




使用TPC-DS基准评估SQL-on-Hadoop系统的性能
2018年10月30日•成宇公园
MR3现在由DataMonad发布。
介绍
我们经常问有关SQL-on-Hadoop系统性能的问题:
Hive-LLAP与Presto,SparkSQL或Tez上的Hive相比有多快?
由于它是MPP风格的系统,如果成功执行查询,Presto会以最快的速度运行吗?
因为将中间数据存储在内存中,SparkSQL的运行速度通常是否比Hive on Tez快?
什么是运行并发查询的最佳系统?
…
尽管这些问题本身很有趣,但它们与想要采用最合适的技术来满足其需求的工业从业者特别相关。
互联网上有大量基准测试结果,但是我们仍然需要新的基准测试结果。由于所有SQL-on-Hadoop系统都在不断发展,因此格局逐渐变化,以前的基准测试结果可能已经过时。而且,基准测试中使用的硬件可能只支持某些系统,而可能根本没有配置系统来获得最佳性能。另一方面,TPC-DS基准仍然是衡量SQL-on-Hadoop系统性能的事实上的标准。
随着MR3 0.4的发布,我们报告了实验结果,以回答有关SQL-on-Hadoop系统的一些问题。结果绝不是确定的,但应阐明每个系统的位置以及它在SQL-on-Hadoop动态格局中的发展方向。特别是,结果可能与对Hive,Presto和SparkSQL的一些普遍看法相矛盾。
实验中使用的集群
我们在三个不同的群集中运行该实验:Red,Gold和Indigo。群集中的所有计算机都运行HDP(HortonWorks Data Platform)并共享以下属性:
2个Intel(R)Xeon(R)X5650 CPU
红色为192GB,金色和为靛蓝为96GB
6个500GB硬盘
10千兆网络连接
| 红色 | 金 | 靛青 | |
|---|---|---|---|
| Hadoop版本 | Hadoop 2.7.3(HDP 2.6.4) | Hadoop 2.7.3(HDP 2.6.4) | Hadoop 3.1.0(HDP 3.0.1) |
| 主节点数 | 1个 | 2 | 2 |
| 从节点数 | 10 | 40 | 19 |
| TPC-DS基准的比例因子 | 1TB | 10TB | 3TB |
| 从属节点上Yarn的内存大小 | 168GB | 84GB | 84GB |
| 安全 | 的Kerberos | 没有 | 没有 |
从站节点的内存总量为:
红色集群上10 * 196GB = 1960GB
黄金群集上40 * 96GB = 3840GB
Indigo群集上19 * 96GB = 1824GB
我们在Hadoop 2.7.3上使用HDFS复制因子3。
SQL-on-Hadoop系统进行比较
我们比较以下SQL-on-Hadoop系统。请注意,仅在Hadoop 3上正式支持Hive 3.1.0,因此我们修改了源代码,以便也可以在Hadoop 2.7.3上运行它。
在Red和Gold集群(基于Hadoop 2.7.3运行HDP 2.6.4)上:
HDP 2.6.4中包含的Hive-LLAP
Presto 0.203e(启用基于成本的优化)
HDP 2.6.4中包含的SparkSQL 2.2.0
Hive 3.1.0在Tez之上运行
在MR3 0.4上运行的Hive 3.1.0
Hive 2.3.3在MR3 0.4之上运行
在Indigo群集(基于Hadoop 3.1.0运行HDP 3.0.1)上:
HDP 3.0.1中包含的Hive-LLAP
Presto 0.208e(启用基于成本的优化)
HDP 3.0.1中包含的SparkSQL 2.3.1
HDP 3.0.1中包含的Hive on Tez
在MR3 0.4上运行的Hive 3.1.0
Hive 2.3.3在MR3 0.4之上运行
对于Hive-LLAP,我们使用Ambari设置的默认配置。LLAP守护程序在Red群集上使用160GB,在Gold和Indigo群集上使用76GB。ApplicationMaster在所有群集上使用4GB。
对于Presto,我们使用以下配置(在性能调整后选择):
# for the Red cluster
query.initial-hash-partitions 10
query.max-memory-per-node 120GB
query.max-total-memory-per-node 120GB
memory.heap-headroom-per-node 16GB
resources.reserved-system-memory 24GB
sink.max-buffer-size 20GB
node-scheduler.min-candidates 10
# for the Gold and Indigo clusters
query.initial-hash-partitions 40
query.max-memory-per-node 60GB
query.max-total-memory-per-node 60GB
memory.heap-headroom-per-node 8GB
resources.reserved-system-memory 12GB
sink.max-buffer-size 10GB
node-scheduler.min-candidates 40
# for all clusters
task.writer-count 4
node-scheduler.network-topology flat
optimizer.optimize-metadata-queries TRUE
join-distribution-type AUTOMATIC
optimizer.join-reordering-strategy COST_BASED/AUTOMATIC
Presto worker在Red群集上使用144GB,在Gold和Indigo群集上使用72GB(对于JVM -Xmx)。
对于SparkSQL,我们使用Ambari设置的默认配置,另外还将spark.sql.cbo.enabled
和spark.sql.cbo.joinReorder.enabled
设置为true。Spark Thrift Server使用以下选项:
--num-executors 19 --executor-memory 74g --conf spark.yarn.am.memory=74g
在红色集群上--num-executors 39 --executor-memory 72g --conf spark.yarn.am.memory=72g
在黄金集群上--num-executors 18 --executor-memory 72g --conf spark.yarn.am.memory=72g
在靛蓝集群上
对于蜂巢3.1.0和2.3.3,我们使用包含在MR3版本0.4(配置hive2/hive-site.xml
,hive5/hive-site.xml
,mr3/mr3-site.xml
,tez3/tez-site.xml
下conf/tpcds/
)。对于“ Tez上的Hive”,容器在Red群集上使用16GB,在Gold群集上使用10GB,在Indigo群集上使用8GB。对于MR3上的Hive,容器使用:
红色群集上为16GB,每个ContainerWorker中运行一个任务
Gold群集上20GB,每个ContainerWorker中最多运行两个任务
Indigo群集上40GB,每个ContainerWorkers中最多运行五个任务
第一部分:顺序测试的结果
在顺序测试中,我们使用Beeline或Presto客户端从TPC-DS基准提交99个查询。对于红色和金色集群,我们报告运行103个查询的结果,因为查询14、23、24和39分两个阶段进行。对于Indigo群集,我们报告运行99个查询的结果,因为Presto 0.208e不会拆分这四个查询,因此总共执行了99个查询。如果查询失败,我们将计算失败时间并继续进行下一个查询。我们为Red和Indigo集群(而不是Gold集群)上的每个查询设置3600秒的超时。
为了方便读者阅读,我们附上了三个表格,其中包含实验的原始数据。0秒的运行时间表示查询不会编译,负的运行时间(例如-639.367)意味着查询将在639.367秒内失败。这里是[ Google文档 ] 的链接。
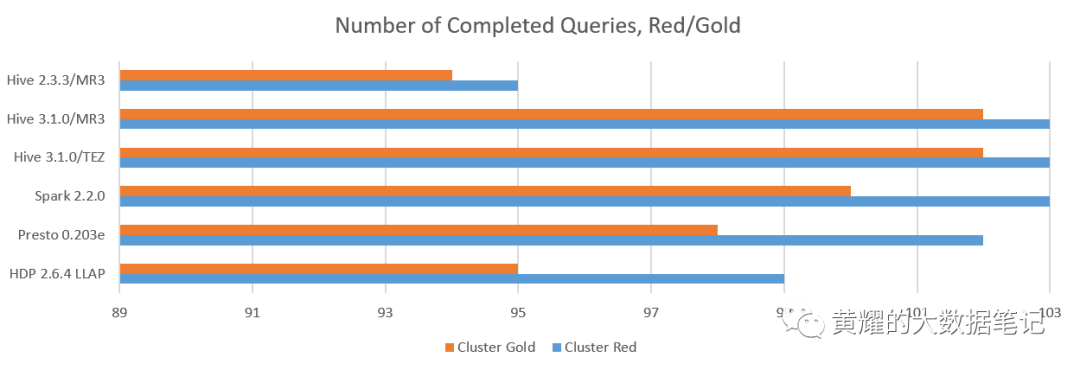
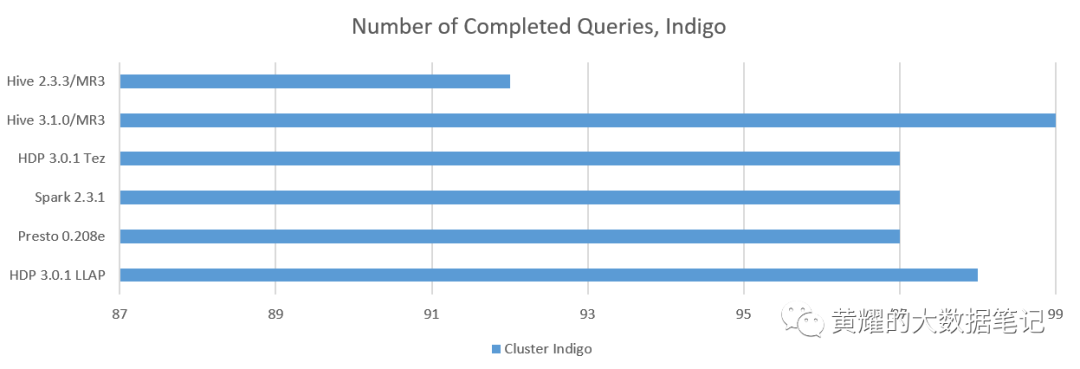
分析1.完成的查询数
我们计算成功返回答案的查询数:
这是摘要:
在Red群集上,MR3上的Hive 3.1.0,Tez上的Hive 3.1.0和SparkSQL 2.2.0完成了所有103个查询的执行。
在Gold群集上,MR3上的Hive 3.1.0和Tez上的Hive 3.1.0仅在查询16上失败,并完成了最多数量的查询。
在Indigo群集上,MR3上的Hive 3.1.0是唯一完成执行所有99个查询的系统。HDP 3.0.1的Hive-LLAP在查询78上失败,因为它在编译步骤后被卡住。
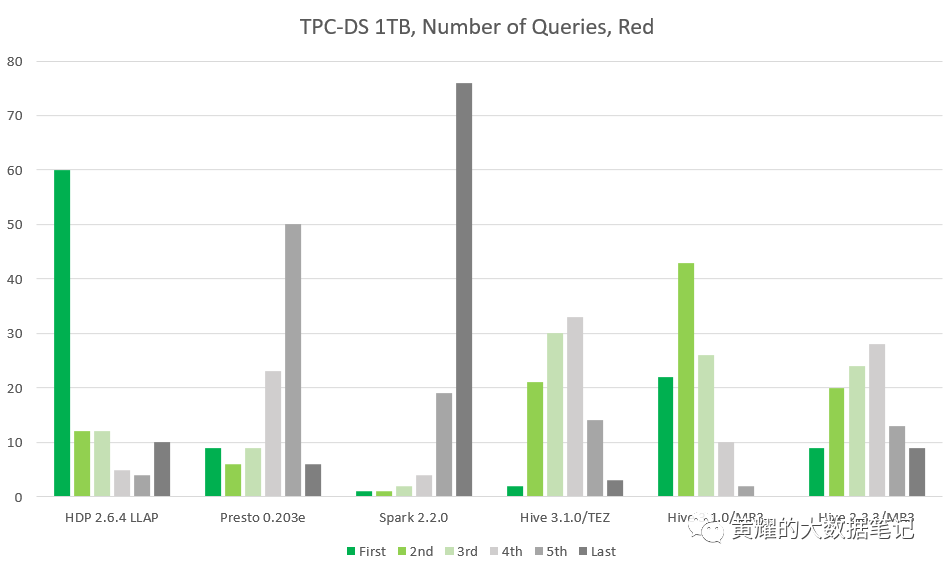
分析2.总运行时间
我们测量所有查询的总运行时间,无论是否成功:


不幸的是,很难从此结果进行公平的比较,因为并非所有系统在一组完整的查询中都是一致的。例如,MR3上的Hive 2.3.3在Red群集上花费了超过12,000秒,因为查询16和94在3600秒后超时并超时,因此占总运行时间的近三分之二。尽管如此,我们可以做一些有趣的观察:
MR3上的Hive 3.1.0在Red和Gold集群上以最快的速度完成了所有查询。特别是,与Tez上的Hive 3.1.0相比,它的总运行时间减少了25%至35%。减少特别重要,因为它部分证明了MR3作为Tez的替代执行引擎的效率。
在Indigo群集上,HDP 3.0.1的Hive-LLAP和MR3上的Hive 3.1.0是两个最快的系统。请注意,HDP 3.0.1的Hive-LLAP在查询78上失败,而MR3的Hive 3.1.0在其上花费了大约760秒。因此,它们的运行时间之间的间隔实际上仅约300秒。
在这三个集群中,SparkSQL是最慢的。这不是因为某些查询因超时而失败,而是因为几乎所有查询运行缓慢。
Tez上的Hive 3.1.0足够快,足以胜过Presto 0.203e和SparkSQL 2.2.0。同样,HDP 3.0.1中的Hive on Tez足够快,足以胜过Presto 0.208e和SparkSQL 2.3.1。
分析3.单个查询的排名
为了快速了解哪个系统可以回答查询,我们根据每个查询的运行时间对所有系统进行排名。对于正在考虑中的查询,将以最快的速度完成执行查询的系统分配到最高位置(第一)。如果系统未编译或无法完成执行查询,则会为所考虑的查询分配最低的位置(第6位)。这样,我们可以从最终用户而不是系统管理员的角度更准确地评估这六个系统。
这是红色集群的结果:
从左到右,该列对应于:HDP 2.6.4的Hive-LLAP,Presto 0.203e,SparkSQL 2.2.0,Tez上的Hive 3.1.0,MR3上的Hive 3.1.0,MR3上的Hive 2.3.3。
第一位到最后一位用深绿色(第一),绿色,浅绿色,浅灰色,灰色,深灰色(最后)着色。
Tez或MR3上的Hive通常在前几个查询中速度较慢,因为它没有活动容器,并且仅在提交第一个查询后才分配新容器。但是,其他系统从预热的容器/工人开始,因此倾向于在前几个查询中快速运行。
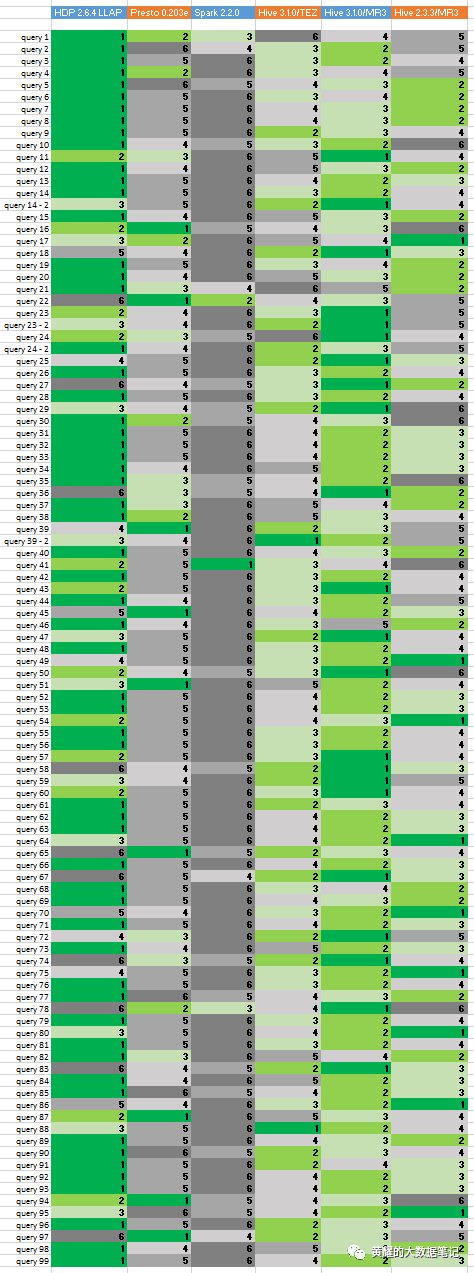
我们观察到HDP 2.6.4的Hive-LLAP在竞争中占主导地位:它在60个查询中排名第一,在12个查询中排名第二。接下来是MR3上的Hive 3.1.0,它首先进行22个查询,然后进行43个查询。Presto 0.203e在9个查询中排名第一,但在6个查询中仅排名第二。请注意,虽然Hive-LLAP在查询次数最多的情况下排在首位,但在10个查询的情况下也排在最后。相比之下,MR3上的Hive 3.1.0不会对任何查询放置最后一个。
从金牌集群中,出现了明显的变化:
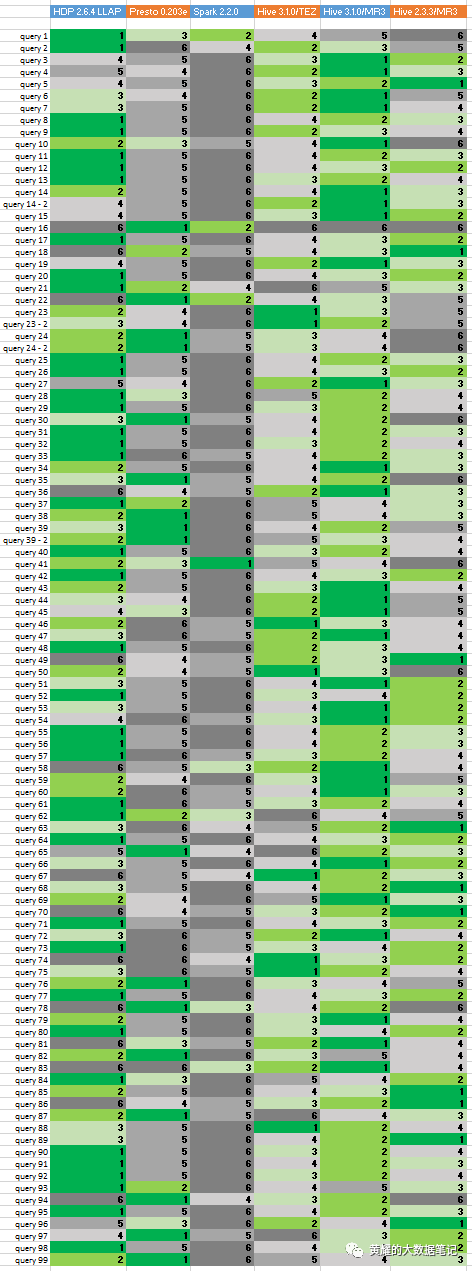
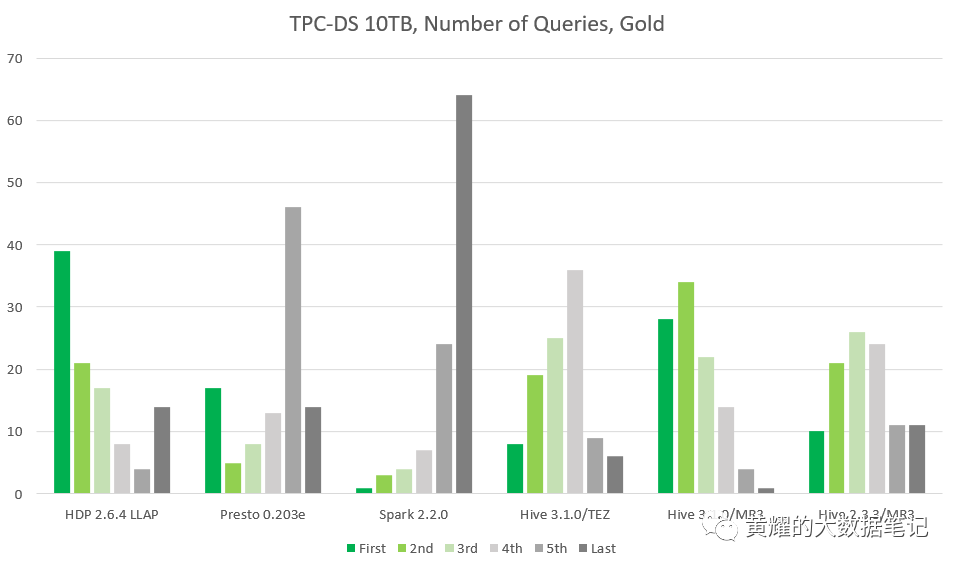
HDP 2.6.4的Hive-LLAP在查询数量最多的情况下仍排在首位(39个查询,在Red群集上为60个查询),但在最后14个查询(在Red群集上为10个查询)之后。MR3上的Hive 3.1.0在28个查询中排在首位,在34个查询中排在最后,仅在查询16中排在最后。(基于Hive的四个系统都在查询16上失败,而Presto 0.203e在139秒内完成。) MR3上的3.1.0与HDP 2.6.4的Hive-LLAP相当:MR3上的Hive 3.1.0在62个查询中位居第一或第二,而HDP 2.6.4的Hive-LLAP则在总查询中居第一或第二60个查询。顺便说一句,SparkSQL 2.2.0仅在Red和Gold集群上仅对查询41排名第一。
Indigo群集的结果对于Hive-LLAP和MR3上的Hive之间的比较特别重要,因为两个系统都基于相同版本的Hive,即Hive 3.1.0。Presto和SparkSQL也是较新的版本,因此结果比Red和Gold集群更准确地反映了每个SQL-on-Hadoop系统的当前状态。这是Indigo群集的结果:
从左到右,该列对应于:HDP 3.0.1的Hive-LLAP,Presto 0.208e,SparkSQL 2.3.1,Tez上的Hive 3.1.0,MR3上的Hive 3.1.0,MR3上的Hive 2.3.3。
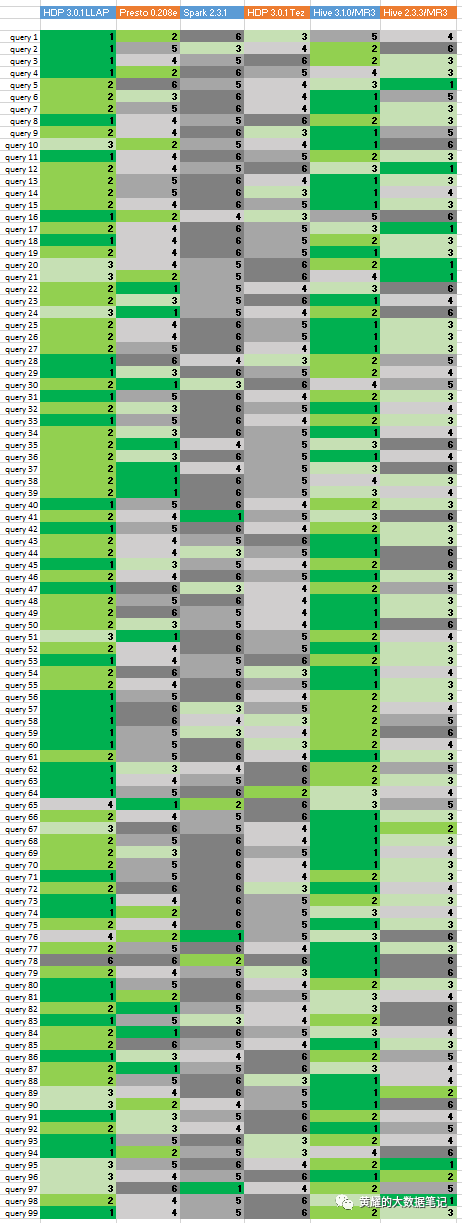
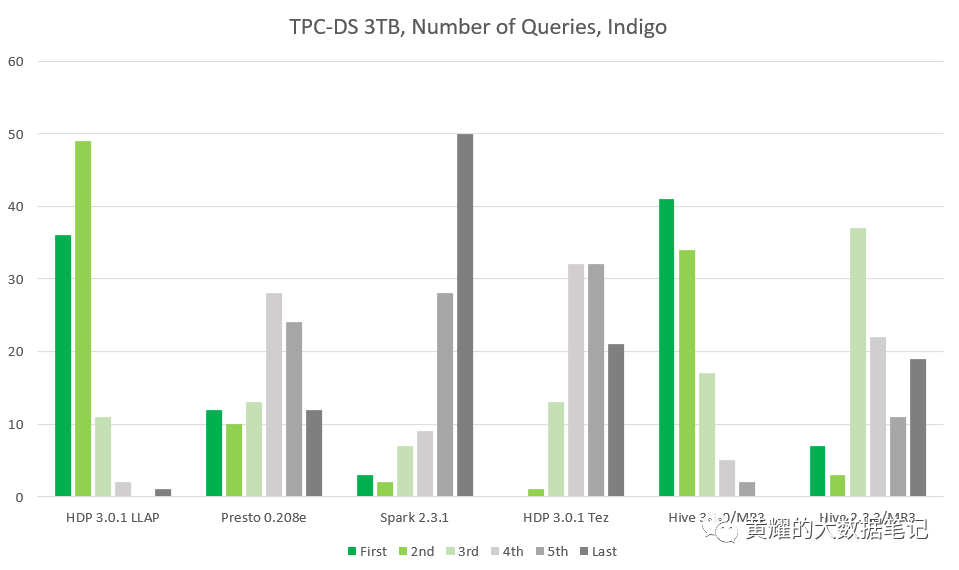
我们观察到,MR3上的Hive 3.1.0现在在性能上略高于HDP 3.0.1的Hive-LLAP:MR3上的Hive 3.1.0在41个查询中排名第一,在34个查询中排名第二,而HDP 3.0的Hive-LLAP排名第一。排名第一的是36个查询,第二个是49个查询。对于Presto .208e,与基于Presto .203e的先前结果没有太大差异。对于SparkSQL 2.3.1,它仍然是所有系统中最慢的。顺便说一句,它仍然排在查询41的首位。
顺序测试摘要
从上面的分析中,我们看到基于Hive的系统确实是SQL-on-Hadoop领域的强大竞争对手,不仅因为它们的稳定性和多功能性,而且现在还因为它们的速度。我们将顺序测试的结果总结如下:
Hive-LLAP和MR3上的Hive是两个最快的SQL-on-Hadoop系统。
在相同的配置下,MR3上的Hive运行速度比Tez上的Hive一致。
Presto稳定且运行速度比SparkSQL快得多,但平均速度不及Hive-LLAP或MR3上的Hive。
与Hive和Presto相比,运行在香草Spark之上的SparkSQL非常慢。我们的实验结果表明,在Hive或Presto随时可用的计算环境中,根本不需要使用SparkSQL。
第二部分 并发测试结果
为了检查SQL-on-Hadoop系统是否已准备好用于生产环境,我们应该在多个查询同时运行或通过并发测试的多用户环境中对其性能,稳定性和可伸缩性进行测试。在我们的实验中,我们选择8到16之间的并发级别,并启动尽可能多的Beeline或Presto客户端(从8个客户端到16个客户端),每个客户端都提交17个查询,查询25到查询40(根据TPC-DS基准) 。对于每次运行,我们都测量所有客户端的最长运行时间。由于群集在最后一个客户端完成所有查询的执行之前一直很忙,因此可以将最长的运行时间视为对所有客户端执行查询的成本。如果来自任何客户端的任何查询失败,则我们将整个运行视为失败。通过这种方式,
并发测试查询的选择相当随意,但对于我们的目的而言仍然是合理的。这是因为所比较的每个系统都成功完成了顺序测试中的所有17个查询。此外,该选择不包含长时间运行的查询(例如查询24),因此很适合进行并发测试。
分析1.运行时间
在红色和金色集群上,我们比较了三个系统:HDP 2.6.4的Hive-LLAP,Presto 0.203e和MR3的Hive 3.1.0。我们不比较SparkSQL 2.2.0,后者在顺序测试中太慢。并发级别为1的结果是从先前的顺序测试中获得的。最后两列显示相对于HDP 2.6.4和Presto 0.203e的Hive-LLAP,MR3上的Hive 3.1.0的运行时间减少了(百分比)。

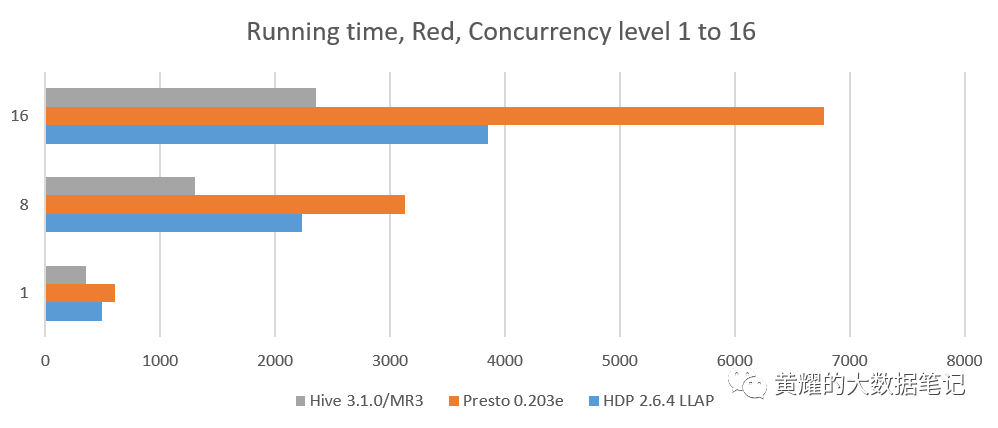

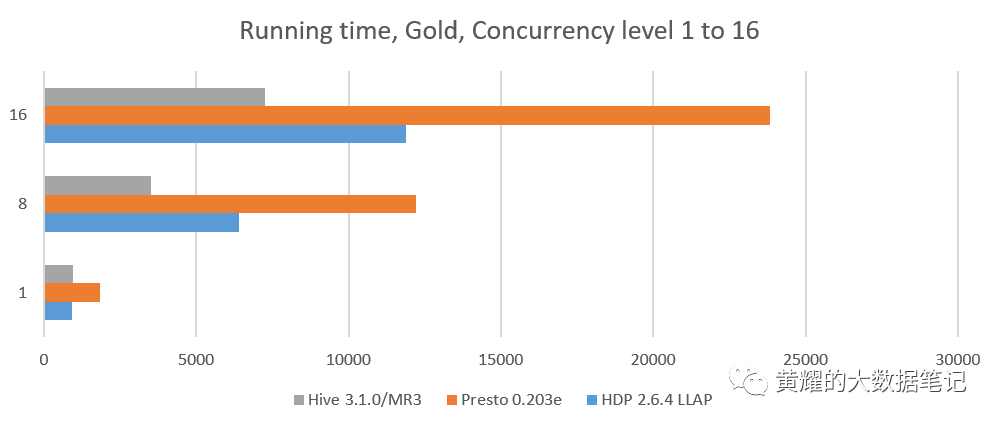
我们观察到,相对于HDP 2.6.4的Hive-LLAP,MR3上的Hive 3.1.0实现了运行时间的显着减少,吞吐量几乎翻了一番。请注意,由于并发级别较高,(每个HDP版本的)Hive-LLAP都会导致维护ApplicationMasters的大量开销,因为每个活动查询都需要专用的ApplicationMaster。例如,对于64的并发级别,Hive-LLAP仅就64个ApplicationMaster而言就消耗了64 * 2G = 128GB的内存(每个Hadoop被算作一个单独的作业)。MR3上的Hive没有这样的问题,因为单个DAGAppMaster足以管理所有并发查询。
在Indigo群集上,我们比较了四个系统:HDP 3.0.1的Hive-LLAP,Presto 0.208e,SparkSQL 2.3.1和MR3上的Hive 3.1.0。并发级别为1的结果是从先前的顺序测试中获得的。

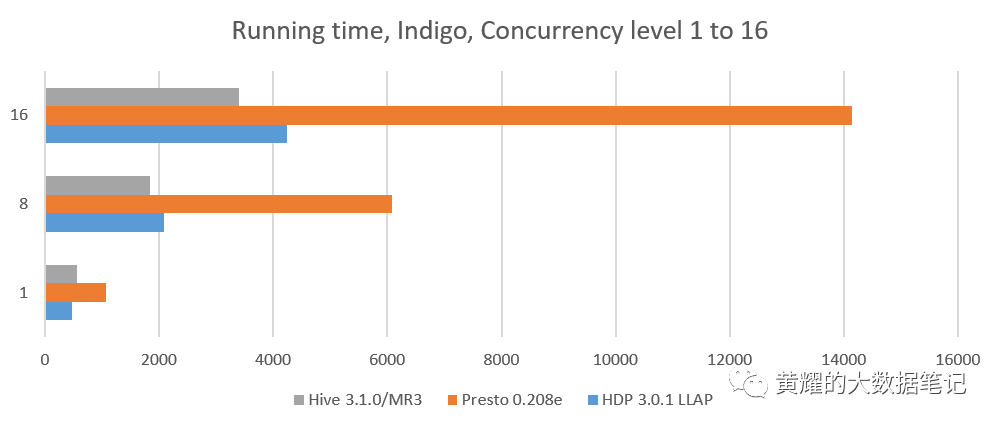
我们观察到MR3上的Hive仍然远远优于Hive-LLAP,尽管事实是单个客户端的顺序执行速度要慢17%。 此外,在更高的并发级别下,运行时间的减少变得更加明显,这表明MR3上的Hive表现出出色的可伸缩性。
分析2.并发因子
在我们的并发测试中,我们从运行时间中得出一个新指标,称为并发因子,用于量化管理并发查询的整体效率。
并发因子=并发测试中的运行时间/(并发级别*等效顺序测试中的运行时间)
因此,并发因子表示`` 相对于在顺序测试中(或在单用户环境中)完成同一查询的时间,在并发测试中(或在并发环境中)完成一个查询要花费多长时间 。'' 这里有一些例子:
并发系数为0.4意味着在顺序测试中花费100秒的查询在并发测试中平均花费40秒。
对于在优化并发查询方面没有优化并且仅串行执行所有传入查询的系统,我们获得的并发因子为1。Hiveon Tez的并发因子接近1,因为不同客户端之间的查询之间没有共享资源。
对于缓存来自客户端的查询结果并跳过从不同客户端执行同一查询的系统,有时我们会获得理想的并发因子“ 1 并发级别 ”。
hive.query.results.cache.enabled
设置为true的配置单元3 在特殊情况下可能会达到理想的并发因子。对于运行并发查询会产生过多开销的系统,我们可能会发现并发因子大于1。
并发因素是评估并发环境中的SQL-on-Hadoop系统的关键指标,因为它衡量管理并发查询的体系结构效率。请注意,它无法衡量执行管道消耗单个查询的效率。例如,在Hive中升级查询优化器对其并发因素影响不大,因为“并发测试中的运行时间”和“等效顺序测试中的运行时间”上面显示的公式中的系数将同样减少相同的因子。这意味着本地优化执行管道不太可能影响并发因子。然后我们得出结论,为了改善(即减少)并发因子,我们应该重新整理整个系统,这对于像Hive,Presto和SparkSQL这样的成熟系统在实践中特别昂贵。因此,在不久的将来,我们不会在任何这些系统中看到并发因子的重大变化。 本质上,并发因子主要由设计和体系结构确定,而不是由实现和优化确定。
以下是从并发测试得出的并发因素:
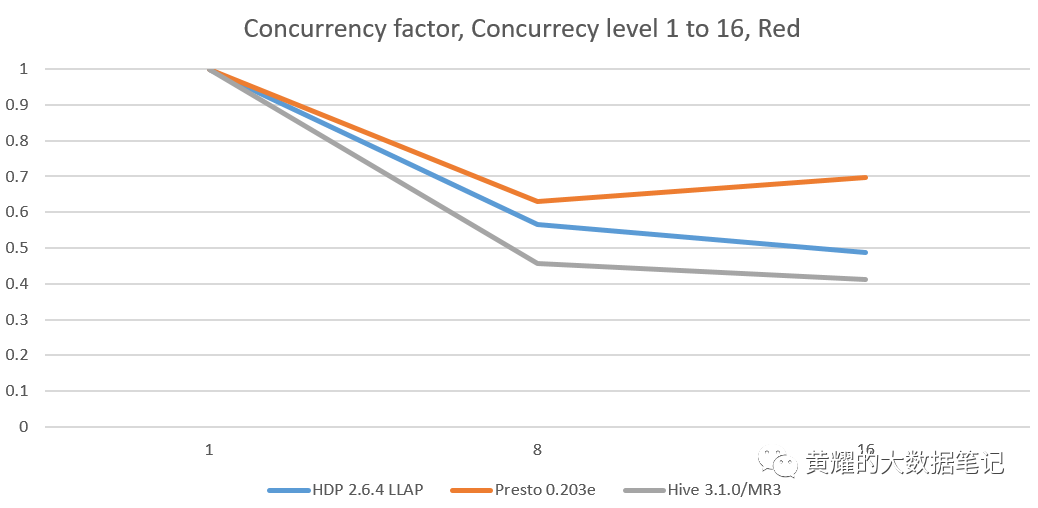
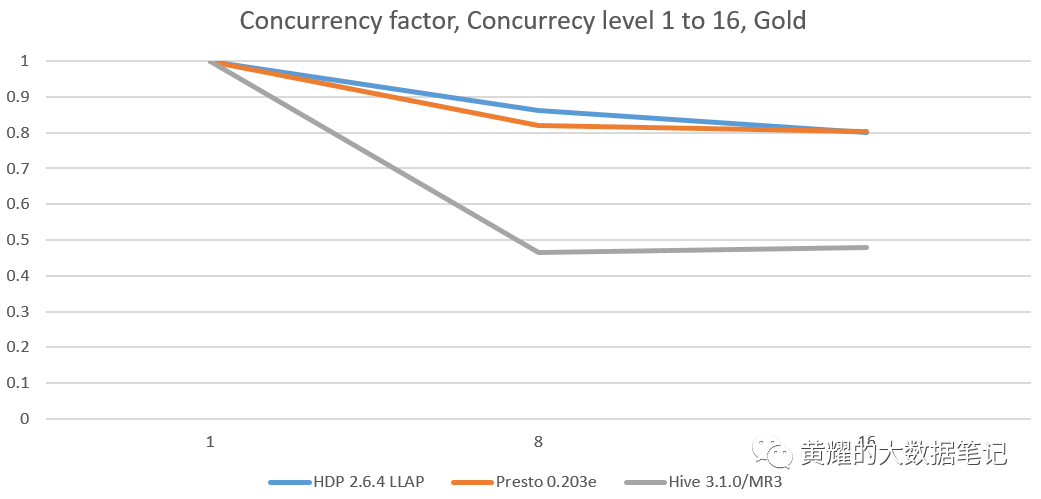
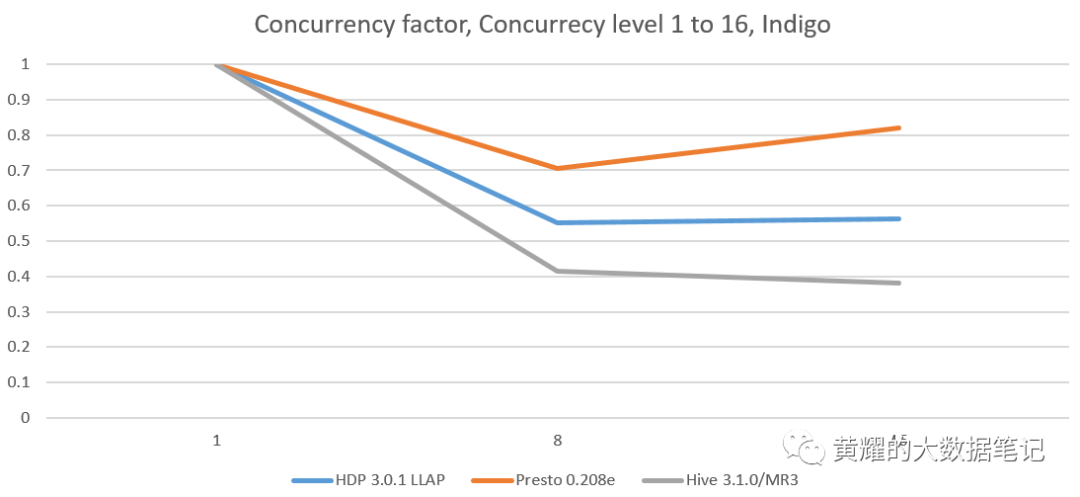
我们观察到,在每个并发测试中,MR3上的Hive都保持最低的并发因子,在所有集群中都保持在0.4左右。此外,其并发因子几乎保持不变,无论并发级别如何。在Red和Indigo群集上,它的并发因子甚至随着并发级别的增加而略有降低。
并发测试摘要
通过上面的分析,我们发现MR3上的Hive在性能上胜过其他竞争对手。它还显示了出色的可伸缩性。例如,MR3上的Hive在Red群集上成功扩展到并发级别128,而没有任何单个查询失败。从对并行因素的分析中可以明显看出,Hive在MR3上的优势来自MR3的设计和体系结构,而不是Hive的使用。毕竟,Hive-LLAP和MR3上的Hive共享相同的代码库来处理单个查询。(有关Hive-LLAP和MR3上的Hive之间的体系结构差异的更多详细信息,请向读者介绍以下页面: 与Hive-LLAP的比较。)我们总结并发测试的结果如下:
Hive on MR3是用于并发环境的最快的SQL-on-Hadoop系统。
与单用户环境一样,对于多用户环境(在香草Spark上运行时),SparkSQL并不是一个好的选择。具有讽刺意味的是,SparkSQL与曾经使Hive看起来像一只缓慢移动的乌龟的兔子相比,现在在比赛中远远落后于Hive。
结论
我们已经通过顺序测试和并发测试对几种流行的SQL-on-Hadoop系统进行了评估。根据读者的背景,实验结果可能与以前对Hive,Presto和SparkSQL的看法相矛盾。随着Hadoop上SQL的格局不断变化,将来我们将使用更新版本的Hadoop SQL系统更新实验结果。
