




本文从知识图谱的生命周期入手,介绍知识图谱中属性研究的若干重要问题及其代表性工作。

一、 背景知识
知识图谱是一种结构化的数据表示形式,用图结构建模事物之间的复杂关系、沉淀领域知识,近年来逐渐成为人工智能技术的一大基石,在信息检索、自然语言问答、推荐系统等任务中得到广泛应用。
知识图谱的图数据模型,通常包含RDF和属性图两大类。但无论选用哪种模型,一个典型的知识图谱中通常都包含两种信息:一种是表达多个实体间关系的关系条目,另一种是表达单个实体局部特征的属性条目。以RDF为例,根据三元组的宾语是实体还是字面属性值,RDF三元组可以分为关系三元组和属性三元组两大类,且均在知识图谱中发挥重要作用。而根据属性值类型的不同,属性条目又可以细分为文本属性、数值属性、离散类别、其他模态等小类。
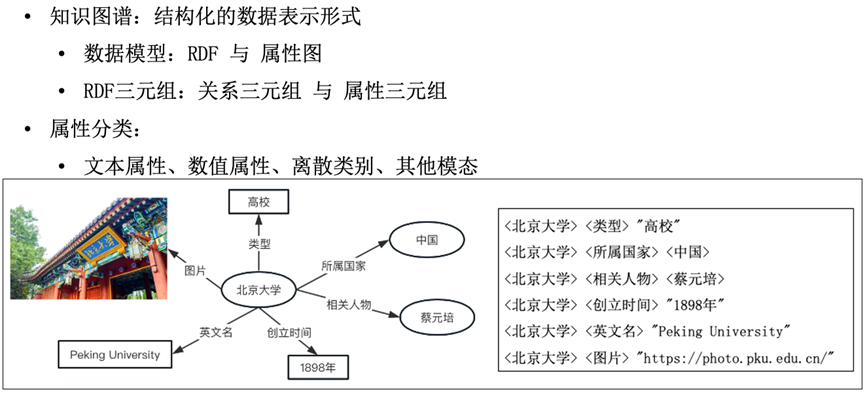
在知识图谱从形成到应用的过程中,逐渐形成了以“数据获取——知识图谱构建——知识图谱质量控制——知识图谱下游应用”为代表的典型流水线。与关系条目一样,属性信息的处理与应用也贯穿于知识图谱的整个生命周期,本文即沿着此生命周期,介绍知识图谱中与属性相关的几个重要研究问题,包括:属性抽取、属性质量控制、属性应用、多模态。
二、 属性抽取
属性抽取致力于从半结构或非结构化文本中识别出属性名和属性值,是信息抽取领域的一个重要任务。与实体识别和关系抽取任务类似,属性名和属性值的抽取也可以用诸如序列标注、分类等方法进行。但由于属性值往往语义更加复杂多样、新的属性名也在源源不断的出现,使得属性抽取任务也存在若干新的挑战。
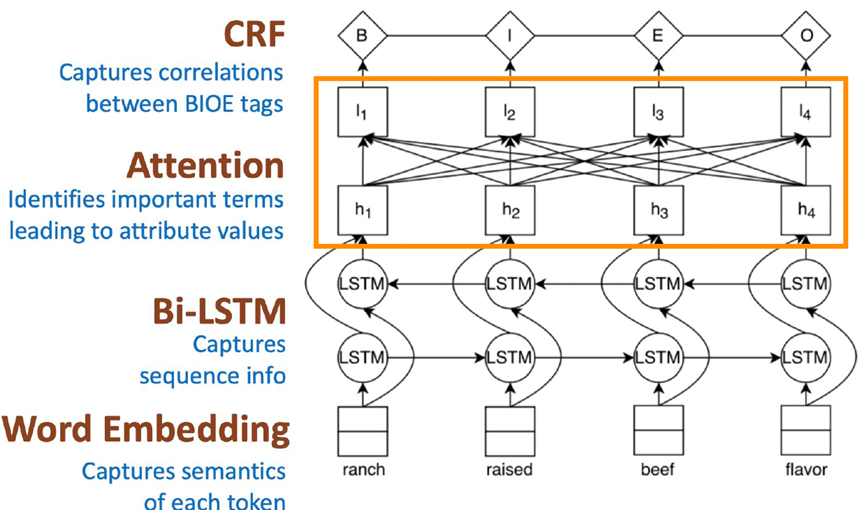
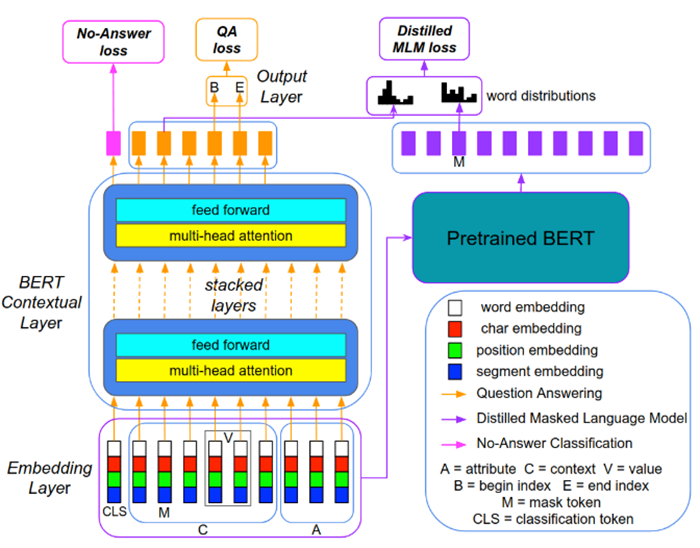
发表于2018年SigKDD上的OpenTag[1]是第一个把序列标注方法引入属性值抽取任务上的工作,摆脱了以往属性值抽取需要依赖手工模版或局限于封闭属性值的问题,并且它在经典的BiLSTM-CRF模型的基础上又增加了注意力机制以捕获解码阶段不同语块的重要性。模型整体结构如下图。
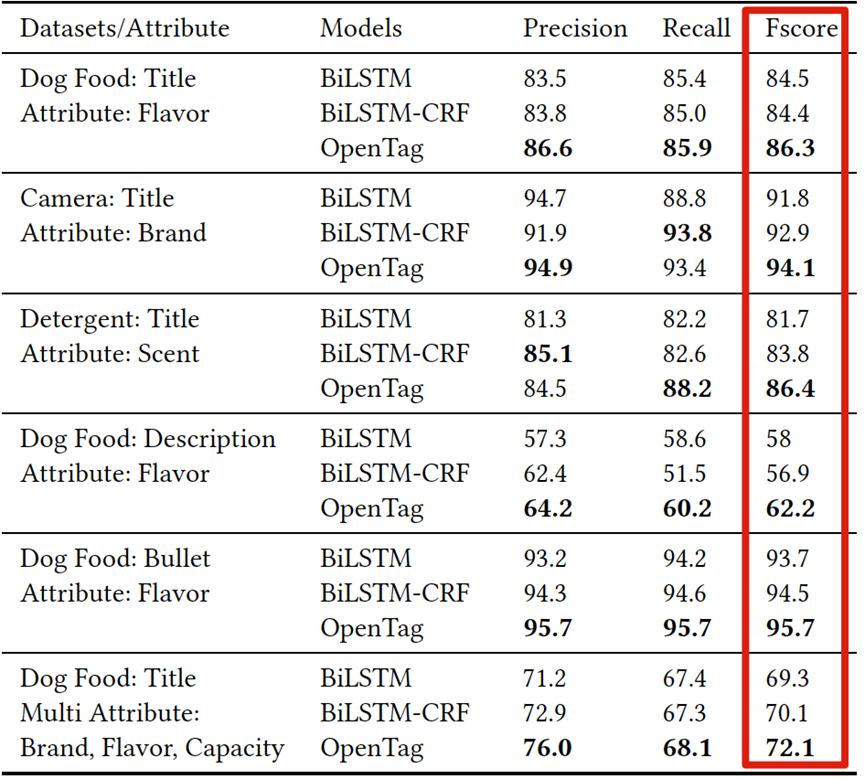
文章在三个品类商品的几种典型属性上进行了实验,F1值都有所提升。证明了序列标注方法在属性值抽取任务上的有效性,也证明了文章增加的注意力机制的作用。
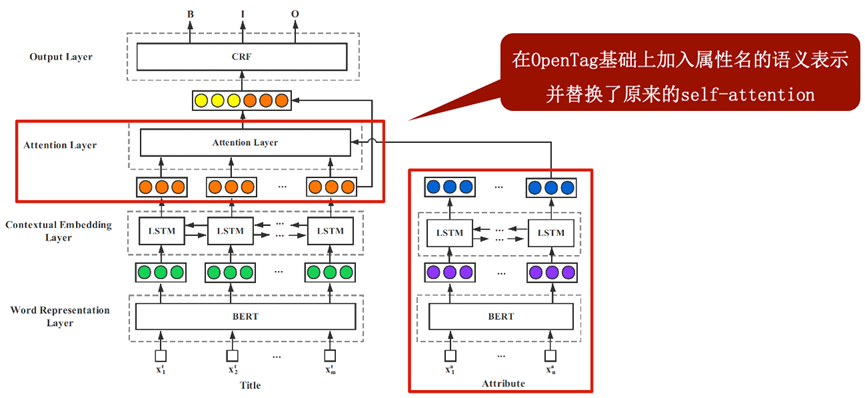
OpenTag使用序列标注方法取得了初步的成效,但它遗留了一个很大的问题:它需要为每种属性训练一个单独的模型,当待抽取的属性名很多,或者出现了新的属性名时,模型就难以应对或需要重新训练,方法的可扩展性和泛化性很有限。为此,有若干工作致力于对其改进,经典方法如SuOpenTag[2]、AVEQA[3]和AdaTag[4]。
SuOpenTag[2]也使用序列标注的方法进行属性值的抽取。但与为每种属性训练单独模型的OpenTag不同,SuOpenTag让所有属性共用一个模型。借鉴阅读理解任务的思路,SuOpenTag将文本语料作为上下文,将待抽取的属性名视为阅读理解任务中的问题,使用长短时记忆网络捕获各属性名的特征并通过注意力机制纳入属性值标签的预测中。
文章还构建了大规模的英文属性抽取数据集AE-650k和AE-110k。与以往在单个属性上训练的方法相比,属性抽取的准确率和召回率都有所提高,并且实验发现在更多不同属性数据上的训练还可以进一步提升抽取效果,说明不同属性之间可能存在一些语义共性。

发表于20年SigKDD上的AVEQA[3]使用问答方式进行属性值的抽取,它把此前建模上下文依赖关系的BiLSTM模型替换为了BERT,并加入两个新的损失:蒸馏掩码预测和无答案分类,以增强模型对零样本未见属性的泛化能力。三个任务进行联合训练,在AE-110k的4个高频属性上取得了更好的抽取结果,也大幅提高了对未见属性的抽取性能。
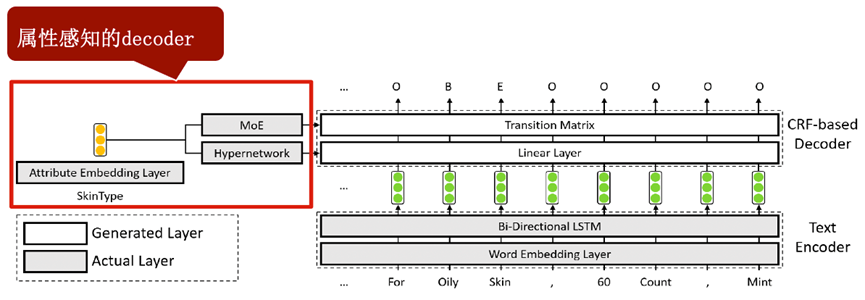
AdaTag[4]则提出在CRF解码的过程中,使用超网络和多专家模型(Mixture-of-Experts, MoE)得到属性感知的解码器,在协同训练保留各属性间共性的同时捕获不同属性的差异性。
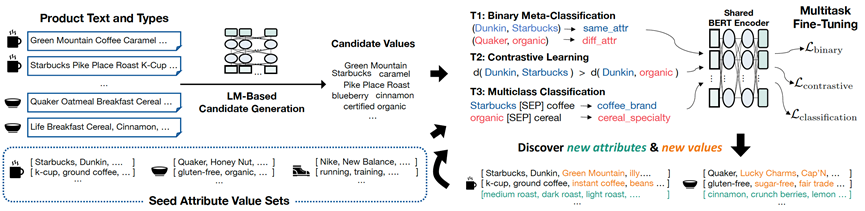
前面几篇工作都是在给定属性名的情况下对属性值进行抽取,但真实世界的很多场景中属性名并不总是已知,需要模型有从文本中同时获取属性名和属性值的能力。发表于WWW 2022的OA-Mine[5]提出了一个利用少量种子属性和预训练模型,在弱监督范式下挖掘新的属性名并抽取属性值的迭代框架。
三、 属性质量控制
知识图谱质量控制通常包括三大任务:一是质量评估,致力于从整体上把握数据质量,判断其是否适合具体任务使用;二是问题发现,如识别图谱中的错误和缺失,并尝试发现问题根源以从源头缓解问题;三是质量提升,如对发现的错误进行纠正、对重要的缺失信息进行补全等。属性在知识图谱的质量控制过程中也需要解决这些问题,这里重点介绍属性检错、纠错、补全的一些工作。
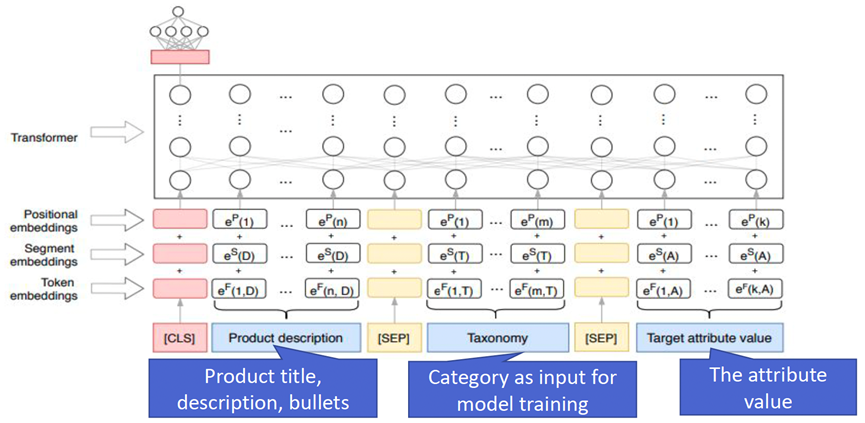
Autoknow[6]是亚马逊的一个自动化产品知识图谱构建系统,涵盖本体发现、数据抽取、数据清洗等多个模块。在其数据清洗模块中,使用Transformer结构对输入的产品描述文本、产品类别信息和属性值进行统一编码,在属性检错任务上取得了比传统的离群点检测方法更好的结果,证明了Transformer编码语义信息的有效性,也通过消融实验证明了产品类别信息在其中的作用。
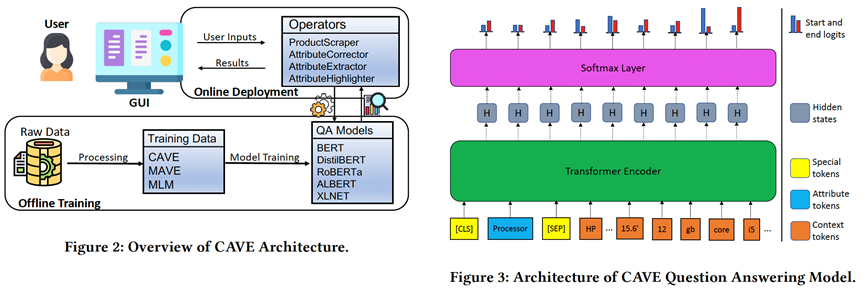
CAVE[7]是一个利用问答范式对商品属性值进行纠正和扩充的系统。该平台集成了若干在电商语料上预训练过的问答模型,并为用户提供了丰富的交互接口进行属性值的纠正、提取和不同商品属性比较等功能。
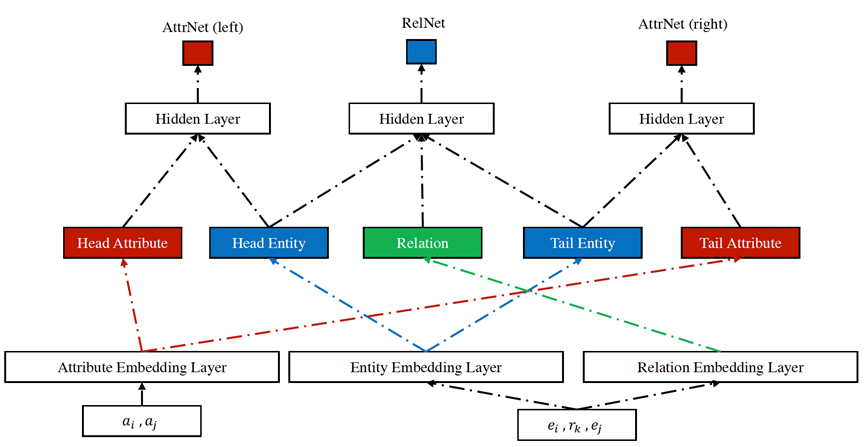
MT-KGNN[8]是一个较早对非离散的属性值进行预测和补全的工作。通过将属性值预测的损失纳入知识图谱嵌入表示的学习过程中,文章在关系三元组分类和属性值补全任务上都取得了更好的结果,证明属性信息能增强知识图谱表示学习,知识图谱的嵌入表示也可以帮助属性的预测,即关系和属性信息的学习推理可以实现相互促进。
四、 属性应用
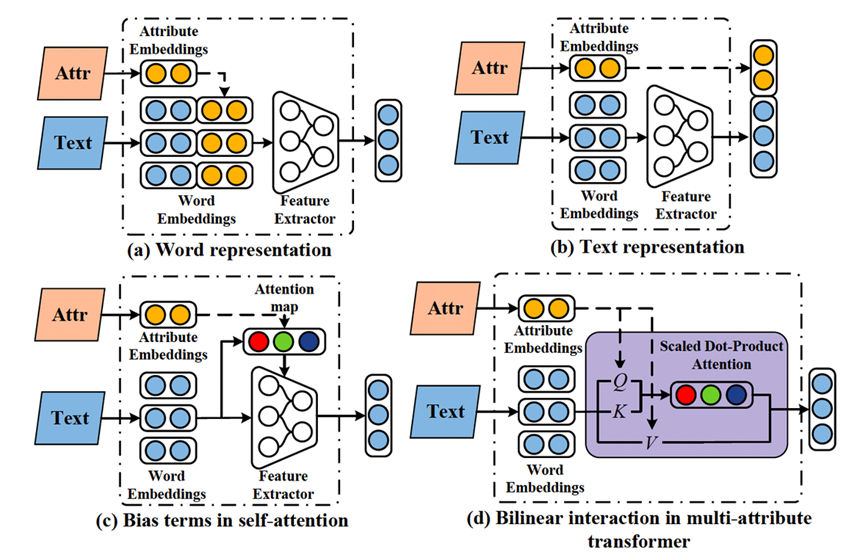
知识图谱中的属性有广泛的应用场景,如可以直接应用到电商领域的搜索、推荐、问答、商品比较等任务中;也可以在知识图谱表示学习的过程中丰富实体的语义特征;还可以在知识图谱之外,注入到其他自然语言处理任务中提升效果,如文章[9]总结了将结构化的属性信息注入情感分类任务的不同方式如下图。
五、 从文本属性到多模态
多模态技术的研究与落地在近年来得到了快速推进,多模态知识图谱的构建和应用也方兴未艾。多模态知识图谱通常有两种形态:一种是图片等其他模态信息作为实体的属性,另一种是多模态信息直接作为实体。由于属性能够将多种模态的信息以简单统一的方式加入知识图谱,可以视为知识图谱进军多模态领域的重要端口,近年来也有很多研究。
如京东在EMNLP 2020发布的JAVE[10] 构造了87k的中文多模态属性抽取数据集,并证明了将图片信息纳入属性名和属性值的联合抽取任务中能够提升效果。
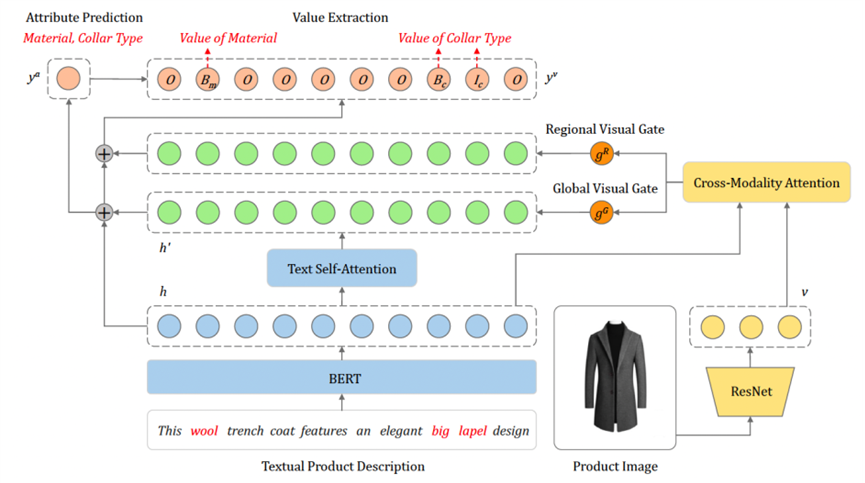
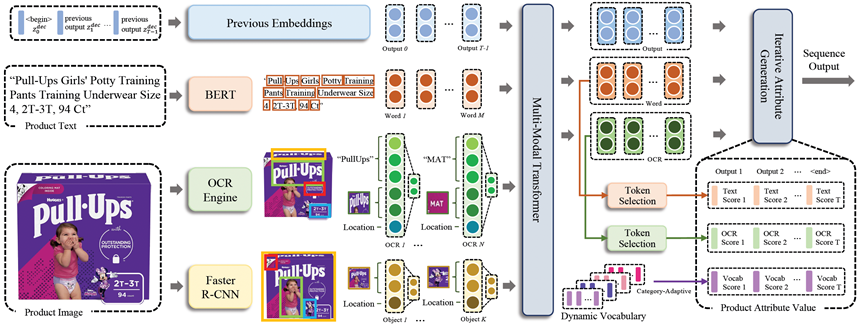
亚马逊发表于SigKDD 2021的PAM[11]也指出亚马逊网站有大约20%的商品属性只能从图片中获得,结合图片对象识别、OCR提取的文字、描述文本和商品类别信息,文章使用端到端的生成模型进行属性值的抽取并带来了性能的提升。
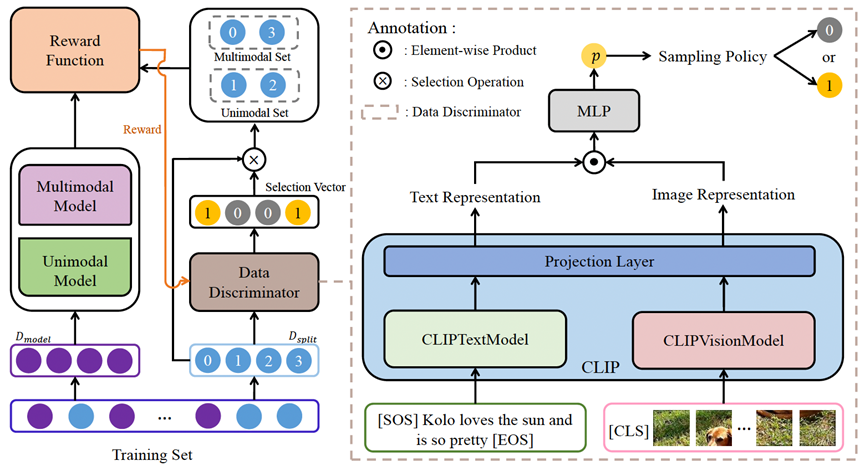
发表于COLING 2022的文章RDS[12]则提出,多模态信息未必总能提升任务效果,增加的图片等信息有时还可能带来噪音干扰。在社交媒体的信息抽取任务中,他们提出不同数据可能适合不同模型,有的数据适合单一模态,有的适合多模态,并提出了一个基于强化学习的数据划分策略,在实体识别和关系抽取任务上证明了效果。
六、 总结
本文对知识图谱属性研究中的若干问题及其代表性工作进行了回顾和介绍,希望能够对读者有所启发。
参考文献:


欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:http://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

