




建立空间索引的图形列通过表达式、函数、类型转换后导致索引失效。
部分空间函数根本不会走空间索引。
索引效率低,IO与CPU放大严重。
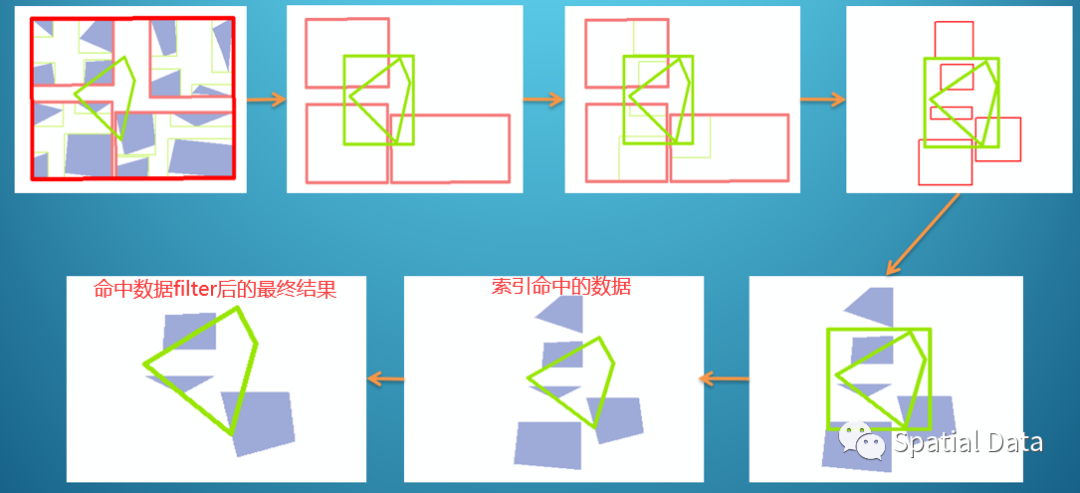
当查询的时候,用查询条件的图形的bbox去索引里扫描,看哪些图形的bbox与查询条件图形的bbox有交集并返回,这就是查询计划里的索引扫描,是bbox与bbox的计算,IO密集型。
最后,对索引扫描到的空间数据,使用其真实的图形与查询条件真实图形做比较,获取真正的图形空间关系,这就是查询计划里的Filter,是geom与geom的计算,CPU密集型。
一个典型的空间查询就是先扫描索引,再Filter过滤,示例如下
explain select * from house wherest_intersects(geom,st_geomfromtext('Polygon((118 32,118.5 33,119 32,118 32))',4326));

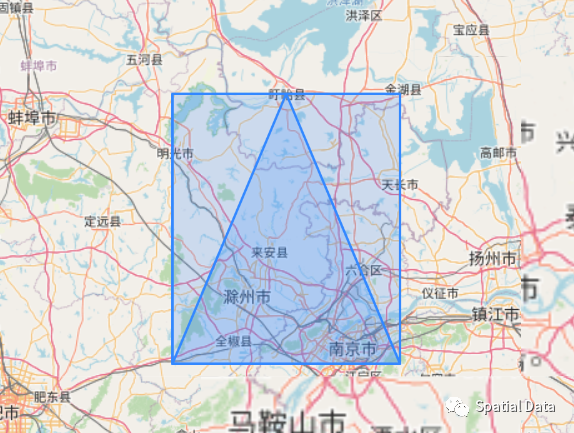
类似上图的情况,就是实际查询图形不大,可bbox很大,导致IOCPU放大从而查询性能低下的情况,一般遵循一个原则“拆”,本文将根据实际案例做说明。
场景说明:当前有近10万电力设备点分布于全国,要求统计暴雨面影响到的电力设备数量。暴雨面是MultiPolygon类型,上图可知,数据描述如下图:
#电力设备测试数量select count(*) from dlsb;count-------99007(1 行记录)# 测试的暴雨数据select count(*) from rain;count-------1(1 行记录)# 暴雨图斑多义图形,由几百个Polygon子图形组成select St_GeometryType(geom) GeomType,ST_NumGeometries(geom) GeomCount from rain;geomtype | geomcount-----------------+-----------ST_MultiPolygon | 307(1 行记录)
select count(a.*) from dlsb a,rain bwhere st_intersects(a.geom,b.geom);count-------12814(1 行记录)Time: 41401.309 ms (00:41.401)
新建一个拆分表,并建立索引,把大图形拆成小图形,结果存储到该表:
--新建一个新的表,存储拆分后的图形
CREATE TABLE rain_single
(
gid serial primary key,
geom geometry(Polygon,4326)
);
--建立索引
CREATE INDEX rain_single_geom_idx
ON rain_single USING gist
(geom);
--将拆分结果存入新的表中
INSERT INTO public.rain_single(geom) SELECT
ST_GeometryN(a.geom, n) As geom FROM rain a
CROSS JOIN generate_series(1,400) n WHERE n <= ST_NumGeometries(a.geom);
select count(a.*) from dlsb a,rain_single b where st_intersects(a.geom,b.geom);
count-------
12814
(1 行记录)
Time: 6088.242 ms (00:06.088)
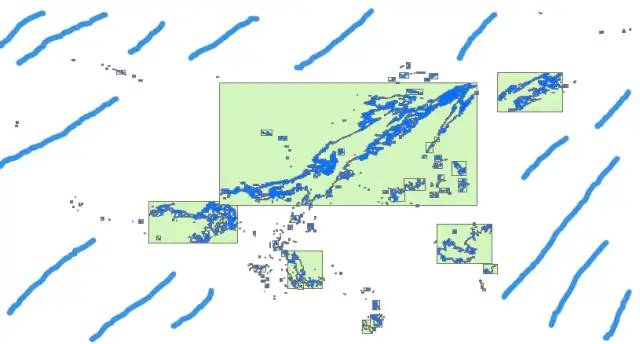
#生成切割测试数据
SELECT row_number() OVER() As id,geom into rain_Subdivide
from (select ST_SubDivide(geom,40) geom from rain_single) as f(geom);
alter table rain_Subdivide alter column geom type
geometry(Polygon,4326) using geom:: geometry(Polygon,4326);
#建立索引
create index rain_Subdivide_geom_idx on abc using gist(geom);
select count(a.*) from dlsb a,rain_Subdivide b where
st_intersects(a.geom,b.geom);
count-------
12814
(1 行记录)
时间:69.127 ms
