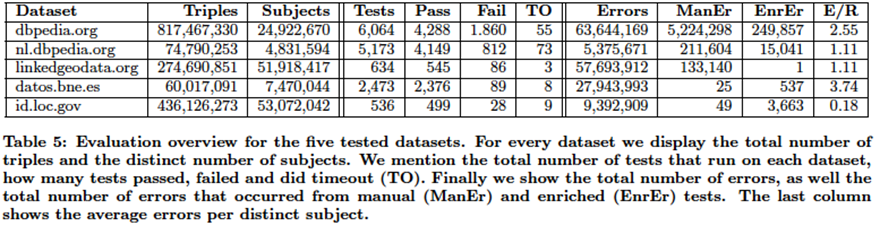

项目还形成了一个开源系统并持续开发中,操作流程主要包括导入数据、约束选择、规则生成和进行验证四个步骤。整体操作很方便,界面也很流畅,但在规则生成部分主要还是基于schema约束的转换以及现有规则库的重用,还有待进一步完善。
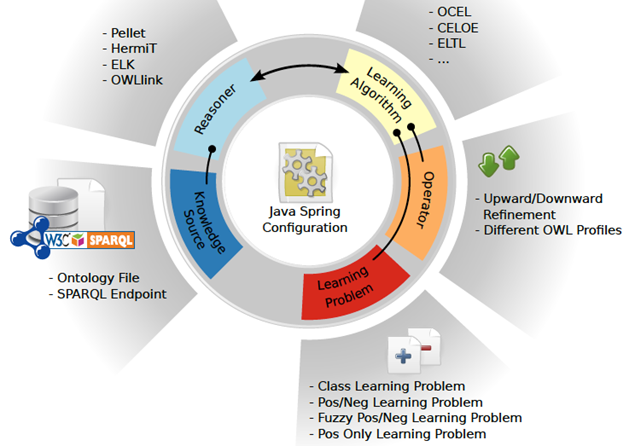
第三个工作是DL-Learner[13,14],它是一个基于owl/描述逻辑的机器学习工具,目前主要解决监督学习任务,帮助构建知识并学习数据。它致力于从正负样本中发现一个owl类表达式,使其能够对新样本进行正确分类,可以用作本体扩充进而发现kb中的错误。该系统集成了许多不同的学习任务和学习算法,并且被集成进protégé、ORE等其他工具中。
从这一条研究体系中可以看到,知识图谱的质量提升任务框架里,首先是资源选择和错误发现,其中错误发现可以采用手动、半自动或自动的方式。其中手动方式主要涉及任务设计和用户参与,但对大规模图谱并不十分适用;半自动方式涉及规则的自动发现和人工验证,但现有工作主要是串行的,怎么将两者结合还没有得到很好的研究;全自动方法由于完全脱离人的校正,准确率和可信度还有待提高。而错误纠正的工作,因为其复杂性还没能得到很好的研究(虽然有很多kb refinement的工作[15]致力于对kb进行补全和纠错,但其大多都依赖于外部资源并且不具备通用性)。
而无论是何种形式的知识图谱质量规则,本质上都可以看作一种描述逻辑形式的分类器,可以参考机器学习的方式生成;另一方面,它的高度可理解性,又给人的深度参与带来了更多的可能性。因而可以以知识图谱质量规则为契机,研究规则系统、机器学习与人三者之间的交互。

本文通过对知识图谱质量控制方面一系列工作的概述,希望帮助读者对这一领域有更多的了解和认识,并激起更多探索的兴趣和想法。
参考文献
[1] Amrapali Zaveri,Anisa Rula, Andrea Maurino, Ricardo Pietrobon, Jens Lehmann andSören Auer: Quality Assessment forLinked Open Data: A Survey. Semantic Web, vol.7, no.1, pp. 63-93, 2016[2] 樊文飞,吉尔茨 (Geerts, F.),刘瑞虹: 数据质量管理基础,国防工业出版社,2016[3] Junyang Gao, Xian Li, Yifan EthanXu, Bunyamin Sisman, Xin Luna Dong, Jun Yang:Efficient Knowledge Graph Accuracy Evaluation. Proc.VLDB Endow. 12(11): 1679-1691 (2019)[4] https://www.cnblogs.com/zzk0/p/13415027.html[5] Wenfei Fan: Dependencies for Graphs: Challenges andOpportunities. ACM J. Data Inf. Qual. 11(2): 5:1-5:12 (2019)[6] Wenfei Fan, Yinghui Wu, Jingbo Xu: FunctionalDependencies for Graphs. SIGMOD Conference 2016: 1843-1857[7] Wenfei Fan, Ping Lu: Dependencies for Graphs. PODS2017: 403-416[8] Wenfei Fan, Chunming Hu, Xueli Liu, Ping Lu:Discovering Graph Functional Dependencies. SIGMOD Conference 2018: 427-439[9] Wenfei Fan: Data Quality: From Theory to Practice.SIGMOD Rec. 44(3): 7-18 (2015)[10] Wenfei Fan, Xueli Liu, Ping Lu, Chao Tian: CatchingNumeric Inconsistencies in Graphs. SIGMOD Conference 2018: 381-393[11] Amrapali Zaveri, Dimitris Kontokostas, Mohamed AhmedSherif, Lorenz Bühmann, MohamedMorsey, Sören Auer, Jens Lehmann: User-driven quality evaluation of DBpedia.I-SEMANTICS 2013:97-104[12] Dimitris Kontokostas, Patrick Westphal, Sören Auer,Sebastian Hellmann, Jens Lehmann, Roland Cornelissen, AmrapaliZaveri:Test-driven evaluation of linked data quality. WWW 2014: 747-758[13] Lorenz Bühmann,Jens Lehmann, Patrick Westphal: DL-Learner - A framework for inductive learningon the Semantic Web. J. Web Semant. 39: 15-24 (2016)[14] Lorenz Bühmann, JensLehmann: Universal OWL Axiom Enrichment for Large Knowledge Bases.EKAW 2012: 57-71[15] Heiko Paulheim: Knowledge graph refinement: A surveyof approaches and evaluation methods. Semantic Web 8(3): 489-508 (2017) 相 关 链 接
相 关 链 接