





联想排序算法对比
示例表
CREATE TABLE `user` (`id` INT( 11 ) AUTO_INCREMENT COMMENT '主键id',`id_card` VARCHAR ( 20 ) NOT NULL COMMENT '身份证号码',`name` VARCHAR ( 64 ) NOT NULL COMMENT '姓名',`age` INT ( 4 ) NOT NULL COMMENT '年龄',`city` VARCHAR (16) NOT NULL COMMENT '城市',PRIMARY KEY ( `id` ),INDEX ( `city` )) ENGINE = INNODB COMMENT '用户表';insert into `user`(id_card,name,age, city) values('429106xxxxxxxx2134','关小童',22, '杭州'),('429106xxxxxxxx1234','郑凯',26, '上海'),('129106xxxxxxxx6543','王媛',28, '上海'),('129206xxxxxxxx6742','潘振',17, '长沙'),('129236xxxxxxxx7653','孙二娘',43, '杭州'),('129306xxxxxxxx8542','空三少',39, '青岛'),('129506xxxxxxxx4541','王麻子',55, '三亚'),('139306xxxxxxxx6666','我错了',7, '三亚'),('139206xxxxxxxx888x','小名',31, '合肥'),('439106xxxxxxxx999x','小红',29, '合肥'),('439122xxxxxxxx000x','邓论',78, '石家庄'),('429122xxxxxxxx1541','魔教中人',96, '合肥'),('129122xxxxxxxx0214','孙猴子',89, '花果山'),('129234xxxxxxxx0520','小主播',3, '杭州'),('129234xxxxxxxx1314','史蒂夫',11, '米国'),('129234xxxxxxxx7777','醍醐灌顶',14, '杭州');
创建一张示例表 user, 表中有 5个字段:id 是自增的主键,id_card 表示用户的身份证号码,name 表示用户姓名,age 表示用户年龄,city 表示用户所在城市;另外我们除了主键索引 id 外,还为 city字段创建了一个普通索引。最后向表中插入了几条数据。
假设现在有个需求,查询城市为“合肥”的所有人名字,并且按照年龄从小到大排序返回1000个人的的姓名,年龄, 身份证号码。对应的SQL应该为:
SELECT id_card,name,ageFROM userWHERE city = '合肥'ORDER BY ageLIMIT 3;
这条SQL对应的逻辑相对简单,很好理解。语句在执行时会使用到city索引树,并且会进行排序。可以通过Explain分析一下SQL的执行计划。
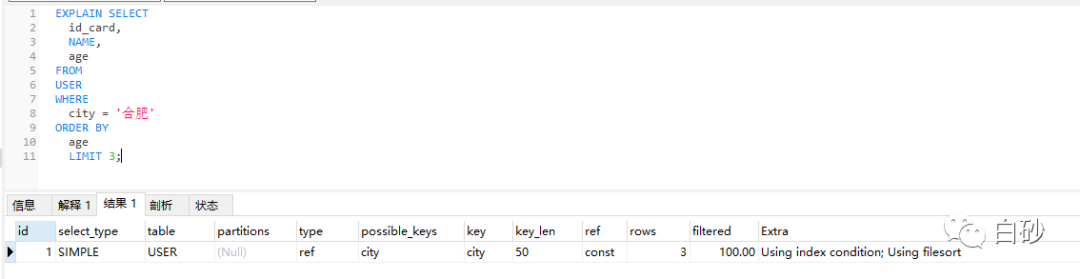
上图中 key 的值为 city, 表示使用到了 city 索引树;Extra 这个字段中的“Using filesort”表示的就是需要排序。
全字段排序
# 查看 sort_buffer 的大小SHOW VARIABLES LIKE 'sort_buffer_size';# 设置 sort_buffer 的大小SET GLOBAL sort_buffer_size = 262144;
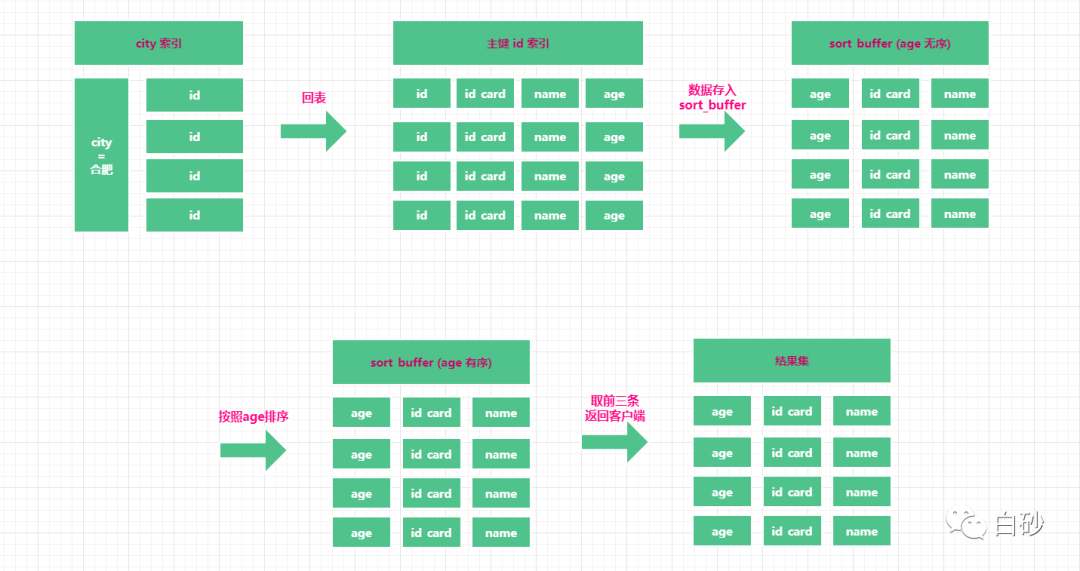
这个排序过程,因为是将所有查询的字段都存入到了 sort_buffer 中,因此称之为全字段排序。
看到这里,我相信大家应该会和我有一样的疑问,我们如果查询符合条件的数据有很多,以至于 sort_buffer 这块内存无法装下所有数据,这个时候在内存中肯定无法完成排序了,那该怎么办?
这个时候,就不得不利用磁盘临时文件作为辅助排序了。借助磁盘文件进行排序的时候,采用的是归并排序算法。当从主键id 索引树中查询到数据时,将数据放入到 sort_buffer 中,当 sort_buffer 中快满时,就在 sort_buffer 中对这部分数据进行排序,然后将排好序的数据放入到临时文件中,然后在继续从主键索引中读取数据,再在 sort_buffer 中进行排序,写入磁盘的临时文件中,循环操作,一直到所有数据读取完毕。最后将磁盘上的这些小文件,进行合并成一个有序的大文件,这样就完成了所有数据的排序。
在这个过程中,可以看出,在要排序的数据到达一定大小的情况下,如果 sort_buffer_size 的值越小,需要的临时文件就越多,发生 IO 的次数也就越多,性能就越差。
虽然知道了全字段排序的原理,也能通过查询配置查看 sort_buffer_size 的大小。该怎么确定在执行语句进行排序的时候有没有使用临时文件呢?可以通过 MySQL 中 information_schema 库中的 optimizer_trace 表来查看 SQL 执行的优化信息,但是默认情况下 optimizer_trace 的开关是关闭的,因为它记录的是 SQL 相关的优化信息,会额外消耗 MySQL 的资源。我们可以通过如下命令来查看和修改 optimizer_trace 的状态。
# 查看show variables like 'optimizer_trace';# 临时针对当前数据库连接修改(连接断开后,下次再连接数据库时,该值还是false)set optimizer_trace = "enabled=on";# 针对所有数据库连接修改set global optimizer_trace = "enabled=on";
开启了 optimizer_trace 统计信息之后,我们就可以从这张表中查看 SQL 执行的相关信息了。以文章前面示例为例,我们一次执行以下 SQL:
/* 打开optimizer_trace,只对本线程有效 */SET optimizer_trace='enabled=on';/* 执行语句 */SELECT id_card, name, age FROM user WHERE city = '合肥' ORDER BY age LIMIT 3;/* 查看 OPTIMIZER_TRACE 输出 */SELECT * FROM `information_schema`.`OPTIMIZER_TRACE`\G
最终会看到很多的信息,截取一点来确认我们是否使用了临时文件
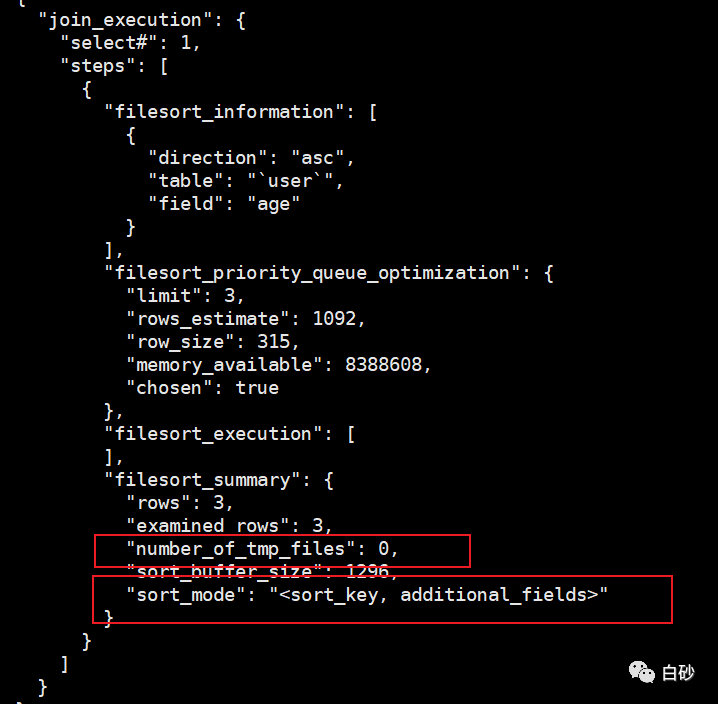
图中的 number_of_tmp_files 这一行表示的是否使用了临时文件,排序过程中使用的临时文件数,结果为0,则表示本次排序没有使用到临时文件进行排序。如果是大于0的,则表示使用了临时文件进行排序。
rowid 排序
看懂了上面的全字段排序,我会想,实际上我只是对age进行排序,为什么还要把一些其他的字段放进 sort_buffer 中呢?而且 sort_buffer 本身就是有内存大小限制的,sort_buffer 中放入的字段越多,占用的内存多大,存放的条数就越少。如果要对多条数据进行排序 或者 查询返回的字段很多的话,sort_buffer 中存放的字段数太多。,那很有可能用到磁盘文件排序了,磁盘那么慢,排序性能会比内存排序差很多。
如果 MySQL 认为排序的单行长度太大怎么办呢?
这一点MySQL的开发人员就考虑到这个问题了,因此就有了 rowid 排序。rowid 排序的原理大致就是,不会将所有要查询的字段都放入到 sort_buffer 中,而是将需要排序的字段和主键id放入到 sort_buffer 中。对应本文的例子就是将 age 和 id 放入到 sort_buffer 中。
在实际开发过程当中,有的表我们没有创建主键索引,那这个时候 MySQL 会判断表中有没有唯一索引,如果有唯一索引,那就会将这个唯一索引当做主键;如果也没有唯一索引,那么 MySQL 会默认为每一行数据生成一个 rowid,这个 rowid 作用和主键作用一样,那么在排序的时候,放入到 sort_buffer 中的字段就是被排序的字段和 rowid 了,这也是为什么叫它 rowid 排序的由来了。
show variables like 'max_length_for_sort_data';
# 限制设置为16个字节set max_length_for_sort_data = 16;# 查询数据SELECT id_card, name, age FROM user WHERE city = '合肥' ORDER BY age LIMIT 3;
1、首先MySQL 初始化 sort_buffer , 确定向内存中放入哪些字段。由于示例中的查询的是 name, id_card,age,三个字段长度之和超过了 max_length_for_sort_data 的限制,采用 rowid 排序。 只放入需要排序的字段 age 和 主键 id。
2、从索引树 city 找到第一个满足条件的主键id,返回主键id。
3、根据返回的主键id,进行回表,回到主键索引树查找对应id的记录值,并取出 age 的值,将 id, age 存入到 sort_buffer 中。
4、继续在 city 索引树上找下一条满足条件的节点数据,重复步骤2 和 3,直到索引树上条件不满足时停止。
5、对 sort_buffer 中的数据按照字段 age 进行排序;
6、从排好序的数据中,取前三条数据。由于我们要查的数据是 id_card、name、age 这三个字段,此时 sort_buffer 中只有 id 和 age 字段,因此此时还需要根据取到的三条数据的 id,到主键索引树上读取 id_card、name、age 的值;
7、最后将 id_card、name、age 字段的数据返回给客户端。
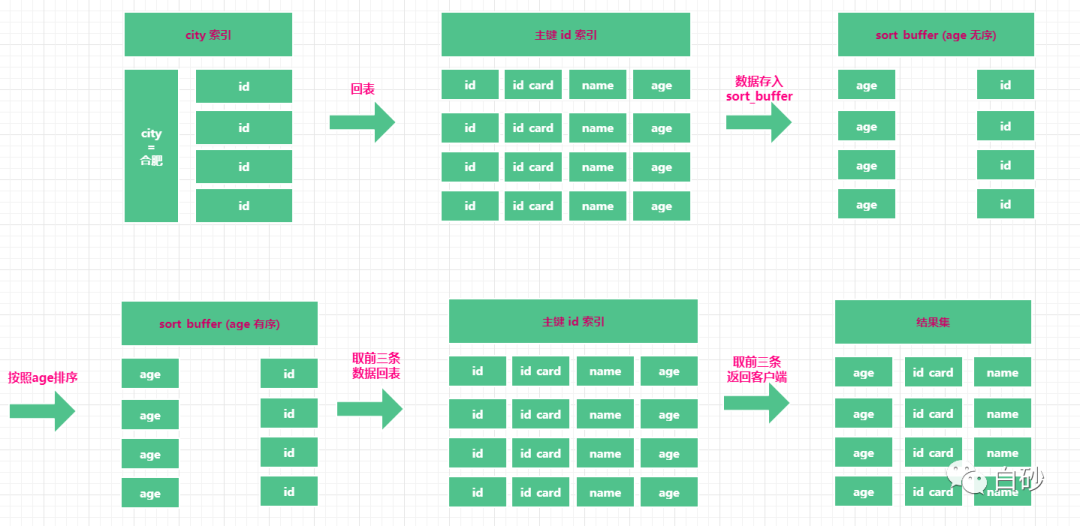
从这个流程中,可以发现,相比全字段排序来讲,rowid 排序的回表次数更多。同样,可以使用 optimizer_trace 记录的rowid 排序信息。
select * from information_schema.optimizer_trace\G
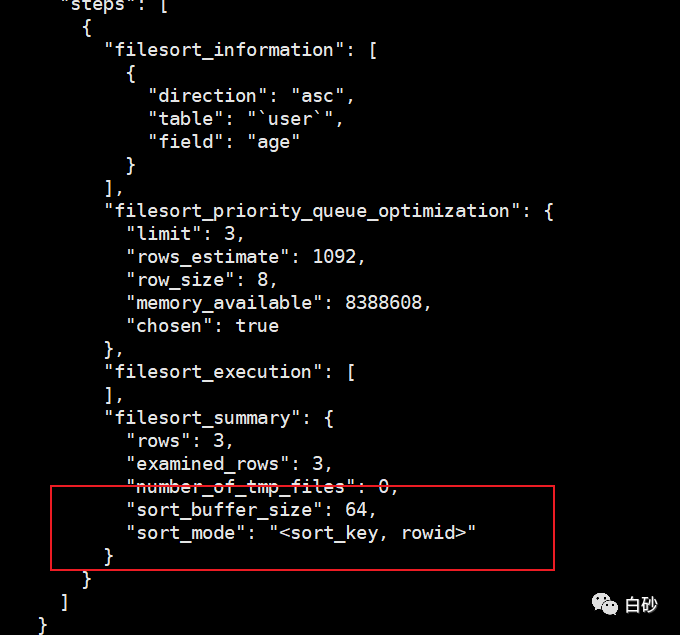
从图中我们可以看到,sort_mode 这一行显示的 rowid,这说明本次排序使用的是 rowid 排序,而对于全字段排序,则显示的不是 rowid。
总结
- End -
最后,求关注。如果你还想看更多优质原创文章,欢迎关注我的公众号「白砂」。
如果我的文章对你有所帮助,还请帮忙点赞、在看、转发一下,你的支持会激励我输出更高质量的文章,非常感谢!
点个在看你最好看
