




故障现象
测试环境在测试生产系统新版本的时候出现,了很多表被阻塞,导致了前端很慢。
故障根源
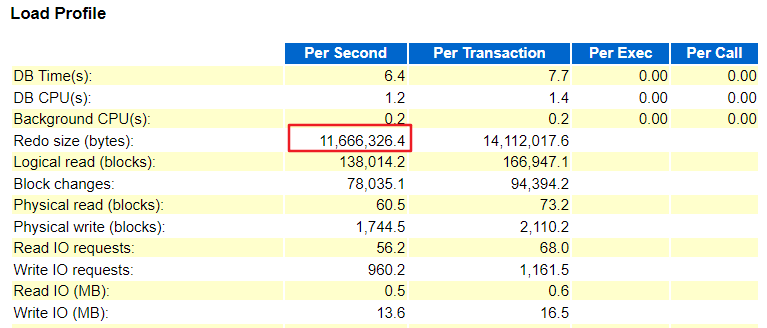
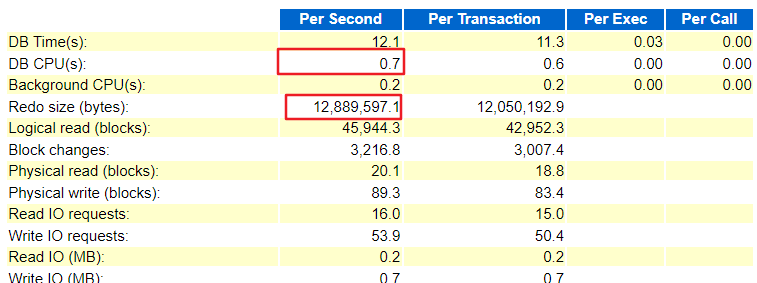
从awr报告中可以看出,一节点和二节点每秒的redo 日志都在12M左右产生较多,db cpu和db time 差距较大说名大部分时间都花费在等待其他资源而不是消耗在cpu上
一节点:
二节点:
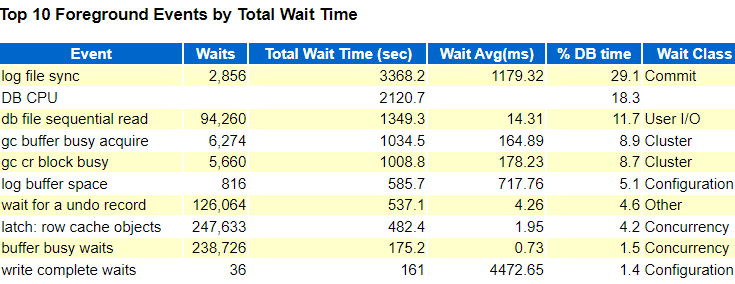
此时,再来查看一节点和二节点的等待事件
一节点:
二节点:
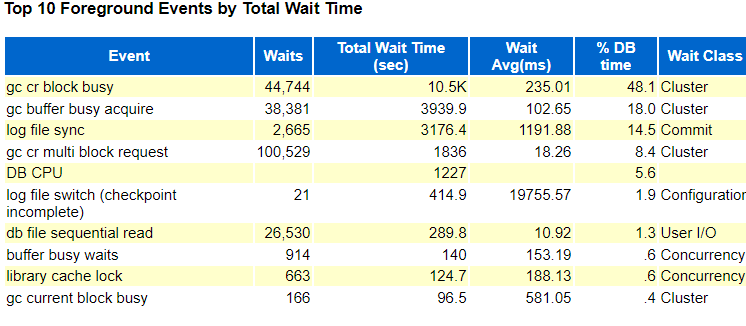
一节点和二节点都有比较明显的log file sync 这个等待事件,log file sync 是当用户执行commit/rollback指令,redo信息需要从log buffer刷新到本地redo log file。
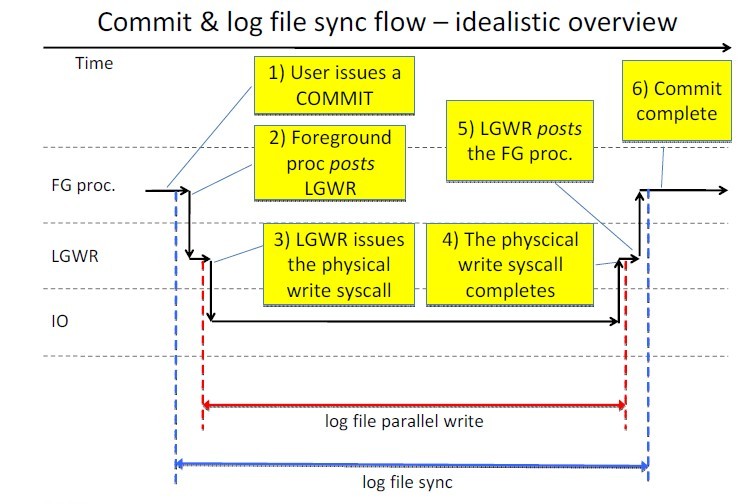
从上图可以看出Log file sync 可能会等待在一下几个阶段:
- 唤醒lgwr进程
- Lgwr收集要写入哪些redo,并发出I/O请求
- 写redo 需要的时间
- LGWR I/O 处理完成
- LGWR返回给前台进程
- 前台进程被唤醒
通常来说,Log file sync产生的主要原因是3-4之间也就是log file parallel write。
一节点:
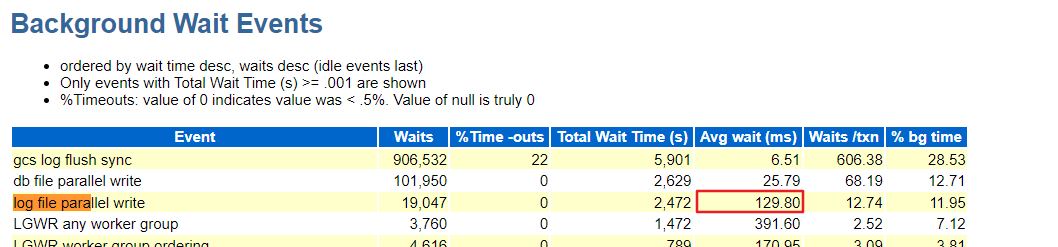
二节点:
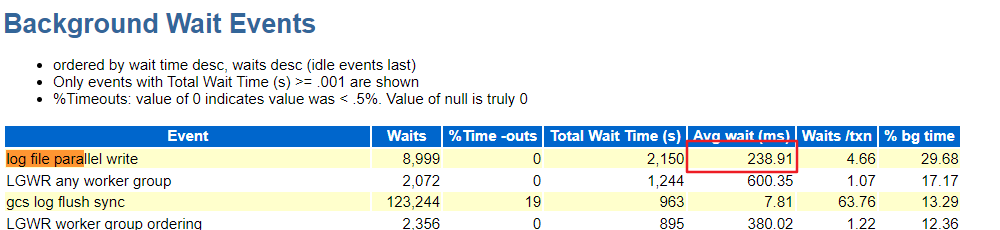
从上图可以看出 log file parallel write 平均等待时间特别高,正常情况下建议在7ms以内。
log file parallel write 特别慢主要是由于I/O 慢引起的。
通过一节点的OSW监控日志可以发现,共享存储I/O压力很大,尤其是DATA磁盘组
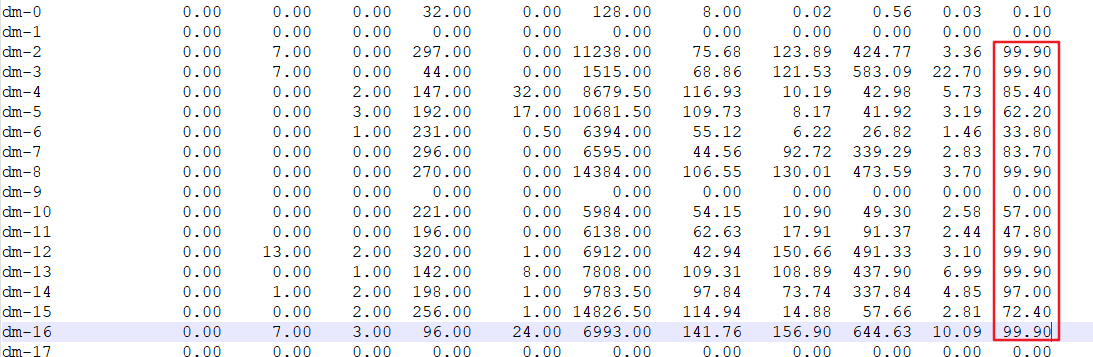

关于二节点的gc 类等待时间,是由于 current/cr block在进行修改后,只有将修改信息写入到redo的logfile里,才能通过LMS进程传送到其他节点。
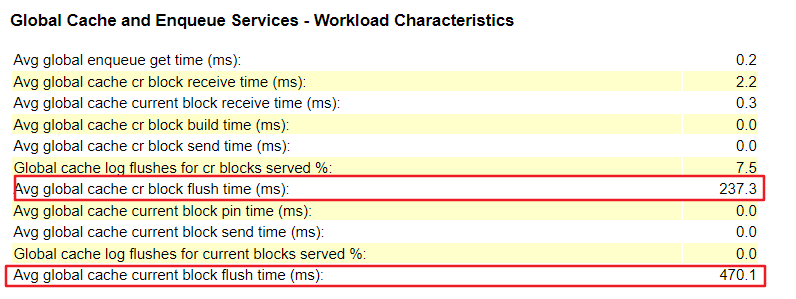
从上图就可以看出,消耗时间特别长,所以产生的大量的gc类等待事件
产生日志主要对象
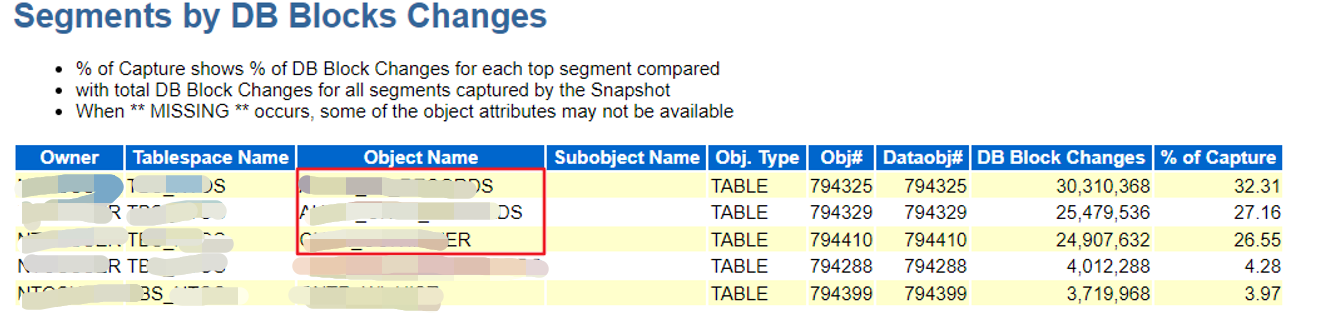
解决方案及总结
请存储工程师排查存储方面是否存在存储方面的故障(包含存储本身和存储链路)。
将redo 日志移动到SSD组成的磁盘组上,比如 RECO 或者REDO。
参考文档
WAITEVENT: "log file sync" Reference Note (文档 ID 34592.1)
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
