





前言
上一期我们介绍了etcd的基本功能,还有怎么安装,这一期我们得杠个个硬骨头,RAFT协议。
浅析Raft协议
在介绍RAFT协议之前,我们先来说一下,分布式遇到的一些挑战。
最大的挑战
分布式最大的挑战在于怎么样保证多个节点数据的一致性。假设现在我们有三台机器A、B、C。当我向A写入一组数据的(1,2,3)的时候,如何保证这些数据(1,2,3)按照顺序同步到B和C。(网络会延迟,网络会中断),当发生网络中断或者丢包的时候,数据1和3先传输过去了,但是2丢失了,随后2又重新组织传了过来。如何确保数据的一致性就是算法的核心所在。RAFT实现了最终一致性的算法。
Raft协议的工作模式是一个Leader节点和多个Follower节点。在Raft协议中,每一个节点都维护一个状态机,这个状态机有三种状态,分别是Leader状态,Follower状态,Candidate状态。在任意一个时刻,集群中的任意一个节点都属于这三个状态之一。
以上内容过于难理解,下面我们来通过一个著名的动画学习。(http://thesecretlivesofdata.com/raft/)

左边的绿点代表客户端,右边的蓝点代表服务器,当前是单节点的服务器。此时客户端将数字8,写入到服务器。在只有一个节点的情况下,很容易达成共识。但是当我们的服务器变成了多台机器。如何保证数据的一致性就变成了一个问题。
三种状态
动画定义了节点的三种状态,我们前面说过状态机有三种状态,分别是Leader状态,Follower状态,Candidate状态。
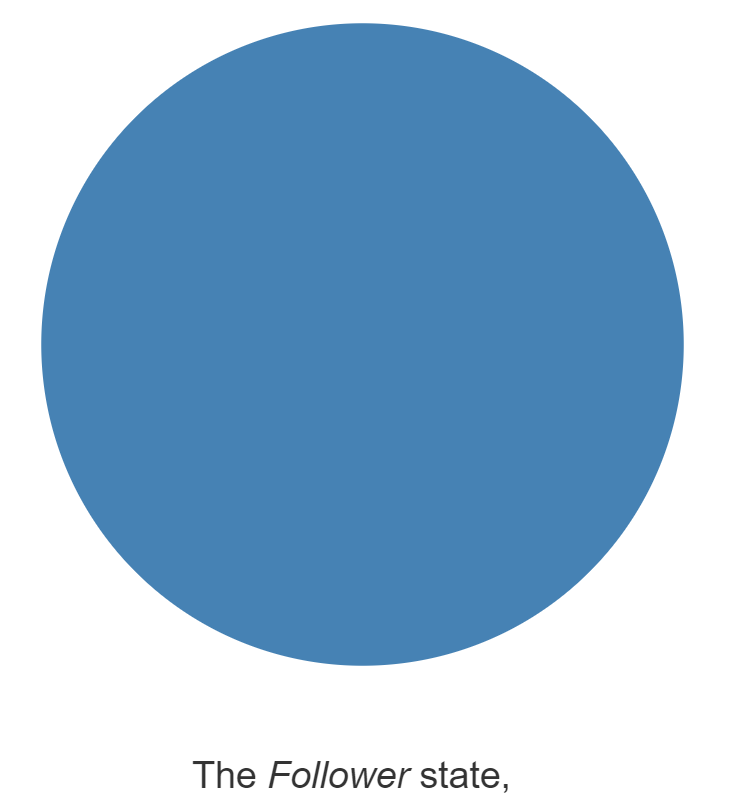 | 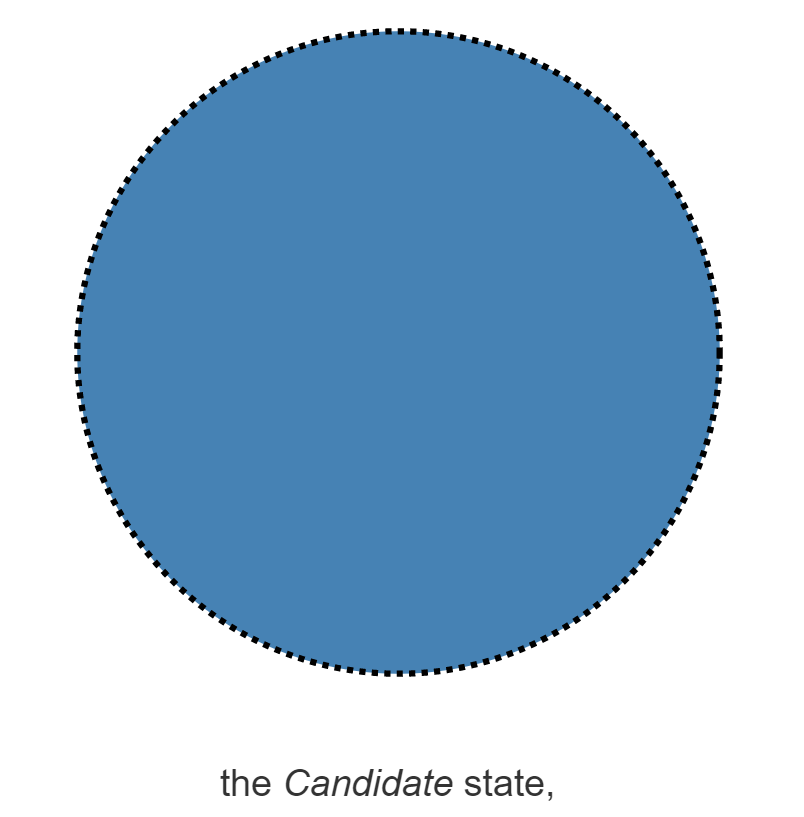 | 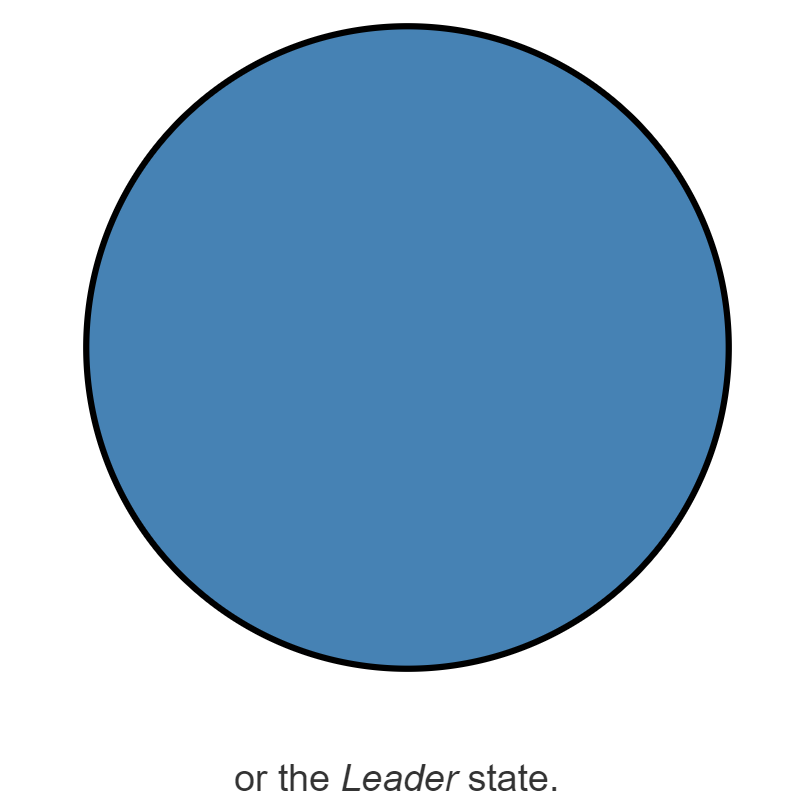 |
|---|
以下是三种状态的图示,注意观察它们的边框。
一开始三个节点都是fllower状态
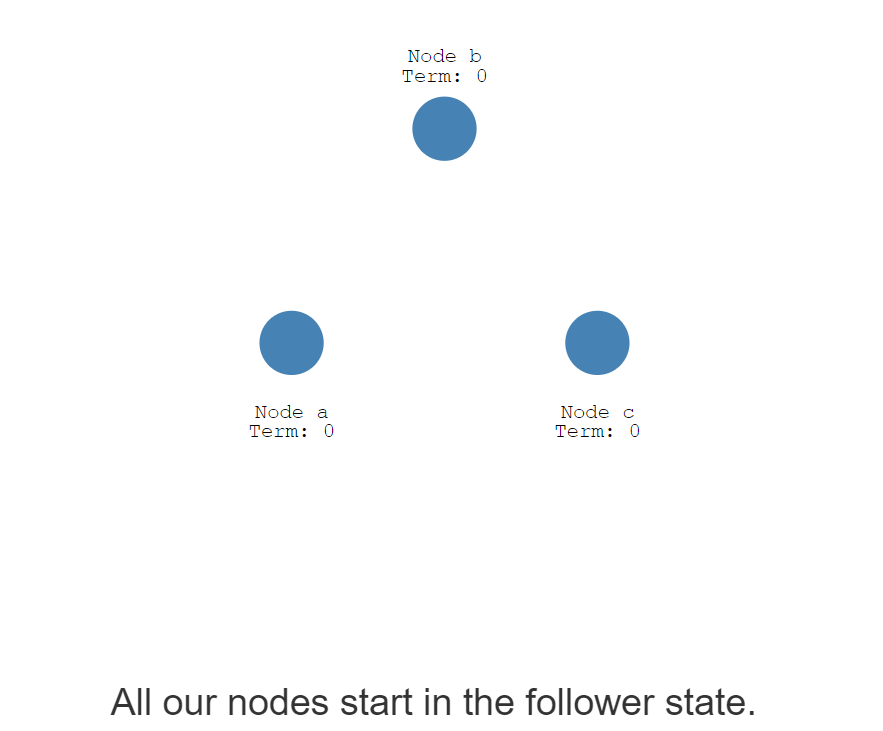
但是,如果follower没有收到领导者的心跳信息,则会成为Candidate状态。
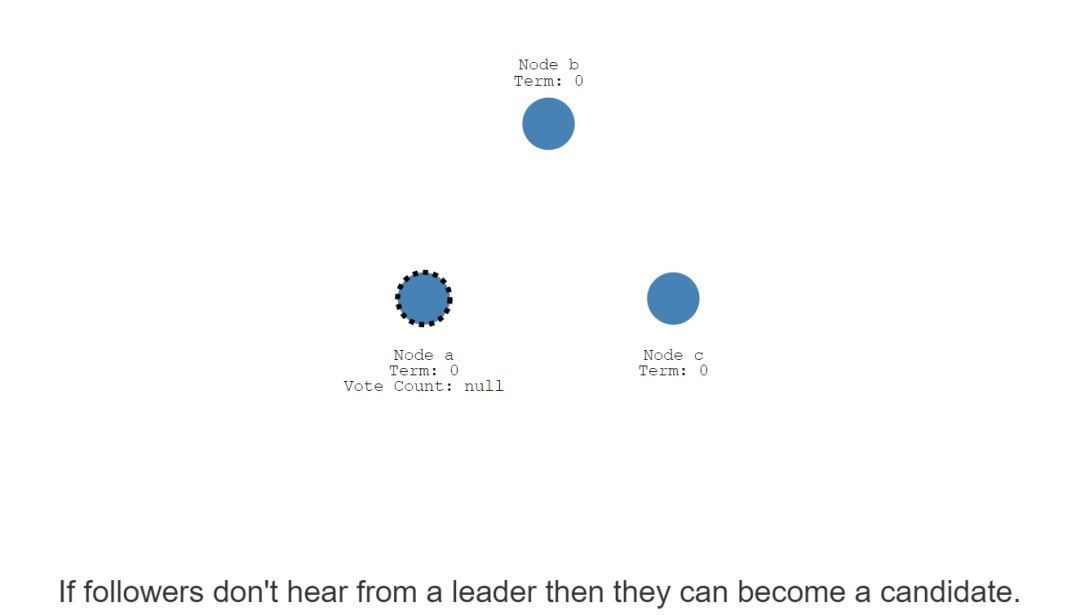
当Node A成了候选者,它就会向其他节点发起投票。

节点将投票表决,如果Node A作为候选人从多个节点中获取选票,它此时就将成为领导者。这个过程被称作:“Leader Election”(领导者选举)。就和美国大选一样,谁获得的选票多谁就是大总统。此时,所有对系统做的修改都要通过Node A(领导者),每次更改都将添加为节点日志中的条目。日志条目当前未提交,暂时不会更新节点的值。要提交条目,节点首先将日志条目有复制到跟随者节点(Node b和Node c)。然后Leader将等待,直到大多数节点也写入了这个条目(Set 5)。这个过程叫做日志复制。然后领导者通知跟随者followers,这个条目已提交。整个集群就对当前系统状态达成一致性共识。
注意看每个节点还有一个Term :0的下标。每一次开始一个新的选举时,称为一个任期。每个任期都有一个对应的整数与之关联,称为任期号,任期号用单词Term表示,这个值是一个严格递增的整数值。
领导者选举
raft算法是有两种超时机制来控制选举。第一个是election timeout。
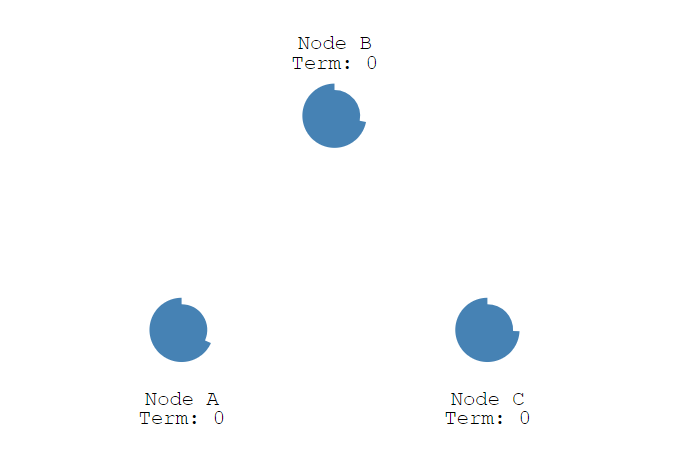
节点刚刚启动,Noad A、Node B、Node C全部进入到follower状态,同时创建一个超时时间在150ms-300ms之间的选举超时定时器。
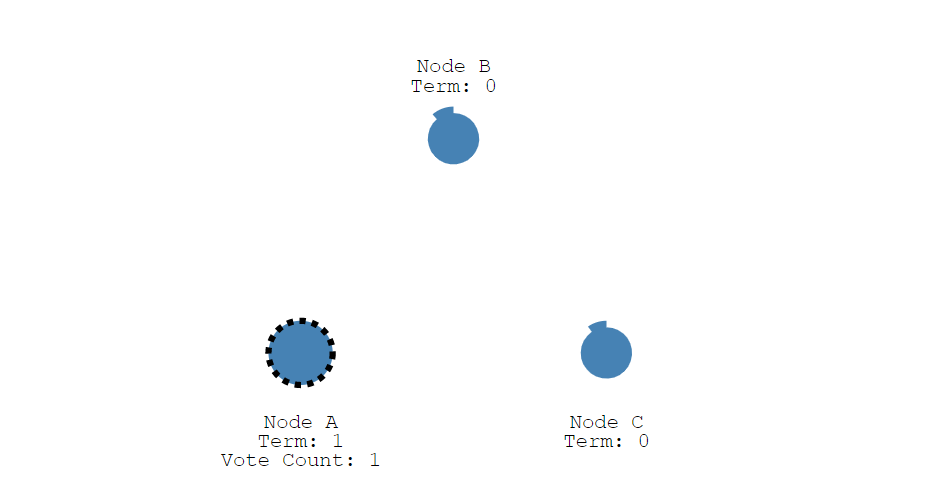
当Node A节点率先到达超时时间后(没有收到leader节点心跳),就变成candidate状态,同时任期号term+1,并给自己投票,Vote Count:1,得到一票。
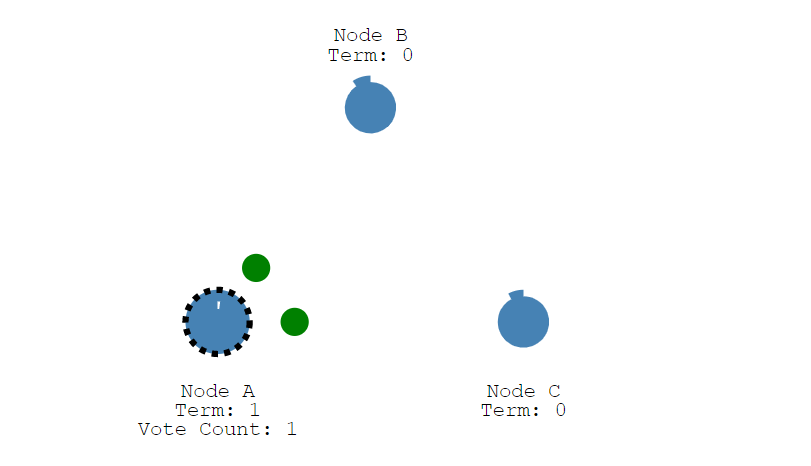
然后Node A就将请求大家投票的信息发送给Node B和Node C。
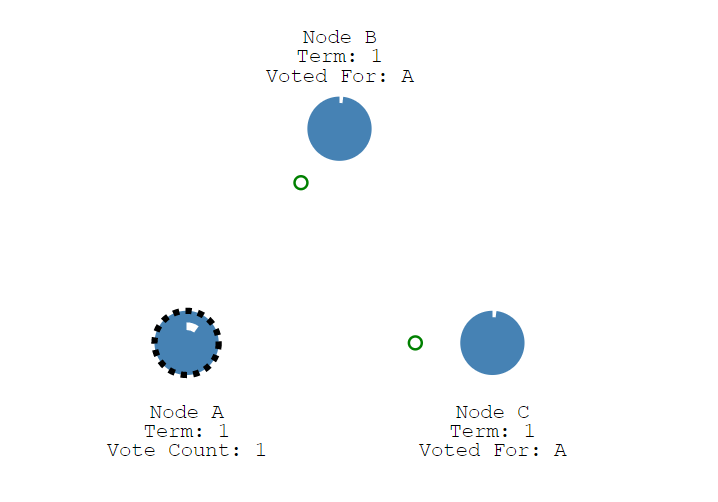
此时Node B和Node C在这个任期还没有投票,它们接收消息的任期号大于当前任期号,那么它们将投票给候选人,并且节点重置其选举超时。此时的候选者一旦获取到多数投票,它就将成为领导者。
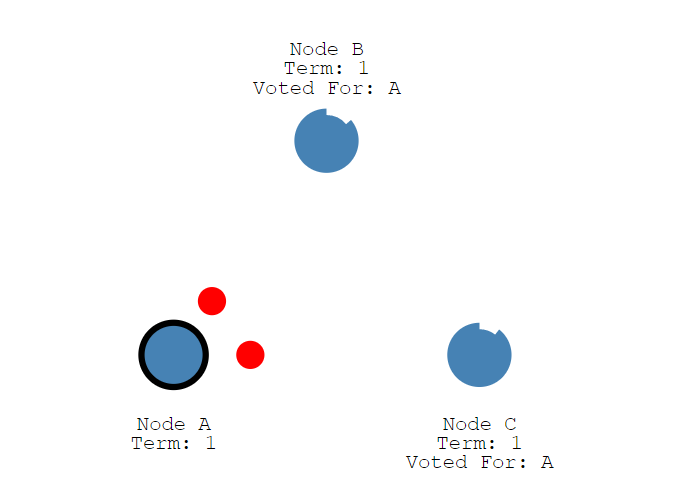
领导者开始向其关注者发送添加条目消息,这些消息以心跳超时指定的时间间隔发送,跟随者然后响应每个追加条目消息,此选举任期将持续到追随者停止接收心跳并成为候选人为止。
领导者故障
如果领导者突然发生了故障。
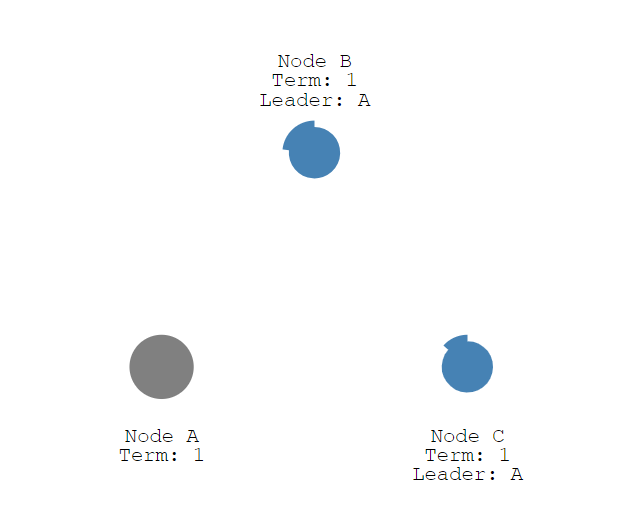
此时就和之前一样。当Node C节点率先到达超时时间后(没有收到leader节点心跳),就变成candidate状态,同时任期号term+1,并给自己投票,Vote Count:1,得到一票。
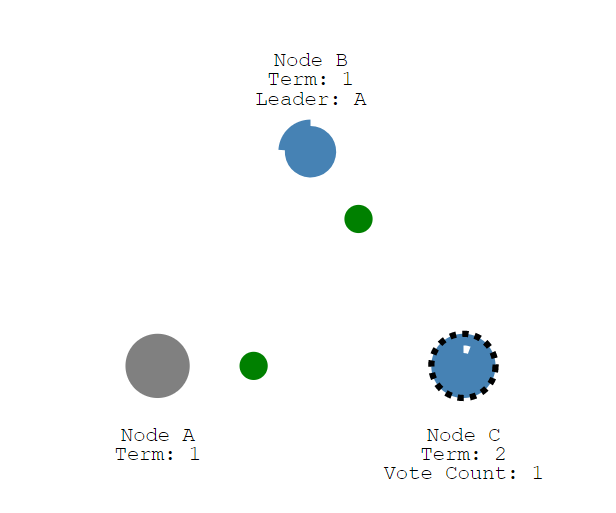
然后Node C就将请求大家投票的信息发送给Node A和Node B。因为Node A已经死掉了,现在就只能收到Node B的投票。
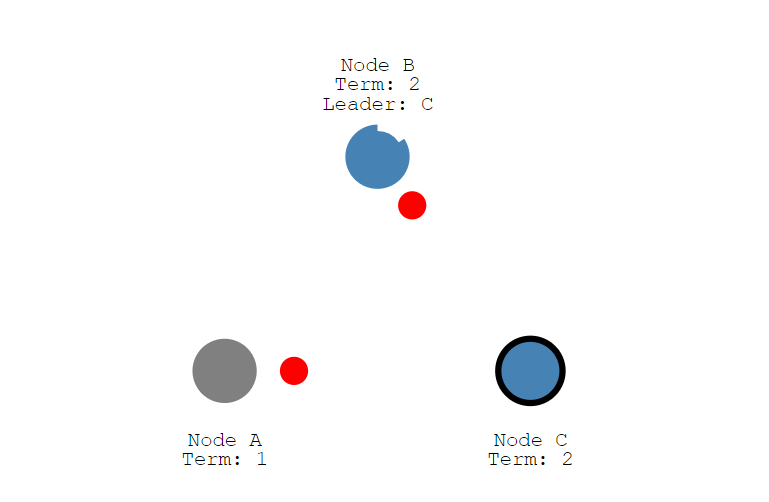
在获得了多数投票后,现在Node C成为了新的领导者,然后任期号变成了2。
split vote(分裂投票)
如果两个节点同时成为了候选者(时间相同的情况下),则可能会发生split vote(分裂投票)。我们来看一个四个节点的案例。

此时两个节点都开始以相同的任期进行选举投票。
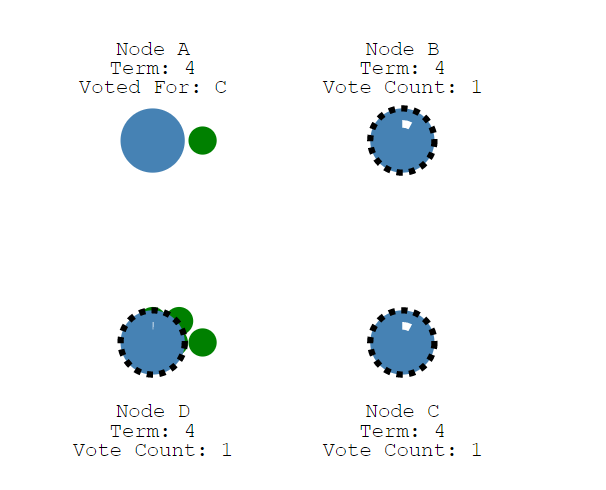
现在,每位候选人都有2票,并且在这个任期中将无法获得更多选票,节点将等待新的选举,然后重试。
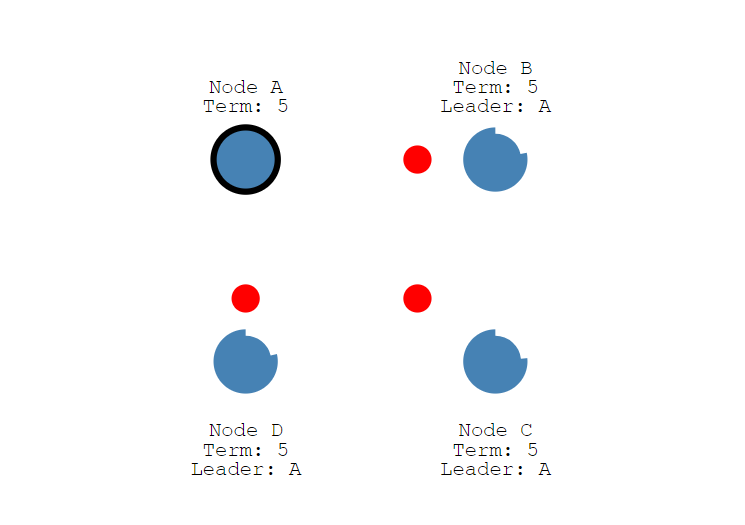
结果在新一轮中,Node A获取了大多数选票,重新成为了领导者。
日志复制
正如我们前面介绍的,客户端将修改的信息先发送给领导者,这将添加日志条目,接下来领导者将更改的信息在下一次的心跳中发送给Fllower,一旦大多数追随者认可了该条目,便会提交该条目。提交之后就会返回给客户端。
如果发生了异常,也就是网络分区异常,简单来说就是脑裂的情况,我们看看它是怎么保证一致性的。
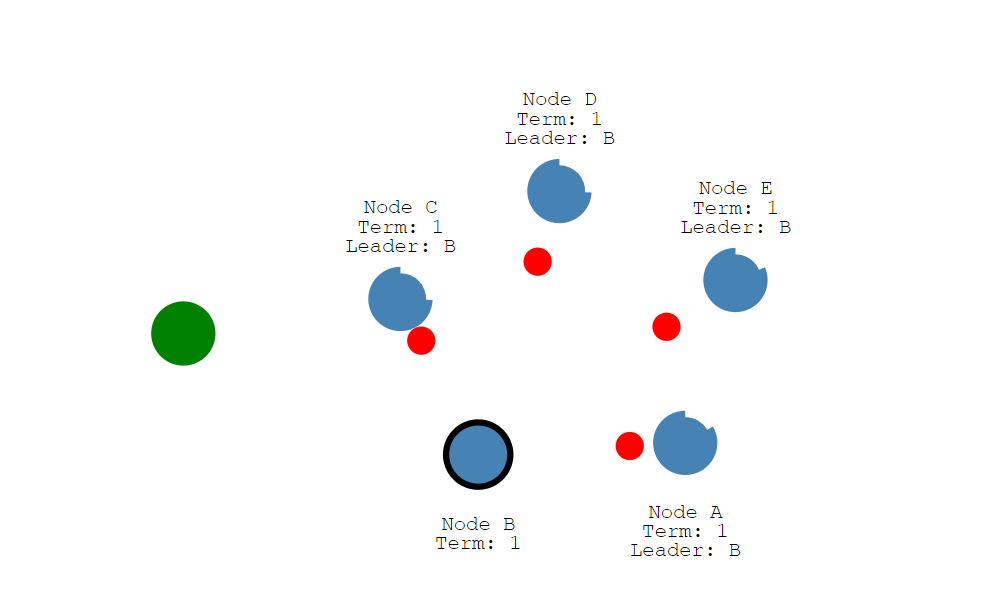
假设这是一个5节点的集群。领导者是Node B。当发生网络隔离故障的时候,假设Node A和Node B在一个网络分区,Node C、Node D、Node E在一个网络分区中。
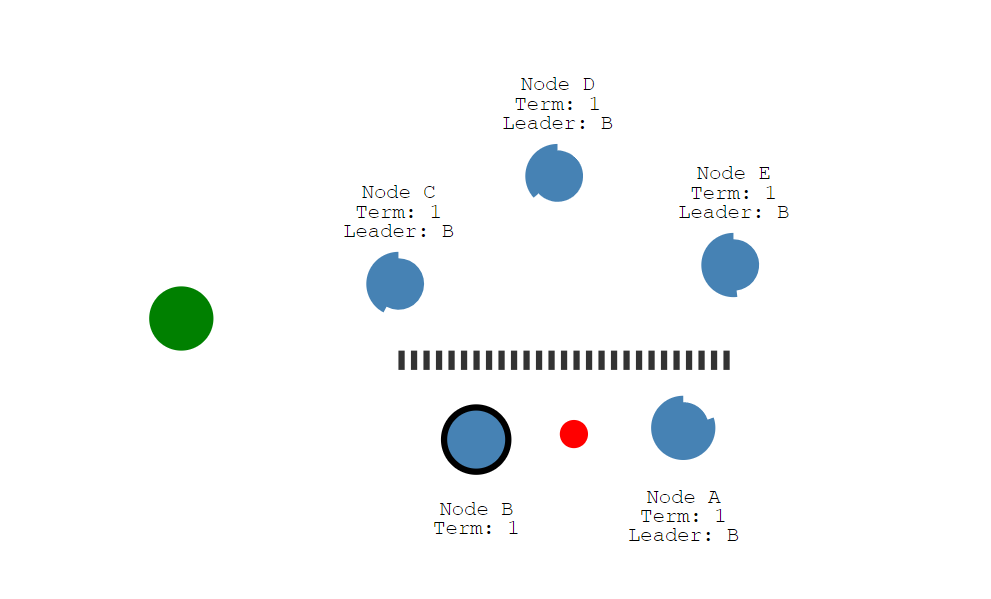
此时Node B是领导者,它只能和Node A进行了通信。而另外的Node C、Node D、Node E将发生选举,确认谁是新的领导者。
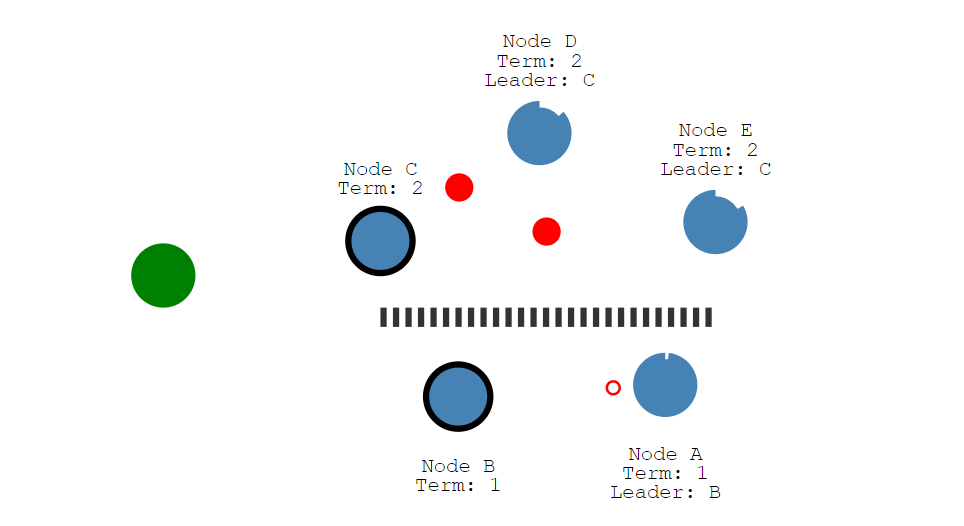
可以看到Node C成为了新的领导者,Node D和Node E成为了跟随者,且它们的任期号变成了2。现在让我们添加另一个客户端,并尝试更新两个领导者。
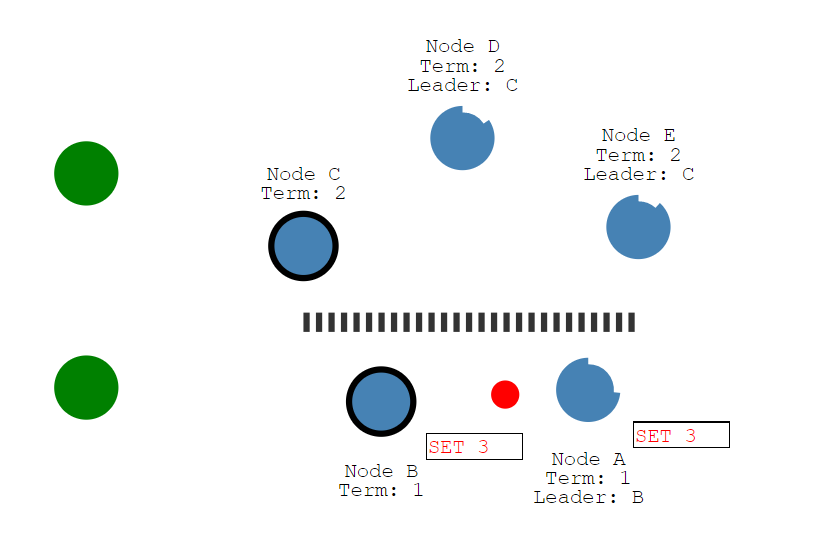
下面的绿色的客户端将Node B的值改成了3。但是问题是Node B现在没有办法复制到多数节点(只能复制到Node A),因此它的日志条目将保持为未提交状态。
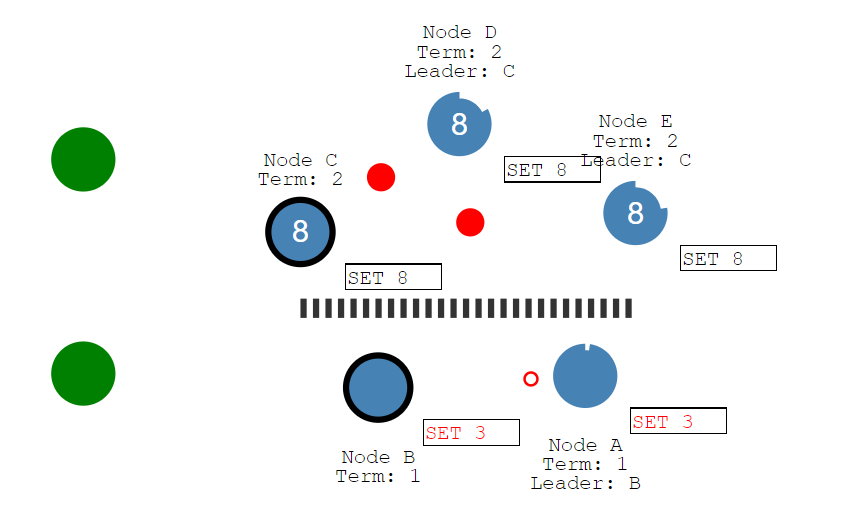
而另外一个客户端尝试修改Node C的值为8,它是可以复制到Node D和Node E的,此时它能复制到多数节点,它能成功的进行提交。
现在我们修复网络分区。
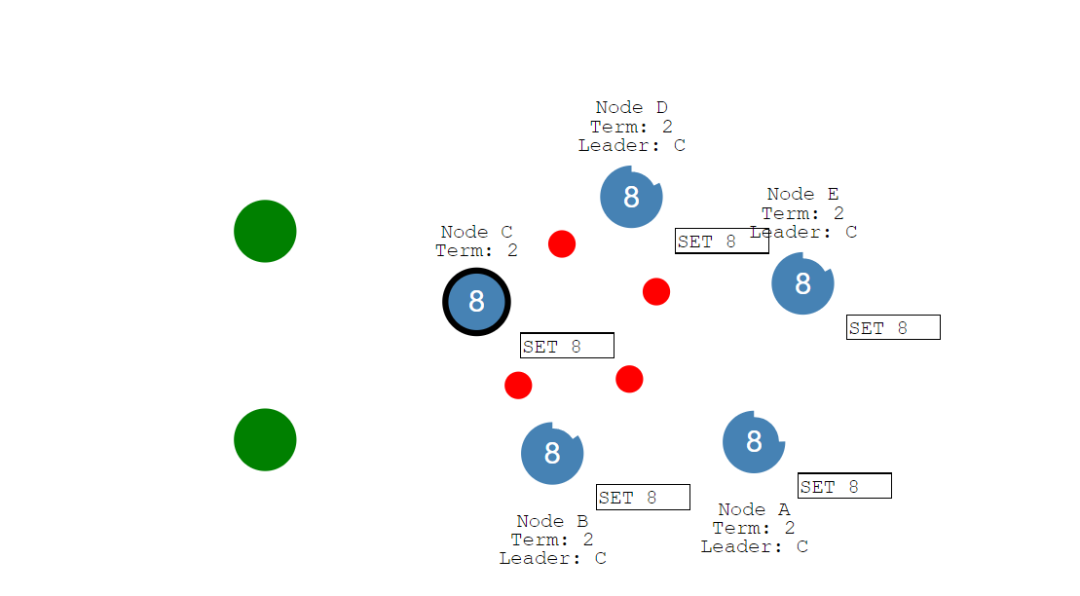
此时Node B看到有更高的选举期限,也就是任期号(term),它将选择直接退出。Node A和Node B都将回滚其未提交的条目,并匹配新领导者的日志。现在,我们的日志在整个集群中是一致的。
后记
今天Raft协议的介绍就到这里,我这个是比较浅的理论,简单来说就是最简单的入门。更加深入的理论可以参考:
https://www.geeksforgeeks.org/raft-consensus-algorithm/
参考链接
http://thesecretlivesofdata.com/raft/
