




建立空间索引的图形列通过表达式、函数、类型转换后导致索引失效。
部分空间函数根本不会走空间索引。
索引效率低,IO与CPU放大严重。
--居民点create table house(gid serial primary key,geom geometry(Point,4326));create index house_geom_idx on house using gist(geom);--区域内构造测试数据insert into house(geom)select (st_dump(ST_GeneratePoints(ST_MakeEnvelope(113,24,125,35,4326),25000))).geom;--交通点create table station(gid serial primary key,geom geometry(Point,4326));insert into station(geom)select (st_dump(ST_GeneratePoints(ST_MakeEnvelope(113,24,125,35,4326),6000))).geom;
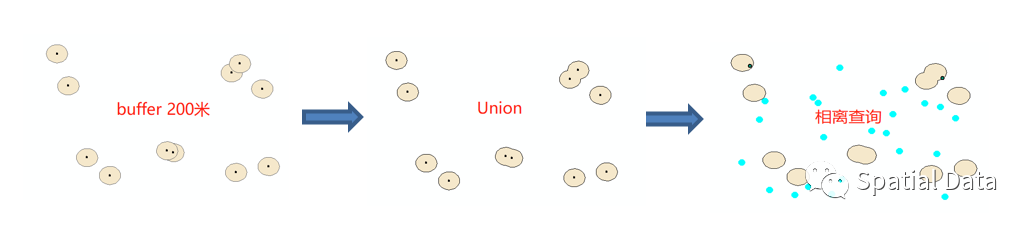
1 station先缓冲200米;
2 合并所有小缓冲区为一个面;
3 计算与缓冲面不相交的居民点;
explain with temp_t as(select st_union(st_buffer(geom::geography,200)::geometry) as geomfrom station)select count(a.*) from house a,temp_t b whereST_Disjoint(a.geom,b.geom);QUERY PLAN-------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------Aggregate (cost=1077439.85..1077439.86 rows=1 width=8)-> Nested Loop (cost=451710.00..1077419.02 rows=8333 width=60)Join Filter: st_disjoint(a.geom, (st_union((geography(st_transform(st_buffer(st_transform(geometry((station.geom)::geography), _st_bestsrid((station.geom)::geography)), '200'::double precision, ''::text), 4326)))::geometry)))-> Aggregate (cost=451710.00..451710.01 rows=1 width=32)-> Seq Scan on station (cost=0.00..110.00 rows=6000 width=32)-> Seq Scan on house a (cost=0.00..459.00 rows=25000 width=92)JIT:Functions: 9Options: Inlining true, Optimization true, Expressions true, Deforming true
既然ST_Disjoint函数根本不走空间索引,那么换个思路,假设先查询交通点200米范围内的居民点,然后从总的居民点记录扣除查询到的数据,剩下的数据就是满足业务要求的结果了。
explain analyse select count(a.*) from house a where gid not in (select distinct(a.gid) from house a,(select st_union(st_buffer(geom::geography,200)::geometry) geom from station) bwhere ST_intersects(a.geom,b.geom) );QUERY PLAN-------------------------------------------------------(actual time=29084.264..29084.268 rows=1 loops=1)-> Seq Scan on house a (cost=451773.12..452294.62 rows=12500 width=60) (actual time=29076.760..29083.094 rows=24992 loops=1)Filter: (NOT (hashed SubPlan 1))Rows Removed by Filter: 8SubPlan 1-> Unique (cost=451772.93..451773.06 rows=25 width=4) (actual time=29062.593..29062.600 rows=8 loops=1)-> Sort (cost=451772.93..451773.00 rows=25 width=4) (actual time=29062.591..29062.595 rows=8 loops=1)Sort Key: a_1.gidSort Method: quicksort Memory: 25kB-> Nested Loop (cost=451710.28..451772.35 rows=25 width=4) (actual time=5319.598..29062.563 rows=8 loops=1)-> Aggregate (cost=451710.00..451710.01 rows=1 width=32) (actual time=1952.370..1952.371 rows=1 loops=1)-> Seq Scan on station (cost=0.00..110.00 rows=6000 width=32) (actual time=0.011..1.205 rows=6000 loops=1)-> Index Scan using house_geom_idx on house a_1 (cost=0.28..62.31 rows=2 width=36) (actual time=3367.208..27110.156 rows=8 loops=1)Index Cond: (geom && (st_union((geography(st_transform(st_buffer(st_transform(geometry((station.geom)::geography), _st_bestsrid((station.geom)::geography)), '200'::double precision, ''::text), 4326)))::geometry)))Filter: st_intersects(geom, (st_union((geography(st_transform(st_buffer(st_transform(geometry((station.geom)::geography), _st_bestsrid((station.geom)::geography)), '200'::double precision, ''::text), 4326)))::geometry)))Rows Removed by Filter: 24990

二次重构方案:查询的时候不使用ST_Union,从29s优化到858ms。
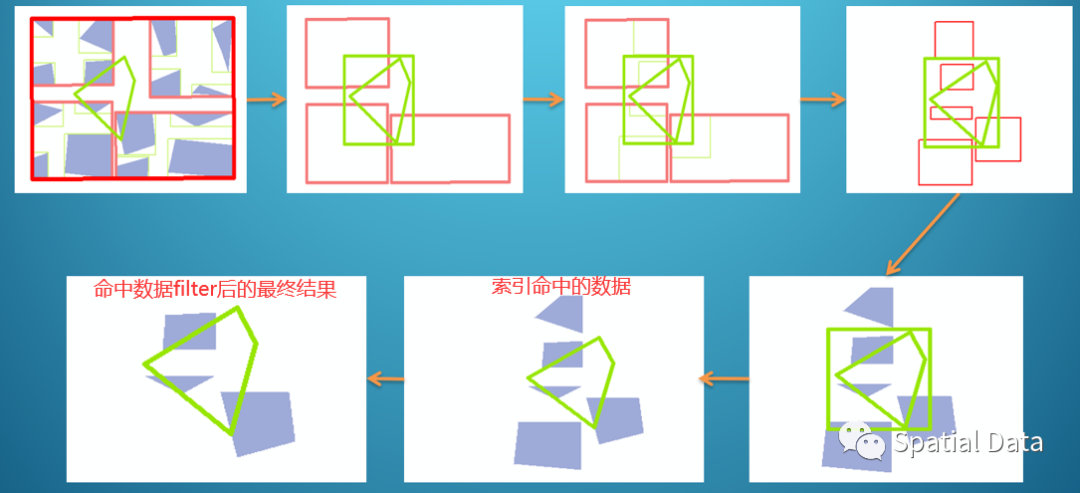
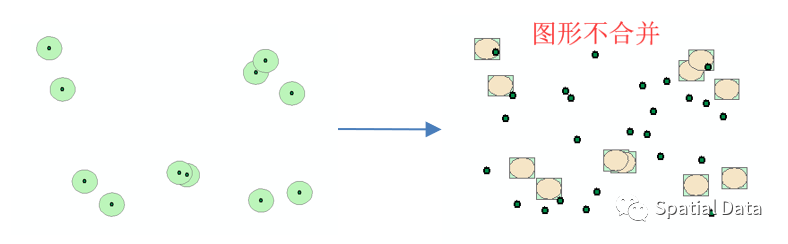
不合并缓冲区后,每个交通点缓冲区的bbox都是独立的,并且范围不大,那么索引命中效率就会非常高,有效抑制IO与CPU放大问题,如下图:
explain analyse select count(a.*) from house a where gid not in (select distinct(a.gid) from house a,(select st_buffer(geom::geography,200)::geometry geom from station) bwhere ST_intersects(a.geom,b.geom) );QUERY PLAN-------------------------------------------------------(actual time=858.170..858.173 rows=1 loops=1)-> Seq Scan on house a (cost=1671767.45..1672288.95 rows=12500 width=60) (actual time=849.879..857.160 rows=24992 loops=1)Filter: (NOT (hashed SubPlan 1))Rows Removed by Filter: 8SubPlan 1-> Unique (cost=1670954.95..1671704.95 rows=25000 width=4) (actual time=501.950..501.956 rows=8 loops=1)-> Sort (cost=1670954.95..1671329.95 rows=150000 width=4) (actual time=501.949..501.952 rows=8 loops=1)Sort Key: a_1.gidSort Method: quicksort Memory: 25kB-> Nested Loop (cost=75.41..1656008.00 rows=150000 width=4) (actual time=102.677..501.871 rows=8 loops=1)-> Seq Scan on station (cost=0.00..110.00 rows=6000 width=32) (actual time=0.015..1.282 rows=6000 loops=1)-> Index Scan using house_geom_idx on house a_1 (cost=75.41..275.96 rows=2 width=36) (actual time=0.019..0.019 rows=0 loops=6000)Index Cond: (geom && (geography(st_transform(st_buffer(st_transform(geometry((station.geom)::geography), _st_bestsrid((station.geom)::geography)), '200'::double precision, ''::text), 4326)))::geometry)Filter: st_intersects(geom, (geography(st_transform(st_buffer(st_transform(geometry((station.geom)::geography), _st_bestsrid((station.geom)::geography)), '200'::double precision, ''::text), 4326)))::geometry)Rows Removed by Filter: 0
1 ST_Intersects函数是走了house_geom_idx索引的,并且Filter后removed记录数量为0,证明索引效率非常的高,完全没有多余数据被索引命中。
2 not in 查询可以使用not exists或左连接优化。
三次重构方案:从858ms到645ms。
not exists优化
xplain analyse SELECT count(*) from house aWHERE NOT EXISTS (SELECT *FROM (select distinct(a.gid) gid from house a,(select st_buffer(geom::geography,200)::geometry geom from station) bwhere ST_intersects(a.geom,b.geom) ) bWHERE b.gid= a.gid);QUERY PLAN---------------------------------------------(actual time=644.843..644.848 rows=1 loops=1)
左连接优化:
explain analyse select count(*) from (select a.*,b.gid as gid2 from house a left join (select distinct(a.gid) from house a,(select st_buffer(geom::geography,200)::geometry geom from station) bwhere ST_intersects(a.geom,b.geom) ) as b on a.gid=b.gid) as cwhere gid2 is null;QUERY PLAN------------------------------------------------(actual time=647.435..647.439 rows=1 loops=1)
ST_Disjoint空间关系是不会走空间索引的,该函数绝对不要在空间查询的条件中使用。
ST_Disjoint查询场景应该使用ST_Intersects查询取反去获取结果。
不要在查询过程中,查询条件中使用ST_Union函数,只能在最终的查询结果输出时可以使用合并函数,因为在过程中、条件中使用,一定会导致IO与CPU放大,极其影响性能。
精益求精,对任何可能存在优化空间的sql语句,都应该尝试测试下输出性能。
文章转载自Spatial Data,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
