




点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!
1. percona-toolkit介绍
2. percona-toolkit软件安装
yum install perl-DBI perl-DBD-MySQL
1. 工具介绍
2. 常用参数
常用参数 | 含义 |
--user | 用户 |
--password | 密码 |
--port | 端口 |
--host | 主机 |
--socket | 本地套接字 |
--match-command | 匹配状态 |
--match-info | 匹配信息 |
--match-state | 匹配声明 |
--ignore-host/--match-host | 匹配主机 |
--ignore-db/--match-db | 匹配数据库 |
--ignore-user/--match-user | 匹配用户 |
--kill | 杀掉连接并且退出 |
--kill-query | 只杀掉连接执行的语句,但是线程不会被终止 |
打印满足条件的语句 | |
--busy-time | SQL运行时间的线程 |
--idle-time | sleep时间的连接线程,必须在--match-command sleep时才有效 |
--interval | query的间隔 |
--victim | oldest|all|all-but-oldest 针对范围 |
--daemonize | 是否放到后台执行 |
--interval | 执行频率(s=seconds, m=minutes, h=hours, d=days) |
--log-dsn D=test,t=pk_log | 记录信息到表中 |
3. 应用案例
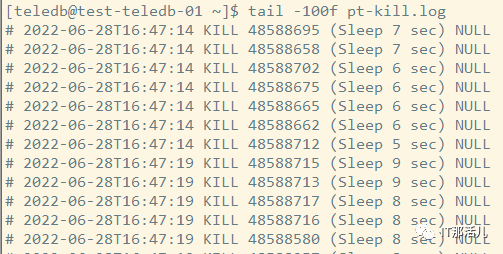
1)杀掉空闲链接sleep 5秒的 SQL 并打印日志
/usr/bin/pt-kill --user=test --password=test -S
/app/test/socket_3306/mysql_3306.sock --match-command Sleep
--idle-time 5 --victim all --interval 5 --kill --daemonize
--pid=/tmp/ptkill.pid --print --log=/app/teledb/pt-kill.log &

2)杀运行时间超过10s的SQL语句但保留线程,并打印日志
pt-kill --user=test --password=test -S
/app/test/socket_3306/mysql_3306.sock --busy-time=10 --
victims all --print --kill-query

3)查杀select大于20s的会话
pt-kill --user=test --password=test -S
/app/test/socket_3306/mysql_3306.sock--match-info
"select|Select|SELECT" --print --victims all --busy-time 20s

4)建议
如果要对生产数据库部署pt-kill工具,一定要与业务方沟通确认相关策略,并将查杀结果日志记录下来,定期推送kill掉的SQL给相关人员,避免影响正常生产SQL的执行。
1. 工具介绍
2. 常用参数
常用参数 | 含义 |
--create-review-table | 当使用--review参数把分析结果输出到表中时,如果没有表就自动创建 |
--create-history-table | 当使用--history参数把分析结果输出到表中时,如果没有表就自动创建 |
--filter | 对输入的慢查询按指定的字符串进行匹配过滤后再进行分析 |
--limit | 限制输出结果百分比或数量,默认值是20,即将最慢的20条语句输出 |
--host | mysql服务器地址 |
--user | mysql用户名 |
--password | mysql用户密码 |
--history | 将分析结果保存到表中,分析结果比较详细,下次再使用--history时,如果存在相同的语句,且查询所在的时间区间和历史表中的不同,则会记录到数据表中,可以通过查询同一CHECKSUM来比较某类型查询的历史变化 |
--review | 将分析结果保存到表中,这个分析只是对查询条件进行参数化,一个类型的查询一条记录,比较简单。当下次使用--review时,如果存在相同的语句分析,就不会记录到数据表中 |
--output | 分析结果输出类型,值可以是report(标准分析报告)、slowlog(Mysql slow log)、json、json-anon,一般使用report,以便于阅读 |
--since | 从什么时间开始分析,值为字符串,可以是指定的某个”yyyy-mm-dd (hh:mm:ss)”格式的时间点,也可以是简单的一个时间值:s(秒)、h(小时)、m(分钟)、d(天),如12h就表示从12小时前开始统计。 |
--until | 截止时间,配合—since可以分析一段时间内的慢查询 |
3. 应用案例
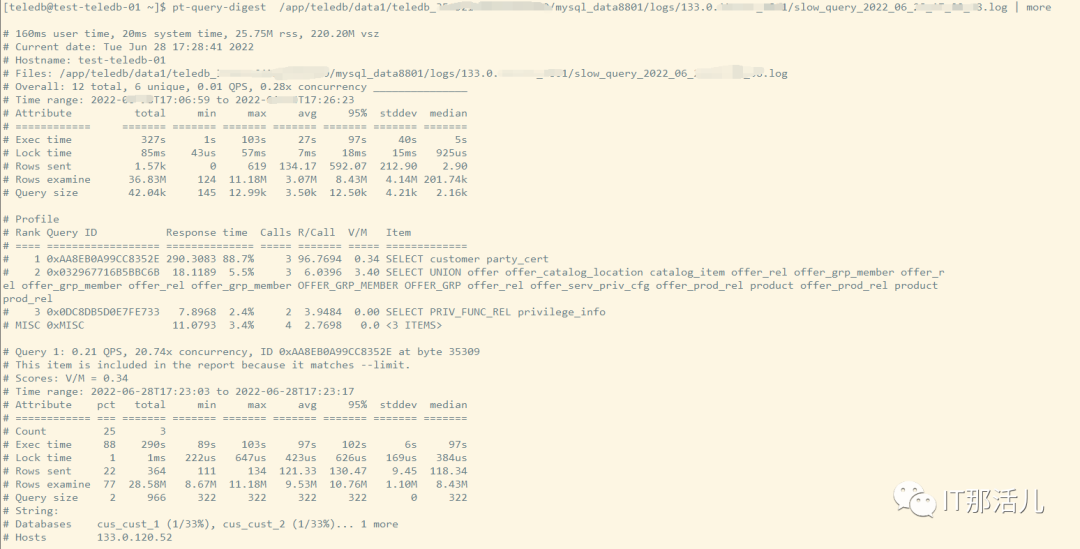
1)直接分析慢查询文件
pt-query-digest app/test/mysql/log/mysql-slow.log | more
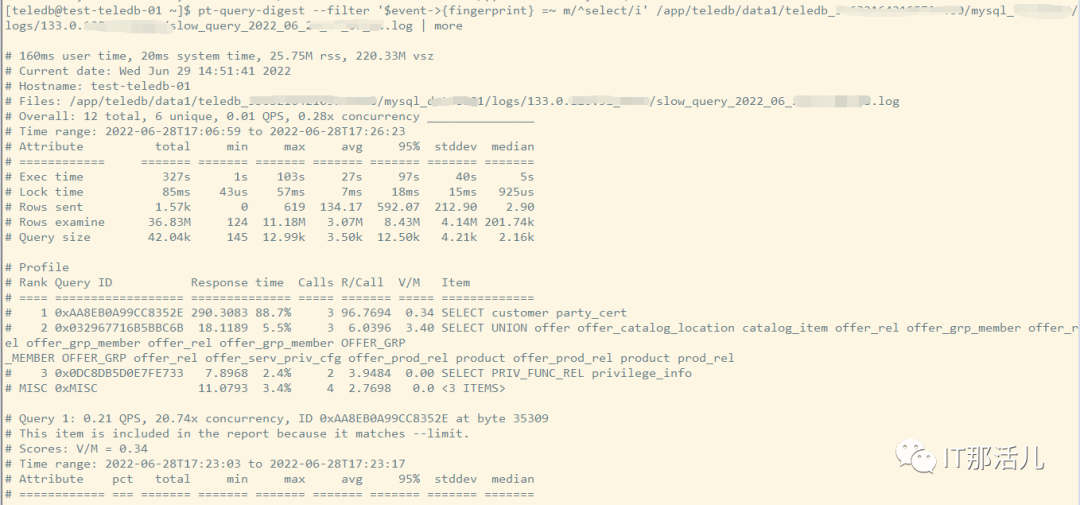
2)针对某个用户的慢查询
pt-query-digest --filter '($event->{user} || "") =~ m/^root/i' app/test/mysql/log/mysql-slow.log
4. 分析输出结果
第一部分:总体统计结果
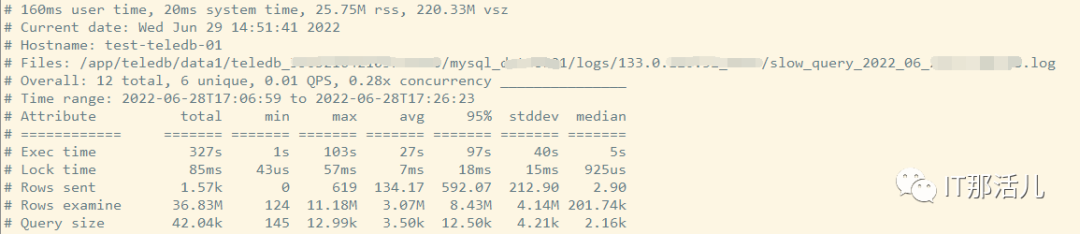
从左往右依次代表:



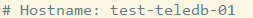

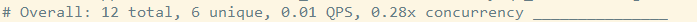
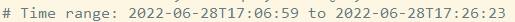
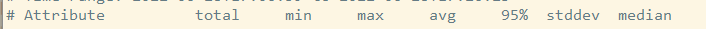


从上到下依次代表:
语句执行时间; 锁占用时间; 发送到客户端的行数; select语句扫描行数; 查询的字符数。
第二部分:查询分组统计结果

Rank:所有语句的排名,默认按查询时间降序排列 Query ID:sql ID; Response:总响应时间; time:该查询在本次分析中总的时间占比; calls:执行次数,即本次分析总共有多少条这种类型的查询语句; R/Call:平均每次执行的响应时间; V/M:响应时间Variance-to-mean的比率; Item:查询对象。
第三部分:每种查询的详细统计分析
由下面查询的详细统计结果,最上面的表格列出了执行次数、最大、最小、平均、95%等各项目的统计。
ID:查询的ID号,和上图的Query ID对应; Databases:数据库名; Users:各个用户执行的次数(占比); Query_time distribution :查询时间分布, 长短体现区间占比; Tables:查询中涉及到的表; Explain:SQL语句。
本文作者:吴航舟(上海新炬中北团队)
本文来源:“IT那活儿”公众号

文章转载自IT那活儿,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
