




点击上方“IT那活儿”公众号,关注后了解更多内容,不管IT什么活儿,干就完了!!!
Kingbase的安装包为ISO文件,需要将其进行挂在,mount kingbase-cluster.iso mnt。
yum groupinstall "X Window System"
yum groupinstall "GNOME Desktop" "Graphical Administration Tools"
注意:如果使用命令行的方式进行安装,可以不安装这些组件,使用 sh setup.sh -i console命令行安装方式,在此不再展示。
sys_basebackup -D $KINBGBASE_DATA -F p -X stream -R -c -h primary_ip -p 54321 -U system -W -P

注意事项:
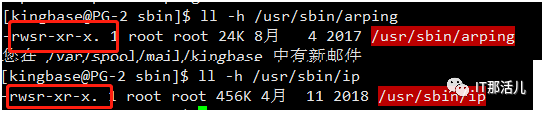
集群中要求各个主机之间可以免密登录。 repmgr 由于需要绑定VIP和解绑VIP,因此操作系统用户Kingbase需要有权限执行ip 和 arping命令,因此需要,修改命令的权限:
cd /usr/sbin
ll -h ip
ll -h arping
chmod 4755 ip
chmod 4755 arping
repmgr属于扩展插件,需要在数据库中安装,因此使用单独的数据库进行插件安装:
create database esrep;
\c esrep
create extension repmgr;
create user esrep with superuser login replication password 'esrep';
alter schema repmgr owner to esrep;
grant all on all tables in schema repmgr to esrep;
alter default privilege in schema repmgr grant all on tables to esrep;
用户esrep为superuser的原因,该用户在后期切换过程中需要执行CHECKPOINT和pg_promote函数,否则在做switchover的时候 出现以下报错信息 :
[kingbase@PG-2 etc]$ repmgr -f opt/Kingbase/ES/V8/Server/etc/repmgr.conf standby switchover
NOTICE: executing switchover on node "node121" (ID: 2)
NOTICE: local node "node121" (ID: 2) will be promoted to primary; current primary "node120" (ID: 1) will be demoted to standby
NOTICE: stopping current primary node "node120" (ID: 1)
NOTICE: issuing CHECKPOINT
ERROR: unable to execute CHECKPOINT
DETAIL:
错误: 只有超级用户可以做 CHECKPOINT
NOTICE: node (ID: 1) release the virtual ip XXX.XXX.163.210/24 success
DETAIL: executing server command "/opt/Kingbase/ES/V8/Server/bin/sys_ctl -D '/data/kingbase' -l opt/Kingbase/ES/V8/Server/bin/logfile -W -m fast stop"
INFO: checking for primary shutdown; 1 of 60 attempts ("shutdown_check_timeout")
INFO: checking for primary shutdown; 2 of 60 attempts ("shutdown_check_timeout")
NOTICE: current primary has been cleanly shut down at location 0/309D938
NOTICE: PING XXX.XXX.163.210 (XXX.XXX.163.210) 56(84) bytes of data.
--- XXX.XXX.163.210 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 1000ms
WARNING: ping host"XXX.XXX.163.210" failed
DETAIL: average RTT value is not greater than zero
INFO: loadvip result: 1, arping result: 1
NOTICE: new primary node (ID: 2) acquire the virtual ip XXX.XXX.163.210/24 success
NOTICE: promoting standby to primary
DETAIL: promoting server "node121" (ID: 2) using sys_promote()
ERROR: unable to execute pg_promote()
DETAIL:
错误: 对函数 pg_promote 权限不够
DETAIL: query text is:
SELECT pg_catalog.pg_promote(wait := FALSE)
ERROR: unable to promote server from standby to primary
on_bmj=off
node_id=1
node_name='node120'
promote_command='/opt/Kingbase/ES/V8/Server/bin/repmgr standby promote -f opt/Kingbase/ES/V8/Server/etc/repmgr.conf'
follow_command='/opt/Kingbase/ES/V8/Server/bin/repmgr standby follow -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf -W --upstream-node-id=%n'
conninfo='host=XXX.XXX.163.120 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3'
data_directory='/data/kingbase'
sys_bindir='/opt/Kingbase/ES/V8/Server/bin'
ssh_options='-q -o ConnectTimeout=10 -o StrictHostKeyChecking=no -o ServerAliveInterval=2 -o ServerAliveCountMax=5 -p 22'
reconnect_attempts=5
reconnect_interval=2
connection_check_type='ping'
failover='automatic'
recovery='automatic'
priority=100
monitoring_history='no'
trusted_servers='XXX.XXX.122.1'
virtual_ip='XXX.XXX.163.254/24'
net_device='ens33'
net_device_ip='XXX.XXX.163.120'
ipaddr_path='/usr/sbin'
arping_path='/usr/sbin'
replication_user='repmgr'
replication_type='physical'
use_replication_slots=true
passfile='/home/kingbase/.encpwd'
location='my-repmgr'
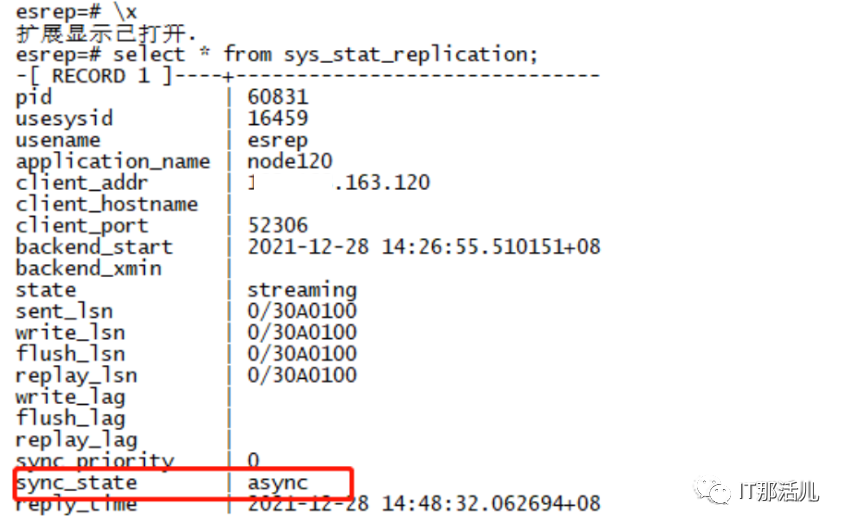
synchronous='async'
repmgrd_pid_file='/opt/Kingbase/ES/V8/Server/etc/hamgrd.pid'
kbha_pid_file='/opt/Kingbase/ES/V8/Server/etc/kbha.pid'
ping_path='/usr/bin'
auto_cluster_recovery_level=1
use_check_disk=off
log_level='INFO'
log_facility='STDERR'
log_file='/opt/Kingbase/ES/V8/Server/etc/hamgr.log'
kbha_log_file='/opt/Kingbase/ES/V8/Server/etc/kbha.log'
[kingbase@PG-1 ~]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf primary register
INFO: connecting to primary database...
INFO: "repmgr" extension is already installed
NOTICE: PING XXX.XXX.163.210 (XXX.XXX.163.210) 56(84) bytes of data.
--- XXX.XXX.163.210 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 1001ms
WARNING: ping host"XXX.XXX.163.210" failed
DETAIL: average RTT value is not greater than zero
INFO: loadvip result: 1, arping result: 1
NOTICE: node (ID: 1) acquire the virtual ip XXX.XXX.163.210/24 success
NOTICE: primary node record (ID: 1) registered
kbha -A daemon -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf
on_bmj=off
node_id=2
node_name='node121'
promote_command='/opt/Kingbase/ES/V8/Server/bin/repmgr standby promote -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf'
follow_command='/opt/Kingbase/ES/V8/Server/bin/repmgr standby follow -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf -W --upstream-node-id=%n'
conninfo='host=XXX.XXX.163.121 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3'
data_directory='/data/kingbase'
sys_bindir='/opt/Kingbase/ES/V8/Server/bin'
ssh_options='-q -o ConnectTimeout=10 -o StrictHostKeyChecking=no -o ServerAliveInterval=2 -o ServerAliveCountMax=5 -p 22'
reconnect_attempts=5
reconnect_interval=2
connection_check_type='ping'
failover='automatic'
recovery='automatic'
priority=100
monitoring_history='no'
trusted_servers='XXX.XXX.122.1'
virtual_ip='XXX.XXX.163.254/24'
net_device='ens33'
net_device_ip='XXX.XXX.163.121'
ipaddr_path='/usr/sbin'
arping_path='/usr/sbin'
replication_user='repmgr'
replication_type='physical'
use_replication_slots=true
passfile='/home/kingbase/.encpwd'
location='my-repmgr'
synchronous='async'
repmgrd_pid_file='/opt/Kingbase/ES/V8/Server/etc/hamgrd.pid'
kbha_pid_file='/opt/Kingbase/ES/V8/Server/etc/kbha.pid'
ping_path='/usr/bin'
auto_cluster_recovery_level=1
use_check_disk=off
log_level='INFO'
log_facility='STDERR'
log_file='/opt/Kingbase/ES/V8/Server/etc/hamgr.log'
kbha_log_file='/opt/Kingbase/ES/V8/Server/etc/kbha.log'
[kingbase@PG-2 etc]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf standby register
INFO: connecting to local node "node121" (ID: 2)
INFO: connecting to primary database
WARNING: --upstream-node-id not supplied, assuming upstream node is primary (node ID 1)
ERROR: local node not attached to primary node 1
HINT: specify the actual upstream node id with --upstream-node-id, or use -F/--force to continue anyway
[kingbase@PG-2 etc]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf standby register -F
INFO: connecting to local node "node121" (ID: 2)
INFO: connecting to primary database
WARNING: --upstream-node-id not supplied, assuming upstream node is primary (node ID 1)
WARNING: local node not attached to primary node 1
NOTICE: -F/--force supplied, continuing anyway
INFO: standby registration complete
NOTICE: standby node "node121" (ID: 2) successfully registered
kbha -A daemon -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf
[kingbase@PG-2 etc]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+-----------+----------+----------+----------+-----------------------------------------------------------------------------------------------------------------------------------------------------
1 | node120 | primary | * running | | default | 100 | 1 |
host=XXX.XXX.163.120 user=esrep dbname=esrep port=54321
connect_timeout=10 keepalives=1 keepalives_idle=10
keepalives_interval=1 keepalives_count=3
2 | node121 | standby | running | ! node120 | default | 100
| 1 | host=XXX.XXX.163.121 user=esrep dbname=esrep
port=54321 connect_timeout=10 keepalives=1
keepalives_idle=10 keepalives_interval=1 keepalives_count=3
WARNING: following issues were detected
- node "node121" (ID: 2) is not attached to its upstream node "node120" (ID: 1)
[kingbase@PG-2 etc]$ repmgr --help
repmgr: replication management tool for Kingbase
repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf standby follow --upstream-node-id 1
repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf standby clone -U esrep -d repmgr -h XXX.XXX.163.120 --upstream-node-id 1
repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf standby register --upstream-node-id 1
[kingbase@PG-2 etc]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf standby follow --upstream-node-id 1
INFO: timelines are same, this server is not ahead
DETAIL: local node lsn is 0/309D658, follow target lsn is 0/309D658
NOTICE: setting node 2's upstream to node 1
NOTICE: begin to stopp server at 2021-12-28 14:14:01.097086
NOTICE: stopping server using "/opt/Kingbase/ES/V8/Server/bin/sys_ctl -D '/data/kingbase' -l /opt/Kingbase/ES/V8/Server/bin/logfile -w -t 90 -m fast stop"
NOTICE: stopp server finish at 2021-12-28 14:14:01.203263
NOTICE: begin to start server at 2021-12-28 14:14:01.203421
NOTICE: starting server using "/opt/Kingbase/ES/V8/Server/bin/sys_ctl -w -t 90 -D '/data/kingbase' -l /opt/Kingbase/ES/V8/Server/bin/logfile start"
NOTICE: start server finish at 2021-12-28 14:14:01.331299
NOTICE: STANDBY FOLLOW successful
DETAIL: standby attached to upstream node "node120" (ID: 1)
[kingbase@PG-2 etc]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+-----------------------------------------------------------------------------------------------------------------------------------------------------
1 | node120 | primary | * running | | default | 100 | 1 |
host=XXX.XXX.163.120 user=esrep dbname=esrep port=54321
connect_timeout=10 keepalives=1 keepalives_idle=10
keepalives_interval=1 keepalives_count=3
2 | node121 | standby | running | node120 | default | 100 | 1 | host=XXX.XXX.163.121 user=esrep dbname=esrep port=54321
connect_timeout=10 keepalives=1 keepalives_idle=10
keepalives_interval=1 keepalives_count=3
[kingbase@PG-2 etc]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+-----------------------------------------------------------------------------------------------------------------------------------------------------
1 | node120 | primary | * running | | default | 100 | 1 | host=XXX.XXX.163.120 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2 | node121 | standby | running | node120 | default | 100 | 1 | host=XXX.XXX.163.121 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
[kingbase@PG-2 etc]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf standby switchover
NOTICE: executing switchover on node "node121" (ID: 2)
NOTICE: local node "node121" (ID: 2) will be promoted to primary; current primary "node120" (ID: 1) will be demoted to standby
NOTICE: stopping current primary node "node120" (ID: 1)
NOTICE: issuing CHECKPOINT
NOTICE: node (ID: 1) does not hold the virtual ip XXX.XXX.163.210/24 before we release it
DETAIL: executing server command "/opt/Kingbase/ES/V8/Server/bin/sys_ctl -D '/data/kingbase' -l /opt/Kingbase/ES/V8/Server/bin/logfile -W -m fast stop"
INFO: checking for primary shutdown; 1 of 60 attempts ("shutdown_check_timeout")
INFO: checking for primary shutdown; 2 of 60 attempts ("shutdown_check_timeout")
NOTICE: current primary has been cleanly shut down at location 0/309E468
NOTICE: PING XXX.XXX.163.210 (XXX.XXX.163.210) 56(84) bytes of data.
--- XXX.XXX.163.210 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1000ms
rtt min/avg/max/mdev = 0.037/0.091/0.145/0.054 ms
INFO: found vip on local host, need to do arping
INFO: loadvip result: 1, arping result: 1
NOTICE: new primary node (ID: 2) acquire the virtual ip XXX.XXX.163.210/24 success
NOTICE: promoting standby to primary
DETAIL: promoting server "node121" (ID: 2) using sys_promote()
NOTICE: waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete
NOTICE: STANDBY PROMOTE successful
DETAIL: server "node121" (ID: 2) was successfully promoted to primary
NOTICE: issuing CHECKPOINT
INFO: local node 1 can attach to rejoin target node 2
DETAIL: local node's recovery point: 0/309E468; rejoin target node's fork point: 0/309E4E0
NOTICE: setting node 1's upstream to node 2
WARNING: unable to ping "host=XXX.XXX.163.120 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3"
DETAIL: PQping() returned "PQPING_NO_RESPONSE"
NOTICE: begin to start server at 2021-12-28 14:26:55.452867
NOTICE: starting server using "/opt/Kingbase/ES/V8/Server/bin/sys_ctl -w -t 90 -D '/data/kingbase' -l /opt/Kingbase/ES/V8/Server/bin/logfile start"
NOTICE: start server finish at 2021-12-28 14:26:55.564191
NOTICE: replication slot "repmgr_slot_2" deleted on node 1
NOTICE: NODE REJOIN successful
DETAIL: node 1 is now attached to node 2
NOTICE: switchover was successful
DETAIL: node "node121" is now primary and node "node120" is attached as standby
INFO: no repmgrd running on all reachable nodes, do not try to unpause repmgrd
NOTICE: STANDBY SWITCHOVER has completed successfully
[kingbase@PG-2 etc]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+-----------------------------------------------------------------------------------------------------------------------------------------------------
1 | node120 | standby | running | node121 | default | 100 | 1 | host=XXX.XXX.163.120 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2 | node121 | primary | * running | | default | 100 | 2 | host=XXX.XXX.163.121 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
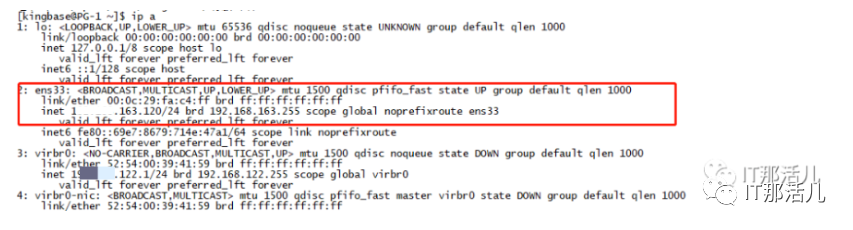
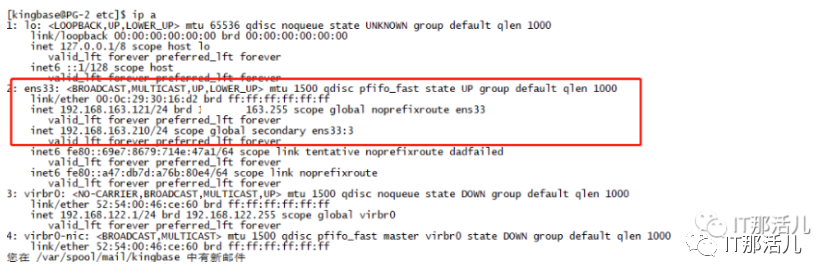
新主库正常加载VIP。
repmgr --config /opt/Kingbase/ES/V8/Server/etc/repmgr.conf
node rejoin -d "
host=XXX.XXX.163.121 user=esrep dbname=esrep
port=54321"
--force-rewind
sys_ctl stop $KINGBASE_DATA

[kingbase@PG-1 ~]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+-----------------------------------------------------------------------------------------------------------------------------------------------------
1 | node120 | primary | * running | | default | 100 | 5 |
host=XXX.XXX.163.120 user=esrep dbname=esrep port=54321
connect_timeout=10 keepalives=1 keepalives_idle=10
keepalives_interval=1 keepalives_count=3
2 | node121 | standby | - failed | node120 | default | 100 |
? | host=XXX.XXX.163.121 user=esrep dbname=esrep port=54321
connect_timeout=10 keepalives=1 keepalives_idle=10
keepalives_interval=1 keepalives_count=3
WARNING: following issues were detected
- unable to connect to node "node121" (ID: 2)
[kingbase@PG-2 ~]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+-----------------------------------------------------------------------------------------------------------------------------------------------------
1 | node120 | primary | * running | | default | 100 | 5 | host=XXX.XXX.163.120 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2 | node121 | standby | running | node120 | default | 100 |
5 | host=XXX.XXX.163.121 user=esrep dbname=esrep port=54321
connect_timeout=10 keepalives=1 keepalives_idle=10
keepalives_interval=1 keepalives_count=3
[kingbase@PG-2 kingbase]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf -D /data/kingbase standby clone -h XXX.XXX.163.120 -U system -d esrep
NOTICE: destination directory "/data/kingbase" provided
INFO: connecting to source node
DETAIL: connection string is: host=XXX.XXX.163.120 user=system dbname=esrep
DETAIL: current installation size is 935 MB
NOTICE: checking for available walsenders on the source node (2 required)
NOTICE: checking replication connections can be made to the source server (2 required)
WARNING: directory "/data/kingbase" exists but is not empty
ERROR: unable to use directory "/data/kingbase"
HINT: use -F/--force to force this directory to be overwritten
[kingbase@PG-2 kingbase]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf -D /data/kingbase standby clone -h XXX.XXX.163.120 -U system -d esrep -F
NOTICE: destination directory "/data/kingbase" provided
INFO: connecting to source node
DETAIL: connection string is: host=XXX.XXX.163.120 user=system dbname=esrep
DETAIL: current installation size is 935 MB
NOTICE: checking for available walsenders on the source node (2 required)
NOTICE: checking replication connections can be made to the source server (2 required)
WARNING: directory "/data/kingbase" exists but is not empty
NOTICE: deleting existing directory "/data/kingbase"
/data/kingbase: Permission denied
NOTICE: starting backup (using sys_basebackup)...
HINT: this may take some time; consider using the -c/--fast-checkpoint option
INFO: executing:
/opt/Kingbase/ES/V8/Server/bin/sys_basebackup -l "repmgr base backup" -D /data/kingbase -h XXX.XXX.163.120 -p 54321 -U esrep -X stream -S repmgr_slot_2
NOTICE: standby clone (using sys_basebackup) complete
NOTICE: you can now start your Kingbase server
HINT: for example: sys_ctl -D /data/kingbase start
HINT: after starting the server, you need to re-register this standby with "repmgr standby register --force" to update the existing node record
[kingbase@PG-2 kingbase]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf standby register -F
INFO: connecting to local node "node121" (ID: 2)
INFO: connecting to primary database
INFO: standby registration complete
NOTICE: standby node "node121" (ID: 2) successfully registered
[kingbase@PG-2 kingbase]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+-----------------------------------------------------------------------------------------------------------------------------------------------------
1 | node120 | primary | * running | | default | 100 | 5 |
host=XXX.XXX.163.120 user=esrep dbname=esrep port=54321
connect_timeout=10 keepalives=1 keepalives_idle=10
keepalives_interval=1 keepalives_count=3
2 | node121 | standby | running | node120 | default | 100 |
5 | host=XXX.XXX.163.121 user=esrep dbname=esrep port=54321
connect_timeout=10 keepalives=1 keepalives_idle=10
keepalives_interval=1 keepalives_count=3
[kingbase@PG-1 ~]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+-----------------------------------------------------------------------------------------------------------------------------------------------------
1 | node120 | standby | running | node121 | default | 100 |
7 | host=XXX.XXX.163.120 user=esrep dbname=esrep port=54321
connect_timeout=10 keepalives=1 keepalives_idle=10
keepalives_interval=1 keepalives_count=3
2 | node121 | primary | * running | | default | 100 | 8 |
host=XXX.XXX.163.121 user=esrep dbname=esrep port=54321
connect_timeout=10 keepalives=1 keepalives_idle=10
keepalives_interval=1 keepalives_count=3
[kingbase@PG-2 etc]$ sys_ctl stop
waiting for server to shut down.... done
server stopped
[kingbase@PG-1 ~]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+---------------+-----------+----------+----------+----------+-----------------------------------------------------------------------------------------------------------------------------------------------------
1 | node120 | standby | running | ? node121 | default | 100
| 7 | host=XXX.XXX.163.120 user=esrep dbname=esrep
port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2 | node121 | primary | ? unreachable | | default | 100 | ?
| host=XXX.XXX.163.121 user=esrep dbname=esrep port=54321
connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
WARNING: following issues were detected
- unable to connect to node "node120" (ID: 1)'s upstream node "node121" (ID: 2)
- unable to determine if node "node120" (ID: 1) is attached to its upstream node "node121" (ID: 2)
- unable to connect to node "node121" (ID: 2)
- node "node121" (ID: 2) is registered as an active primary but is unreachable
[2021-12-28 21:53:07] [WARNING] unable to ping "host=XXX.XXX.163.121 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3"
[2021-12-28 21:53:07] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2021-12-28 21:53:07] [WARNING] unable to connect to upstream node "node121" (ID: 2)
[2021-12-28 21:53:07] [INFO] sleeping 3 seconds until next reconnection attempt
[2021-12-28 21:53:10] [INFO] checking state of node 2, 1 of 5 attempts
[2021-12-28 21:53:10] [WARNING] unable to ping "user=esrep connect_timeout=10 dbname=esrep host=XXX.XXX.163.121 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 fallback_application_name=repmgr"
[2021-12-28 21:53:10] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2021-12-28 21:53:10] [INFO] sleeping 3 seconds until next reconnection attempt
[2021-12-28 21:53:13] [INFO] checking state of node 2, 2 of 5 attempts
[2021-12-28 21:53:13] [WARNING] unable to ping "user=esrep connect_timeout=10 dbname=esrep host=XXX.XXX.163.121 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 fallback_application_name=repmgr"
[2021-12-28 21:53:13] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2021-12-28 21:53:13] [INFO] sleeping 3 seconds until next reconnection attempt
[2021-12-28 21:53:16] [INFO] checking state of node 2, 3 of 5 attempts
[2021-12-28 21:53:16] [WARNING] unable to ping "user=esrep connect_timeout=10 dbname=esrep host=XXX.XXX.163.121 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 fallback_application_name=repmgr"
[2021-12-28 21:53:16] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2021-12-28 21:53:16] [INFO] sleeping 3 seconds until next reconnection attempt
[2021-12-28 21:53:19] [INFO] checking state of node 2, 4 of 5 attempts
[2021-12-28 21:53:19] [WARNING] unable to ping "user=esrep connect_timeout=10 dbname=esrep host=XXX.XXX.163.121 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 fallback_application_name=repmgr"
[2021-12-28 21:53:19] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2021-12-28 21:53:19] [INFO] sleeping 3 seconds until next reconnection attempt
[2021-12-28 21:53:22] [INFO] checking state of node 2, 5 of 5 attempts
[2021-12-28 21:53:22] [WARNING] unable to ping "user=esrep connect_timeout=10 dbname=esrep host=XXX.XXX.163.121 port=54321 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3 fallback_application_name=repmgr"
[2021-12-28 21:53:22] [DETAIL] PQping() returned "PQPING_NO_RESPONSE"
[2021-12-28 21:53:22] [WARNING] unable to reconnect to node 2 after 5 attempts
[2021-12-28 21:53:22] [NOTICE] setting "wal_retrieve_retry_interval" to 86405000 milliseconds
[2021-12-28 21:53:22] [WARNING] wal receiver not running
[2021-12-28 21:53:22] [NOTICE] WAL receiver disconnected on all sibling nodes
[2021-12-28 21:53:22] [INFO] WAL receiver disconnected on all 0 sibling nodes
[2021-12-28 21:53:22] [INFO] 0 active sibling nodes registered
[2021-12-28 21:53:22] [INFO] primary and this node have the same location ("default")
[2021-12-28 21:53:22] [INFO] no other sibling nodes - we win by default
[2021-12-28 21:53:22] [NOTICE] setting "wal_retrieve_retry_interval" to 5000 ms
[2021-12-28 21:53:22] [NOTICE] this node is the only available candidate and will now promote itself
[2021-12-28 21:53:22] [INFO] try to ping the trusted_servers "XXX.XXX.122.1" before execute promote_command
[2021-12-28 21:53:24] [NOTICE] PING XXX.XXX.122.1 (XXX.XXX.122.1) 56(84) bytes of data.
--- XXX.XXX.122.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 0.077/0.083/0.089/0.006 ms
[2021-12-28 21:53:24] [NOTICE] successfully ping one or more of the trusted_servers "XXX.XXX.122.1"
[2021-12-28 21:53:24] [NOTICE] try to stop old primary db (host: "XXX.XXX.163.121")
[2021-12-28 21:53:26] [NOTICE] PING XXX.XXX.163.210 (XXX.XXX.163.210) 56(84) bytes of data.
--- XXX.XXX.163.210 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1003ms
rtt min/avg/max/mdev = 0.700/1.215/1.730/0.515 ms
[2021-12-28 21:53:26] [WARNING] the virtual ip is already on other host, try to release it on old primary node (host: "XXX.XXX.163.121")
[2021-12-28 21:53:26] [INFO] ES connection to host "XXX.XXX.163.121" succeeded, ready to release vip on it
[2021-12-28 21:53:27] [NOTICE] old primary node (host: "XXX.XXX.163.121") release the virtual ip XXX.XXX.163.210/24 success
[2021-12-28 21:53:27] [NOTICE] will acquire the virtual ip again
[2021-12-28 21:53:29] [NOTICE] PING XXX.XXX.163.210 (XXX.XXX.163.210) 56(84) bytes of data.
--- XXX.XXX.163.210 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 1002ms
[2021-12-28 21:53:29] [WARNING] ping host"XXX.XXX.163.210" failed
[2021-12-28 21:53:29] [DETAIL] average RTT value is not greater than zero
[2021-12-28 21:53:30] [INFO] loadvip result: 1, arping result: 1
[2021-12-28 21:53:30] [NOTICE] new primary node (ID: 1) acquire the virtual ip XXX.XXX.163.210/24 success
[2021-12-28 21:53:30] [INFO] promote_command is:
"/opt/Kingbase/ES/V8/Server/bin/repmgr standby promote -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf"
NOTICE: promoting standby to primary
DETAIL: promoting server "node120" (ID: 1) using sys_promote()
NOTICE: waiting up to 60 seconds (parameter "promote_check_timeout") for promotion to complete
NOTICE: STANDBY PROMOTE successful
DETAIL: server "node120" (ID: 1) was successfully promoted to primary
[kingbase@PG-1 ~]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+-----------------------------------------------------------------------------------------------------------------------------------------------------
1 | node120 | primary | * running | | default | 100 | 9 |
host=XXX.XXX.163.120 user=esrep dbname=esrep port=54321
connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2 | node121 | primary | - failed | | default | 100 | ? |
host=XXX.XXX.163.121 user=esrep dbname=esrep port=54321
connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
WARNING: following issues were detected
- unable to connect to node "node121" (ID: 2)
继续查看新主的repmgr的日志,以下为旧主的自动恢复:
[2021-12-28 21:53:31] [INFO] switching to primary monitoring mode
[2021-12-28 21:53:31] [NOTICE] monitoring cluster primary "node120" (ID: 1)
[2021-12-28 21:53:31] [INFO] create a thread 0x2b78b03b3700 to check the cluster status
[2021-12-28 21:53:31] [INFO] child node: 2; attached: no
[2021-12-28 21:53:31] [INFO] check node status again, try 1 / 5 times
[2021-12-28 21:53:32] [INFO] node (ID: 2): no server running
[2021-12-28 21:53:32] [INFO] [thread 0x2b78b03b3700] the cluster has no other running primary node, exit
[2021-12-28 21:53:33] [INFO] child node: 2; attached: no
[2021-12-28 21:53:33] [INFO] check node status again, try 2 / 5 times
[2021-12-28 21:53:35] [INFO] child node: 2; attached: no
[2021-12-28 21:53:35] [INFO] check node status again, try 3 / 5 times
[2021-12-28 21:53:37] [INFO] child node: 2; attached: no
[2021-12-28 21:53:37] [INFO] check node status again, try 4 / 5 times
[2021-12-28 21:53:39] [INFO] child node: 2; attached: no
[2021-12-28 21:53:39] [INFO] check node status again, try 5 / 5 times
[2021-12-28 21:53:41] [INFO] child node: 2; attached: no
[2021-12-28 21:53:41] [INFO] found node down, recovery will be triggered after recovery delay time 20s
[2021-12-28 21:53:43] [INFO] child node: 2; attached: no
[2021-12-28 21:53:45] [INFO] child node: 2; attached: no
[2021-12-28 21:53:47] [INFO] child node: 2; attached: no
[2021-12-28 21:53:49] [INFO] child node: 2; attached: no
[2021-12-28 21:53:51] [INFO] child node: 2; attached: no
[2021-12-28 21:53:53] [INFO] child node: 2; attached: no
[2021-12-28 21:53:56] [INFO] child node: 2; attached: no
[2021-12-28 21:53:58] [INFO] child node: 2; attached: no
[2021-12-28 21:54:00] [INFO] child node: 2; attached: no
[2021-12-28 21:54:02] [INFO] child node: 2; attached: no
[2021-12-28 21:54:02] [INFO] recovery delay time reached. can do recovery now.
[2021-12-28 21:54:02] [INFO] [thread pid:6112] do_nodes_recovery thread begin. The pthread_t tid is 0x2b78b03b3700
[2021-12-28 21:54:02] [NOTICE] [thread pid:6112] node (ID: 2; host: "XXX.XXX.163.121") is not attached, ready to auto-recovery
[2021-12-28 21:54:02] [NOTICE] [thread pid:6112] Now, the primary host ip: XXX.XXX.163.120
[2021-12-28 21:54:02] [INFO] [thread pid:6112] ES connection to host "XXX.XXX.163.121" succeeded, ready to do auto-recovery
[2021-12-28 21:54:02] [INFO] unlink file /tmp/.s.KINGBASE.54321.lock
[2021-12-28 21:54:02] [NOTICE] executing repmgr command "/opt/Kingbase/ES/V8/Server/bin/repmgr --dbname="host=XXX.XXX.163.120 dbname=esrep user=esrep port=54321" node rejoin --force-rewind"
NOTICE: executing sys_rewind
DETAIL: sys_rewind command is "/opt/Kingbase/ES/V8/Server/bin/sys_rewind -D '/data/kingbase' --source-server='host=XXX.XXX.163.120 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3'"
sys_rewind: servers diverged at WAL location 0/6A009098 on timeline 8
sys_rewind: no rewind required
sys_rewind: status check: restore all the backup temp file, Done!
NOTICE: 0 files copied to /data/kingbase
INFO: deleting slot directory "/data/kingbase/sys_replslot/repmgr_slot_1"
NOTICE: setting node 2's upstream to node 1
WARNING: unable to ping "host=XXX.XXX.163.121 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3"
DETAIL: PQping() returned "PQPING_NO_RESPONSE"
NOTICE: begin to start server at 2021-12-28 21:54:03.185429
NOTICE: starting server using "/opt/Kingbase/ES/V8/Server/bin/sys_ctl -w -t 90 -D '/data/kingbase' -l /opt/Kingbase/ES/V8/Server/bin/logfile start"
NOTICE: start server finish at 2021-12-28 21:54:03.409308
NOTICE: NODE REJOIN successful
DETAIL: node 2 is now attached to node 1
[2021-12-28 21:54:03] [NOTICE] kbha: node (ID: 2) rejoin success.
[2021-12-28 21:54:03] [NOTICE] [thread pid:6112] node "node121" (ID: 2) auto-recovery success
[2021-12-28 21:54:03] [INFO] [thread pid:6112] do_nodes_recovery thread ends. The pthread_t tid is 0x2b78b03b3700
[2021-12-28 21:54:04] [INFO] thread tid:0x2b78b03b3700 is not running
[2021-12-28 21:54:04] [INFO] the recovery thread was exited, reset tid
[2021-12-28 21:54:04] [NOTICE] Some nodes reconnect, all standby nodes are OK now
[2021-12-28 21:54:08] [NOTICE] new standby "node121" (ID: 2) has connected
- unable to connect to node "node121" (ID: 2)
[kingbase@PG-1 ~]$ repmgr -f /opt/Kingbase/ES/V8/Server/etc/repmgr.conf cluster show
ID | Name | Role | Status | Upstream | Location | Priority | Timeline | Connection string
----+---------+---------+-----------+----------+----------+----------+----------+-----------------------------------------------------------------------------------------------------------------------------------------------------
1 | node120 | primary | * running | | default | 100 | 9 | host=XXX.XXX.163.120 user=esrep dbname=esrep port=54321 connect_timeout=10 keepalives=1 keepalives_idle=10 keepalives_interval=1 keepalives_count=3
2 | node121 | standby | running | node120 | default | 100 |
8 | host=XXX.XXX.163.121 user=esrep dbname=esrep port=54321
connect_timeout=10 keepalives=1 keepalives_idle=10
keepalives_interval=1 keepalives_count=3
[kingbase@PG-3 kingbase]$ initdb -D /data/kingbase -A scram-sha-256 -E utf8 -U system -W --wal-segsize=16
initdb: could not find suitable text search configuration for locale "zh_CN.UTF-8"
本文作者:魏 强(上海新炬中北团队)
本文来源:“IT那活儿”公众号

