




点击蓝字 关注我们
摘要
在今年的 QCon 大会上,Apache SeaTunnel PPMC Member 高俊分享了题为《EtLT架构下的数据集成平台—Apache SeaTunnel》。
主要内容:
ETL到EtLT架构演进
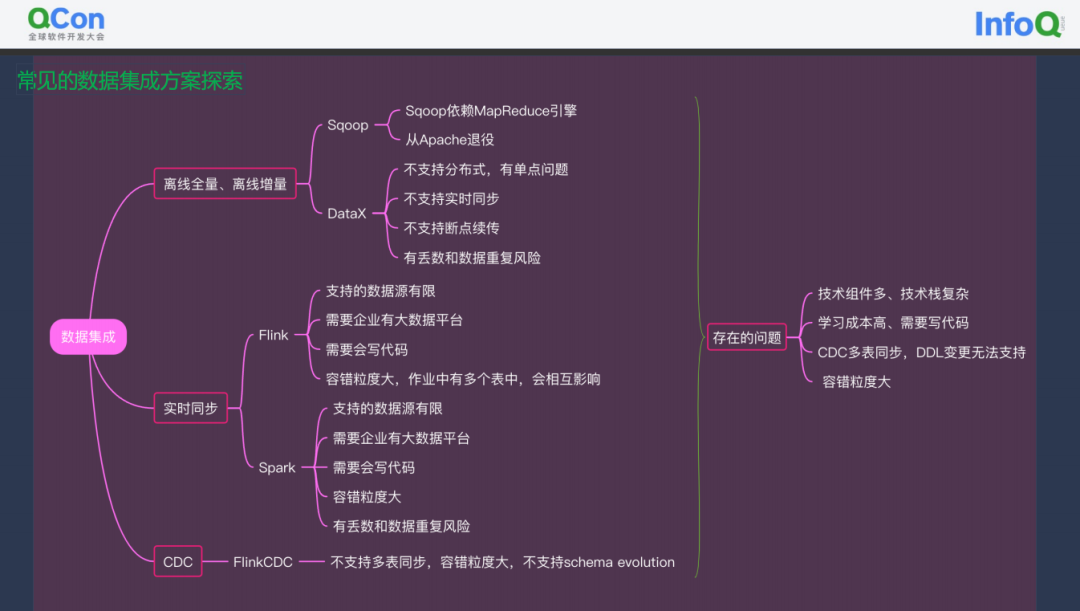
数据集成领域的痛点&常见的解决方案
下一代数据集成平台ApacheSeaTunnel
SeaTunnel的核心架构及设计
下一代数据集成引擎SeaTunnelZeta
近期规划&如何快速参与社区建设

ETL到EtLT架构演进
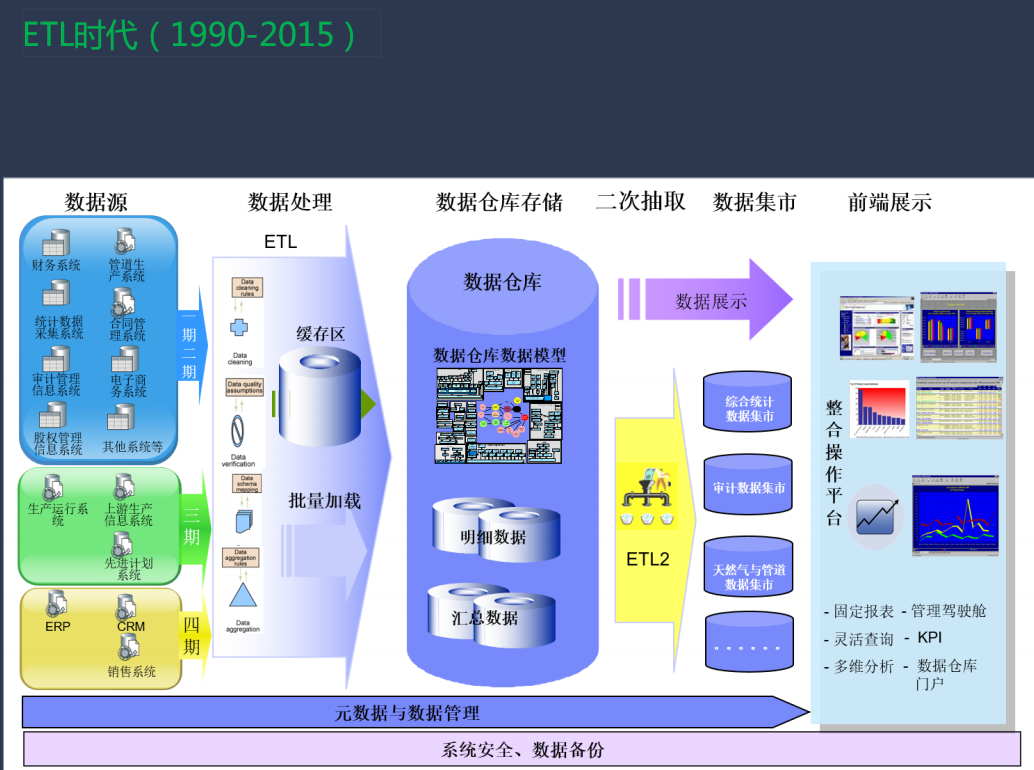
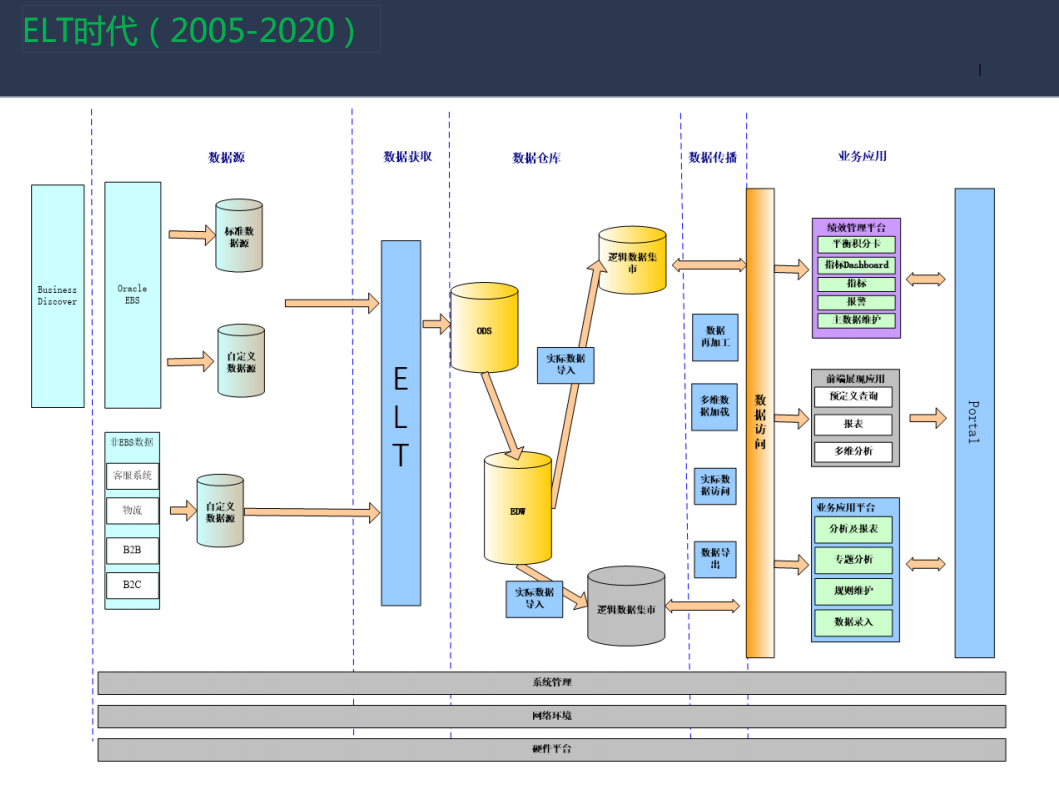
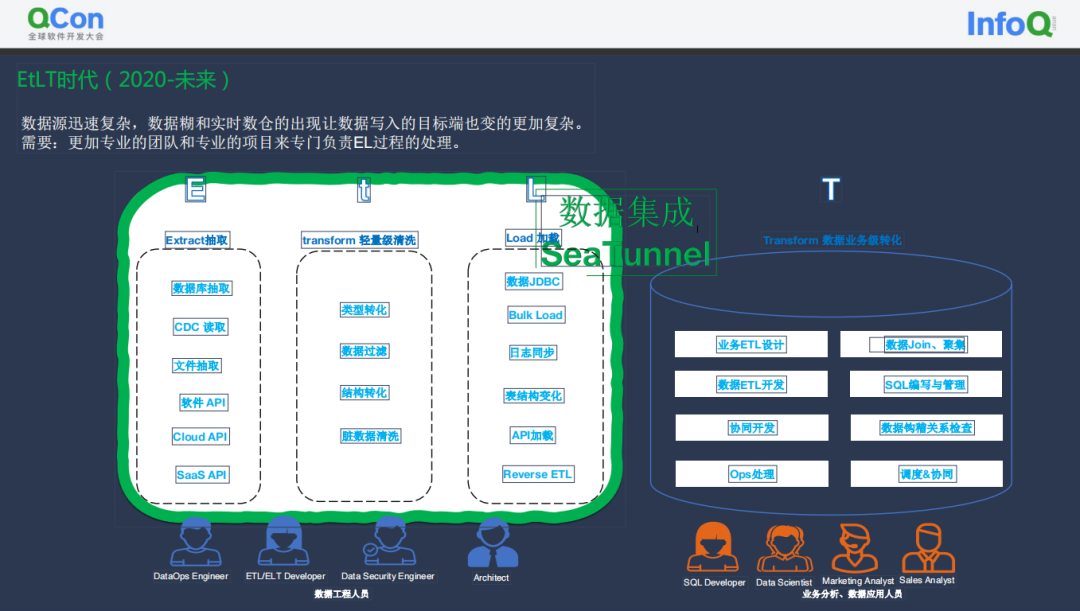
数据集成领域的痛点&常见的解决方案
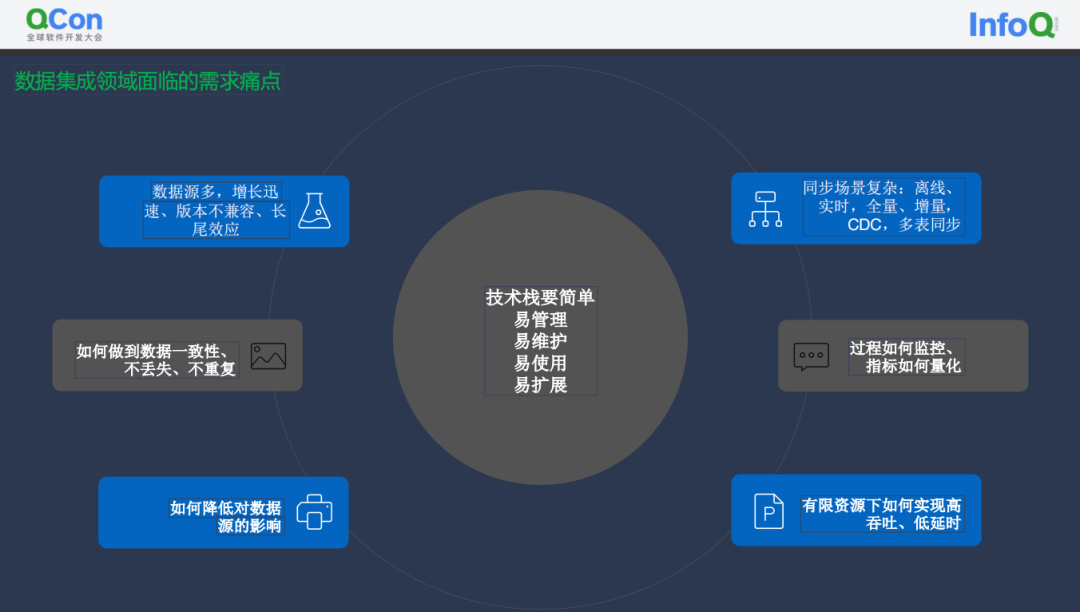
数据源多,SeaTunnel 社区目前统计到的数据源已经接近 500 个而且还在迅速的增长;版本不兼容,随着数据源版本迭代,兼容性上会出现问题,而且随着新技术的不断出现,数据集成领域需要快速地适配数据源,这是需要解决的一个核心痛点; 同步场景复杂:数据同步包括离线、实时,全量、增量同步,CDC,多表同步等,CDC的核心需求是要解决直接读物数据库的变更日志并解析,将其应用到下游,这个过程中,如何解析不同数据库的日志数据格式,事务处理,整库同步,分库分表等很多场景都有待适配支持; 过程如何监控、指标如何量化:同步过程中的监控缺失会带来信息的不透明,例如不确定已经同步的数据数量等; 有限资源下如何实现高吞吐、低延时,以降低成本; 如何降低对数据源的影响:多个表需要实时同步时,频繁读取 binlog 对数据源造成的压力较大,影响数据源的稳定性。同时JDBC 连接数过多时,也会导致数据源不稳定,甚至在数据源限制了最大连接数的情况下,同步作业可能无法正常运行。数据集成平台需要尽量降低对数据源的影响,比如减少连接占用,限制同步速度等。 如何做到数据一致性、不丢失、不重复:有些数据一致性要求高的系统,是不允许出现数据丢失和重复的。
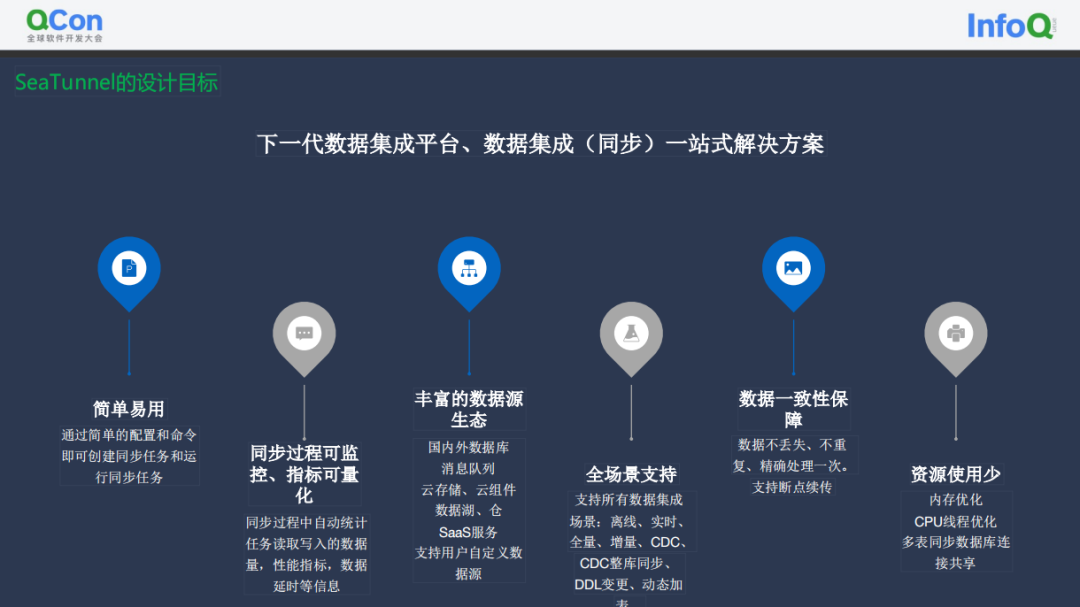
下一代数据集成平台Apache SeaTunnel
1
6大设计目标
2
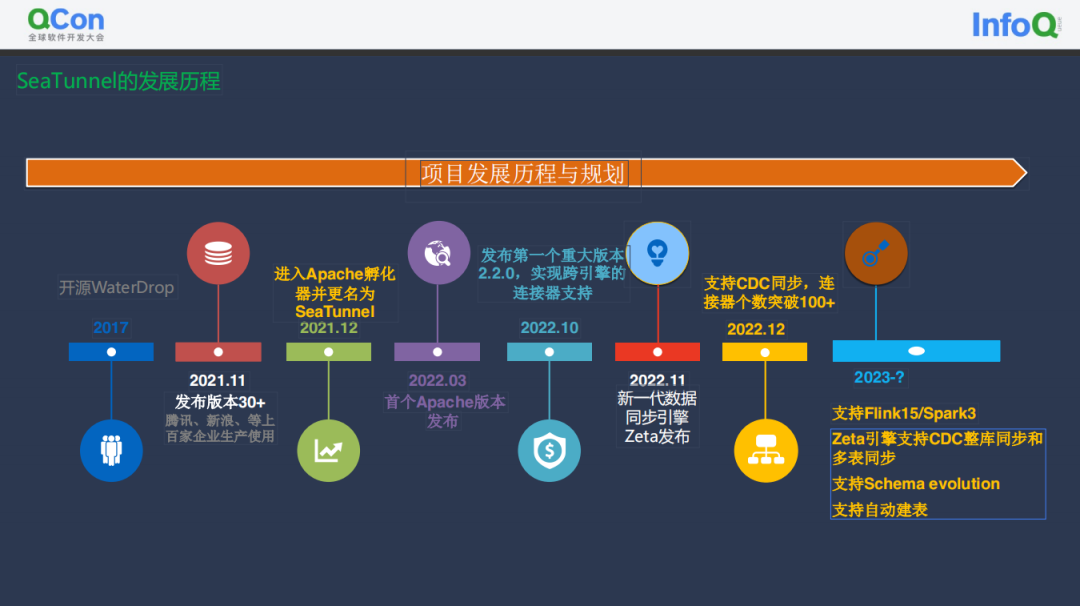
项目发展历程
3
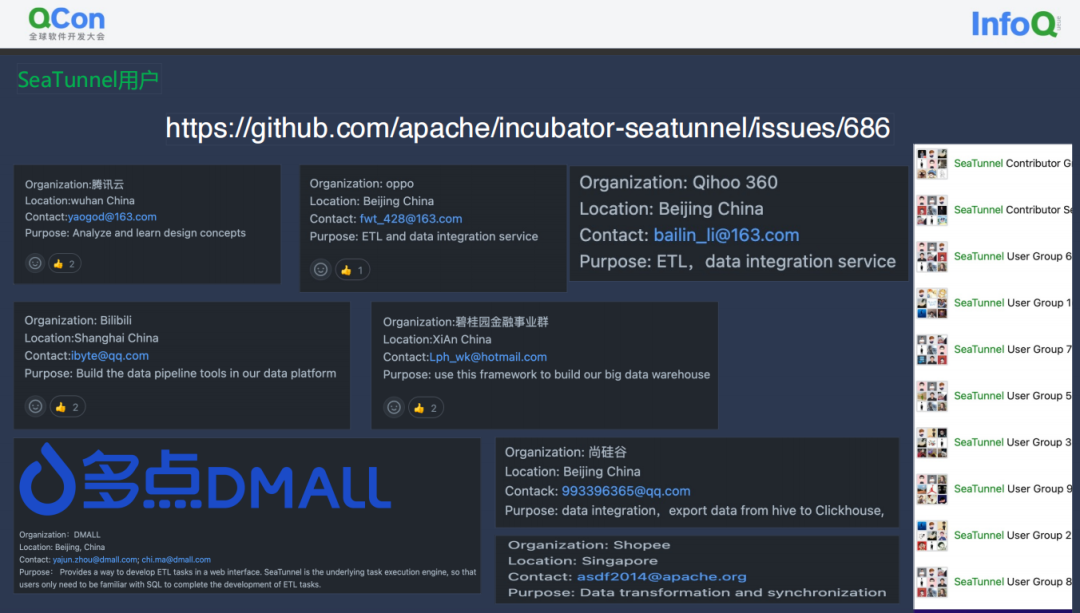
用户遍布全球
核心设计和架构
1
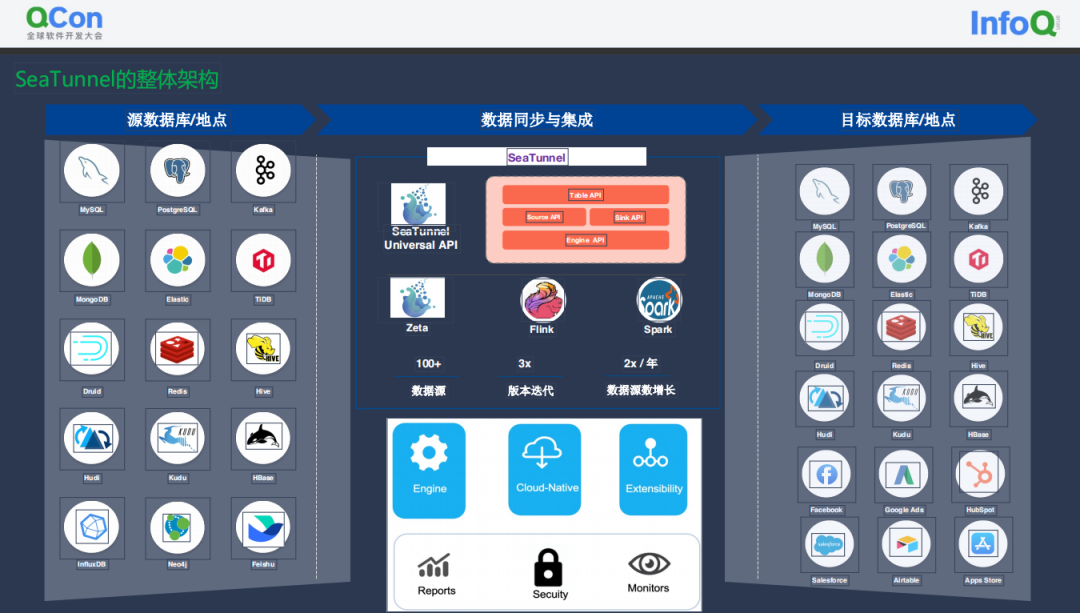
整体架构
2
与引擎解耦的连接器API

3
Source Connector
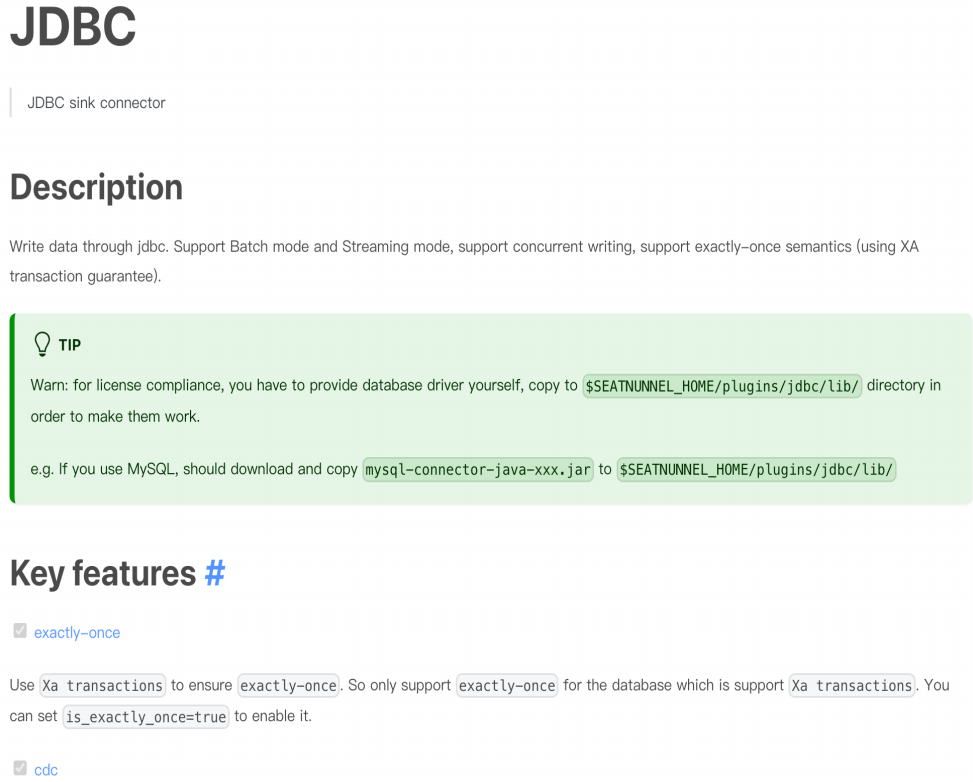
4
Sink Connector
SaveMode支持,灵活选择目标表现有数据的处理⽅式 自动建表,支持建表模板修改,多表同步场景下解放双⼿ Exactly-once语义支持,数据不丢失也不会重复,CheckPoint能⼒适配Zeta,Spark,Flink三种引擎 CDC支持,支持处理数据库日志事件
5
Transform Connector
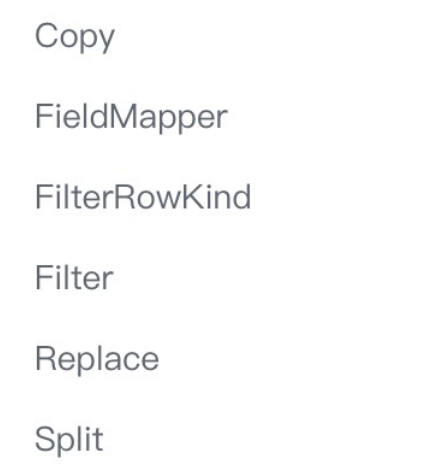
支持复制一列到新列 支持字段改名、改顺序、类型修改、删除列 支持替换数据中的内容 支持将一列拆分成多列 CDC Connector设计
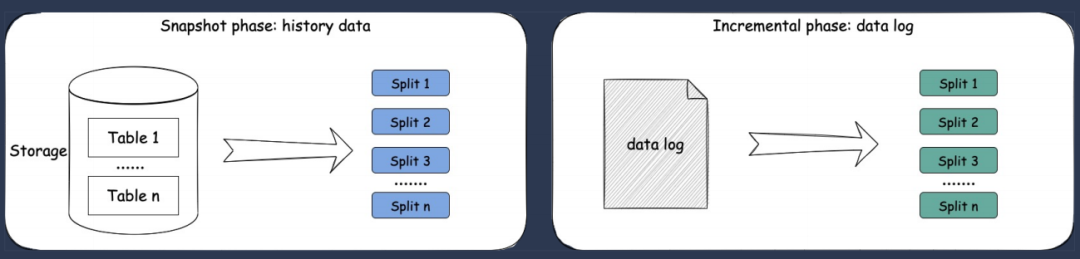
支持无锁并行快照历史数据 支持动态加表 支持分库分表和多结构表读取 支持Schemaevolution 支持Checkpoint流程,保证数据不丢失不重复 支持离线批量CDC同步
6
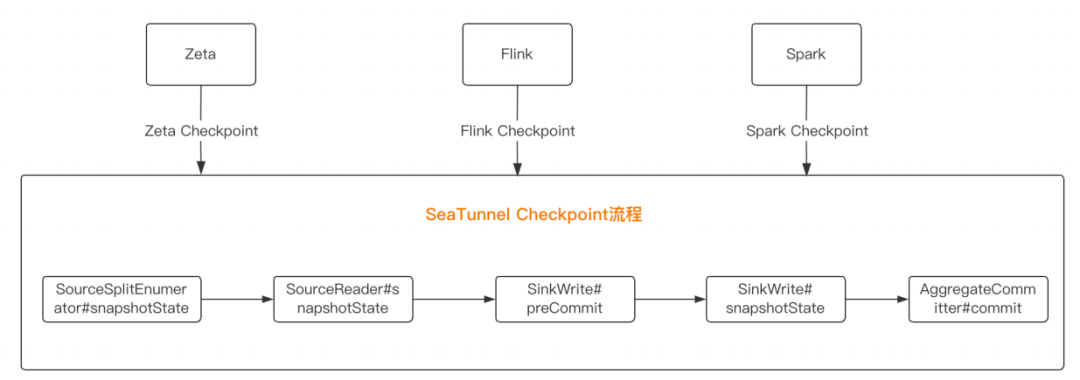
Checkpoint功能设计
下一代数据集成引擎SeaTunnel Zeta
1
SeaTunnel Zeta集群管理
2
SeaTunnel Zeta PipelineBase Failover

无论是批作业,还是流作业,以Pipeline为单位进行资源分配,Pipeline分配到所需资源后即可开始执行,不会等待所有task 都获取到资源。这可以解决 Flink 等引擎在数据同步时的一些痛点问题,也就是作业中有多个 Source 和 Sink 进行同步时,如果任何一端出现问题,整个作业都会被标为失败而被停止。 以Pipeline为粒度进行容错(Checkpoint, 状态回滚),目标表出现问题后,只会影响到上下游任务,其他任务会正常执行。 问题解决后,支持对单个Pipeline进行手工恢复。
3
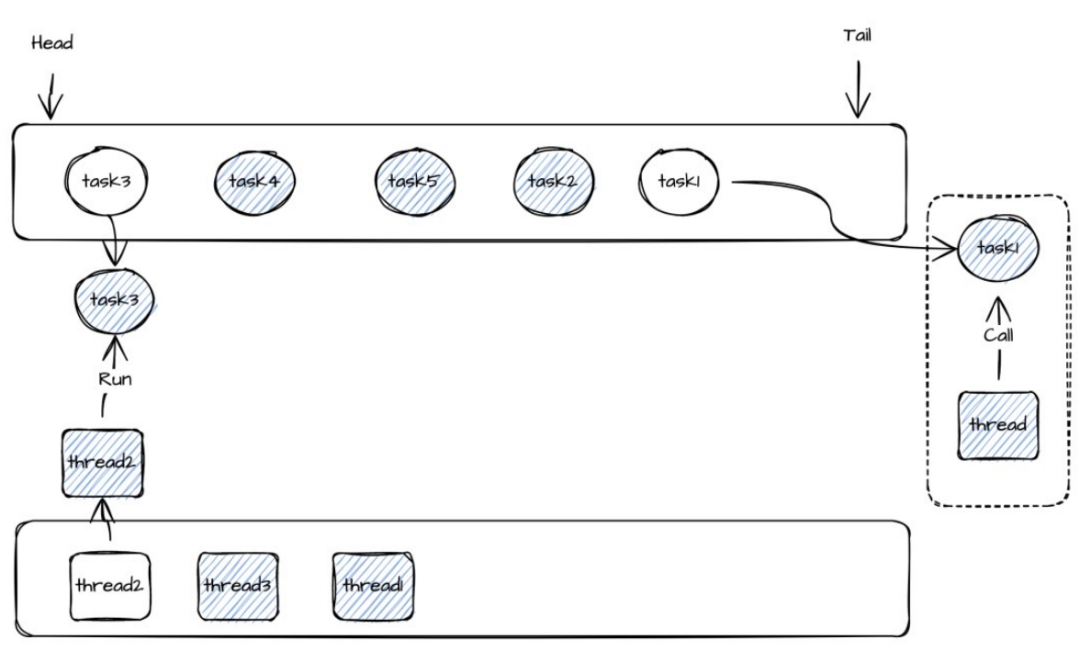
SeaTunnel Zeta 动态线程共享
4
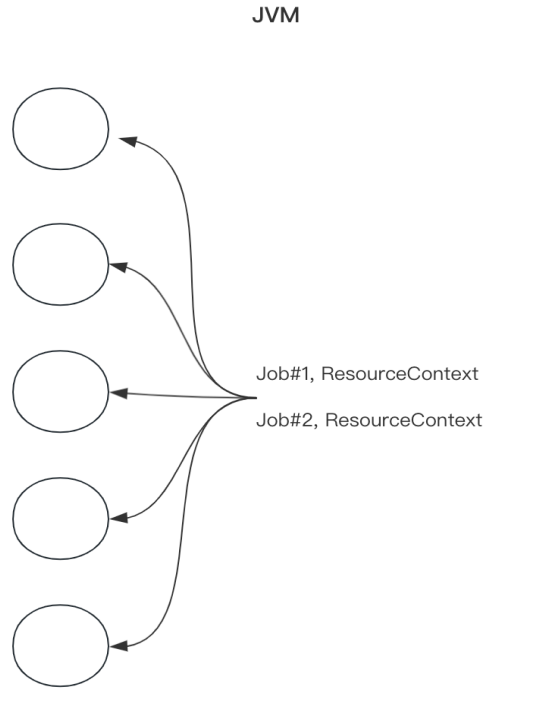
SeaTunnel Zeta 连接池共享
5
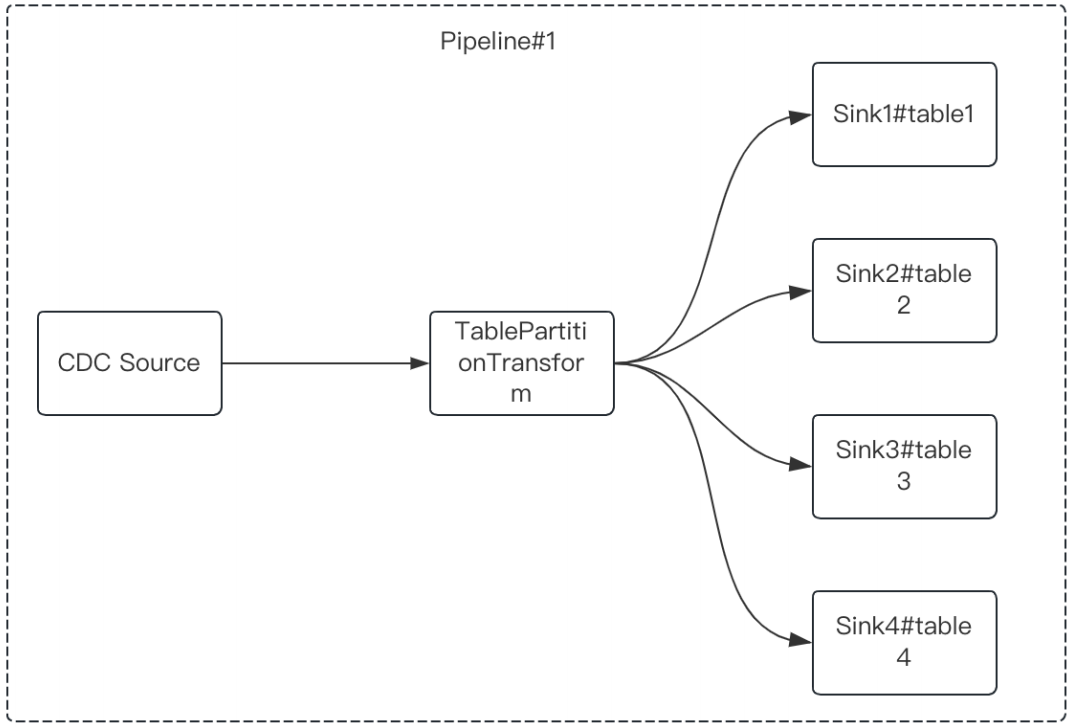
SeaTunnel Zeta多表同步
6
性能对比
近期规划&参与社区
Apache SeaTunnel

往期推荐
分享、点赞、在看,给个3连击呗!

文章转载自SeaTunnel,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
