




让软件执行情况可视化,是性能分析、调试的利器
Brendan Gregg, Netflix
日常工作中,我们需要理解软件对系统资源的使用情况。比如对于cpu,我们想知道当前软件究竟使用了多少cpu?软件更新以后又变化了多少?剖析器(profilers)可以用来分析这样的问题,帮助软件开发者优化代码,指导软件使用者调优运行环境。但是profile通常都很长,太长的输出分析和理解起来都很不方便。火焰图作为一种新的profile可视化方式,可以让我们更直观,更方便的理解、分析问题。
在像“Netflix云微服务架构”这种软件升级迭代迅速的环境中,快速理解profiles尤为重要。同时,对profile的快速的理解也有助于我们更好的研究其他人编写的软件。
火焰图可以用多种profilers(包括资源和系统事件)的输出生成,本文以cpu为例,介绍了火焰图的用法以及其可以解决的各种实际问题。
CPU Profiling
CPU分析的一种常用技术是,使用像Linux perf_events和DTrace之类系统追踪工具的对stack traces进行采样。stack trace显示了代码的调用关系,比如下面的stack trace ,每个方法作为一行并按照父子关系从下到上排序。
SpinPause
StealTask::do_it
GCTaskThread::run
java_start
start_thread
综合考虑采样成本、输出大小、应用环境,CPU profile 有可能是这样收集:对所有的cpu,对stack traces以每秒99次的速度,连续采样30秒(使用99而不是100,是为了防止采样周期与某些系统周期事件重合,影响采样结果)。对于一个16核的机器来说,输出结果可能会有47520个堆栈采样。可能会输出成千上万行文本。(ps:原文是not 100, to avoid lock-step sampling 理解不了,所以按照书中的描述写的)
有些profile可以压缩输出,比如DTrace,可以把相同的stack traces汇总到一起,只输出次数。这个优化还是蛮有用的,比如长时间的for 循环,或者系统idle状态的stack traces,都会被简化成一个。
Linux perf_events还可以进一步压缩输出,通过合并相同的substack,使用树形结构汇总输出。对于树的每个分枝,都可以统计count或百分比。如图一所示:
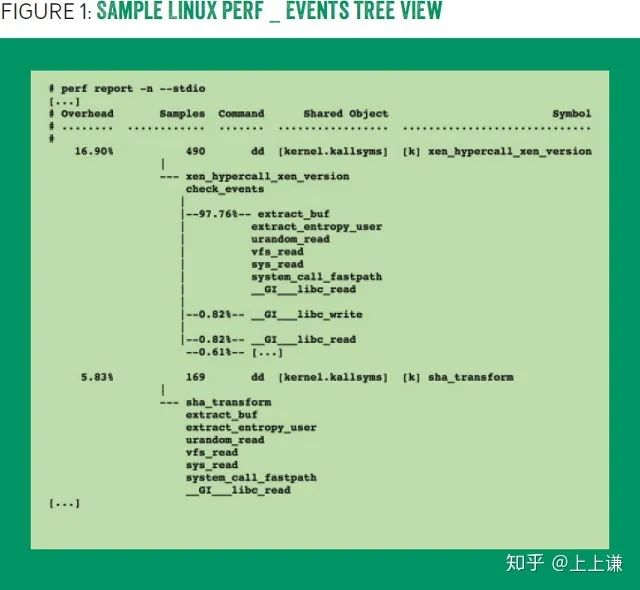
实际上,perf_events和DTrace的输出,在很多情况下,足够分析问题使用了。但是也有时候,面对超长的输出,就像面对一堵写满字的高墙,分析其中某个堆栈就好比盲人摸象、管中窥豹。
The Problem
为了分析“the Joyent public cloud”的性能问题,我们发明了火焰图。问题简单描述就是:某台服务器上部署了一个mysql服务,该服务的cpu使用率比预期的情况高了40%。
我们使用DTrace,以997 Hz 的频率连续采样stack traces 60秒,尽管DTrace对输出进行了压缩,输出还是有591622行,包括27053个stack traces,图二展示了输出结果,屏幕最下方显示的是调用最频繁的方法,说不定是问题的关键。

最频繁的方法是calc_sum_of_all_status()
,这个方法在执行mysql命令show status
时被调用。也许有个客户端在疯狂执行这个命令做监控?
为了证明这个结论,用该方法采样的次数5530,除以总的采样次数348427。算出来这个方法只占用了1.6%,远远不到40%。看来得继续分析profile。
如果继续按照调用频度,一个一个分析stack traces,完全是一项体力劳动。看下图三就知道这是一项多么庞大的工作量。缩放以后,整个DTrace输出就像一个毫无特征的灰色图片。

这简直是不可能完成的任务!那么,有没有更好的方法呢?
为了充分利用stack traces 层次的特性,我发明了一种可视化原型,如图四所示,展示了跟图三相同的信息。图片之所以选择暖色调,是因为这种原型解释了为什么cpu很“hot”,也正是因为暖色调和火焰一样的形状。这种原型被命名为“火焰图”。(可交互的svg格式的图4可以在http://queue.acm.org/downloads/2016/Gregg4.svg 体验)
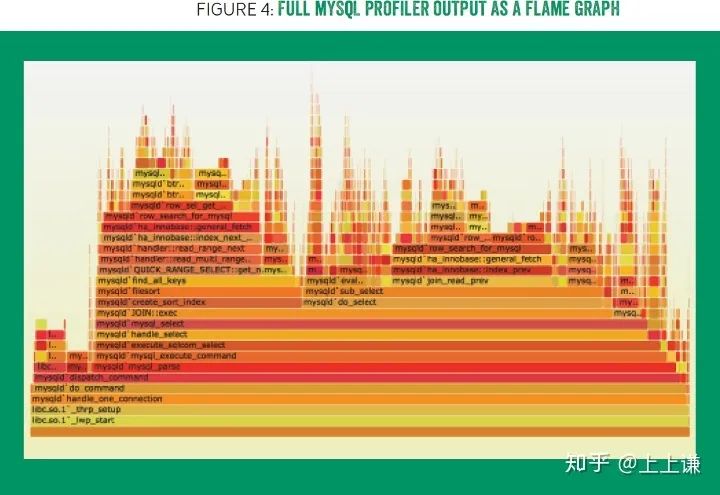
使用火焰图可以很快的找到profile的主体部分,图片显示之前找到的MySQL status 命令,只占profile的3.28%,真正的大头是含有join
的mysql语句。顺着这个线索,我们找到了根本问题,解决以后,cpu使用率下降了40%。
Flame Graphs Explained
火焰图用相邻的diagram代表一堆stack traces 。diagram的形状像是一个倒着的冰锥 。这个冰锥一样的图形通常用来描述cpu profile。
火焰图有以下特征:
• 一列box代表一个stack trace,每个box代表一个stack frame。
• y轴显示了栈的深度,按照调用关系从下到上排列。最顶上的box代表采样时,on-CPU的方法。每个box下边是该方法的调用者,以此类推。
• x轴代表了整个采样的范围,注意x轴并不代表时间,所有box按照方法名称的字母顺序排列,这样的好处是,相同名称的box,可以合并为一个。
• box的宽度代表了该方法在采样中出现的频率。该频率与宽度成比例。
• 如果box很长,会显示完整的方法名称,如果很短,只会显示省略号或者nothing。
• box的颜色是随机选择的暖色调,这样有助于肉眼区分细长的塔状boxes。当然也有其他配色方案,后面再说。
• profile有可能是单线程、多线程、多应用甚至是多host的,如果需要,可以分解成子图。
• 还有很多其他的采样方式,box的宽度除了频率以外,还可以表示多种其他的含义。比如off-cpu火焰图中,x轴的宽度代表方法block的时间。
使用火焰图,整个profile一目了然,可以方便的定位到感兴趣的位置。火焰图成了软件执行情况的导航图。
除了这种可交互的展示方式,火焰图也可以方便的保存为静态图片的格式,方便打印出来。
Interactivity
火焰图可以支持交互功能,可以显示更多细节、改进导航和执行计算。
原生的火焰图使用嵌入式javascript生成一张可交互的svg图片,提供了三种交互特性:鼠标hover显示详情、点击缩放和搜索。
hover显示详情
当鼠标hove到box上,tooltip内和图片左下方会显示方法的full name,该方法的采样数量,以及百分比。格式如下:
Function: mysqld'JOIN::exec (272,959 samples, 78.34 percent).
hover这项特性有助于用户查看很窄的box,显示百分比能够帮助用户量化代码路径的资源使用率,指导用户找到代码中急需优化的部分。
点击缩放
当用户点击一个box时,火焰图水平缩放,以显示局部的细节信息。该box下方的父box颜色变淡,表示只有部分被展示。点击reset zoom 可以回到全局视图。
搜索
点击search或者按ctrl+f 来使用搜索功能。搜索功能支持正则表达式,所有命中的box会被高亮并被显示为紫色。同时,图片右下角会显示命中方法的总百分比。如图五所示。(可交互的图五可以在这里体验: http://queue.acm.org/downloads/2016/Gregg5.svg.)
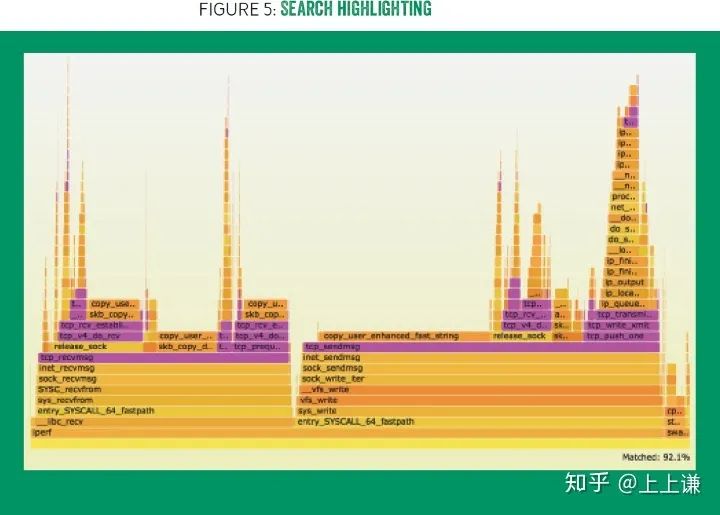
搜索不仅可以方便定位方法,还可以高亮逻辑上相关的一组方法。比如输入"^ext4_"显示所有跟linux ext4 文件系统相关的方法。
有时候,多个代码路径都以相同的热点函数(比如自旋锁)结束,如果这些方法分布在图片20多个位置上,汇总他们的百分比就很麻烦。搜索功能可以解决这个问题。
Instructions
火焰图有很多实现,原生的火焰图使用Perl编写,并且开放源码。包括采样在内,生成一张火焰图总共分三步:
用户采样 stack traces (比如使用 Linux perf_events、DTrace或者Xperf)。
将采样输出压缩为指定格式。我们已经编写了很多perl脚本处理各种profiler的输出。在项目中以"stackcollapse"前缀命名。
使用 flamegraph.pl 生成火焰图. 该脚本使用javascript解析前边步骤的输出生成最终输出。
指定压缩格式指的是:把一个stack traces展示为一行,栈帧之间使用分号间隔,并在末尾的空格之后显示采样数量。应用名称,进程id之类的信息,可以用“.”分隔以后, 补充在stack traces之前。增加这些信息以后,生成的火焰图中,会按照这些前缀进行分组。
比如说,假如profile包含下面三个stack traces:
func_c func_b func_a start_thread
func_d func_a start_thread
func_d func_a start_thread
压缩为指定格式以后,是这个样子的:
start_thread;func_a;func_b;func_c 1
start_thread;func_a;func_d 2
如果把应用名称(比如:java)也加在里面,则是:
java;start_thread;func_a;func_b;func_c 1
java;start_thread;func_a;func_d 2
设计这种中间格式的好处是,如果出现了新的profiler,只需要编写转换器就可以使用火焰图。目前已经有DTrace、perf_events、FreeBSD pmcstat, Xperf, SystemTap, Xcode Instruments, Intel VTune, Lightweight Java Profiler, Java jstack, and gdb 这么多可用的转换器。
flamegraph.pl 支持一些用户选项,比如说更改火焰图的title。
下面是从采样(使用perf )到生成图片的一个具体的例子:
# git clone https://github.com/brendangregg/FlameGraph
# cd FlameGraph
# perf record -F 99 -a -g -- sleep 60
# perf script | ./stackcollapse-perf.pl | ./flamegraph.pl > out.svg
因为中间格式每个记录一行,在生成火焰图之前可以使用grep/sed/awk 进行修改。使用其他profiler的教程参见官方文档。
Flame Graph Interpretation
如何分析生成的火焰图:
• 火焰图顶部显示了采样过程中on CPU的方法。对CPU profiles,这些方法直接占用cpu资源。对于其他的profile,这些方法导致了相关的内核事件。
• 在火焰图顶部寻找“高原”状的方法,位于顶部的某个很宽的方法,表示其在采样中大量出现。对于CPU profiles,这意味着这个方法经常在CPU上运行。
• 自顶向下看显示了调用关系,上边的方法被其下方的方法调用,以此类推。快速的从上往下浏览可以理解某个方法为什么被调用。
• 自底向上看显示了代码逻辑,提供了程序的全局视图。底部的方法会调用其顶部的多个方法,以此类推。自底向上看可以看到代码的分支形成的多个小型的“塔尖”。
• box的宽度可以用来比较,更宽的box意味着在采样结果中更多的比例。
• 对于cpu profiles 来说,如果a方法比b方法宽,有可能是因为a方法本身执行需要使用比b方法更多的cpu。也有可能是a方法被调用的次数比b方法更频繁。采样的最终结果并不能体现一个方法被调用多少次,所以这两种情况都有可能。
• 如果一个方法顶部出现了两个“大塔尖”,导致火焰图中出现一个“大分叉”,这样的方法很值得研究。两个“塔尖”可能是被调用的两个子方法,也可能是条件语句的两个不同分支。
Interpretation Example
为了更直观的让大家理解火焰图的含义,下面以图六作为例子。这是使用cpu profile生成的一张火焰图。

图片顶部显示说明g()
使用cpu最频繁;虽然d()
很宽,但是该方法直接使用cpu最少。b()
和c()
并不直接使用cpu资源,而他们的子方法使用。
g()
底部的方法显示了调用关系:g()
被 f()
调用,f()
被 d()
调用,以此类推。
对比b()
和 h()
的宽度可以发现,b()
对cpu的使用率是h()
的4倍。真正在cpu上执行的是他们的子方法。
该图的主分支是a()
调用了 b()
和 h()
,原因有可能是a()
中存在条件分支(比如一个if语句,如果为true执行b()
,反之执行h()
),也有可能a()
分成了两个步骤b()
和 h()
。
Other Code-Path Visualizations
正如图一所示,Linux perf_events 使用树形结构展示cpu使用率,这是另一种层级可视化方式。与火焰图相比,该方法并不能提供直观的全局视图。
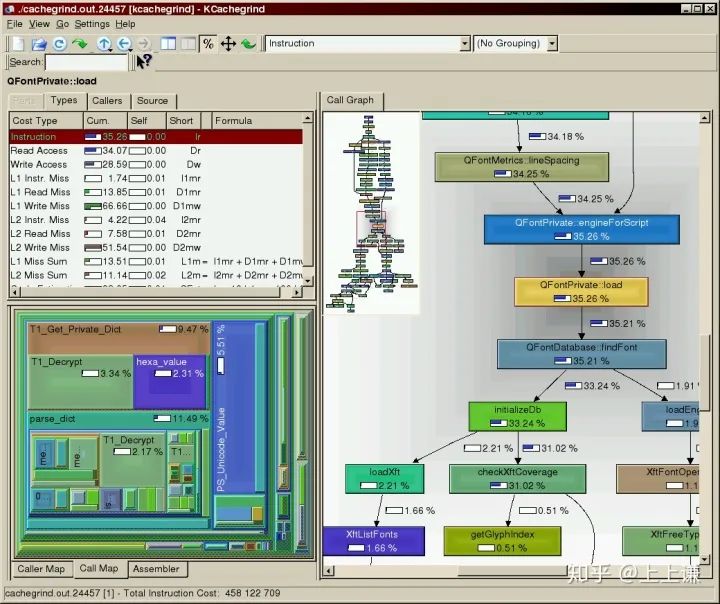
KCacheGrind 使用有向无环图实现可视化,使用宽度自适应的box表示方法,使用箭头表示调用关系,box和箭头上都标注了百分比。与Linux perf_events一样,图片缩小以后,也很难提供全局信息。
sunburst布局跟火焰图的冰锥布局很像。不同的是sunburst使用了极坐标。sunburst生成的图形很漂亮,但是却并不利于理解。与角度大小相比,人们更容易区分宽度。所以在直观性上火焰图更胜一筹 。
Flame charts 灵感来源于火焰图,是跟火焰图相似的可视化方式。区别是,x轴并不是按照字母表的顺序排列,而是按照时间百分比排序。这样做的优势是:很容易发现时间相关的问题。但同时,缺点也很明显,这种排序减少了方法的合并,当分析多个线程时,劣势更加明显。Flame charts 跟火焰图一起使用应该会更有用。
Challenges
火焰图面临的挑战,更多是来自于profilers,而不是火焰图本身。profilers会面对两类典型的问题:
• Stack traces不完整。
有些profiler只提供固定深度(比如10)的采样,这种不完整的输出不利于分析,如果增大深度,这些profiler会直接失败。更糟糕的问题是有些编译器会使用“重用帧指针寄存器(frame pointer register)”这样的编译优化,破坏了标准Stack traces采样流程。解决方式是关闭这种编译器优化(比如gcc使用参数 -fno-omit-frame-pointer
)或者使用另一种采样技术。
• 方法名称丢失。
有些profilers,堆栈信息是完整的,但是方法名称却丢失了,显示为十六进制地址。使用了JIT (just-in-time) 技术编译的代码经常有这个问题。因为JIT并不会为profiler创建符号表。对于不同的profiler和runtime,这个问题有不同的解决方式,比如Linux perf_events允许应程序提供一个额外的符号表文件,用于产生采样结果。
我们在 Netflix 的工作过程中,曾经尝试为Java生成火焰图,结果两个问题都遇到了 。第一个问题通过一个新的jvm参数:—XX:+PreserveFramePointer
解决了。该参数禁用了编译器优化。第二个问题由perf-map-agent解决,这个Java agent可以为profiler生成符号表。
火焰图面临的另一个挑战是生成SVG文件的大小。一个超大的profile有可能会有成千上万的code paths,最终生成的svg可能有几十mb,浏览器加载要花费比较长的时间。解决方式是忽略掉在途中细到肉眼难以观察的方法,忽略这些方法不会影响全局视图,同时能缩小输出。
Other Color Schemes
除了使用随机的暖色调外,火焰图支持其他配色方案,比如使用颜色区分代码或者数据维度。
Perl版本的火焰图支持很多配色选项,其中一个选项是java。该选项通过不同颜色区分模块,规则如下:绿色代表Java,黄色为C++,红色用于所有其他用户代码,橙色用于内核模块。见图七(可交互的svg格式的图7可以在http://queue.acm.org/downloads/2016/Gregg7.svg 体验)。
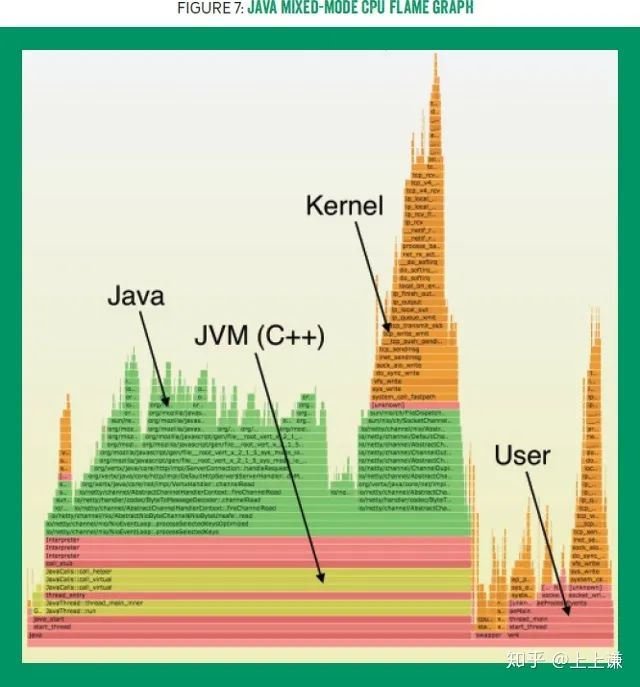
另一个可用的选项是hash,该选项根据函数名的hash选择颜色,这个选项在比较多张火焰图的时候非常有用,因为在不同的图片上,相同的方法会用相同的颜色表示。
颜色选项对于“差分火焰图”也很重要,“差分火焰图”将在下一节中介绍。
Differential Flame Graphs
差分火焰图显示了两个profile的区别。比如现在有两个profile A和B,Perl版本的火焰图支持这样的操作:以A为基准,使用B与A的差值生成一张火焰图。在差分火焰图上,红色代表差值为正数,蓝色代表差值为负数。这种差分图的问题是,如果A中的某个方法,在B中完全没有被调用,差分图就会把这种方法丢弃。丢失的数据会误导用户。
一种改进的方法是flamegraphdiff
,使用三张图解决这个问题。第一张是A,第二张是B,第三张是前边提到的差分图。当鼠标hover到任意一个方法时,三张图上该方法都会高亮显示。同时flamegraphdiff也支持红/蓝的配色方案说明百分比的增减。
Other Targets
前边提到,火焰图可以可视化多种profiler的输出。profiler有以下几种:CPU PMC (performance monitoring counter) 溢出事件, 静态追踪(static tracing) 事件, 动态追踪(dynamic tracing) 事件。下面是一些其他profiler的例子.
Stall Cycles
tall-cycle 火焰图显示被处理器或硬件资源(通常是内存I/O)block的代码路径。stack trace使用PMC profiler, 比如 Linux perf_events采集,分析这样的火焰图,开发人员可以使用其他策略优化代码,优化的目的是减少内存I/O,而不是减少指令。
CPI
CPI(cycles per instruction)指令每周期数, 或者其倒数IPC 可以描述cpu的使用情况。cpi火焰图用宽度表示采样cpu周期数,同时用颜色区分每个函数的cpi:红色表示高cpi,蓝色表示低cpi。cpi火焰图需要两个profile:CPU 采样 profile 和 指令数量 profile,使用差分火焰图技术生成。
Memory
火焰图可以通过可视化许多不同的内存事件来揭示内存增长。
通过跟踪 malloc() 方法可以生成 malloc火焰图,用于可视化申请内存的代码路径。这个方案可能很难应用与实践,因为malloc函数调用很频繁,使得在某些场景中跟踪它们的成本很高。
通过跟踪 brk()和 mmap()方法可以展示导致虚拟内存中的扩展的代码路径。当然如果异步的申请内存就另当别论了。这些方法调用频率很低,很适合追踪。
跟踪内存缺页异常可以展示导致物理内存中的扩展的代码路径。导致内存缺页的代码路径通常会频繁的申请内存。内存缺页异也是低频事件。
I/O
与io相关的问题,比如文件系统,存储设备和网络,通常可以使用system tracers方便的追踪。使用这类profiles生成的火焰图显示了使用I/O的代码路径。
在实践中,io火焰图可以定位导致io的原因。比如一个磁盘io可能由以下事件引起:应用程序发起系统调用,文件系统预读,异步的脏数据flush,或者内核异步的磁盘清理。通过火焰图上的代码路径可以区分以上导致磁盘io的事件类型。
Off-CPU
当然,也有许多问题使用上边提到的火焰图是看不见的。分析这些问题需要了解线程被阻塞(而不是on cpu)的时间。线程阻塞的原因有很多,比如等待I/O、锁、计时器、打开CPU以及等待分页或交换。追踪线程被重新调度时的stack traces可以区分这些原因,线程block的时间长度可以通过跟踪线程从离开CPU到返回CPU的时间来测量。系统profilers通常使用内核中的静态跟踪点来跟踪这些事件。
通过上边profile可以生成Off-CPU火焰图用来分析这类问题 。
Wakeups
在Off-CPU火焰图的应用中发现这样一个问题:当线程阻塞的原因是条件变量时,火焰图很难解答“为什么条件变量被其他线程持有这么长时间”这样的问题。
通过跟踪线程唤醒事件,可以生成Wakeups火焰图。该图显示了线程阻塞的原因。Wakeups火焰图可以与Off-CPU火焰图一起研究,以获得关于阻塞线程的更多信息。
Chain Graphs
持有条件变量的线程可能已在另一个条件变量(由另一个线程持有)上被阻塞。实际上,一个线程可能被第二个、第三个甚至第四个线程阻塞。对于这种复杂场景,只分析一个wakeup火焰图可能还不够。
chain 火焰图是分析这种复杂场景的一种尝试,chain 火焰图从off-CPU火焰图为基础,将Wakeups火焰图放到每个stack traces顶部。通过自顶向下的分析可以理解阻塞线程的整个条件变量链路。宽度对应线程block的时间。
chain 火焰图可以通过组合Off-CPU火焰图U和Wakeups火焰图来实现。这需要大量的采样,目前来看,在实际应用中不太现实。
Future Work
与火焰图相关的许多工作,都涉及到不同的profiler与不同的runtimes(例如,对于NoDE.JS、Ruby、Perl、Lua、Erlang、Python、Java、Gangangand,以及dTrof、PrimeEvices、PMCSTAT、Xperf、仪器)。等等)。将来可能会增加更多种类。
另一个正在开发的差分火焰图,称为白/黑差分,使用前面描述的单火焰图方案加上右侧的一个额外区域,用来显示丢失的代码路径。差分火焰图(任何类型)在未来也会得到更多的应用;在Netflix,我们正在努力让微服务每晚生成这些图:用来帮助进行性能问题分析。
其他几个火焰图实现正在开发中,探索不同的特性。比如:bla bla bla...bla bla bla...
Conclusion
火焰图是堆栈跟踪的可视化的高效工具,支持CPU以及许多其他profile。它创建了软件执行情况的可视地图,并允许用户导航到感兴趣的区域。与其他可视化技术相比,火焰图更直观的传递信息,在处理超大profile是优势明显。火焰图作为理解profile的基本工具,已经成功分析解决了无数的性能问题。
via https://zhuanlan.zhihu.com/p/73385693
