




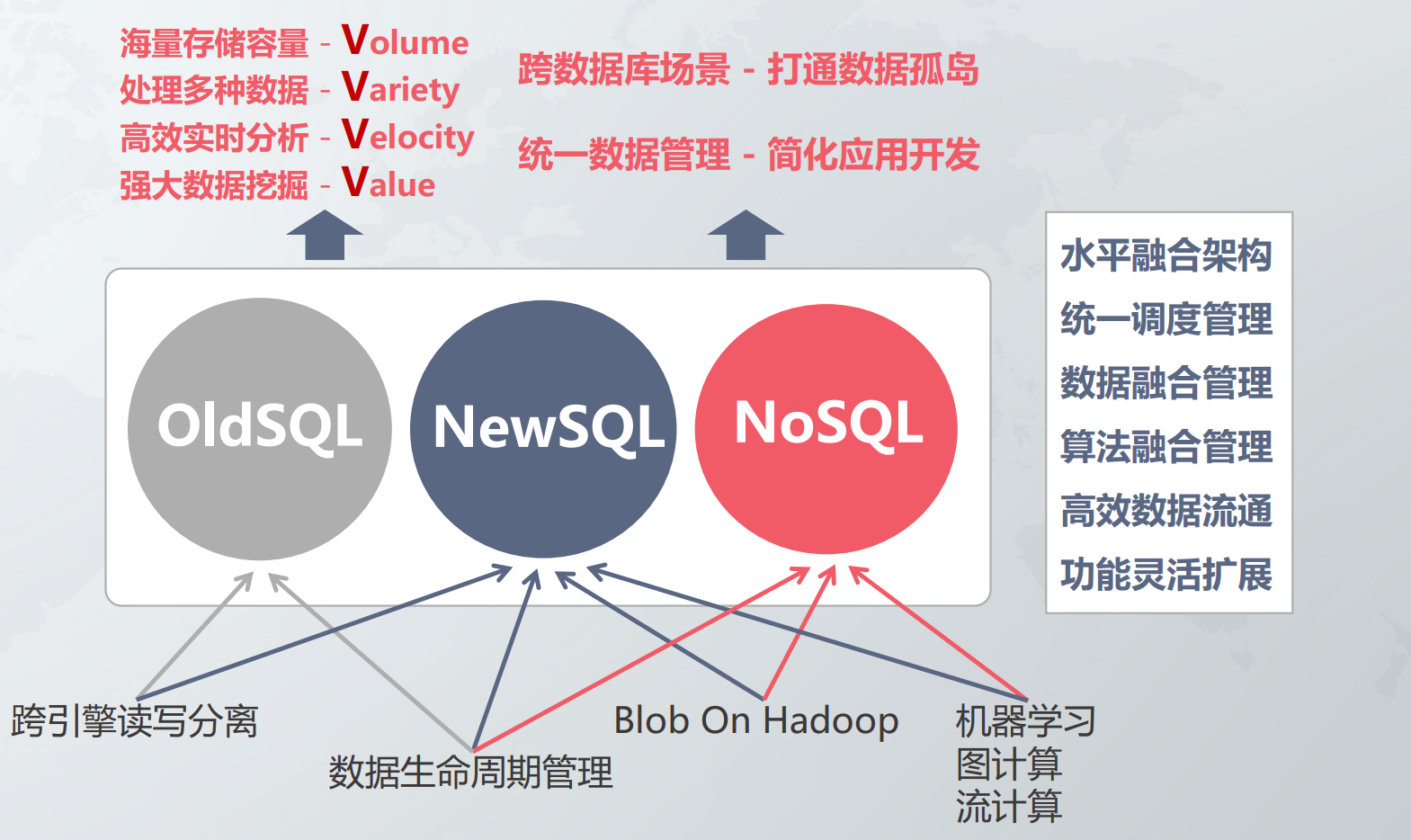
GBase UP产品的特点及其价值体现:
数据融合
异构引擎透明访问 简化应用开发,降低数据建模的复杂度 跨引擎数据交换 高吞吐率的多对多通讯机制 跨引擎关联查询 实现自动优化的引擎间关联分析 BLOB on Hadoop 扩展非结构化数据存储和计算能力
数据流通
跨引擎读写分离 支撑大规模数据事务处理和实时BI数据分析 数据生命周期管理 按不同温度选择最合适的引擎存储数据,降低数据总体持有成本 PB级备份与恢复 实现在线PB级数据备份与恢复
算法融合
跨引擎UDF扩展 支持跨引擎UDF函数,灵活扩展系统的计算能力 机器学习 融合Spark机器学习算法,实现 In-Database Analysis R语言 同时适应偏向SQL和偏向R的用户
处理的核心问题
统一调度
数据融合
算法融合
数据流通
Mega SQL Engine (SQL92 + SQL')
• 统一接口
• 统一查询语言
• 统一用户管理和权限控制
• 统一元数据
• 跨引擎优化器和计划器
• 跨引擎关联查询
• 跨引擎数据分区和镜像
• 计算扩展
• 并行调度器
• 引擎适配器
Data Exchange Layer
并行数据交换 跨引擎数据一致性 实时同步
Data Exchange Layer
• 跨引擎并行数据交换
• 跨引擎数据一致性、完整性
• 实时同步
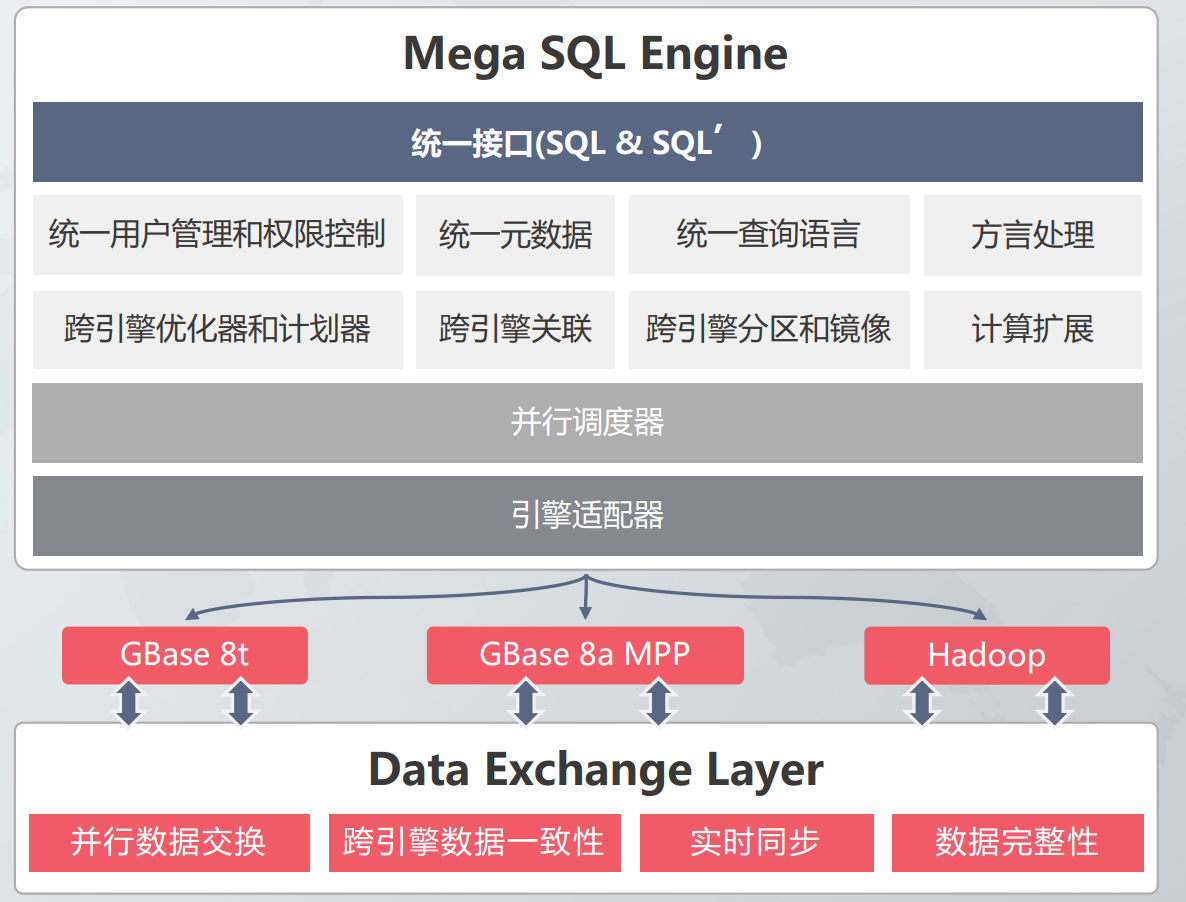
系统架构图
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
