




数据在各生命周期有不同的处理要求,尤其是时间序列数据,其业务场景常常是初期集中于 OLTP,中期用于 OLAP,后期很少使用,只是偶尔用于历史数 据分析,整体呈现热、温、冷三种典型的处理模型,从存储成本和计算特征考 虑,不同时期的数据采用不同的引擎存储。 最常见的一种情况,最近生成的数据会被频繁使用和修改,将其存放在 GBase 8t 中,将近期生成但不再更新的数据放在 GBase 8a 中,将历史数据放 在 Hive 中。用户通过 SQL 透明读写,而 GBase UP 按照设定的数据迁移策略后 台自动透明的高效迁移。
代码示意: 创建分区表,按热、温、冷分别存储在三个数据引擎
Create table t_part (…, in_date date) partition by range(in_date)
(partition p_hive values less than (date_sub(current_date(),interval 1 month))
engine=‘Hive’,
partition p_8a values less than (date_sub(current_date(),interval 1 week))
engine=‘GBase8a’,
partition p_8t values less than MAXVALUE engine=‘GBase8t’);
统一平台必须支持统一的用户管理和授权,但是各引擎之间可能差异很大, 如 GBase 8a MPP 和 Hive:
Hive授权有 user、group、role三个维度,权限有 8项 ALTER ,CREATE, DROP, INDEX, LOCK, SELECT, SHOW_DATABASE,UPDATE,但 Hive 并无 create user 或 create group 语句,而是有 create role,drop role 等语句。
GBase 8a MPP 的按 SQL92 标准,有 user 的 create、drop、show 、rename, set password 授 权 范 围 全 局 、 库 、 表 、 字 段 共 四 级 , 授 权 项 有 ALL [PRIVILEGES],ALTER,ALTER ROUTINE,CREATE,CREATE ROUTINE, CREATE TEMPORARY TABLES ,CREATE USER, CREATE VIEW, DELETE, DROP,EXECUTE, FILE, GRANT OPTION,INDEX,INSERT,PROCESS,RELOAD,SELECT,SHOW DATABASES,SHOW VIEW,UPDATE,USAGE 共 25 项。
从用户角度,GBaseUP 采用 GBase 8a MPP 的用户管理和授权模式,逐步融 合 Hive,GBase 8t 的特色模式 。
BLOB on Hadoop
采用 HBASE 和 HDFS 存储海量中小文件是近几年成熟起来的方案,GBase UP 内部融合此方案,同时更加灵活,具体是扩展 BLOB 类型,增加 URI 模式,使 其能够存储从微博、微信的图片到一张 DVD 9 的电影。即将 BLOB URI 作为 GBase 8a MPP 访问外部数据的一种方式,即在 8a 中存储 URI 字符串,实际数据在 URI 标识的访问位置,同时有 Last Modi,Content Length、MD5 等校验手段保证数 据的一致性和完整性。
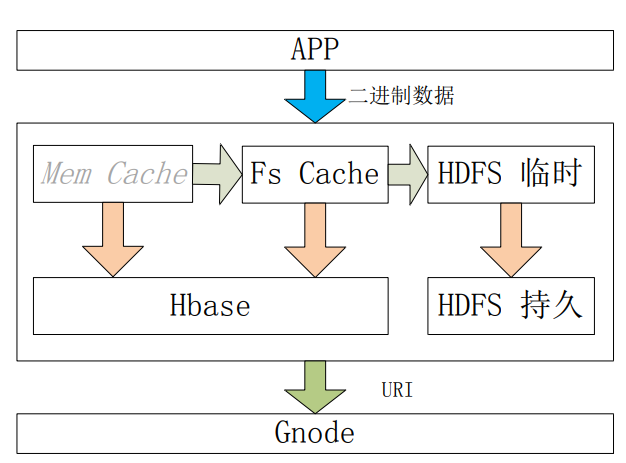
Cache 和存储
APP 采用 JDBC、CAPI 与 UP 相连接,可以通过正常的预处理查询模式读写 BLOB 字段,大大简化开发的复杂度。同时借助内存、磁盘、HDFS 临时目录的模 式兼顾事务原子性和执行效率。
用户定义函数(UDF User defined Function)扩展是由第三方开发的特定
算法模型引入到数据库系统的常见方式,在 UP 中,将关系数据库、图数据库、
KV 数据库等数据库引擎的内置函数和 UDF 都可以作为 UP 的 UDF 函数,实现数
据和算子的融合,存储各个引擎的数据可以借助其他引擎的算子进行交互计算,
支持上下文无关运算和上下文相关的聚合计算,计算参数和结果可以是字段也
可以是表对象。考虑到 UDF 的占用资源和稳定性,建立 UDF 沙盒容器,控制容
器的资源占用,监视其稳定性,当资源可控和保证稳定性后,可以考虑将 UDF
移入数据库管理系统以提高运行效率。
代码示意:
Create table t1_oltp(website varchar(200), clickcount number(10)…) engine=‘GBase8t’;
Create table t2_hive(key bigint, url varchar(1000), weichat varchar(5000), …) engine=‘Hive’;
Insert into t2_hive … ;
-- 注册用户自定义函数
Create function extractwebsite returns string soname ‘hive_common.so’;
-- SQL 中调用自定义函数
Insert into t1_oltp(website,clickcount) select extractwebsite(url), count(*) from t2_hive;
Hive、Spark、GBase 8t 的内置专有函数和 UDF 扩展函数,都可以通过注 册的方式引入到 UP,作为 UP 层的 UDF 函数在 SQL 中调用。
