




TutorialsPoint impala 教程
来源:W3CSchool
impala 概述
什么是Impala?
Impala是用于处理存储在Hadoop集群中的大量数据的MPP(大规模并行处理)SQL查询引擎。 它是一个用C ++和Java编写的开源软件。 与其他Hadoop的SQL引擎相比,它提供了高性能和低延迟。
换句话说,Impala是性能最高的SQL引擎(提供类似RDBMS的体验),它提供了访问存储在Hadoop分布式文件系统中的数据的最快方法。
为什么选择Impala?
Impala通过使用标准组件(如HDFS,HBase,Metastore,YARN和Sentry)将传统分析数据库的SQL支持和多用户性能与Apache Hadoop的可扩展性和灵活性相结合。
- 使用Impala,与其他SQL引擎(如Hive)相比,用户可以使用SQL查询以更快的方式与HDFS或HBase进行通信。
- Impala可以读取Hadoop使用的几乎所有文件格式,如Parquet,Avro,RCFile。
Impala将相同的元数据,SQL语法(Hive SQL),ODBC驱动程序和用户界面(Hue Beeswax)用作Apache Hive,为面向批量或实时查询提供熟悉且统一的平台。
与Apache Hive不同,Impala不基于MapReduce算法。 它实现了一个基于守护进程的分布式架构,它负责在同一台机器上运行的查询执行的所有方面。
因此,它减少了使用MapReduce的延迟,这使Impala比Apache Hive快。
Impala的优点
以下是Cloudera Impala的一些值得注意的优点的列表。
- 使用impala,您可以使用传统的SQL知识以极快的速度处理存储在HDFS中的数据。
- 由于在数据驻留(在Hadoop集群上)时执行数据处理,因此在使用Impala时,不需要对存储在Hadoop上的数据进行数据转换和数据移动。
- 使用Impala,您可以访问存储在HDFS,HBase和Amazon s3中的数据,而无需了解Java(MapReduce作业)。您可以使用SQL查询的基本概念访问它们。
- 为了在业务工具中写入查询,数据必须经历复杂的提取 - 变换负载(ETL)周期。但是,使用Impala,此过程缩短了。加载和重组的耗时阶段通过新技术克服,如探索性数据分析和数据发现,使过程更快。
- Impala正在率先使用Parquet文件格式,这是一种针对数据仓库场景中典型的大规模查询进行优化的柱状存储布局。
Impala的功能
以下是cloudera Impala的功能 -
- Impala可以根据Apache许可证作为开源免费提供。
- Impala支持内存中数据处理,即,它访问/分析存储在Hadoop数据节点上的数据,而无需数据移动。
- 您可以使用Impala使用类SQL查询访问数据。
- 与其他SQL引擎相比,Impala为HDFS中的数据提供了更快的访问。
- 使用Impala,您可以将数据存储在存储系统中,如HDFS,Apache HBase和Amazon s3。
- 您可以将Impala与业务智能工具(如Tableau,Pentaho,Micro策略和缩放数据)集成。
- Impala支持各种文件格式,如LZO,序列文件,Avro,RCFile和Parquet。
- Impala使用Apache Hive的元数据,ODBC驱动程序和SQL语法。
关系数据库和Impala
Impala使用类似于SQL和HiveQL的Query语言。 下表描述了SQL和Impala查询语言之间的一些关键差异。
Impala | 关系型数据库 |
Impala使用类似于HiveQL的类似SQL的查询语言。 | 关系数据库使用SQL语言。 |
在Impala中,您无法更新或删除单个记录。 | 在关系数据库中,可以更新或删除单个记录。 |
Impala不支持事务。 | 关系数据库支持事务。 |
Impala不支持索引。 | 关系数据库支持索引。 |
Impala存储和管理大量数据(PB)。 | 与Impala相比,关系数据库处理的数据量较少(TB)。 |
Hive,Hbase和Impala
虽然Cloudera Impala使用与Hive相同的查询语言,元数据和用户界面,但在某些方面它与Hive和HBase不同。 下表介绍了HBase,Hive和Impala之间的比较分析。
HBase | Hive | Impala |
HBase是基于Apache Hadoop的宽列存储数据库。 它使用BigTable的概念。 | Hive是一个数据仓库软件。 使用它,我们可以访问和管理基于Hadoop的大型分布式数据集。 | Impala是一个管理,分析存储在Hadoop上的数据的工具。 |
HBase的数据模型是宽列存储。 | Hive遵循关系模型。 | Impala遵循关系模型。 |
HBase是使用Java语言开发的。 | Hive是使用Java语言开发的。 | Impala是使用C ++开发的。 |
HBase的数据模型是无模式的。 | Hive的数据模型是基于模式的。 | Impala的数据模型是基于模式的。 |
HBase提供Java,RESTful和Thrift API。 | Hive提供JDBC,ODBC,Thrift API。 | Impala提供JDBC和ODBC API。 |
支持C,C#,C ++,Groovy,Java PHP,Python和Scala等编程语言。 | 支持C ++,Java,PHP和Python等编程语言。 | Impala支持所有支持JDBC / ODBC的语言。 |
HBase提供对触发器的支持。 | Hive不提供任何触发器支持。 | Impala不提供对触发器的任何支持。 |
所有这三个数据库 -
- 是NOSQL数据库。
- 可用作开源。
- 支持服务器端脚本。
- 按照ACID属性,如Durability和Concurrency。
- 使用分片进行分区。
Impala的缺点
使用Impala的一些缺点如下 -
- Impala不提供任何对序列化和反序列化的支持。
- Impala只能读取文本文件,而不能读取自定义二进制文件。
- 每当新的记录/文件被添加到HDFS中的数据目录时,该表需要被刷新。
impala 环境
本章介绍了安装Impala的先决条件,如何在系统中下载,安装和设置Impala。
与Hadoop及其生态系统软件类似,我们需要在Linux操作系统上安装Impala。 由于cloudera提供Impala,因此它可用于Cloudera Quick Start VM。
本章介绍如何下载Cloudera Quick Start VM并启动Impala。
下载Cloudera快速启动VM
按照以下步骤下载最新版本的Cloudera QuickStartVM。
第1步
打开cloudera网站的主页http://www.cloudera.com/。 您将获得如下所示的页面。
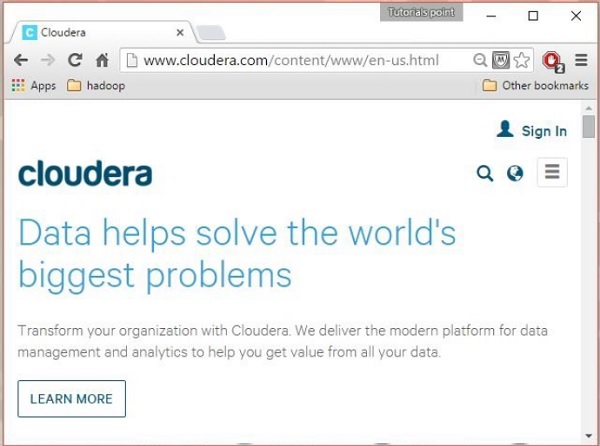
第2步
单击cloudera主页上的登录链接,这将重定向到如下所示的登录页面。
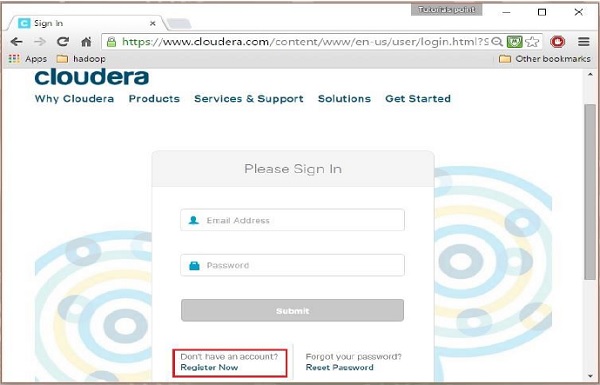
如果您尚未注册,请点击“立即注册”链接,这将为您提供帐户注册表。 在这里注册并登录cloudera帐户。
第3步
登录后,通过单击以下快照中突出显示的“下载”链接打开cloudera网站的下载页面。
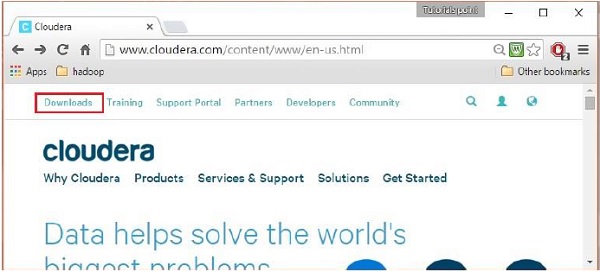
第4步 - 下载QuickStartVM
通过单击“立即下载”按钮下载cloudera QuickStartVM,如以下快照中突出显示的
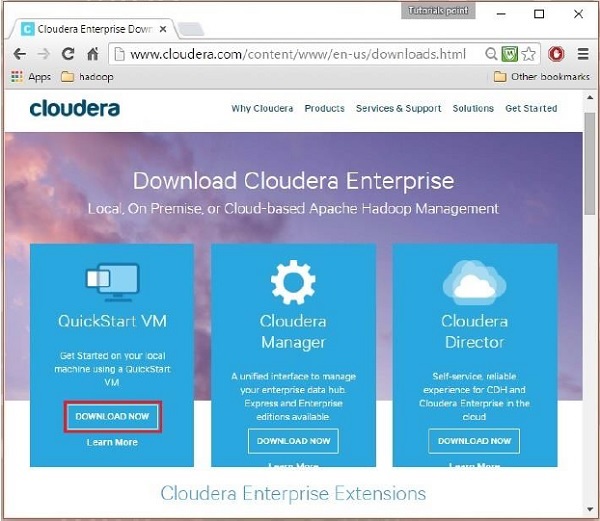
这将重定向到QuickStart VM的下载页面。
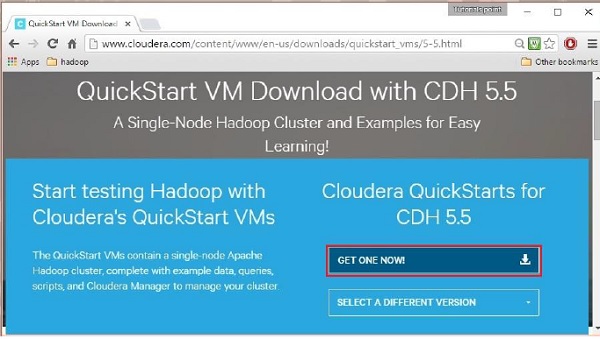
单击Get ONE NOW按钮,接受许可协议,然后单击提交按钮,如下所示。
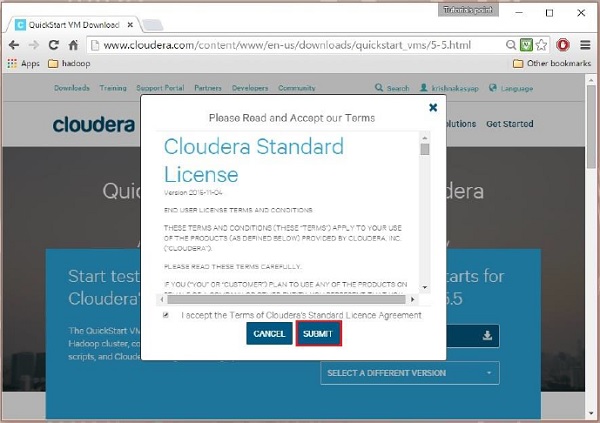
Cloudera提供与VM兼容的VMware,KVM和VIRTUALBOX。 选择所需的版本。 在我们的教程中,我们演示了使用虚拟框的Cloudera QuickStartVM设置,因此点击VIRTUALBOX下载按钮,如下面的快照所示。
这将开始下载名为cloudera-quickstart-vm-5.5.0-0-virtualbox.ovf的文件,这是一个虚拟盒图像文件。
导入Cloudera QuickStartVM
在下载cloudera-quickstart-vm-5.5.0-0-virtualbox.ovf文件后,我们需要使用虚拟盒导入它。 为此,首先,您需要在系统中安装虚拟盒。 按照以下步骤导入下载的映像文件。
第1步
从以下链接下载虚拟框,并安装它https://www.virtualbox.org/
第2步
打开虚拟盒软件。 单击文件,然后选择导入设备,如下所示。
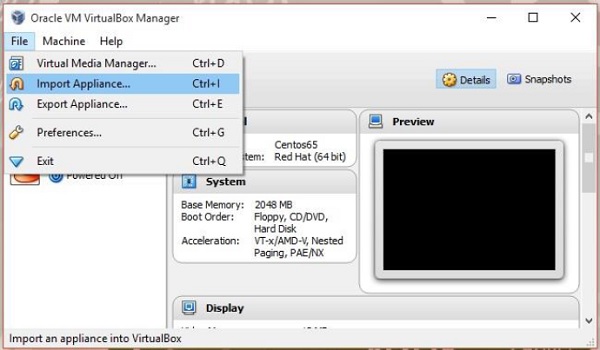
第3步
在单击导入设备时,您将获得导入虚拟设备窗口。 选择下载的图像文件的位置,如下所示。
导入Cloudera QuickStartVM映像后,启动虚拟机。 此虚拟机具有Hadoop,cloudera Impala和安装的所有必需的软件。 虚拟机的快照如下所示。
启动Impala Shell
要启动Impala,请打开终端并执行以下命令。
[cloudera@quickstart ~] $ impala-shell
这将启动Impala Shell,显示以下消息。
Starting Impala Shell without Kerberos authentication
Connected to quickstart.cloudera:21000
Server version: impalad version 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
********************************************************************************
Welcome to the Impala shell. Copyright (c) 2015 Cloudera, Inc. All rights reserved.
(Impala Shell v2.3.0-cdh5.5.0 (0c891d7) built on Mon Nov 9 12:18:12 PST 2015)
Press TAB twice to see a list of available commands.
********************************************************************************
[quickstart.cloudera:21000] >
注意 - 我们将在后面的章节讨论所有impala-shell命令。
Impala查询编辑器
除了Impala shell之外,您还可以使用Hue浏览器与Impala进行通信。 安装CDH5并启动Impala后,如果打开浏览器,您将获得cloudera主页,如下所示。
现在,单击书签Hue以打开Hue浏览器。 在点击时,您可以看到Hue浏览器的登录页面,使用凭证cloudera和cloudera进行日志记录。
一旦您登录到Hue浏览器,您可以看到Hue浏览器的快速启动向导如下所示。
在单击查询编辑器下拉菜单时,您将获得Impala支持的编辑器列表,如以下屏幕截图所示。
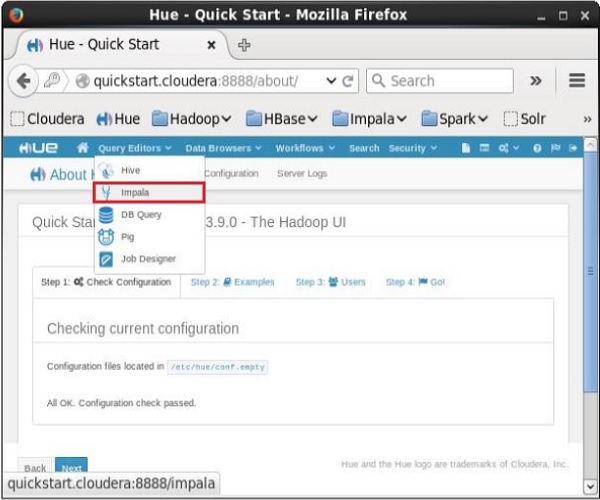
在下拉菜单中单击Impala时,您将获得Impala查询编辑器,如下所示。
impala 架构
Impala是在Hadoop集群中的许多系统上运行的MPP(大规模并行处理)查询执行引擎。 与传统存储系统不同,impala与其存储引擎解耦。 它有三个主要组件,即Impala daemon(Impalad),Impala Statestore和Impala元数据或metastore。
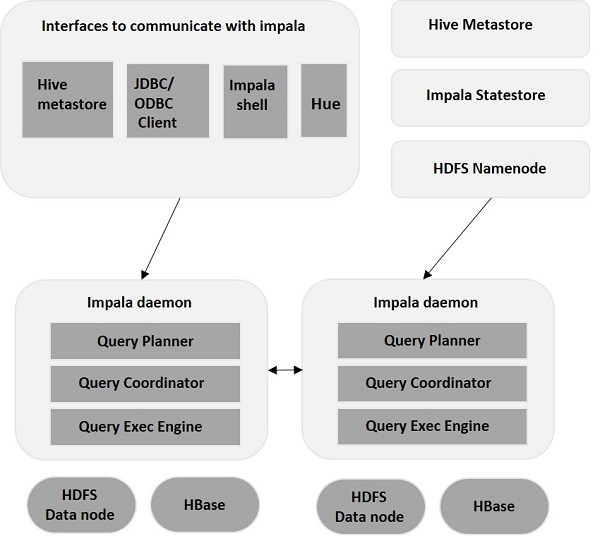
Impala daemon(Impalad)
Impala daemon(也称为impalad)在安装Impala的每个节点上运行。 它接受来自各种接口的查询,如impala shell,hue browser等...并处理它们。
每当将查询提交到特定节点上的impalad时,该节点充当该查询的“协调器节点”。 Impalad还在其他节点上运行多个查询。 接受查询后,Impalad读取和写入数据文件,并通过将工作分发到Impala集群中的其他Impala节点来并行化查询。 当查询处理各种Impalad实例时,所有查询都将结果返回到中央协调节点。
根据需要,可以将查询提交到专用Impalad或以负载平衡方式提交到集群中的另一Impalad。
Impala 存储的状态
Impala有另一个称为Impala State存储的重要组件,它负责检查每个Impalad的运行状况,然后经常将每个Impala Daemon运行状况中继给其他守护程序。 这可以在运行Impala服务器或群集中的其他节点的同一节点上运行。
Impala State存储守护进程的名称为存储的状态。 Impalad将其运行状况报告给Impala State存储守护程序,即存储的状态。
在由于任何原因导致节点故障的情况下,Statestore将更新所有其他节点关于此故障,并且一旦此类通知可用于其他impalad,则其他Impala守护程序不会向受影响的节点分配任何进一步的查询。
Impala元数据和元存储
Impala元数据和元存储是另一个重要组件。 Impala使用传统的MySQL或PostgreSQL数据库来存储表定义。 诸如表和列信息和表定义的重要细节存储在称为元存储的集中式数据库中。
每个Impala节点在本地缓存所有元数据。 当处理极大量的数据和/或许多分区时,获得表特定的元数据可能需要大量的时间。 因此,本地存储的元数据缓存有助于立即提供这样的信息。
当表定义或表数据更新时,其他Impala后台进程必须通过检索最新元数据来更新其元数据缓存,然后对相关表发出新查询。
查询处理接口
要处理查询,Impala提供了三个接口,如下所示。
- Impala-shell - 使用Cloudera VM设置Impala后,可以通过在编辑器中键入impala-shell命令来启动Impala shell。 我们将在后续章节中更多地讨论Impala shell。
- Hue界面 - 您可以使用Hue浏览器处理Impala查询。 在Hue浏览器中,您有Impala查询编辑器,您可以在其中键入和执行impala查询。 要访问此编辑器,首先,您需要登录到Hue浏览器。
- ODBC / JDBC驱动程序 - 与其他数据库一样,Impala提供ODBC / JDBC驱动程序。 使用这些驱动程序,您可以通过支持这些驱动程序的编程语言连接到impala,并构建使用这些编程语言在impala中处理查询的应用程序。
查询执行过程
每当用户使用提供的任何接口传递查询时,集群中的Impalads之一就会接受该查询。 此Impalad被视为该特定查询的协调程序。
在接收到查询后,查询协调器使用Hive元存储中的表模式验证查询是否合适。 稍后,它从HDFS名称节点收集关于执行查询所需的数据的位置的信息,并将该信息发送到其他impalad以便执行查询。
所有其他Impala守护程序读取指定的数据块并处理查询。 一旦所有守护程序完成其任务,查询协调器将收集结果并将其传递给用户。
impala Shell
在前面的章节中,我们已经看到了使用cloudera及其体系结构安装Impala。
- Impala shell(命令提示符)
- Hue (用户界面)
- ODBC和JDBC(第三方库)
本章介绍如何启动Impala Shell和shell的各种选项。
Impala Shell命令参考
Impala shell的命令分为一般命令,查询特定选项以及表和数据库特定选项,如下所述。
通用命令
- help
- version
- history
- shell (or) !
- connect
- exit | quit
查询特定的选项
- Set/unset
- Profile
- Explain
表和数据库特定选项
- Alter
- describe
- drop
- insert
- select
- show
- use
启动Impala Shell
打开cloudera终端,以超级用户身份登录,然后键入cloudera作为密码,如下所示。
[cloudera@quickstart ~]$ su
Password: cloudera
[root@quickstart cloudera]#
通过键入以下命令启动Impala shell -
[root@quickstart cloudera] # impala-shell
Starting Impala Shell without Kerberos authentication
Connected to quickstart.cloudera:21000
Server version: impalad version 2.3.0-cdh5.5.0 RELEASE
(build 0c891d79aa38f297d244855a32f1e17280e2129b)
*********************************************************************
Welcome to the Impala shell. Copyright (c) 2015 Cloudera, Inc. All rights reserved.
(Impala Shell v2.3.0-cdh5.5.0 (0c891d7) built on Mon Nov 9 12:18:12 PST 2015)
Want to know what version of Impala you're connected to? Run the VERSION command to
find out!
*********************************************************************
[quickstart.cloudera:21000] >
Impala - 通用命令
Impala的通用命令解释如下 -
help命令
Impala shell的help命令提供了Impala中可用的命令的列表 -
[quickstart.cloudera:21000] > help;
Documented commands (type help <topic>):
========================================================
compute describe insert set unset with version
connect explain quit show values use
exit history profile select shell tip
Undocumented commands:
=========================================
alter create desc drop help load summary
version命令
version命令为您提供Impala的当前版本,如下所示。
[quickstart.cloudera:21000] > version;
Shell version: Impala Shell v2.3.0-cdh5.5.0 (0c891d7) built on Mon Nov 9
12:18:12 PST 2015
Server version: impalad version 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
history命令
Impala的history命令显示在shell中执行的最后10个命令。 以下是历史命令的示例。 这里我们执行了5个命令,即版本,帮助,显示,使用和历史。
[quickstart.cloudera:21000] > history;
[1]:version;
[2]:help;
[3]:show databases;
[4]:use my_db;
[5]:history;
quit/exit命令
您可以使用quit或exit命令从Impala shell中弹出,如下所示。
[quickstart.cloudera:21000] > exit;
Goodbye cloudera
connect命令
connect命令用于连接到Impala的给定实例。 如果没有指定任何实例,则它将连接到默认端口21000,如下所示。
[quickstart.cloudera:21000] > connect;
Connected to quickstart.cloudera:21000
Server version: impalad version 2.3.0-cdh5.5.0 RELEASE (build
0c891d79aa38f297d244855a32f1e17280e2129b)
Impala查询特定选项
Impala的特定于查询的命令接受查询。 它们在下面解释 -
说明
explain命令返回给定查询的执行计划。
[quickstart.cloudera:21000] > explain select * from sample;
Query: explain select * from sample
+------------------------------------------------------------------------------------+
| Explain String |
+------------------------------------------------------------------------------------+
| Estimated Per-Host Requirements: Memory = 48.00MB VCores = 1 |
| WARNING: The following tables are missing relevant table and/or column statistics. |
| my_db.customers |
| 01:EXCHANGE [UNPARTITIONED] |
| 00:SCAN HDFS [my_db.customers] |
| partitions = 1/1 files = 6 size = 148B |
+------------------------------------------------------------------------------------+
Fetched 7 row(s) in 0.17s
简介
profile命令显示有关最近查询的低级信息。 此命令用于查询的诊断和性能调整。 以下是配置文件命令的示例。 在这种情况下,profile命令返回说明查询的低级信息。
[quickstart.cloudera:21000] > profile;
Query Runtime Profile:
Query (id=164b1294a1049189:a67598a6699e3ab6):
Summary:
Session ID: e74927207cd752b5:65ca61e630ad3ad
Session Type: BEESWAX
Start Time: 2016-04-17 23:49:26.08148000 End Time: 2016-04-17 23:49:26.2404000
Query Type: EXPLAIN
Query State: FINISHED
Query Status: OK
Impala Version: impalad version 2.3.0-cdh5.5.0 RELEASE (build 0c891d77280e2129b)
User: cloudera
Connected User: cloudera
Delegated User:
Network Address:10.0.2.15:43870
Default Db: my_db
Sql Statement: explain select * from sample
Coordinator: quickstart.cloudera:22000
: 0ns
Query Timeline: 167.304ms
- Start execution: 41.292us (41.292us) - Planning finished: 56.42ms (56.386ms)
- Rows available: 58.247ms (1.819ms)
- First row fetched: 160.72ms (101.824ms)
- Unregister query: 166.325ms (6.253ms)
ImpalaServer:
- ClientFetchWaitTimer: 107.969ms
- RowMaterializationTimer: 0ns
表和数据库特定选项
下表列出了Impala中的表和数据特定选项。
Sr.No | 指挥解释 |
1 | Alter alter命令用于更改Impala中表的结构和名称。 |
2 | Describe Impala的describe命令提供表的元数据。 它包含列和其数据类型等信息。 describe命令具有desc作为快捷方式。 |
3 | Drop drop命令用于从Impala中删除构造,其中构造可以是表,视图或数据库函数。 |
4 | insert Impala的insert命令用于
|
5 | select select语句用于对特定数据集执行所需的操作。 它指定要在其上完成某些操作的数据集。 您可以打印或存储(在文件中)select语句的结果。 |
6 | show Impala的show语句用于显示各种构造(如表,数据库和表)的中继。 |
7 | use Impala的use语句用于将当前上下文更改为所需的数据库。 |
impala 查询语言基础
Impala数据类型
下表描述了Impala数据类型。
Sr.No | 数据类型及说明 |
1 | BIGINT 此数据类型存储数值,此数据类型的范围为-9223372036854775808至9223372036854775807.此数据类型在create table和alter table语句中使用。 |
2 | BOOLEAN 此数据类型只存储true或false值,它用于create table语句的列定义。 |
3 | CHAR 此数据类型是固定长度的存储,它用空格填充,可以存储最大长度为255。 |
4 | DECIMAL 此数据类型用于存储十进制值,并在create table和alter table语句中使用。 |
5 | DOUBLE 此数据类型用于存储正值或负值4.94065645841246544e-324d -1.79769313486231570e + 308范围内的浮点值。 |
6 | FLOAT 此数据类型用于存储正或负1.40129846432481707e-45 .. 3.40282346638528860e + 38范围内的单精度浮点值数据类型。 |
7 | INT 此数据类型用于存储4字节整数,范围从-2147483648到2147483647。 |
8 | SMALLINT 此数据类型用于存储2字节整数,范围为-32768到32767。 |
9 | STRING 这用于存储字符串值。 |
10 | TIMESTAMP 此数据类型用于表示时间中的点。 |
11 | TINYINT 此数据类型用于存储1字节整数值,范围为-128到127。 |
12 | VARCHAR 此数据类型用于存储可变长度字符,最大长度为65,535。 |
13 | ARRAY 这是一个复杂的数据类型,它用于存储可变数量的有序元素。 |
14 | Map 这是一个复杂的数据类型,它用于存储可变数量的键值对。 |
15 | Struct 这是一种复杂的数据类型,用于表示单个项目的多个字段。 |
Impala 评论
Impala中的注释与SQL中的注释类似。一般来说,我们在编程语言中有两种类型的注释,即单行注释和多行注释。
单行注释 - 后面跟有“ - ”的每一行都被视为Impala中的注释。 以下是Impala中单行注释的示例。
-- Hello welcome to tutorials point.
多行注释 - / *和* /之间的所有行在Impala中被视为多行注释。 以下是Impala中多行注释的示例。
/*
Hi this is an example
Of multiline comments in Impala
*/
Impala中的运算符与SQL中的运算符类似。 请参阅我们的SQL教程,通过单击以下链接sql-operators。
数据库特定语句
impala 创建数据库
在Impala中,数据库是一种在其命名空间中保存相关表,视图和函数的构造。 它在HDFS中表示为目录树; 它包含表分区和数据文件。 本章介绍如何在Impala中创建数据库。
CREATE DATABASE语句
CREATE DATABASE语句用于在Impala中创建新数据库。
语法
以下是CREATE DATABASE语句的语法。
CREATE DATABASE IF NOT EXISTS database_name;
这里,IF NOT EXISTS是一个可选的子句。 如果我们使用此子句,则只有在没有具有相同名称的现有数据库时,才会创建具有给定名称的数据库。
例
以下是create database语句的示例。 在本例中,我们创建了一个名为my_database的数据库。
[quickstart.cloudera:21000] > CREATE DATABASE IF NOT EXISTS my_database;
在cloudera impala-shell中执行上述查询时,您将获得以下输出。
Query: create DATABASE my_database
Fetched 0 row(s) in 0.21s
验证
SHOW DATABASES查询给出Impala中的数据库列表,因此可以使用SHOW DATABASES语句验证是否创建了数据库。 在这里,您可以在列表中观察新创建的数据库my_db。
[quickstart.cloudera:21000] > show databases;
Query: show databases
+-----------------------------------------------+
| name |
+-----------------------------------------------+
| _impala_builtins |
| default |
| my_db |
+-----------------------------------------------+
Fetched 3 row(s) in 0.20s
[quickstart.cloudera:21000] >
Hdfs路径
为了在HDFS文件系统中创建数据库,需要指定要创建数据库的位置。
CREATE DATABASE IF NOT EXISTS
database_name
LOCATION
hdfs_path;
使用Hue浏览器创建数据库
打开Impala查询编辑器并在其中键入CREATE DATABASE语句。 此后,单击执行按钮,如下面的屏幕截图所示。
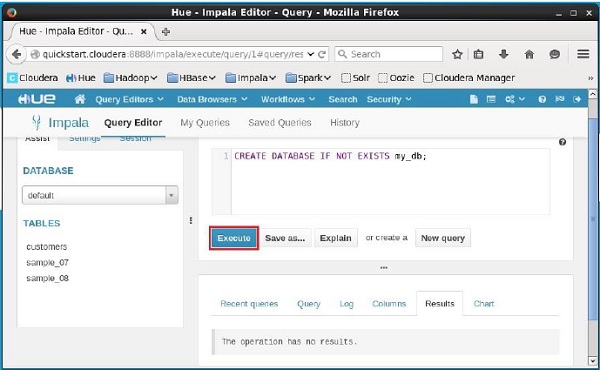
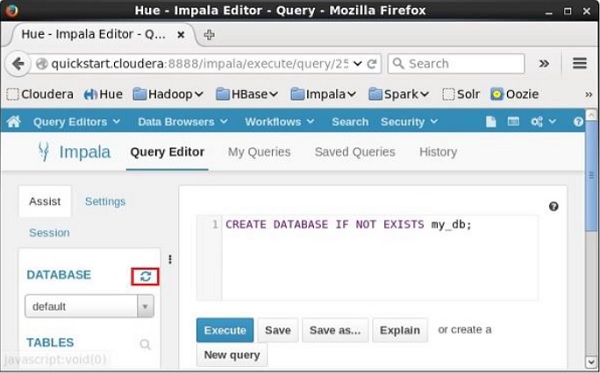
执行查询后,轻轻地将光标移动到下拉菜单的顶部,您会发现一个刷新符号。 如果单击刷新符号,将刷新数据库列表,并对其应用最近的更改。
验证
单击编辑器左侧标题DATABASE下的下拉框。 在那里您可以看到系统中的数据库列表。 这里可以观察新创建的数据库my_db,如下所示。
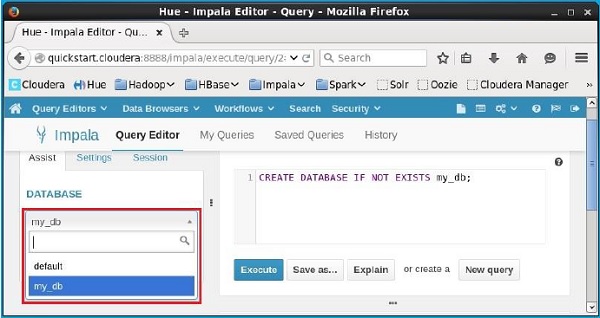
如果仔细观察,您只能看到一个数据库,即列表中的my_db以及默认数据库。
impala 删除数据库
Impala的DROP DATABASE语句用于从Impala中删除数据库。 在删除数据库之前,建议从中删除所有表。
语法
以下是DROP DATABASE语句的语法。
DROP (DATABASE|SCHEMA) [IF EXISTS] database_name [RESTRICT |
CASCADE] [LOCATION hdfs_path];
这里,IF EXISTS是一个可选子句。 如果我们在存在具有给定名称的数据库时使用此子句,则它将被删除。 如果没有具有给定名称的现有数据库,则不执行任何操作。
例
以下是DROP DATABASE语句的示例。 假设您在Impala中有一个名称为sample_database的数据库。
并且,如果使用SHOW DATABASES语句验证数据库列表,您将观察其中的名称。
[quickstart.cloudera:21000] > SHOW DATABASES;
Query: show DATABASES
+-----------------------+
| name |
+-----------------------+
| _impala_builtins |
| default |
| my_db |
| sample_database |
+-----------------------+
Fetched 4 row(s) in 0.11s
现在,您可以使用DROP DATABASE语句删除此数据库,如下所示。
< DROP DATABASE IF EXISTS sample_database;
这将删除指定的数据库,并给您以下输出。
Query: drop DATABASE IF EXISTS sample_database;
验证
您可以使用SHOW DATABASES语句验证给定数据库是否已删除。 在这里,您可以观察到名为sample_database的数据库从数据库列表中删除。
[quickstart.cloudera:21000] > SHOW DATABASES;
Query: show DATABASES
+----------------------+
| name |
+----------------------+
| _impala_builtins |
| default |
| my_db |
+----------------------+
Fetched 3 row(s) in 0.10s
[quickstart.cloudera:21000] >
级联
一般来说,要删除数据库,您需要手动删除其中的所有表。 如果使用级联,Impala会在删除指定数据库中的表之前删除它。
例
假设在Impala中有一个数据库命名为sample,它包含两个表,即student和test。 如果您尝试直接删除此数据库,您将收到一个错误,如下所示。
[quickstart.cloudera:21000] > DROP database sample;
Query: drop database sample
ERROR:
ImpalaRuntimeException: Error making 'dropDatabase' RPC to Hive Metastore:
CAUSED BY: InvalidOperationException: Database sample is not empty. One or more
tables exist.
使用级联,您可以直接删除此数据库(无需手动删除其内容),如下所示。
[quickstart.cloudera:21000] > DROP database sample cascade;
Query: drop database sample cascade
注意 - 您不能删除Impala中的“当前数据库”。 因此,在删除数据库之前,需要确保将当前上下文设置为除要删除的数据库之外的数据库。
使用Hue浏览器删除数据库
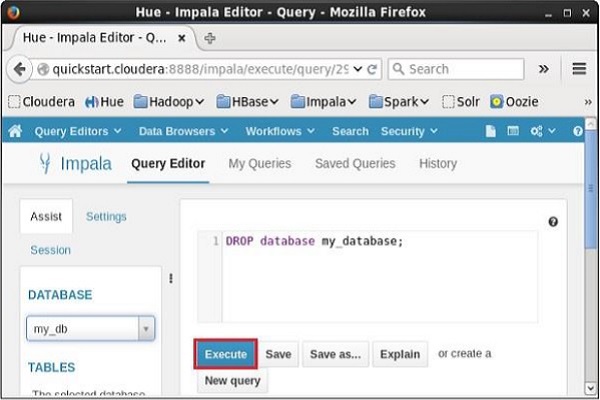
打开Impala查询编辑器并在其中键入DELETE DATABASE语句,然后单击执行按钮,如下所示。 假设有三个数据库,即my_db,my_database和sample_database以及默认数据库。 这里我们删除名为my_database的数据库。
执行查询后,轻轻将光标移动到下拉菜单的顶部。 然后,您将找到一个刷新符号,如下面的屏幕截图所示。 如果单击刷新符号,将刷新数据库列表,并将对其应用最近所做的更改。
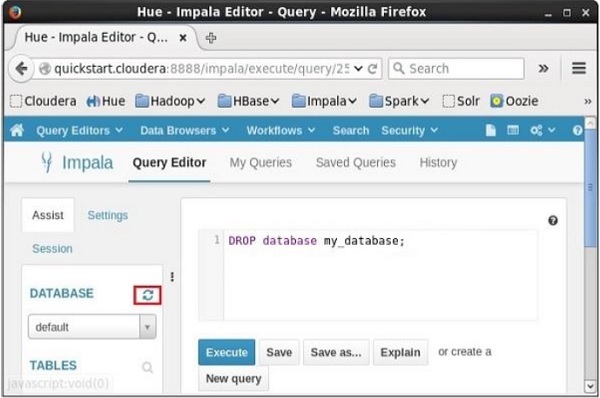
验证
单击编辑器左侧标题DATABASE下的下拉菜单。 在那里,您可以看到系统中的数据库列表。 这里可以观察新创建的数据库my_db,如下所示。
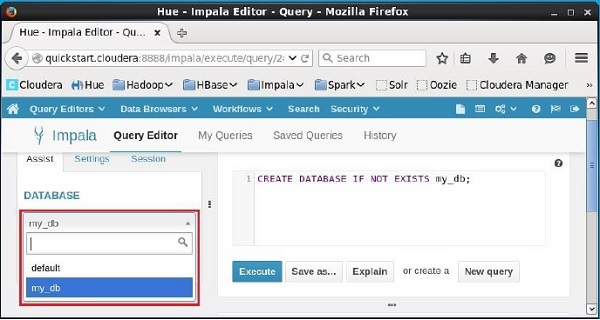
如果仔细观察,您只能看到一个数据库,即列表中的my_db以及默认数据库。
impala 选择数据库
连接到Impala后,需要从可用的数据库中选择一个。 Impala的USE DATABASE语句用于将当前会话切换到另一个数据库。
语法
以下是USE语句的语法。
USE db_name;
例
以下是USE语句的示例。 首先,让我们创建一个名为sample_database的数据库,如下所示。
> CREATE DATABASE IF NOT EXISTS sample_database;
这将创建一个新的数据库,并给您以下输出。
Query: create DATABASE IF NOT EXISTS my_db2
Fetched 0 row(s) in 2.73s
如果使用SHOW DATABASES语句验证数据库列表,则可以观察其中新创建的数据库的名称。
> SHOW DATABASES;
Query: show DATABASES
+-----------------------+
| name |
+-----------------------+
| _impala_builtins |
| default |
| my_db |
| sample_database |
+-----------------------+
Fetched 4 row(s) in 0.11s
现在,让我们使用USE语句将会话切换到新创建的数据库(sample_database),如下所示。
> USE sample_database;
这将更改当前上下文为sample_database并显示如下所示的消息。
Query: use sample_database
使用Hue浏览器选择数据库
在Impala的查询编辑器的左侧,您会看到一个下拉菜单,如下面的屏幕截图所示。
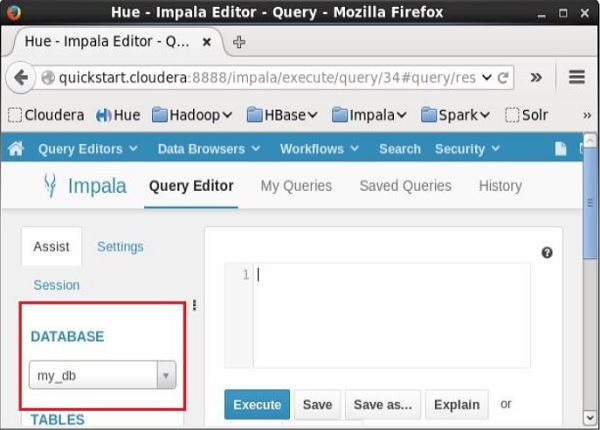
如果单击下拉菜单,您将在Impala中找到所有数据库的列表,如下所示。
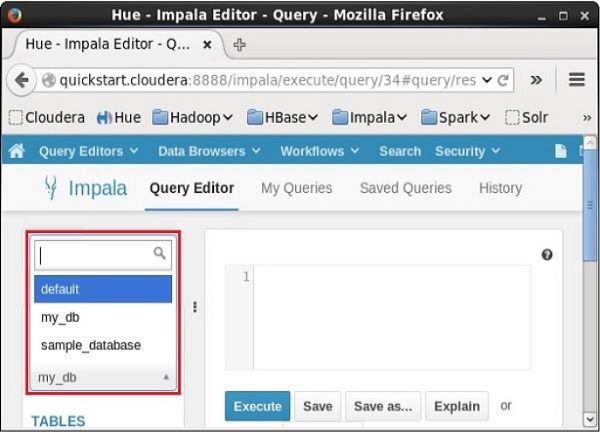
只需选择需要更改当前上下文的数据库。
Table 特定语句
impala CREATE TABLE语句
CREATE TABLE语句用于在Impala中的所需数据库中创建新表。 创建基本表涉及命名表并定义其列和每列的数据类型。
语法
以下是CREATE TABLE语句的语法。 这里,IF NOT EXISTS是一个可选的子句。 如果使用此子句,则只有在指定数据库中没有具有相同名称的现有表时,才会创建具有给定名称的表。
create table IF NOT EXISTS database_name.table_name (
column1 data_type,
column2 data_type,
column3 data_type,
………
columnN data_type
);
CREATE TABLE是指示数据库系统创建新表的关键字。 表的唯一名称或标识符位于CREATE TABLE语句之后。 (可选)您可以指定database_name和table_name。
例
以下是create table语句的示例。 在这个例子中,我们在数据库my_db中创建了一个名为student的表。
[quickstart.cloudera:21000] > CREATE TABLE IF NOT EXISTS my_db.student
(name STRING, age INT, contact INT );
执行上述语句时,将创建具有指定名称的表,并显示以下输出。
Query: create table student (name STRING, age INT, phone INT)
Fetched 0 row(s) in 0.48s
验证
show Tables查询提供Impala中当前数据库中的表的列表。 因此,可以使用Show Tables语句验证是否创建了表。
首先,您需要将上下文切换到所需表所在的数据库,如下所示。
[quickstart.cloudera:21000] > use my_db;
Query: use my_db
然后,如果您使用show tables查询获取表的列表,则可以在其中观察名为student的表,如下所示。
[quickstart.cloudera:21000] >
show tables;
Query: show tables
+-----------+
| name |
+-----------+
| student |
+-----------+
Fetched 1 row(s) in 0.10s
HDFS路径
为了在HDFS文件系统中创建数据库,需要指定要创建数据库的位置,如下所示。
CREATE DATABASE IF NOT EXISTS database_name LOCATION hdfs_path;
使用Hue浏览器创建数据库
打开impala查询编辑器,并在其中键入CREATE Table Statement。 然后单击执行按钮,如下面的屏幕截图所示。
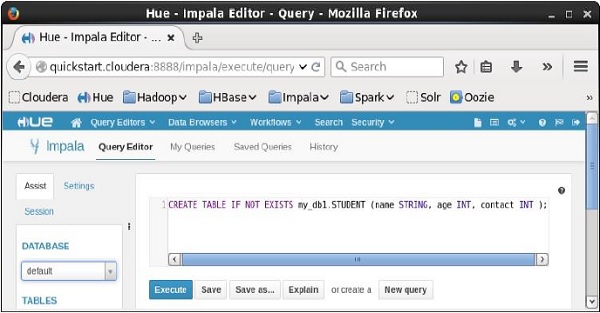
执行查询后,轻轻将光标移动到下拉菜单的顶部,您会发现一个刷新符号。 如果单击刷新符号,将刷新数据库列表,并对其应用最近所做的更改。
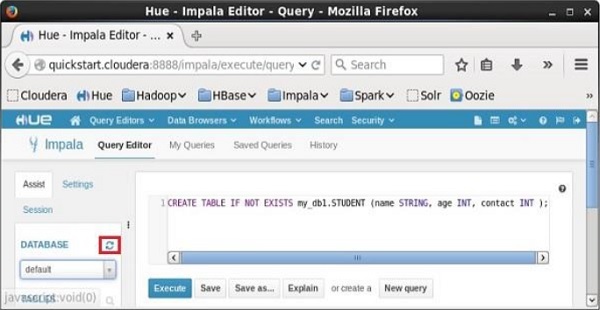
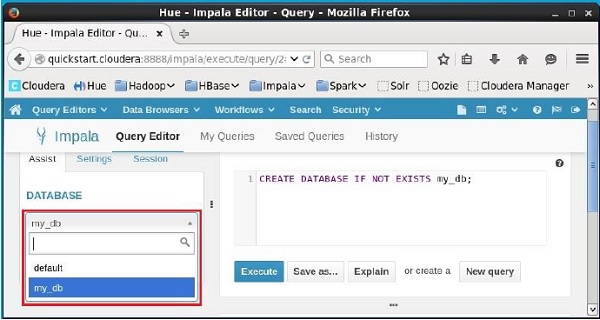
验证
单击编辑器左侧标题DATABASE下的下拉菜单。 在那里你可以看到一个数据库列表。 选择数据库my_db,如下所示。
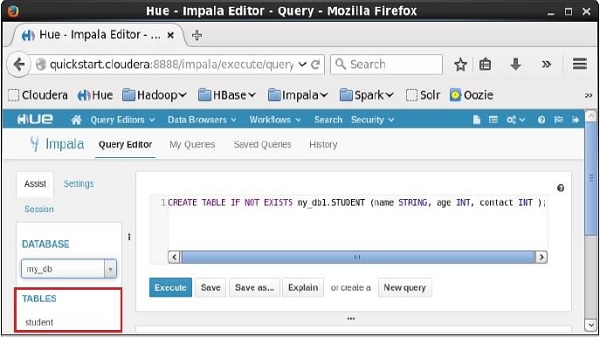
在选择数据库my_db时,您可以看到其中的表列表,如下所示。 在这里你可以找到新创建的表学生,如下所示。
impala Insert语句
Impala的INSERT语句有两个子句 - into和overwrite。 Insert语句with into子句用于将新记录添加到数据库中的现有表中。
语法
INSERT语句有两种基本语法,如下所示:
insert into table_name (column1, column2, column3,...columnN)
values (value1, value2, value3,...valueN);
这里,column1,column2,... columnN是要插入数据的表中的列的名称。
您还可以添加值而不指定列名,但是,您需要确保值的顺序与表中的列的顺序相同,如下所示。
Insert into table_name values (value1, value2, value2);
CREATE TABLE是关键字,告诉数据库系统创建一个新表。 表的唯一名称或标识符位于CREATE TABLE语句之后。 (可选)您可以指定database_name和table_name。
例
假设我们在Impala中创建了一个名为student的表,如下所示。
create table employee (Id INT, name STRING, age INT,address STRING, salary BIGINT);
以下是在名为employee的表中创建记录的示例。
[quickstart.cloudera:21000] > insert into employee
(ID,NAME,AGE,ADDRESS,SALARY)VALUES (1, 'Ramesh', 32, 'Ahmedabad', 20000 );
在执行上述语句时,会将记录插入到名为employee的表中,并显示以下消息。
Query: insert into employee (ID,NAME,AGE,ADDRESS,SALARY) VALUES (1, 'Ramesh',
32, 'Ahmedabad', 20000 )
Inserted 1 row(s) in 1.32s
您可以插入另一个记录,而不指定列名称,如下所示。
[quickstart.cloudera:21000] > insert into employee values (2, 'Khilan', 25,
'Delhi', 15000 );
在执行上述语句时,会将记录插入到名为employee的表中,并显示以下消息。
Query: insert into employee values (2, 'Khilan', 25, 'Delhi', 15000 )
Inserted 1 row(s) in 0.31s
您可以在employee表中插入更多记录,如下所示。
Insert into employee values (3, 'kaushik', 23, 'Kota', 30000 );
Insert into employee values (4, 'Chaitali', 25, 'Mumbai', 35000 );
Insert into employee values (5, 'Hardik', 27, 'Bhopal', 40000 );
Insert into employee values (6, 'Komal', 22, 'MP', 32000 );
插入值后,Impala中的employee表将如下所示。
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 6 | Komal | 22 | MP | 32000 |
+----+----------+-----+-----------+--------+
覆盖表中的数据
我们可以使用覆盖子句覆盖表的记录。 覆盖的记录将从表中永久删除。 以下是使用overwrite子句的语法。
Insert overwrite table_name values (value1, value2, value2);
例
以下是使用子句覆盖的示例。
[quickstart.cloudera:21000] > Insert overwrite employee values (1, 'Ram', 26,
'Vishakhapatnam', 37000 );
在执行上面的查询时,这将覆盖表数据,指定的记录显示以下消息。
Query: insert overwrite employee values (1, 'Ram', 26, 'Vishakhapatnam', 37000 )
Inserted 1 row(s) in 0.31s
在验证表时,您可以观察到表employee的所有记录都被新记录覆盖,如下所示。
+----+------+-----+---------------+--------+
| id | name | age | address | salary |
+----+------+-----+---------------+--------+
| 1 | Ram | 26 | Vishakhapatnam| 37000 |
+----+------+-----+---------------+--------+
使用Hue浏览器插入数据
打开Impala查询编辑器并键入其中的insert语句。 然后单击执行按钮,如下面的屏幕截图所示。
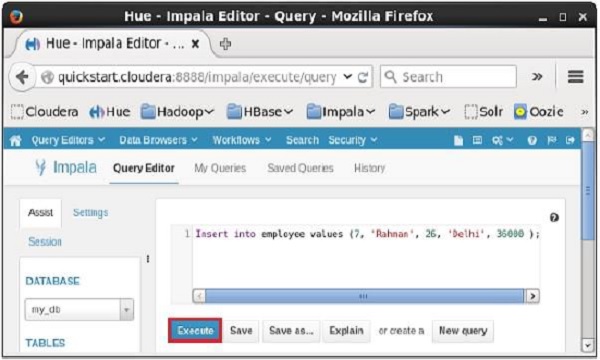
执行查询/语句后,此记录将添加到表中。
impala Select语句
Impala SELECT语句用于从数据库中的一个或多个表中提取数据。 此查询以表的形式返回数据。
语句
以下是Impala select语句的语法。
SELECT column1, column2, columnN from table_name;
这里,column1,column2 ...是您要获取其值的表的字段。 如果要获取字段中的所有可用字段,则可以使用以下语法 -
SELECT * FROM table_name;
例
假设我们在Impala中有一个名为customers的表,其中包含以下数据 -
ID NAME AGE ADDRESS SALARY
--- ------- --- ---------- -------
1 Ramesh 32 Ahmedabad 20000
2 Khilan 25 Delhi 15000
3 Hardik 27 Bhopal 40000
4 Chaitali 25 Mumbai 35000
5 kaushik 23 Kota 30000
6 Komal 22 Mp 32000
您可以使用select语句获取customers表的所有记录的id,name和age,如下所示 -
[quickstart.cloudera:21000] > select id, name, age from customers;
在执行上述查询时,Impala从指定表中获取所有记录的id,name,age,并显示它们,如下所示。
Query: select id,name,age from customers
+----+----------+-----+
| id | name | age |
| 1 | Ramesh | 32 |
| 2 | Khilan | 25 |
| 3 | Hardik | 27 |
| 4 | Chaitali | 25 |
| 5 | kaushik | 23 |
| 6 | Komal | 22 |
+----+----------+-----+
Fetched 6 row(s) in 0.66s
您还可以使用select查询从customers表中获取所有记录,如下所示。
[quickstart.cloudera:21000] > select name, age from customers;
Query: select * from customers
在执行上述查询时,Impala从指定的表中提取和显示所有记录,如下所示。
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | Hardik | 27 | Bhopal | 40000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | kaushik | 23 | Kota | 30000 |
| 6 | Komal | 22 | MP | 32000 |
+----+----------+-----+-----------+--------+
Fetched 6 row(s) in 0.66s
使用Hue获取记录
打开Impala查询编辑器并键入其中的select语句。 然后单击执行按钮,如下面的屏幕截图所示。
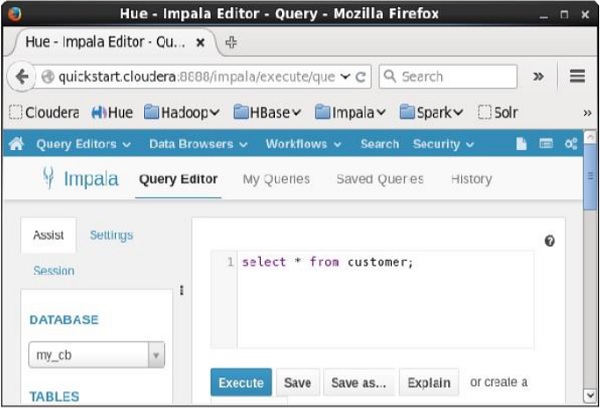
执行查询后,如果向下滚动并选择“结果”选项卡,则可以看到指定表的记录列表,如下所示。
impala Describe语句
Impala中的describe语句用于提供表的描述。 此语句的结果包含有关表的信息,例如列名称及其数据类型。
语法
以下是Impala describe语句的语法。
Describe table_name;
例
例如,假设我们在Impala中有一个名为customer的表,其中包含以下数据 -
ID NAME AGE ADDRESS SALARY
--- --------- ----- ----------- -----------
1 Ramesh 32 Ahmedabad 20000
2 Khilan 25 Delhi 15000
3 Hardik 27 Bhopal 40000
4 Chaitali 25 Mumbai 35000
5 kaushik 23 Kota 30000
6 Komal 22 Mp 32000
您可以使用如下所示的describe语句获取客户表的描述 -
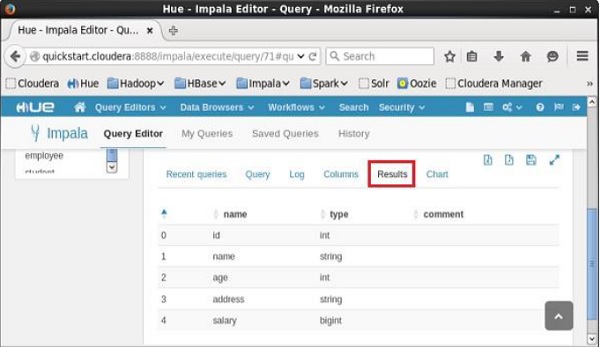
[quickstart.cloudera:21000] > describe customer;
在执行上面的查询时,Impala获取指定表的元数据并显示它,如下所示。
Query: describe customer
+---------+--------+---------+
| name | type | comment |
+---------+--------+---------+
| id | int | |
| name | string | |
| age | int | |
| address | string | |
| salary | bigint | |
+---------+--------+---------+
Fetched 5 row(s) in 0.51s
使用Hue描述记录
打开Impala查询编辑器并键入其中的describe语句,然后单击执行按钮,如下面的屏幕截图所示。
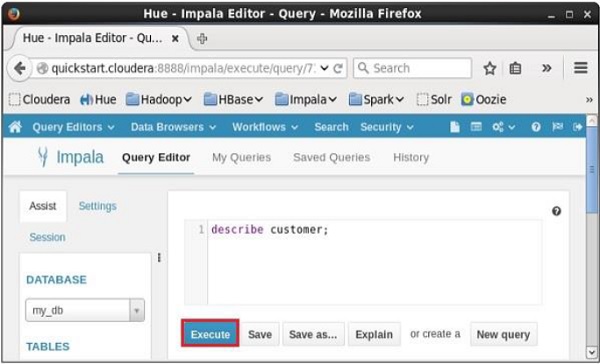
执行查询后,如果向下滚动并选择“结果”选项卡,您可以看到表的元数据,如下所示。
impala ALTER TABLE
Impala中的Alter table语句用于对给定表执行更改。 使用此语句,我们可以添加,删除或修改现有表中的列,也可以重命名它们。
本章通过语法和示例解释了各种类型的alter语句。 首先假设我们在Impala的my_db数据库中有一个名为customers的表,具有以下数据
ID NAME AGE ADDRESS SALARY
--- --------- ----- ----------- --------
1 Ramesh 32 Ahmedabad 20000
2 Khilan 25 Delhi 15000
3 Hardik 27 Bhopal 40000
4 Chaitali 25 Mumbai 35000
5 kaushik 23 Kota 30000
6 Komal 22 Mp 32000
并且,如果获取数据库my_db中的表列表,可以在其中找到customers表,如下所示。
[quickstart.cloudera:21000] > show tables;
Query: show tables
+-----------+
| name |
+-----------+
| customers |
| employee |
| student |
| student1 |
+-----------+
更改表的名称
语法
ALTER TABLE重命名现有表的基本语法如下 -
ALTER TABLE [old_db_name.]old_table_name RENAME TO [new_db_name.]new_table_name
例
下面是使用alter语句更改表名称的示例。 这里我们将表客户的名称更改为用户。
[quickstart.cloudera:21000] > ALTER TABLE my_db.customers RENAME TO my_db.users;
执行上述查询后,Impala根据需要更改表的名称,并显示以下消息。
Query: alter TABLE my_db.customers RENAME TO my_db.users
您可以使用show tables语句验证当前数据库中的表的列表。 您可以找到名为users而不是customers的表。
Query: show tables
+----------+
| name |
+----------+
| employee |
| student |
| student1 |
| users |
+----------+
Fetched 4 row(s) in 0.10s
向表中添加列
语法
ALTER TABLE向现有表中添加列的基本语法如下 -
ALTER TABLE name ADD COLUMNS (col_spec[, col_spec ...])
例
以下查询是演示如何向现有表中添加列的示例。 这里我们在users表中添加两列account_no和phone_number(两者都是bigint数据类型)。
[quickstart.cloudera:21000] > ALTER TABLE users ADD COLUMNS (account_no BIGINT,
phone_no BIGINT);
在执行上面的查询时,它会将指定的列添加到名为student的表中,并显示以下消息。
Query: alter TABLE users ADD COLUMNS (account_no BIGINT, phone_no BIGINT)
如果您验证表用户的模式,您可以在其中找到新添加的列,如下所示。
quickstart.cloudera:21000] > describe
users;
Query: describe users
+------------+--------+---------+
| name | type | comment |
+------------+--------+---------+
| id | int | |
| name | string | |
| age | int | |
| address | string | |
| salary | bigint | |
| account_no | bigint | |
| phone_no | bigint | |
+------------+--------+---------+
Fetched 7 row(s) in 0.20s
从表中删除列
语法
现有表中ALTER TABLE到DROP COLUMN的基本语法如下 -
ALTER TABLE name DROP [COLUMN] column_name
例
以下查询是从现有表中删除列的示例。 这里我们删除名为account_no的列。
[quickstart.cloudera:21000] > ALTER TABLE users DROP account_no;
在执行上面的查询时,Impala删除名为account的列,不显示以下消息。
Query: alter TABLE users DROP account_no
如果验证表用户的模式,则在删除之后,将找不到名为account_no的列。
[quickstart.cloudera:21000] > describe users;
Query: describe users
+----------+--------+---------+
| name | type | comment |
+----------+--------+---------+
| id | int | |
| name | string | |
| age | int | |
| address | string | |
| salary | bigint | |
| phone_no | bigint | |
+----------+--------+---------+
Fetched 6 row(s) in 0.11s
更改列的名称和类型
语法
ALTER TABLE更改现有表中的列的名称和数据类型的基本语法如下 -
ALTER TABLE name CHANGE column_name new_name new_type
例
以下是使用alter语句更改列的名称和数据类型的示例。 这里我们将列phone_no的名称更改为电子邮件,将其数据类型更改为字符串。
[quickstart.cloudera:21000] > ALTER TABLE users CHANGE phone_no e_mail string;
在执行上述查询时,Impala执行指定的更改,显示以下消息。
Query: alter TABLE users CHANGE phone_no e_mail string
您可以使用describe语句验证表用户的元数据。 您可以观察到Impala已对指定的列进行了必要的更改。
[quickstart.cloudera:21000] > describe users;
Query: describe users
+----------+--------+---------+
| name | type | comment |
+----------+--------+---------+
| id | int | |
| name | string | |
| age | int | |
| address | string | |
| salary | bigint | |
| phone_no | bigint | |
+----------+--------+---------+
Fetched 6 row(s) in 0.11s
使用Hue改变表
打开Impala查询编辑器并在其中键入alter语句,然后单击执行按钮,如下面的屏幕截图所示。
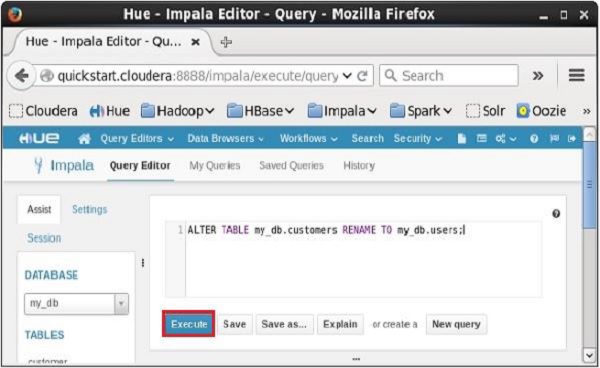
在执行上述查询时,它会将表customer的名称更改为用户。 以同样的方式,我们可以执行所有的alter查询。
impala 删除表
Impala drop table语句用于删除Impala中的现有表。 此语句还会删除内部表的底层HDFS文件
注意 - 使用此命令时必须小心,因为删除表后,表中可用的所有信息也将永远丢失。
语法
以下是DROP TABLE语句的语法。 这里,IF EXISTS是一个可选子句。 如果我们使用此子句,则会删除具有给定名称的表,只要它存在。 否则,不会执行任何操作。
DROP table database_name.table_name;
如果尝试删除不存在IF EXISTS子句的表,将会生成错误。 (可选)您可以指定database_name和table_name。
例
让我们首先验证数据库my_db中的表的列表,如下所示。
[quickstart.cloudera:21000] > show tables;
Query: show tables
+------------+
| name |
+------------+
| customers |
| employee |
| student |
+------------+
Fetched 3 row(s) in 0.11s
从上面的结果可以看出,数据库my_db包含3个表
下面是drop table语句的示例。 在本例中,我们从数据库my_db中删除名为student的表。
[quickstart.cloudera:21000] > drop table if exists my_db.student;
执行上述查询时,将删除具有指定名称的表,并显示以下输出。
Query: drop table if exists student
验证
show Tables查询提供Impala中当前数据库中的表的列表。 因此,可以使用Show Tables语句验证是否删除了表。
首先,您需要将上下文切换到所需表所在的数据库,如下所示。
[quickstart.cloudera:21000] > use my_db;
Query: use my_db
然后,如果使用show tables查询获取表的列表,可以观察名为student的表不在列表中。
[quickstart.cloudera:21000] > show tables;
Query: show tables
+-----------+
| name |
+-----------+
| customers |
| employee |
| student |
+-----------+
Fetched 3 row(s) in 0.11s
使用Hue浏览器创建数据库
打开Impala查询编辑器并在其中键入drop表语句。 然后单击执行按钮,如下面的屏幕截图所示。
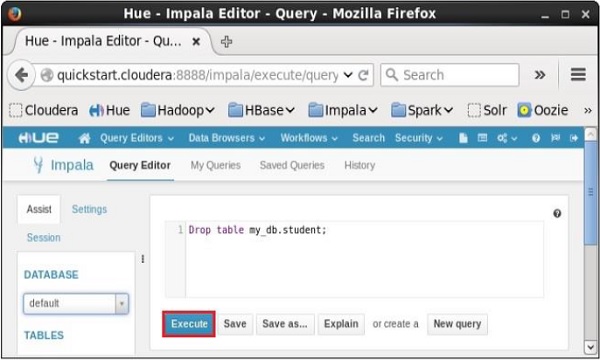
执行查询后,轻轻将光标移动到下拉菜单的顶部,您会发现一个刷新符号。 如果单击刷新符号,将刷新数据库列表,并对其应用最近所做的更改。
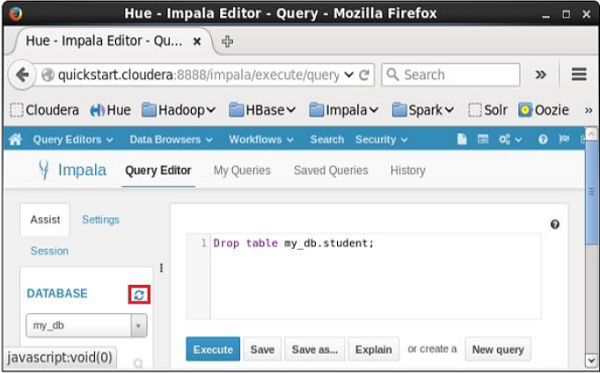
验证
单击编辑器左侧标题DATABASE下的下拉菜单。 在那里你可以看到一个数据库列表; 选择数据库my_db,如下所示。
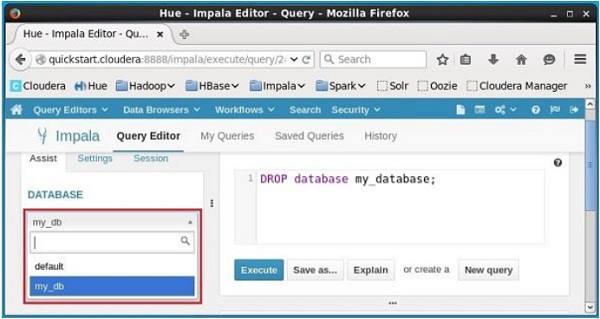
在选择数据库my_db时,可以看到其中的表列表,如下所示。 在这里,您不能在列表中找到已删除的表学生,如下所示。
impala 截断表
Impala的Truncate Table语句用于从现有表中删除所有记录。
您也可以使用DROP TABLE命令删除一个完整的表,但它会从数据库中删除完整的表结构,如果您希望存储一些数据,您将需要重新创建此表。
语法
以下是truncate table语句的语法。
truncate table_name;
例
假设,我们在Impala中有一个名为customers的表,如果您验证其内容,则会得到以下结果。 这意味着customers表包含6条记录。
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+--------+
| id | name | age | address | salary | e_mail |
+----+----------+-----+-----------+--------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 | NULL |
| 2 | Khilan | 25 | Delhi | 15000 | NULL |
| 3 | kaushik | 23 | Kota | 30000 | NULL |
| 4 | Chaitali | 25 | Mumbai | 35000 | NULL |
| 5 | Hardik | 27 | Bhopal | 40000 | NULL |
| 6 | Komal | 22 | MP | 32000 | NULL |
+----+----------+-----+-----------+--------+--------+
以下是使用truncate语句在Impala中截断表的示例。 这里我们删除名为customers的表的所有记录。
[quickstart.cloudera:21000] > truncate customers;
在执行上述语句时,Impala删除指定表的所有记录,并显示以下消息。
Query: truncate customers
Fetched 0 row(s) in 0.37s
验证
如果您验证customers表的内容,在删除操作后,使用select语句,您将获得一个空行,如下所示。
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
Fetched 0 row(s) in 0.12s
使用Hue浏览器截断表
打开Impala查询编辑器并在其中键入truncate语句。 然后单击执行按钮,如下面的屏幕截图所示。
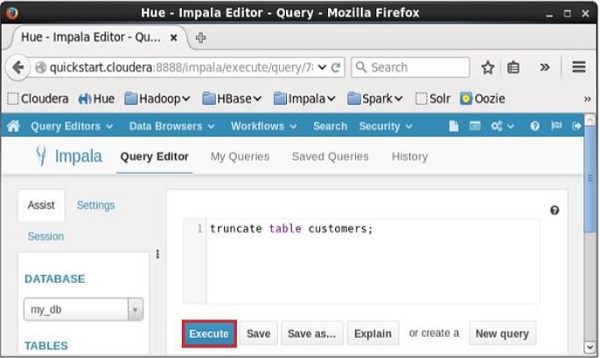
执行查询/语句后,将删除表中的所有记录。
impala 显示表
Impala中的show tables语句用于获取当前数据库中所有现有表的列表。
例
以下是show tables语句的示例。 如果要获取特定数据库中的表列表,首先,将上下文更改为所需的数据库,并使用show tables语句获取其中的表列表,如下所示。
[quickstart.cloudera:21000] > use my_db;
Query: use my_db
[quickstart.cloudera:21000] > show tables;
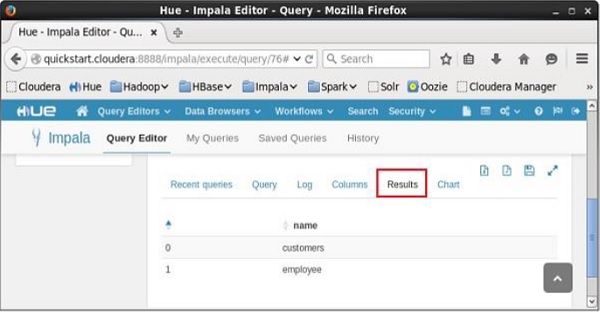
在执行上面的查询时,Impala获取指定数据库中的所有表的列表,并显示它如下所示。
Query: show tables
+-----------+
| name |
+-----------+
| customers |
| employee |
+-----------+
Fetched 2 row(s) in 0.10s
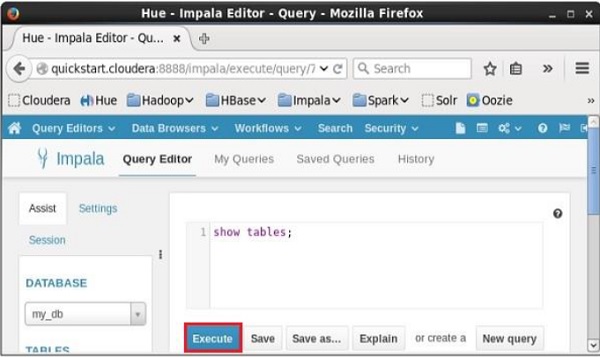
使用Hue列出表
打开impala查询编辑器,选择上下文为my_db并键入其中的show tables语句,然后单击执行按钮,如下面的屏幕截图所示。
执行查询后,如果向下滚动并选择“结果”选项卡,您可以看到如下所示的表列表。
impala 创建视图
视图仅仅是存储在数据库中具有关联名称的Impala查询语言的语句。 它是以预定义的SQL查询形式的表的组合。
视图可以包含表的所有行或选定的行。 可以从一个或多个表创建视图。 视图允许用户 -
- 以用户或用户类发现自然或直观的方式结构化数据。
- 限制对数据的访问,以便用户可以看到和(有时)完全修改他们需要的内容,而不再更改。
- 汇总可用于生成报告的各种表中的数据。
您可以使用Impala的Create View语句创建视图。
语法
以下是create view语句的语法。 IF NOT EXISTS是一个可选的子句。 如果使用此子句,则只有在指定数据库中没有具有相同名称的现有表时,才会创建具有给定名称的表。
Create View IF NOT EXISTS view_name as Select statement
例
例如,假设在Impala中的my_db数据库中有一个名为customers的表,其中包含以下数据。
ID NAME AGE ADDRESS SALARY
--- --------- ----- ----------- --------
1 Ramesh 32 Ahmedabad 20000
2 Khilan 25 Delhi 15000
3 Hardik 27 Bhopal 40000
4 Chaitali 25 Mumbai 35000
5 kaushik 23 Kota 30000
6 Komal 22 MP 32000
以下是Create View语句的示例。 在此示例中,我们创建一个视图为customers表,其中包含列,名称和年龄。
[quickstart.cloudera:21000] > CREATE VIEW IF NOT EXISTS customers_view AS
select name, age from customers;
执行上述查询时,将创建具有所需列的视图,并显示以下消息。
Query: create VIEW IF NOT EXISTS sample AS select * from customers
Fetched 0 row(s) in 0.33s
验证
您可以使用select语句验证刚创建的视图的内容,如下所示。
[quickstart.cloudera:21000] > select * from customers_view;
这将产生以下结果。
Query: select * from customers_view
+----------+-----+
| name | age |
+----------+-----+
| Komal | 22 |
| Khilan | 25 |
| Ramesh | 32 |
| Hardik | 27 |
| Chaitali | 25 |
| kaushik | 23 |
+----------+-----+
Fetched 6 row(s) in 4.80s
使用Hue创建视图
打开Impala查询编辑器,选择上下文为my_db,并键入其中的Create View语句,然后单击执行按钮,如下面的屏幕截图所示。
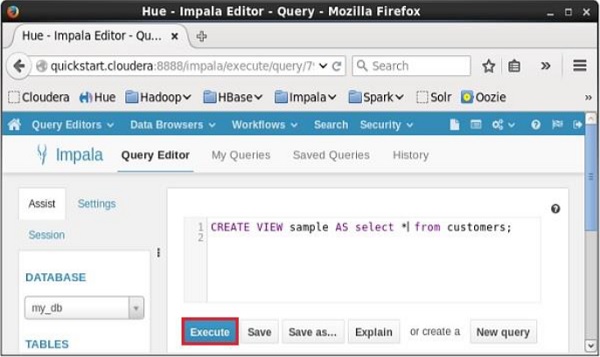
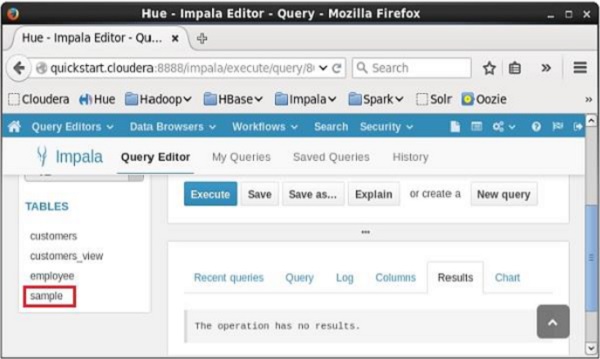
执行查询后,如果向下滚动,您可以看到在表列表中创建的名为sample的视图,如下所示。
impala ALTER VIEW
Impala的Alter View语句用于更改视图。 使用此语句,您可以更改视图的名称,更改数据库以及与其关联的查询。
由于视图是一个逻辑结构,因此没有物理数据会受到alter view查询的影响。
语法
以下是Alter View语句的语法
ALTER VIEW database_name.view_name为Select语句
例
例如,假设在Impala中的my_db数据库中有一个名为customers_view的视图,其中包含以下内容。
+----------+-----+
| name | age |
+----------+-----+
| Komal | 22 |
| Khilan | 25 |
| Ramesh | 32 |
| Hardik | 27 |
| Chaitali | 25 |
| kaushik | 23 |
+----------+-----+
以下是Alter View语句的示例。 在这个例子中,我们将列id,name和salary而不是name和age添加到customers_view。
[quickstart.cloudera:21000] > Alter view customers_view as select id, name,
salary from customers;
在执行上述查询时,Impala对customers_view进行指定的更改,并显示以下消息。
Query: alter view customers_view as select id, name, salary from customers
验证
您可以使用select语句验证名为customers_view的视图的内容,如下所示。
[quickstart.cloudera:21000] > select * from customers_view;
Query: select * from customers_view
这将产生以下结果。
+----+----------+--------+
| id | name | salary |
+----+----------+--------+
| 3 | kaushik | 30000 |
| 2 | Khilan | 15000 |
| 5 | Hardik | 40000 |
| 6 | Komal | 32000 |
| 1 | Ramesh | 20000 |
| 4 | Chaitali | 35000 |
+----+----------+--------+
Fetched 6 row(s) in 0.69s
使用Hue改变视图
打开Impala查询编辑器,选择上下文为my_db,并在其中键入Alter View语句,然后单击执行按钮,如下面的屏幕截图所示。
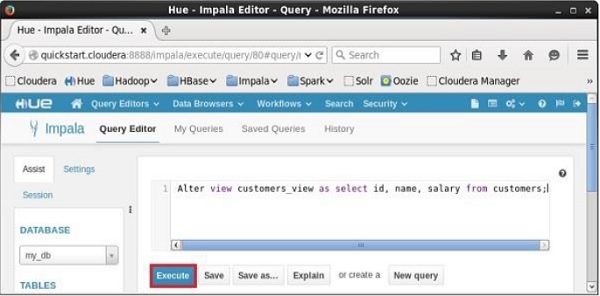
执行查询后,名为sample的视图将被相应地更改。
impala 删除视图
Impala的Drop View查询用于删除现有视图。 由于视图是一个逻辑结构,因此没有物理数据将受到视图查询的影响。
语法
下面是drop视图语句的语法。
DROP VIEW database_name.view_name;
例
例如,假设在Impala中的my_db数据库中有一个名为customers_view的视图,其中包含以下内容。
+----------+-----+
| name | age |
+----------+-----+
| Komal | 22 |
| Khilan | 25 |
| Ramesh | 32 |
| Hardik | 27 |
| Chaitali | 25 |
| kaushik | 23 |
+----------+-----+
以下是Drop View语句的示例。 在此示例中,我们尝试使用drop view查询删除名为customers_view的视图。
[quickstart.cloudera:21000] > Drop view customers_view;
在执行上述查询时,Impala会删除指定的视图,并显示以下消息。
Query: drop view customers_view
验证
如果使用show tables语句验证表的列表,可以观察到名为customers_view的视图被删除。
[quickstart.cloudera:21000] > show tables;
这将产生以下结果。
Query: show tables
+-----------+
| name |
+-----------+
| customers |
| employee |
| sample |
+-----------+
Fetched 3 row(s) in 0.10s
使用Hue删除视图
打开Impala查询编辑器,选择上下文为my_db,并在其中键入Drop视图语句,然后单击执行按钮,如下面的屏幕截图所示。
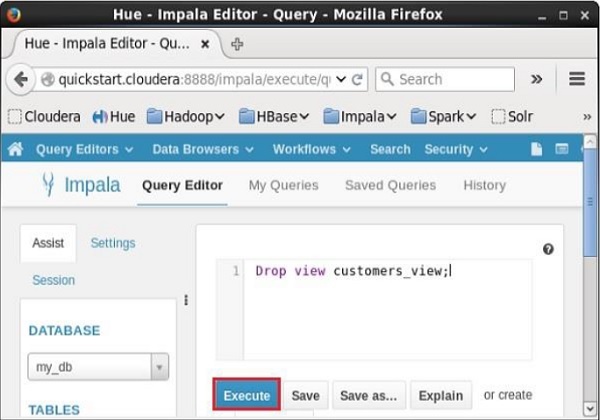
执行查询后,如果向下滚动,您可以看到名为TABLES的列表。 此列表包含当前数据库中的所有表和视图。 从此列表中,您可以发现指定的视图已删除。
impala 条款
impala ORDER BY子句
Impala ORDER BY子句用于根据一个或多个列以升序或降序对数据进行排序。 默认情况下,一些数据库按升序对查询结果进行排序。
语法
以下是ORDER BY子句的语法。
select * from table_name ORDER BY col_name [ASC|DESC] [NULLS FIRST|NULLS LAST]
可以使用关键字ASC或DESC分别按升序或降序排列表中的数据。
以同样的方式,如果我们使用NULLS FIRST,表中的所有空值都排列在顶行; 如果我们使用NULLS LAST,包含空值的行将最后排列。
例
假设我们在数据库my_db中有一个名为customers的表,其内容如下 -
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 3 | kaushik | 23 | Kota | 30000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 6 | Komal | 22 | MP | 32000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
+----+----------+-----+-----------+--------+
Fetched 6 row(s) in 0.51s
以下是使用order by子句按照其ID的升序排列customers表中的数据的示例。
[quickstart.cloudera:21000] > Select * from customers ORDER BY id asc;
在执行时,上述查询产生以下输出。
Query: select * from customers ORDER BY id asc
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 6 | Komal | 22 | MP | 32000 |
+----+----------+-----+-----------+--------+
Fetched 6 row(s) in 0.56s
同样,您可以使用order by子句按降序排列customers表的数据,如下所示。
[quickstart.cloudera:21000] > Select * from customers ORDER BY id desc;
在执行时,上述查询产生以下输出。
Query: select * from customers ORDER BY id desc
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 6 | Komal | 22 | MP | 32000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
+----+----------+-----+-----------+--------+
Fetched 6 row(s) in 0.54s
impala GROUP BY子句
Impala GROUP BY子句与SELECT语句协作使用,以将相同的数据排列到组中。
语法
以下是GROUP BY子句的语法。
select data from table_name Group BY col_name;
例
假设我们在数据库my_db中有一个名为customers的表,其内容如下 -
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 6 | Komal | 22 | MP | 32000 |
+----+----------+-----+-----------+--------+
Fetched 6 row(s) in 0.51s
您可以使用GROUP BY查询获得每个客户的工资总额,如下所示。
[quickstart.cloudera:21000] > Select name, sum(salary) from customers Group BY name;
执行时,上述查询给出以下输出。
Query: select name, sum(salary) from customers Group BY name
+----------+-------------+
| name | sum(salary) |
+----------+-------------+
| Ramesh | 20000 |
| Komal | 32000 |
| Hardik | 40000 |
| Khilan | 15000 |
| Chaitali | 35000 |
| kaushik | 30000 |
+----------+-------------+
Fetched 6 row(s) in 1.75s
假设此表有多个记录,如下所示。
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Ramesh | 32 | Ahmedabad | 1000| |
| 3 | Khilan | 25 | Delhi | 15000 |
| 4 | kaushik | 23 | Kota | 30000 |
| 5 | Chaitali | 25 | Mumbai | 35000 |
| 6 | Chaitali | 25 | Mumbai | 2000 |
| 7 | Hardik | 27 | Bhopal | 40000 |
| 8 | Komal | 22 | MP | 32000 |
+----+----------+-----+-----------+--------+
现在,您可以使用Group By子句,如下所示,考虑重复的记录条目,获取员工的总工资。
Select name, sum(salary) from customers Group BY name;
执行时,上述查询给出以下输出。
Query: select name, sum(salary) from customers Group BY name
+----------+-------------+
| name | sum(salary) |
+----------+-------------+
| Ramesh | 21000 |
| Komal | 32000 |
| Hardik | 40000 |
| Khilan | 15000 |
| Chaitali | 37000 |
| kaushik | 30000 |
+----------+-------------+
Fetched 6 row(s) in 1.75s
impala having子句
Impala中的Having子句允许您指定过滤哪些组结果显示在最终结果中的条件。
一般来说,Having子句与group by子句一起使用; 它将条件放置在由GROUP BY子句创建的组上。
语法
以下是Havingclause的语法。
select * from table_name ORDER BY col_name [ASC|DESC] [NULLS FIRST|NULLS LAST]
例
假设我们在数据库my_db中有一个名为customers的表,其内容如下 -
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-------------+--------+
| id | name | age | address | salary |
+----+----------+-----+-------------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 6 | Komal | 22 | MP | 32000 |
| 7 | ram | 25 | chennai | 23000 |
| 8 | rahim | 22 | vizag | 31000 |
| 9 | robert | 23 | banglore | 28000 |
+----+----------+-----+-----------+--------+
Fetched 9 row(s) in 0.51s
以下是在Impala中使用Having子句的示例 -
[quickstart.cloudera:21000] > select max(salary) from customers group by age having max(salary) > 20000;
此查询最初按年龄对表进行分组,并选择每个组的最大工资,并显示大于20000的工资,如下所示。
20000
+-------------+
| max(salary) |
+-------------+
| 30000 |
| 35000 |
| 40000 |
| 32000 |
+-------------+
Fetched 4 row(s) in 1.30s
impala 限制条款
Impala中的limit子句用于将结果集的行数限制为所需的数,即查询的结果集不包含超过指定限制的记录。
语法
以下是Impala中Limit子句的语法。
select * from table_name order by id limit numerical_expression;
例
假设我们在数据库my_db中有一个名为customers的表,其内容如下 -
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 3 | kaushik | 23 | Kota | 30000 |
| 6 | Komal | 22 | MP | 32000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 8 | ram | 22 | vizag | 31000 |
| 9 | robert | 23 | banglore | 28000 |
| 7 | ram | 25 | chennai | 23000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
+----+----------+-----+-----------+--------+
Fetched 9 row(s) in 0.51s
您可以使用order by子句按照id的升序排列表中的记录,如下所示。
[quickstart.cloudera:21000] > select * from customers order by id;
Query: select * from customers order by id
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 6 | Komal | 22 | MP | 32000 |
| 7 | ram | 25 | chennai | 23000 |
| 8 | ram | 22 | vizag | 31000 |
| 9 | robert | 23 | banglore | 28000 |
+----+----------+-----+-----------+--------+
Fetched 9 row(s) in 0.54s
现在,使用limit子句,您可以将输出的记录数限制为4,使用limit子句如下所示。
[quickstart.cloudera:21000] > select * from customers order by id limit 4;
执行时,上述查询给出以下输出。
Query: select * from customers order by id limit 4
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
+----+----------+-----+-----------+--------+
Fetched 4 row(s) in 0.64s
impala 偏移条款
一般来说,select查询的resultset中的行从0开始。使用offset子句,我们可以决定从哪里考虑输出。 例如,如果我们选择偏移为0,结果将像往常一样,如果我们选择偏移为5,结果从第五行开始。
语法
以下是Impala中的biasclause的语法。
select data from table_name Group BY col_name;
例
假设我们在数据库my_db中有一个名为customers的表,其内容如下 -
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 3 | kaushik | 23 | Kota | 30000 |
| 6 | Komal | 22 | MP | 32000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 8 | ram | 22 | vizag | 31000 |
| 9 | robert | 23 | banglore | 28000 |
| 7 | ram | 25 | chennai | 23000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
+----+----------+-----+-----------+--------+
Fetched 9 row(s) in 0.51s
您可以按其id的升序排列表中的记录,并使用limit和order by子句将记录数限制为4,如下所示。
Query: select * from customers order by id limit 4
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
+----+----------+-----+-----------+--------+
Fetched 4 row(s) in 0.64s
以下是偏移子句的示例。 这里,我们按照id的顺序在customers表中获取记录,并从第0行开始打印前四行。
[quickstart.cloudera:21000] > select * from customers order by id limit 4 offset 0;
执行时,上述查询给出以下结果。
Query: select * from customers order by id limit 4 offset 0
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
+----+----------+-----+-----------+--------+
Fetched 4 row(s) in 0.62s
以相同的方式,您可以从具有偏移5的行开始从客户表获取四个记录,如下所示。
[quickstart.cloudera:21000] > select * from customers order by id limit 4 offset 5;
Query: select * from customers order by id limit 4 offset 5
+----+--------+-----+----------+--------+
| id | name | age | address | salary |
+----+--------+-----+----------+--------+
| 6 | Komal | 22 | MP | 32000 |
| 7 | ram | 25 | chennai | 23000 |
| 8 | ram | 22 | vizag | 31000 |
| 9 | robert | 23 | banglore | 28000 |
+----+--------+-----+----------+--------+
Fetched 4 row(s) in 0.52s
impala Union条款
您可以使用Impala的Union子句组合两个查询的结果。
语法
以下是Impala中的Union子句的语法。
query1 union query2;
例
假设我们在数据库my_db中有一个名为customers的表,其内容如下 -
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 9 | robert | 23 | banglore | 28000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 7 | ram | 25 | chennai | 23000 |
| 6 | Komal | 22 | MP | 32000 |
| 8 | ram | 22 | vizag | 31000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 3 | kaushik | 23 | Kota | 30000 |
+----+----------+-----+-----------+--------+
Fetched 9 row(s) in 0.59s
同样,假设我们有另一个名为employee的表,其内容如下 -
[quickstart.cloudera:21000] > select * from employee;
Query: select * from employee
+----+---------+-----+---------+--------+
| id | name | age | address | salary |
+----+---------+-----+---------+--------+
| 3 | mahesh | 54 | Chennai | 55000 |
| 2 | ramesh | 44 | Chennai | 50000 |
| 4 | Rupesh | 64 | Delhi | 60000 |
| 1 | subhash | 34 | Delhi | 40000 |
+----+---------+-----+---------+--------+
Fetched 4 row(s) in 0.59s
以下是Impala中的union子句的示例。 在此示例中,我们按照ID的顺序在两个表中排列记录,并使用两个单独的查询并使用UNION子句连接这些查询来将其数量限制为3。
[quickstart.cloudera:21000] > select * from customers order by id limit 3
union select * from employee order by id limit 3;
执行时,上述查询给出以下输出。
Query: select * from customers order by id limit 3 union select
* from employee order by id limit 3
+----+---------+-----+-----------+--------+
| id | name | age | address | salary |
+----+---------+-----+-----------+--------+
| 2 | Khilan | 25 | Delhi | 15000 |
| 3 | mahesh | 54 | Chennai | 55000 |
| 1 | subhash | 34 | Delhi | 40000 |
| 2 | ramesh | 44 | Chennai | 50000 |
| 3 | kaushik | 23 | Kota | 30000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
+----+---------+-----+-----------+--------+
Fetched 6 row(s) in 3.11s
impala with子句
如果查询太复杂,我们可以为复杂部分定义别名,并使用Impala的with子句将它们包含在查询中。
语法
以下是Impala中的with子句的语法。
with x as (select 1), y as (select 2) (select * from x union y);
例
假设我们在数据库my_db中有一个名为customers的表,其内容如下 -
[quickstart.cloudera:21000] > select * from customers;
Query: select * from customers
+----+----------+-----+-----------+--------+
| id | name | age | address | salary |
+----+----------+-----+-----------+--------+
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
| 9 | robert | 23 | banglore | 28000 |
| 2 | Khilan | 25 | Delhi | 15000 |
| 4 | Chaitali | 25 | Mumbai | 35000 |
| 7 | ram | 25 | chennai | 23000 |
| 6 | Komal | 22 | MP | 32000 |
| 8 | ram | 22 | vizag | 31000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 3 | kaushik | 23 | Kota | 30000 |
+----+----------+-----+-----------+--------+
Fetched 9 row(s) in 0.59s
同样,假设我们有另一个名为employee的表,其内容如下 -
[quickstart.cloudera:21000] > select * from employee;
Query: select * from employee
+----+---------+-----+---------+--------+
| id | name | age | address | salary |
+----+---------+-----+---------+--------+
| 3 | mahesh | 54 | Chennai | 55000 |
| 2 | ramesh | 44 | Chennai | 50000 |
| 4 | Rupesh | 64 | Delhi | 60000 |
| 1 | subhash | 34 | Delhi | 40000 |
+----+---------+-----+---------+--------+
Fetched 4 row(s) in 0.59s
以下是Impala中的with子句的示例。 在本示例中,我们使用with子句显示年龄大于25的员工和客户的记录。
[quickstart.cloudera:21000] >
with t1 as (select * from customers where age>25),
t2 as (select * from employee where age>25)
(select * from t1 union select * from t2);
执行时,上述查询给出以下输出。
Query: with t1 as (select * from customers where age>25), t2 as (select * from employee where age>25)
(select * from t1 union select * from t2)
+----+---------+-----+-----------+--------+
| id | name | age | address | salary |
+----+---------+-----+-----------+--------+
| 3 | mahesh | 54 | Chennai | 55000 |
| 1 | subhash | 34 | Delhi | 40000 |
| 2 | ramesh | 44 | Chennai | 50000 |
| 5 | Hardik | 27 | Bhopal | 40000 |
| 4 | Rupesh | 64 | Delhi | 60000 |
| 1 | Ramesh | 32 | Ahmedabad | 20000 |
+----+---------+-----+-----------+--------+
Fetched 6 row(s) in 1.73s
impala DISTINCT运算符
Impala中的distinct运算符用于通过删除重复值来获取唯一值。
语法
以下是distinct操作符的语法。
select distinct columns… from table_name;
例
假设我们在Impala中有一个名为customers的表,其内容如下 -
[quickstart.cloudera:21000] > select distinct id, name, age, salary from customers;
Query: select distinct id, name, age, salary from customers
在这里您可以观察客户Ramesh和Chaitali输入两次的工资,并使用distinct运算符,我们可以选择唯一值,如下所示。
[quickstart.cloudera:21000] > select distinct name, age, address from customers;
执行时,上述查询给出以下输出。
Query: select distinct id, name from customers
+----------+-----+-----------+
| name | age | address |
+----------+-----+-----------+
| Ramesh | 32 | Ahmedabad |
| Khilan | 25 | Delhi |
| kaushik | 23 | Kota |
| Chaitali | 25 | Mumbai |
| Hardik | 27 | Bhopal |
| Komal | 22 | MP |
+----------+-----+-----------+
Fetched 9 row(s) in 1.46s
impala 相关资源
impala 相关资源
以下资源包含有关Impala的其他信息。 请使用它们获得更多的深入的知识。
impala相关链接
- Impala Wiki - 百科参考帕拉
impala 相关讨论
Impala是Apache Hadoop的开源,本地分析数据库。 它由Cloudera,MapR,Oracle和Amazon等供应商提供。 本教程中提供的示例一直使用Cloudera Impala进行开发。
