




让我们看一下对共识协议的分析。
今年春节期间,我读了一些关于共识协议的论文。在阅读这些论文之前,我一直想知道 ZooKeeper 的 ZAB 协议和 Raft 协议之间的实际区别是什么,两者都有一个领导者和一个两阶段提交,以及 Paxos 协议如何在实际工程中应用。这些论文为我提供了这些问题的答案。现在,我将尝试用我自己的话解释这些协议,以帮助您理解这些算法。同时,本文中也提到了一些问题,希望大家可以一起讨论。我对这些协议的了解可能有限,所以请纠正我错的地方。
逻辑时钟
逻辑时钟实际上并不是共识协议。这是Lamport在1987年提出的一个想法,旨在解决分布式系统中不同机器之间的时钟不一致可能导致的问题。在独立系统中,机器时间用于识别事件,以便我们可以清楚地识别两个不同事件的发生顺序。但是,在分布式系统中,由于时间偏差可能因机器而异,因此无法通过物理时钟确定事件顺序。实际上,在分布式系统中,我们只关注两个关联事件的顺序。考虑两个事务:一个是 A 行的修改,另一个是 B 行的修改。我们实际上并不关心这两笔交易中的哪一笔先发生。所谓的逻辑时钟是用来定义两个关联事件的发生顺序,即“之前发生”。逻辑时钟无法确定未关联事件的发生顺序。因此,这种“发生在之前”的关系实际上是一种偏序关系。
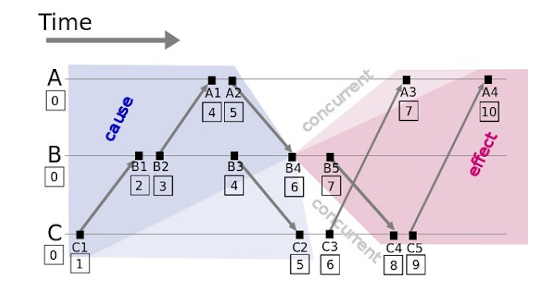
本文中的图表和示例来自此博客。
在此图中,箭头表示进程间通信;A、B 和 C 表示分布式系统中的三个进程。
逻辑时钟的算法非常简单:每个事件对应于一个Lamport时间戳(初始值为0)。
如果节点内发生事件,则时间戳值将加 1。
如果事件是发送事件,则时间戳将添加 1,时间戳将添加到该消息中。
如果事件是接收事件,则时间戳为 Max(消息中的本地时间戳)加 1。
对于所有关联的发送和接收事件,这可以确保发送事件的时间戳小于接收事件的时间戳。如果两个事件(例如,A3 和 B5)未关联,则它们具有相同的逻辑时间。我们可以根据需要定义两个事件的发生顺序,因为这两个事件没有关联。例如,如果进程 A 发生在进程 B 之前,而进程 C 发生在 Lamport 时间戳相同时,我们可以得出“A3 发生在 B5 之前”的结论。然而,在物理世界中,B5发生在A3之前。不过这并不重要。
目前逻辑时钟似乎没有被广泛应用。DynamoDB 使用矢量时钟来求解多个版本的时间顺序。请通知我我不知道的任何其他特定应用程序。谷歌的Spanner也使用物理时钟来解决时钟问题。但是,我们可以从Lamport的逻辑时钟算法中看到共识协议的原型。
复制状态机
当谈到共识协议时,我们通常谈论状态机复制。通常状态机复制和共识协议算法一起使用,以实现分布式系统的高可用性和容错。许多分布式系统使用状态机复制来同步副本之间的数据,例如HDFS,Chubby和Zookeeper。
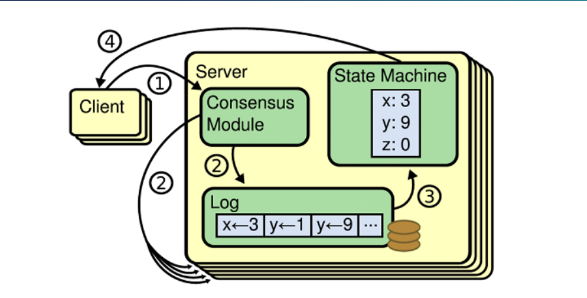
状态机复制在分布式系统中的每个实例副本中维护一个持久日志,并使用一定的共识协议算法来保证日志在每个实例内完全一致。这样,实例中的状态机将逐个日志序列回放日志中的每个命令,以便在客户端读取数据时从每个副本读取相同的数据。状态机复制的核心是图中所示的共识模块,它包含在我们今天要讨论的共识协议算法中。
帕克索斯
Paxos是Lamport在1990年代开发的共识协议算法。人们普遍认为很难理解。因此,Lamport在2001年发表了一篇新论文《Paxos Made Simple》,他在论文中表示,Paxos是世界上最简单的共识算法,非常容易理解。但是,在这个行业中,它仍然普遍被认为难以理解。在阅读了Lamport的论文之后,我认为Paxos协议本身并不难理解,除了争论正确性的复杂过程。然而,Paxos协议过于理论化,远未应用于具体的工程实践。当我第一次了解Paxos协议时,我也感到非常困惑。我多次阅读论文,发现该协议仅用于单事件共识,并且无法修改约定值。如何使用Paxos实现状态机复制?此外,只有提议者和追随者知道基于Paxos协议的商定值。我们如何实际使用这个协议?但是,如果您只从理论上考虑该协议,而不考虑实际工程中可能出现的问题,则Paxos协议要容易得多。在Lamport的论文中,状态机的应用只是一个一般的想法,不包括具体的实现逻辑。直接使用 Paxos 进行状态机复制是不可能的。相反,我们需要为Paxos添加很多东西。这就是为什么Paxos有这么多变体的原因。
基本和平
Basic Paxos是Lamport首先提出的Paxos算法。其实很简单,只需几句话就能解释。接下来,我将用我自己的话来描述Paxos,并举一个例子。要理解Paxos,只需记住一件事:Paxos只能为一个值达成共识,一旦决定,提案就不能改变。也就是说,整个Paxos集团只接受一个提案(或几个具有不同价值观的提案)。有关如何接受多个值来实现状态机复制,请参阅下一节中的 Multi Paxos。
Paxos协议没有Leader概念。除了学习者(只学习提议的结果;这里不讨论),Paxos中只有提议者和接受者可用。Paxos允许多个提议者同时提出一个数字。提议者提出一个值,并试图说服所有接受者就该值达成一致。在准备阶段,提议者向每个接受者发送一个提议者ID n(请注意,提议者在此阶段不会将值传递给接受者)。如果接受方发现它从未从任何提议者那里收到过大于 n 的值,它将回复提议者并承诺不接收 ProposeID 小于或等于 n 的提案的准备消息。如果接受人已经承诺了一个大于n的建议数字,则不会回复提议者。如果接受者接受了小于 n 的提案(在第 2 阶段),它将向提议者返回此提议值。否则,将返回空值。当投标人收到一半以上接受者的回复时,即可开始接受阶段。但是,在此阶段,投标人可以提出的值是有限的。当且仅当收到的答复不包括以前提案的值时,投标人才能提出新的价值。否则,提议者只能使用答复中最大的建议值作为建议值。提议者使用此值和提议 ID n 针对每个接受者启动接受请求。也就是说,即使提议人已经收到接受人的承诺,接受也可能失败,因为接受人可能在接受发起之前已经向具有更高提议ID的提议者做出了承诺。换句话说,即使第一阶段成功,第二阶段仍可能由于多个投标人的存在而失败。
我将提供一个例子,该示例来自此博客。
考虑三台服务器:服务器 1、服务器 2 和服务器 3。他们都希望使用Paxos协议让所有成员都同意他们是领导者。这些服务器是提议者角色,它们建议的值是它们的名称。他们需要三个成员的同意:接受者 1-3。服务器 2 启动提案 1(以 1 作为提议 ID),服务器 1 发起提案 2,服务器 3 发起提案 3。
首先,它是准备阶段:
假设从 Server1 发送的消息首先到达接受器 1 和接受器 2,这两个都尚未收到请求。因此,它们接收此请求并将 [2, null] 返回到 Server1。同时,他们承诺不会收到 ID 小于 2 的请求;
然后,从 Server2 发送的消息到达接受器 2 和接受器 3,并且接受器 3 尚未收到请求。因此,接受器 3 将 [1, null] 返回给提议者 2,并承诺不接收 ID 小于 1 的消息。由于接受方 2 已收到来自 Server1 的请求,并承诺不接收 ID 小于 2 的请求,因此接受方 2 将拒绝来自 Server2 的请求。
最后,来自 Server3 的消息到达接受器 2 和接受器 3,这两个都已收到建议。但是,由于此消息的 ID 大于 2(接受器 2 收到的消息的 ID)和 1(接受器 3 收到的消息的 ID),因此接受器 2 和接受器 3 都会收到此建议并将 [3, null] 返回到 Server3。
此时,由于 Server2 未收到超过一半的回复,因此它会获取一条 ID 为 4 的新消息,并将此消息发送给接受器 2 和接受器 3。由于 4 大于 3(接受器 2 和接受器 3 收到的提案的最大 ID),因此将收到此提案并将 [4, null] 返回到 Server2。
接下来,是接受阶段:
由于 Server3 已收到一半以上的回复(2 个回复),并且返回值为 null,因此 Server3 提交提案 [3, server3]。
由于 Server1 在准备阶段也收到了一半以上的回复,并且返回的值为 null,因此 Server1 提交提案 [2, server1]。
由于 Server2 也收到了一半以上的回复,并且返回的值为 null,因此 Server2 提交提案 [4, server2]。
当接受方 1 和接受方 2 从服务器 2 收到提案 [1, server1] 时,接受方 1 接受此请求,接受方 2 拒绝此请求,因为它已承诺不接受 ID 小于 4 的建议。
接受方 2 和接受方 3 在收到来自服务器 4 的建议 [2, server2] 时接受该建议。
接受者 2 和接受者 3 将拒绝来自 Server3 的提案 [3, server3],因为它们已承诺不接受 ID 小于 4 的提案。
此时,超过一半的接受者(接受者 2 和接受者 3)已接受提案 [4,服务器 2]。学习者感知到提案已通过并开始学习提案。因此,Server2 成为最终的领导者。
多派克索斯
如前所述,Paxos处于理论阶段,不能直接用于状态机复制。原因如下:
- Paxos 只能确定一个值,不能用于连续日志复制。
- 多个提议者的存在可能会导致活锁。在前面的示例中,Server2 在最终接受提案之前提交建议两次。在某些极端情况下,可能需要提交更多的提案。
- 提案的最终结果只有部分接受者知道。这不能保证状态机复制的每个实例都具有完全一致的日志。
事实上,Multi-Paxos实际上是用来解决上述三个问题的,因此Paxos协议可以用于状态机。解决第一个问题非常简单。日志条目的每个索引值都使用一个独立的Paxos实例。解决第二个问题也很容易:一个Paxos组中只包含一个提议者,在读取时使用Paxos协议选择一个领导者(如上例所示),并让这个领导者执行读取以避免活锁问题。此外,单个领导者允许我们在准备阶段省略大部分工作。选择领导者后,只需启动一次准备即可。如果没有接受者收到来自其他领导者的准备请求,则每次写入请求时直接接受请求,除非接受者拒绝请求(拒绝表示新领导者正在执行写入请求)。为了解决第三个问题,Multi-Paxos为每个服务器添加一个firstUnchosenIndex,并让领导者将选定的值同步到每个接受器。这些问题解决后,Paxos就可以用于实际工程。
到目前为止,Paxos有许多新增功能和变体。事实上,我将在后面讨论的ZAB和Raft可以看作是Paxos的修改和变体。一个流传的说法是“世界上只存在一种共识算法,那就是Paxos。
扎布
ZAB(ZooKeeper Atomic BoardCast)是ZooKeeper中使用的共识协议。ZAB是Zookeeper的专用协议。它与Zookeeper紧密绑定,尚未提取到独立的数据库中。因此,ZAB没有被广泛使用,仅限于Zookeeper。然而,关于ZAB协议的论文充分证明了ZAB具有满足强一致性要求的能力。
ZAB与Zookeeper一起诞生于2007年。当时还没有开发Raft协议。根据ZAB上的论文,Zookeeper并没有直接使用Paxos,而是开发了自己的协议,因为Paxos被认为无法满足Zookeeper的要求。例如,Paxos允许多个提议者可能会导致从客户端提交的多个命令无法通过FIFO序列执行。此外,在恢复过程中,某些关注者的数据可能不完整。这些参数基于原始的Paxos协议。事实上,这些问题已经在Paxos的某些变体中得到解决。由于历史原因,最初的Paxos协议未能解决上述问题。因此,Zookeeper 开发人员决定开发一个新的共识协议——ZAB。
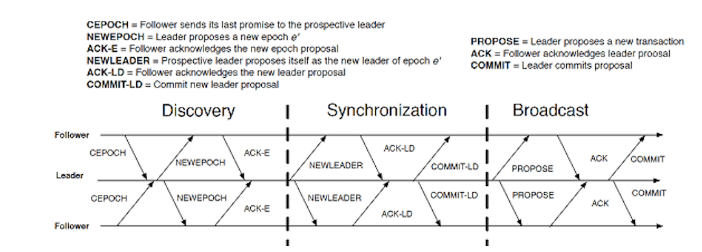
ZAB与随后的Raft协议非常相似。ZAB 负责选择领导者以及恢复。写入也是通过使用两阶段提交来执行的。首先,由领导者发起一轮投票。在接受超过一半的选票后,将启动提交。ZAB 中每个领导者的纪元数实际上相当于我稍后将要谈到的 Raft 中的术语。但是,在 ZAB 中,纪元数和转移数构成一个 zxid,它存储在每个条目中。
ZAB 通过使用两阶段提交启用日志复制。第一阶段是投票。当获得一半以上的同意票时,此阶段成功完成。在此阶段,数据并未真正传递给关注者。这是为了确保一半以上的计算机正常工作或在同一网络分区内。第二个是提交阶段。在此阶段,数据被传输到每个追随者,然后每个追随者(以及领导者)将数据附加到日志中。此时,写入操作已完成。在第一阶段投票是否成功,但在第二阶段的追随者失败并不重要。重启领导者可以保证追随者的数据与领导者的数据一致。如果领导者在提交阶段失败,并且此写入操作已在至少一个追随者上提交,则该追随者肯定会被选为领导者,因为它的 zxid 最大。被选为领导者后,此关注者允许所有关注者提交此消息。如果在领导者失败时没有追随者提交此消息,则此写入操作不会完成。
由于日志只需要在提交时追加,因此 ZAB 日志只需要仅追加功能。
此外,ZAB 支持从副本进行过时读取。为了实现强一致性读取,我们可以使用同步读取。以下是它的工作原理:首先,启动虚拟写入操作(不写入任何内容)。完成此操作后,还会在本地提交此同步操作。然后对本地副本执行读取,以确保正确读取此同步时间点之前的所有数据。但是,Raft 协议下的读取和写入是通过主节点执行的。
筏
Raft 是斯坦福大学开发人员于 2014 年开发的新共识协议。开发人员开发了这个新的共识协议,因为他们认为Paxos很难理解。此外,Paxos只是一个理论,远未应用于实际工程。Paxos的开发者列出了Paxos的一些缺点:
- Paxos协议不需要领导者。每个投标人都可以创建一个提案。领导者选择和共识协议在设计Raft之初是分开的,而在Paxos中领导者选择和提案是混合在一起的,这使得Paxos难以理解。
- 最初的Paxos协议只是为了在一个事件上达成共识。一旦确定值,就无法对其进行修改。但是,在实际场景(包括数据库一致性)中,需要不断就日志条目的值达成共识。因此,Paxos协议本身无法满足要求:我们需要对Paxos协议进行一些改进和补充,以真正意义上将Paxos应用于工程。对Paxos协议进行补充是非常复杂的。尽管 Paxos 协议已经被 Lamport 验证,但基于 Paxos 和改进的算法(如 Multi-Paxos)尚未得到证实。
- 另一个缺点是Paxos只提供粗略的描述。这就要求Paxos的后续改进和使用Paxos的项目(如Google Chubby)必须实现一系列项目来解决Paxos中的特定问题。像Chubby这样的项目的实施细节没有公开。也就是说,要在您自己的项目中应用Paxos,您必须自定义和实现一组满足您特定需求的Paxos协议。
因此,Raft 的开发人员在设计 Raft 时有一个明确的目标:使该协议更易于理解,并在有多种 Raft 设计解决方案可用的情况下选择最易于理解的设计解决方案。开发人员提供了一个例子。在 Raft 协议的领导者选择阶段,一种可能的解决方案是为每个服务器附加一个 ID,让所有服务器选择具有最大 ID 的服务器作为领导者,以快速达成共识(类似于 ZAB 协议)。但是,此解决方案还有一个附加概念 — 服务器 ID。同时,如果具有较高 ID 的服务器发生故障,则具有较小 ID 的服务器必须等待一段时间才能被选为新领导者,这可能会影响可用性。Raft 使用了一个非常简单的领导者选择解决方案:每个服务器休眠一段时间,首先唤醒的服务器提出建议;如果此服务器获得多数票,则将其选为领导者。在一般的网络环境中,首先进行投票的服务器也将首先收到其他投票的投票。因此,只需要一轮投票就可以选出领导者。整个领导者选择过程非常简单。
除了领导者选择,Raft 协议的整体设计也很简单。如果不考虑快照和成员数量的变化,则领导者和追随者之间的交互总共需要两个 RPC 调用。两个调用中的一个是 RequestVote,它仅在领导者选择时才需要。也就是说,所有数据交互都由 AppendEntries RPC 执行。
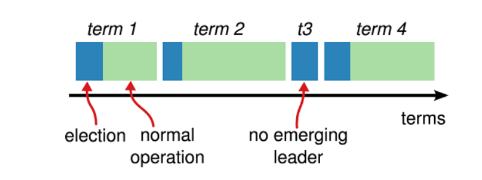
要理解 Raft 协议算法,我们需要先看一下 Term 概念。每个领导者都有自己的术语,该术语将应用于日志的每个条目中,以表示该条目是用哪个术语编写的。此外,期限相当于租约。如果领导者未在指定时间段内发送检测信号(发送检测信号也由 AppendEntries RPC 调用完成),则追随者将认为领导者失败,并在它收到的最大任期上加 1 以形成新任期并开始新的选举。如果候选人的任期不高于该追随者的任期,追随者将否决这些候选人,以确保所选的新领导者具有最高任期。如果在超时之前没有关注者收到足够的投票(这种情况是可能的),则关注者将在当前术语中添加 1 并开始新的投票请求,直到选择新的领导者。Raft 最初是用 C 语言实现的。可以设置非常短的超时(通常以毫秒为单位)。因此,在Raft中,可以在几十毫秒内检测到发生故障的领导者,并且故障恢复时间可以非常短。对于使用 Raft 在 Java 中实现的数据库(如 Ratis),我估计在考虑 GC 时间时不可能设置这么短的超时。
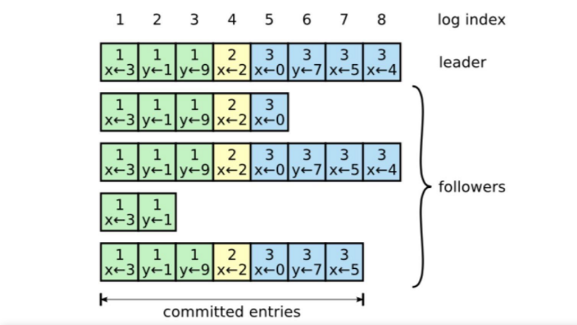
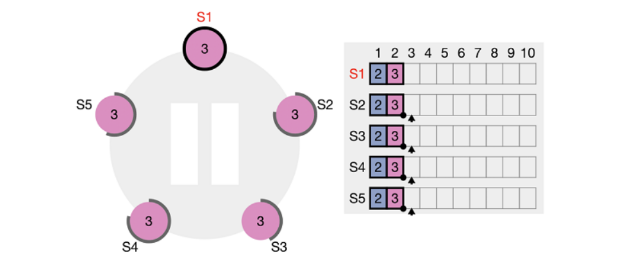
领导者的写入操作也是一个两阶段的提交过程。首先,领导者将写入在其自己的日志中找到的第一个空索引,并通过 AppendEntries RPC 将该条目的值发送给每个关注者。如果领导者从超过一半的追随者(包括他们自己)那里收到“true”,则在接下来的 AppendEntry 中,领导者在 committedIndex 中添加 1,表示已提交书面条目。如下图所示,领导者将 x=4 写入索引 = 8 的条目,并将其发送给所有追随者。在收到第一台服务器(领导者本身)、第三台服务器和第五台服务器的投票后(图中没有显示 index=8 的条目,但该服务器肯定会给出同意票,因为该服务器之前的所有条目都与领导者一致),领导者获得多数票。在下一个 RPC 中,已提交的索引将增加 1,表示已提交具有 index≤8 的所有条目。第二台服务器和第四台服务器的日志内容明显滞后。一个原因是,在之前的 RPC 调用失败后,领导者将重试,直到追随者的日志更新为领导者的日志。另一个原因是两台服务器已重新启动,当前处于恢复状态。当两台服务器收到写入 index=8 的条目的 RPC 时,追随者也会将最后一个条目的术语和索引发送到这些服务器。也就是说,prevLogIndex=7 和 prevLogTerm=3 的消息将被发送到第二个服务器。对于第二台服务器,索引=7 的条目为空(即日志与 leader 不一致)。它将向领导者返回“false”,领导者将无限期地向后遍历,直到找到与第二个服务器的日志内容一致的条目。从那时起,领导者的日志内容将重新发送给追随者以完成恢复。Raft 协议确保所有成员的复制日志中的每个索引都具有一致的内容(如果它们的术语一致)。如果内容不一致,领导者将修改该索引的内容,使其与领导者一致。
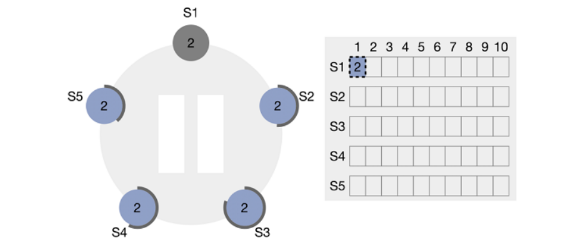
实际上,我之前的描述几乎已经完全解释了 Raft 中的领导者选择、写作和恢复。我们可以找到一些关于Raft的有趣方面。
第一个有趣的方面是可以修改 Raft 中的日志条目。例如,追随者从领导者接收 Prepare 请求,并将值写入索引。如果该领导者失败,新当选的领导者可以重复使用此索引,并且该追随者的索引内容可能会被修改。这会导致两个问题:Raft 中的日志无法在仅追加文件或文件系统中实现。对于 ZAB 和 Paxos 协议,仅附加日志。这只需要文件系统具有追加功能,不需要随机访问和修改功能。
第二个有趣的方面是,Raft 中只维护一个 Commit 索引以确保简单性。也就是说,任何小于或等于此已提交索引的条目都将被视为已提交。这会导致领导者在编写过程中获得多数选票之前(或者在领导者可以通知任何追随者它已编写自己的日志之前)失败。如果在重新启动后再次选择此服务器作为主服务器,则仍将提交此值并使其永久有效。因为这个值包含在领导者的日志中,所以领导者肯定会确保所有追随者的日志与自己的日志一致。默认情况下,此值将在执行后续写入并增加提交索引后提交。
例如,考虑五台服务器。S1 是领导者。当 S1 写入 index=1 的条目时,它会先将数据写入自己的日志,并经历停机,然后才能通知其他服务器追加的条目。
重启后,S1可能仍有机会当选为领导者。当再次选择 S1 作为领导者时,它仍将 index=1 的条目复制到每个服务器(但是,提交的索引不会向前移动)。
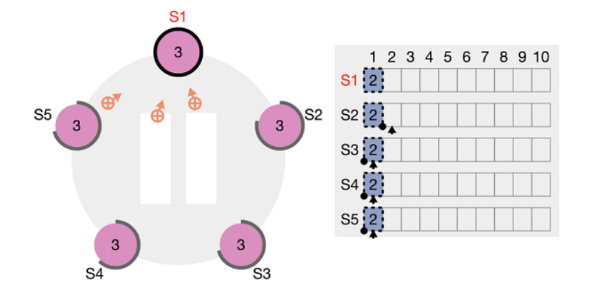
此时,S1 执行另一个写入操作。写入完成后,已提交的索引将移动到位置 2。因此,索引=1 的条目也被视为已提交。
这种行为有点奇怪,因为它等同于意味着 Raft 允许在未经大多数人同意的情况下提交值。此行为取决于领导者。在前面的示例中,如果重启后没有选择 S1 作为领导者,则 index=1 的条目内容将被新领导者的内容覆盖,没有经历投票阶段的内容将不会提交。
虽然这种行为有点奇怪,但并不会造成任何问题,因为领导者和追随者会达成共识。此外,领导者在写入过程中的失败是客户端的挂起语义。Raft上的论文还说,如果需要“恰好一次”的语义,用户需要在写入过程中添加类似UUID的东西,以允许领导者在写入操作之前检查UUID是否已写入。这可以在一定程度上保证“恰好一次”的语义。
关于Raft的论文还将Raft与ZAB算法进行了比较。ZAB 协议的一个缺点是,在恢复阶段,领导者和追随者之间需要交换数据。我真的不明白这一点。在我看来,在 ZAB 中重新选择领导者时,将选择具有最大 Zxid 的服务器作为领导者,其他追随者将从领导者那里完成数据 - 不是领导者从追随者那里完成其数据的情况。
结语
目前,改进后的Paxos协议已经应用于许多分布式产品中,例如Chubby,PaxosStore,阿里云X-DB和蚂蚁金服OceanBase。人们普遍认为 Raft 协议的性能低于 Paxos,因为它只允许按顺序提交条目。不过,使用 Raft 的 TiKV 官方宣称,它在 Raft 上做了很多优化,对 Raft 的性能有了显著提升。POLARDB是另一个阿里云数据库,它也使用Parallel-Raft(Raft的改进版本)在Raft中实现并行提交功能。我相信未来会有更多基于Paxos/Raft的产品上市,并且会对Raft/Paxos进行更多改进。
引用
- 分布式系统中的时间、时钟和事件顺序
- 使用状态机方法实现容错服务 — 教程
- 帕克索斯变得简单
- Paxos上线 — 工程视角
- Multi-Paxos(斯坦福大学的一个PPT演示)
- Zab — 主备份系统的高性能广播
- 寻找可理解的共识算法(Raft)
