




前言
最近 GPT 火出了圈,15 号凌晨 OpenAI 又发布了多模态预训练大模型 GPT-4,短短几个月间已经迅速引爆了整个科技领域,话题不断。
你要问我前阵子 DBA 圈子里最热闹的话题,那么当属瑞典马工的那篇 你怎么还在招聘DBA? 。此文一出,DBA 圈子就炸了,悲观主义者觉得 DBA 的前景确实晦涩暗淡,随着智能化与超融合多模态的发展大趋势,数据库的易用性会越来越好,DBA 的地位受到了冲击,需要立马转型,而乐观主义者则不然,资深的数据库专家在市场上始终抢手,实乃香饽饽。
当然也有很多针对此文的回击,每一篇我都有阅读
- 云数据库是不是智商税
- 驳《再论为什么你不应该招DBA》
- 蹭个热度–要不要DBA和云数据库
- 二次反击《再论为什么你不应该招DBA》
- 你怎么不招聘DBA
- 大厂裁员轰轰烈烈,哪个技术岗位可以独善其身?
- 读《你怎么还在招聘DBA》有感
加之惊为天人的 GPT-4 15 号也问世了,网上和现实中类似的声音越来越多
看网上评论的 GPT-4,初级前端开发已死?
CRUD BOY 怕是要被拍死在沙滩上了
凡是没有自觉用 ChatGPT 的程序员都可以考虑炒掉!
ChatGPT+ Copilot,我可以摆脱双手真正做到 ctrl +c / ctrl +v 了
诚然,GPT4 的能力确实让人叹为观止,原来一个优秀的程序员可以顶十个普通的程序员,但现在一个优秀的且会用 ChatGPT 的程序员可能可以顶五十个。
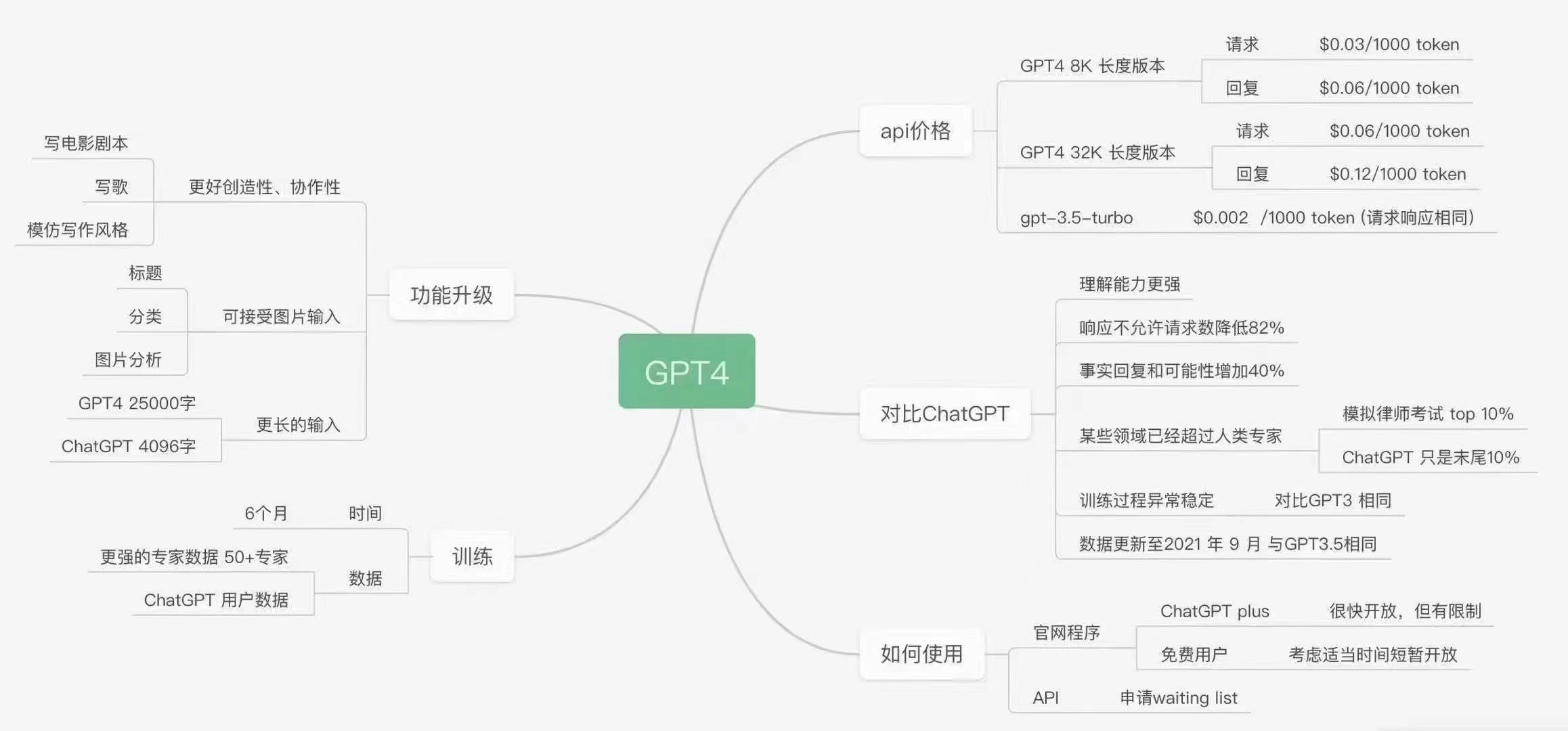

最近我也在思考,随着 GPT 的不断狂飙,会对我个人带来什么样的冲击?我的核心竞争力还能保持多久?我做的事 GPT 能不能帮我做?如果你还是认为它只是小号 Siri、另一个小爱同学,那么你就大大低估了这个产品的革命性威力。
躬身入局
我个人是一名PostgreSQL DBA,和万千 DBA 从业者一样,日常工作无外乎优化 SQL、和业务交涉扯皮、处理故障等等。
以故障处理为例,因为这是占据我日常工作时间极大比重的事情。在我们这里,PostgreSQL 的实例数预估已经上万+了,那么这么多实例总是会遇到形形色色的问题,毕竟 99.99% ✖️ 99.99% = 99.98%,经常有阅读我公众号文章的读者应该有所体会,什么插件出问题了、内核踩BUG了、操作系统抽了、硬件又尿了等等。
以典型的表膨胀为例,相信无数老鸟和新手都遇到这类问题。看看 GPT 会如何回答我的问题
PostgreSQL为什么会表膨胀?如何处理表膨胀?尽可能详细地描述

上面是 GPT 给到我的回答,像是一位初中级 DBA 给到的回复,虽然回答了一些,但是都没到那个精髓,那个最核心的原理。
假如我是一名面试官,我会觉得这位面试者背诵了不少八股文,缺少实际的实战经验,虽然有理论,但是碰到实际中变通一下的场景,可能就抓瞎了。这个也怪不得 GPT, 毕竟 GPT 是语言模型,回答是网上一箩筐信息的整合与提炼。
我曾处理过无数表膨胀的问题,举一个很罕见的场景(这个我在 备库是否有自己的统计信息 里面提及过):
-
autovacuum launcher 定期读取 stats collector 进程收集的统计信息文件以决定何时触发 autovacuum,而备库是不包含此类统计信息文件的,因此假如有个表在主库上即将达到了触发阈值就快要进行 vacuum/analyze 了,结果这个时候做了一个 switchover 或者 failover,新的主库由于没有统计数据,需要新的活动才可以触发收集,因此这个表就会被"延迟"清理,时间可能就增加了一倍。
-
同理,vm文件也不会进行复制,假如有个表要插入新行了,switchover 或者 failover 后第一次 vacuum 之前都不会复用这些空间。
这种场景我想 GPT 是无法回答出来的(当然不排除它去现搜我的文章)。还有我在上面写到的哪些情况会导致表膨胀,我列举了大概 7 点主要原因,最核心的还是 vacuum 的原理:判断系统中是否含有很久之前开启而未提交的事务,并且这个事务由于执行过更新,创建了事务ID。这一点 GPT 也没有回答出来,知晓了原理,那么后面的原因,诸如backend_xid/backend_xmin/复制槽/2pc为何会造成表膨胀也就顺理成章了。
但是 GPT 有一个强大之处,便是会根据上下文语义来进行分析。那让我们再试一次,告诉它核心原理,让它主动纠错
表膨胀最核心的机制还是 vacuum 的机制:判断系统中是否含有很久之前开启而未提交的事务,并且这个事务由于执行过更新,创建了事务ID,那么计算出来的OldestXmin会非常小,vacuum做上述这个判断时,结果通常为true,即返回HEAPTUPLE_RECENTLY_DEAD,这样就会保留此tuple(旧版本),导致回收无法完成,表膨胀由此发生。请你知晓了此原理之后,重新补充回答一下表膨胀的原理和预防处理机制
这次的回答就让人略显失望,漏洞百出。vacuum 优先级是什么鬼,vacuum full 可以调优先级?提升 OldestXmin 靠 min_wal_size?还有 autovacuum = on,实际环境中还是很少有人主动关闭这个参数的
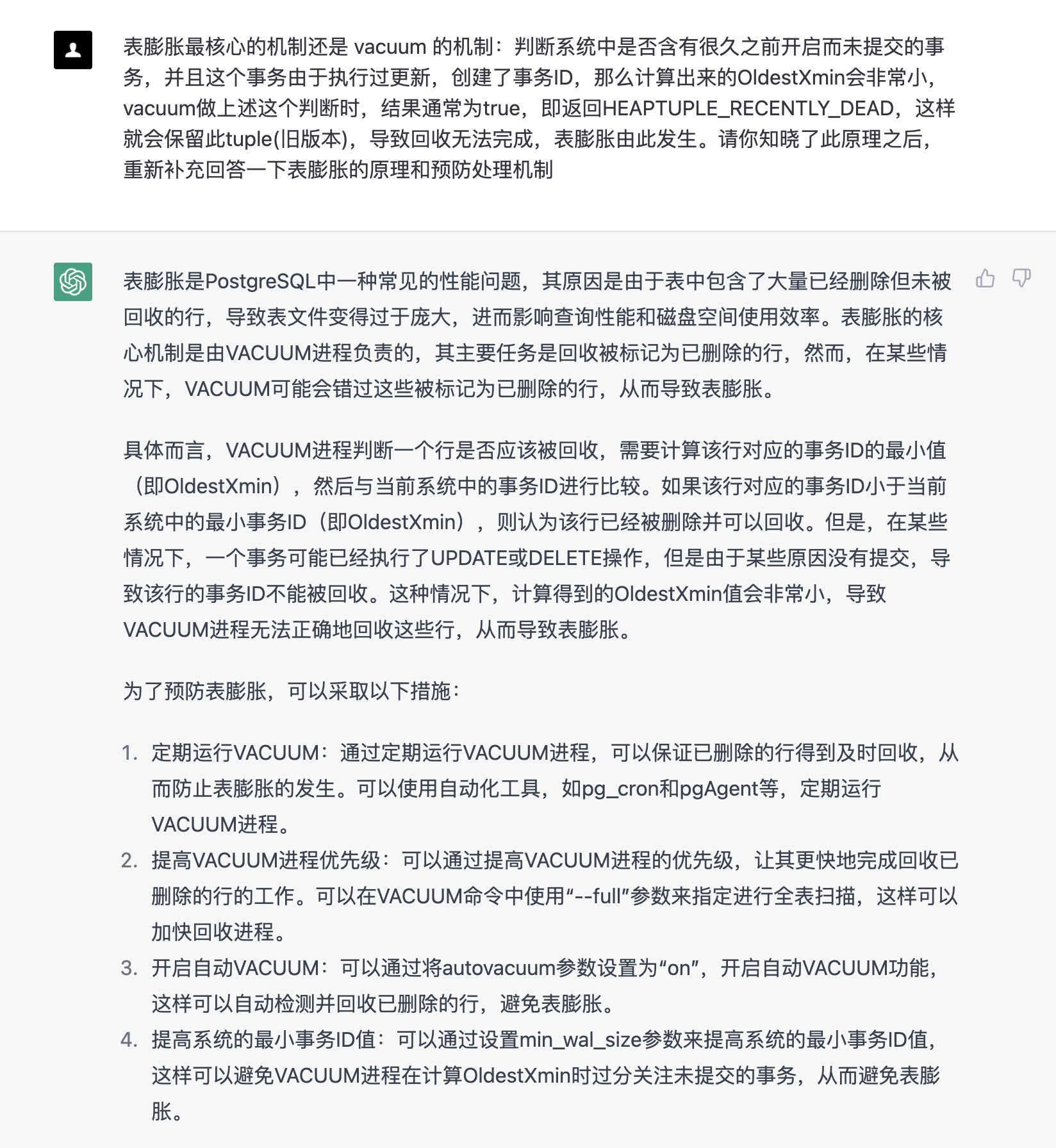
于是我去质疑了他。这一次的回答就有模有样了,并且还回答出了源码级的 HEAPTUPLE_RECENTLY_DEAD,另外原来它所谓的提升 OldestXmin 靠 min_wal_size 是因为
增加最小 WAL 大小可以减少 WAL 日志的切换次数,从而延长 WAL 日志的保存时间,提高了回收死亡元组的机会,从而也可以降低表膨胀的风险。

从这么一个例子可以看出,虽然 GPT 很强大,可以根据上下文语义进行分析,也能够回答连续问题,承认错误,质疑不正确的前提,并拒绝不合理的需求,但是始终缺少了一些东西,没错正是 DBA 在无数生产场景中摸爬滚打踩出来的经验,这个 GPT 是无法复刻的,资深 DBA 自身也是无法做到自我繁殖,这便是我们的不可替代性与价值所在,提升自己的不可替代性才是正解。
小结
ChatGPT 带来的工业革命其实已经在悄然发生,互联网的无边界,马太效应更加明显。互联网工具的唯一性,使得资源快速向头部集中。未来社会,可能 90% 的人都是分母。凭什么你能成为前10%,成为技术红利的享有者,甚至是技术标准的制定者?从前面的例子也能看出,资深的数据库专家真的不用愁,至少短期内的可替代性还很低。当然了,不学习,真的一点希望都没有。所以你要问我 DBA 的前景怎么样?我的回答是:资深专家始终吃香,是金子在哪里都能发光,而传统的 infra DBA 可能就要晦涩一点,不妨主动拥抱变革,提升自己的价值,不至于成为时代洪流里的一粒沙子。
工具既可以作弊,也可以成为你的助手。
