




本期将分享近期全球知识图谱相关
行业动态、论文推荐

近日,微软宣布了 Semantic Kernel,这是一个旨在更深层次理解自然语言的新项目。它旨在利用下一代模型的新兴功能,包括 OpenAI 的 GPT-4 ,并通过 Azure OpenAI 服务支持模型。
Semantic Kernel是一组模型和工具,可以分析自然语言文本并生成丰富的语义表示以捕捉其含义和结构。语义内核基于两个关键思想:语义解析和知识图谱嵌入。语义解析是一种将自然语言文本转换为结构化表示的技术,使用逻辑或基于图的语言等形式语言捕获其含义。知识图谱嵌入是一种学习维基百科或 Freebase 等大规模知识图谱中实体和关系的向量表示的技术。通过结合这两种技术,语义内核可以生成既具有表现力又具有可扩展性的语义表示。
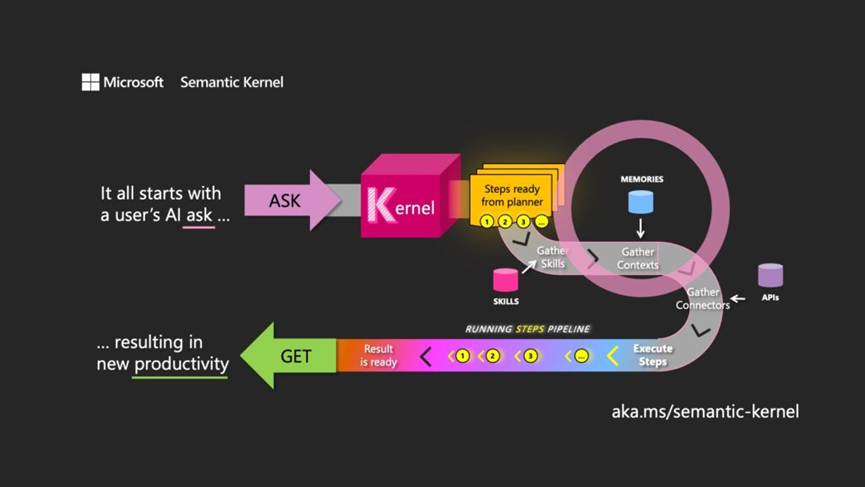
语义内核由三个主要组件组成:
– SK-Parse:一种语义解析器,可将自然语言文本转换为图的表示形式,称为 SK-graphs。
– SK-Embed:知识图谱嵌入器,使用深度神经网络学习 SK 图中实体和关系的向量表示。
– SK-API:一组 API,允许用户访问语义内核的各种功能,例如使用自然语言查询 SK-graph 或从 SK-graph 生成自然语言文本。
3月18日,“2023世界中联中医药大数据产业高峰论坛”在西部(重庆)科学城举行,此次论坛由世界中医药学会联合会中医药大数据产业分会和北京大学重庆大数据研究院联合主办,来自高校、协会、医院、企业的数十名院士专家代表围绕中医药大数据技术创新及应用展开了讨论。
针对基层中医存在的学习慢、记不住、理不清的痛点,北京大学重庆大数据研究院中医药大数据实验室研发了智慧中医药一体化服务平台,为中医药行业赋能。
该平台将中医药与大数据和人工智能技术相结合,通过中医辨证论治智能辅助诊疗技术,可以快速提升基层中医药服务能力。目前,该平台已推出了两款产品,即:面向各级中医院推出基于知识图谱的中西医结合知识库和新一代中医辨证论治智能辅助系统。

企业知识图谱(EKG)技术和语义数据库引擎提供商Ontotext近日宣布Ontotext Metadata Studio 新版上线。最新的产品使用户能够利用其知识图谱中的分类实例数据,以实现高度可解释和可定制的开箱即用分类驱动的标记。
在版本 3.2 中,Ontotext Metadata Studio 使非技术最终用户能够通过标记和链接自己的业务域模型来创建、评估和提高其文本分析服务的质量。借助广泛的可解释性和控制功能,不精通文本分析技术的用户可以了解基础数据集、特定文本分析服务配置和最终输出之间的因果关系。这些增强功能可实现高效的用户干预,使人类真正进入循环并完全控制整个提取过程。
通过大量的用户体验改进,该版本采用了敏捷的文本分析开发方法,实现了短迭代时间和快速反馈循环,同时尽可能接近业务用户。

本周推荐的是一篇发表于WSDM 2023的论文:Active Ensemble Learning for Knowledge Graph Error Detection,提出了一个利用主动和集成学习技术进行知识图谱错误检测的框架KAEL,作者主要来自香港理工大学。

知识图谱近年来在多种任务中广泛应用,但是在知识图谱构造的过程中,错误不可避免,需要合适的方式进行错误的发现和纠正,常用的方法如规则挖掘和嵌入技术等。文章认为,不同的检错器倾向于关注不同类型的错误,而使用集成学习方法有希望充分发挥不同技术的优势。但现有很多集成学习的工作都采用监督学习范式,在知识图谱错误检测任务中不适用,且集成过程中需要模型能够迭代和主动学习,如何应对知识图谱巨大的搜索空间也是一个挑战。
为此,文章提出了一个主动集成的知识图谱错误检测框架KAEL,设计了一个三阶段的主动学习范式,使用多臂老虎机(Multi-armed Bandit, MAB)模型进行基学习器的集成,整体框架如下图所示。
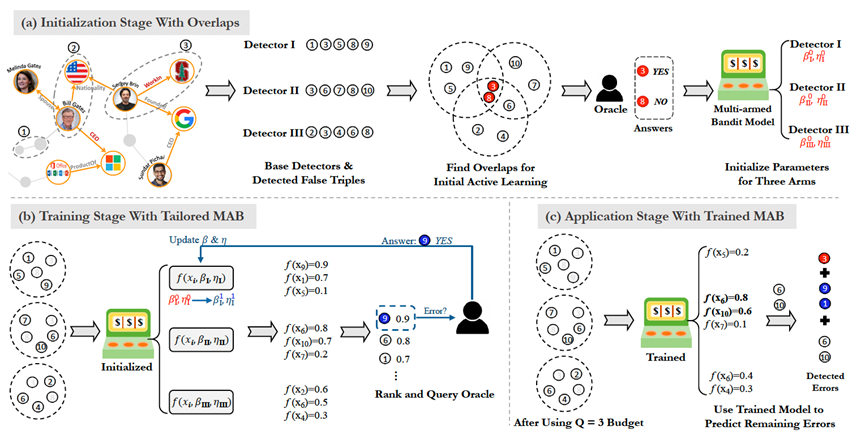
文章在WN18RR、FB15K-237、UMLS等数据集上进行了实验,实验结果证明了文章框架及其设计的集成学习和主动学习策略在知识图谱错误检测任务上的有效性。
更多链接
内容:胡喆媛、代雪佩、薛冰聪、王图图
编辑:王图图
排版:王图图

诚邀您加入我们的gStore社区,我们将在群内解决使用问题,分享最新成果~
请在微信公众号图谱学苑发送“社区”入群~或扫码入群



欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:http://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

