




项目背景

源码编译
git clone -b v2.0.0 https://github.com/apache/incubator-streampark.git
sh build.sh
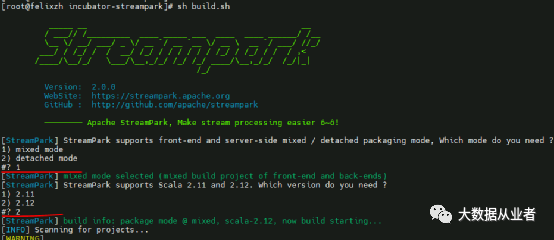
/home/mySourceCode/incubator-streampark/dist

安装部署
tar –xvf apache-streampark_2.12-2.0.0-incubating-bin.tar.gz
vim conf/application.ymlspring:profiles.active: mysqlvim conf/application-mysql.ymlmysql用户名、密码、IP
source /home/myHadoopCluster/apache-streampark_2.12-2.0.0-incubating-bin/script/schema/mysql-schema.sqlsource /home/myHadoopCluster/apache-streampark_2.12-2.0.0-incubating-bin/script/data/mysql-data.sql


添加export HADOOP_HOME=/usr/hdp/3.1.5.0-152/hadoop到bin/startup.sh。sh startup.sh
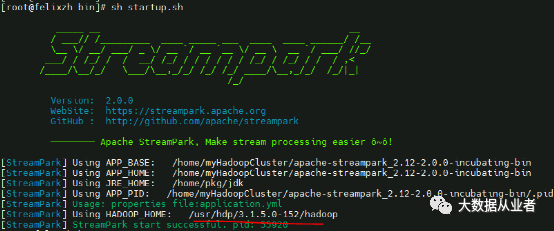
设置FlinkHome
SQL实践案例
CREATE TABLE datagen (f_sequence INT,f_random INT,f_random_str STRING,ts AS localtimestamp,WATERMARK FOR ts AS ts) WITH ('connector' = 'datagen',-- optional options --'rows-per-second'='5','fields.f_sequence.kind'='sequence','fields.f_sequence.start'='1','fields.f_sequence.end'='500','fields.f_random.min'='1','fields.f_random.max'='500','fields.f_random_str.length'='10');CREATE TABLE print_table (f_sequence INT,f_random INT,f_random_str STRING) WITH ('connector' = 'print');INSERT INTO print_table select f_sequence,f_random,f_random_str from datagen;

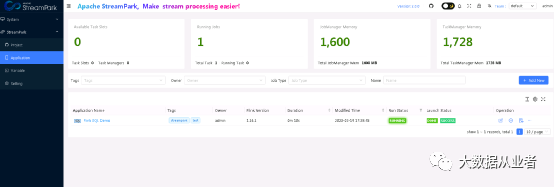
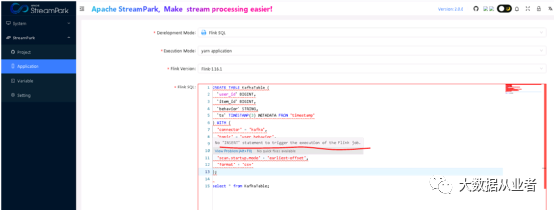
JAR实践案例
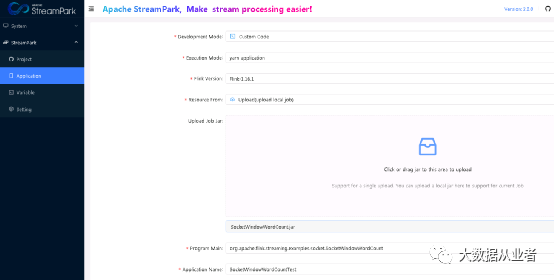

https://github.com/felixzh2020/felixzh-learning-flink/tree/master/JarManifestParserDemo

文章转载自大数据从业者,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
