




联机分析处理OLAP是一种软件技术,它使分析人员能够迅速、一致、交互地从各个方面观察信息,以达到深入理解数据的目的。它具有FASMI(Fast Analysis of Shared Multidimensional Information),即共享多维信息的快速分析的特征。
OLAP场景的关键特征
大多数是读请求
数据总是以相当大的批(> 1000 rows)进行写入
不修改已添加的数据
每次查询都从数据库中读取大量的行,但是同时又仅需要少量的列
宽表,即每个表包含着大量的列
较少的查询(通常每台服务器每秒数百个查询或更少)
对于简单查询,允许延迟大约50毫秒
列中的数据相对较小:数字和短字符串(例如,每个URL 60个字节)
处理单个查询时需要高吞吐量(每个服务器每秒高达数十亿行)
事务不是必须的
对数据一致性要求低
每一个查询除了一个大表外都很小
查询结果明显小于源数据,换句话说,数据被过滤或聚合后能够被盛放在单台服务器的内存中
很容易可以看出,OLAP场景与其他流行场景(例如,OLTP或K/V)有很大的不同, 因此想要使用OLTP或Key-Value数据库去高效的处理分析查询是没有意义的,例如,使用OLAP数据库去处理分析请求通常要优于使用MongoDB或Redis去处理分析请求。
OLAP的基本操作
我们已经知道OLAP的操作是以查询——也就是数据库的SELECT操作为主,但是查询可以很复杂,比如基于关系数据库的查询可以多表关联,可以使用COUNT、SUM、AVG等聚合函数。OLAP正是基于多维模型定义了一些常见的面向分析的操作类型是这些操作显得更加直观。
OLAP的多维分析操作包括:钻取(Drill-down)、上卷(Roll-up)、切片(Slice)、切块(Dice)以及旋转(Pivot),下面还是以上面的数据立方体为例来逐一解释下:
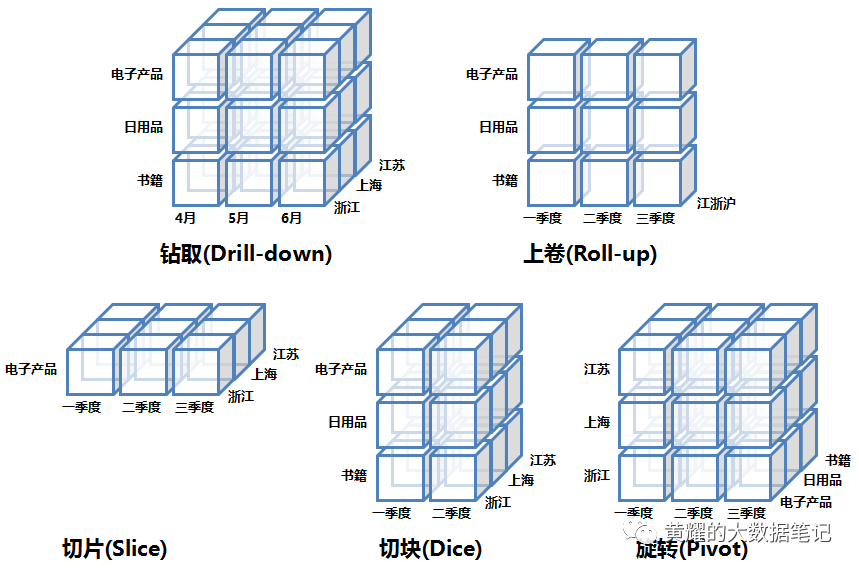
钻取(Drill-down):在维的不同层次间的变化,从上层降到下一层,或者说是将汇总数据拆分到更细节的数据,比如通过对2010年第二季度的总销售数据进行钻取来查看2010年第二季度4、5、6每个月的消费数据,如上图;当然也可以钻取浙江省来查看杭州市、宁波市、温州市……这些城市的销售数据。
上卷(Roll-up):钻取的逆操作,即从细粒度数据向高层的聚合,如将江苏省、上海市和浙江省的销售数据进行汇总来查看江浙沪地区的销售数据,如上图。
切片(Slice):选择维中特定的值进行分析,比如只选择电子产品的销售数据,或者2010年第二季度的数据。
切块(Dice):选择维中特定区间的数据或者某批特定值进行分析,比如选择2010年第一季度到2010年第二季度的销售数据,或者是电子产品和日用品的销售数据。
旋转(Pivot):即维的位置的互换,就像是二维表的行列转换,如图中通过旋转实现产品维和地域维的互换。
OLAP的优势
首先必须说的是,OLAP的优势是基于数据仓库面向主题、集成的、保留历史及不可变更的数据存储,以及多维模型多视角多层次的数据组织形式,如果脱离的这两点,OLAP将不复存在,也就没有优势可言。
数据展现方式
基于多维模型的数据组织让数据的展示更加直观,它就像是我们平常看待各种事物的方式,可以从多个角度多个层面去发现事物的不同特性,而OLAP正是将这种寻常的思维模型应用到了数据分析上。
查询效率
多维模型的建立是基于对OLAP操作的优化基础上的,比如基于各个维的索引、对于一些常用查询所建的视图等,这些优化使得对百万千万甚至上亿数量级的运算变得得心应手。
分析的灵活性
我们知道多维数据模型可以从不同的角度和层面来观察数据,同时可以用上面介绍的各类OLAP操作对数据进行聚合、细分和选取,这样提高了分析的灵活性,可以从不同角度不同层面对数据进行细分和汇总,满足不同分析的需求。
