




前言
说到一致性Hash,就有必要先说说Hash。
Hash是一种负载均衡的算法,在各种语言中都有类似的实现,如Java中的HashMap,可以通过key的Hash值来达到负载均衡,避免数据热点。也可以通过key的Hash的值,能比较快速地查找到value,随机查找的效率比list快很多。
很多高级算法也是基于Hash的算法提供高效的查找或者判断能力,如布隆过滤器(如果感兴趣可以看看之前我写的这篇文章"不靠谱"的布隆过滤器是怎么成为大数据世界中的韦小宝的?)。
说了这么多Hash算法的优点,那Hash算法有什么缺点吗?
显然是有的,否则就没有今天主角什么事了。
试想下,如果用四台服务器存储数据,而存储时是按照Hash进行路由,根据不同的Hash值去不同的服务器进行存储,查询时也是通过Hash值去不同的服务器读取数据,达到负载均衡的目的。
看起来这个方案还是不错的,理论上四台机器共同分摊读写的压力。但是会有什么问题呢?问题就是计划没有变化快。
随着数据量的变化,服务器的数量也会增减。如果服务器减少或者增多,所有客户端都需要进行重新Hash,然后进行分配。
这样会造成一个问题,就是数据需要在服务端也需要进行重新Hash后传输到对应的服务器以适配客户端的查询,如果数据量很大的话,这个开销将会是致命的,不仅服务端需要很大的开销,客户端的不可用时间也会是可不接受的。
那针对上面的场景该如何解决呢?本文的主角就闪亮登场了。

正文
一致性Hash的定义
下面先来看看一致性Hash的定义:
一致性Hash(Consistent Hashing)算法是常用的一种分布式Hash算法,主要用于解决分布式系统中的负载均衡问题。通过将数据映射到一个环形空间中,每个节点对应环上的一个位置,通过对环上的位置进行划分,将数据分布到不同的节点上。这样一来,当新增或删除节点时,只需要调整其对应范围内的数据,而不需要对所有数据重新Hash,大大减小了网络传输和计算成本,提高了集群的稳定性和扩展性。
在一致性Hash算法中,使用Hash函数将数据的键(key)映射到一个0到2^32-1的整数范围内。每个节点也被映射到这个范围内的一个整数值。
数据存取
对于一个键,可以沿着环顺时针或逆时针找到离它最近的节点。这个节点被称为这个键的“owner”,也就是负责处理这个键的节点。映射后数据的分布如图所示:
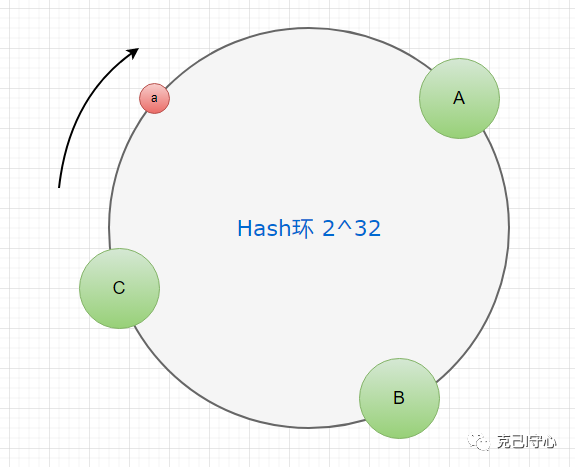
从图上可以看出来,数据a将会被节点A管理,负责a的存储与读取。通常,在一致性Hash的环上,所有节点都对应着一个固定的范围,而且这个范围还保证了数据均匀分布。
节点增减
当有新的节点加入时,通过计算新节点在环上的位置,然后找到其后面所跟的节点,将这个节点负责的数据范围分配给新节点,保证数据在每个节点间的分布均匀。
如下图所示,新增的D节点将会负责节点C到节点D之间数据的存储。这部分数据之前属于A节点管理,此时的A节点只负责管理D节点到A节点之间的数据。
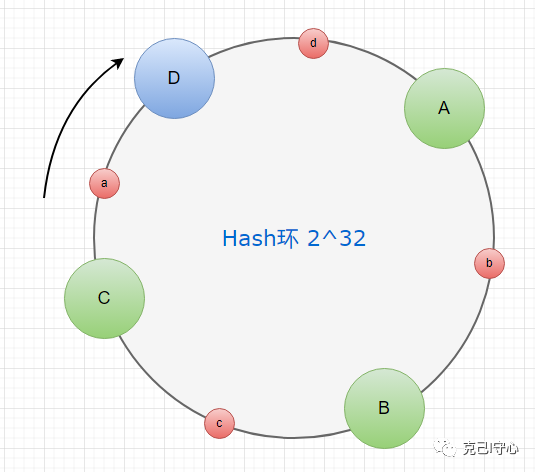
虽然增加了节点D后,a的存取失效了,但是,分布在 A-B,B-C 以及 D-A上面的数据仍然有效,失效的只是C-D段的数据(数据存在A节点,但是顺时针获取的服务器是D)。这样就保证了缓存数据不会像hash算法那样大面积失效,同样起到减轻数据迁移压力的效果。
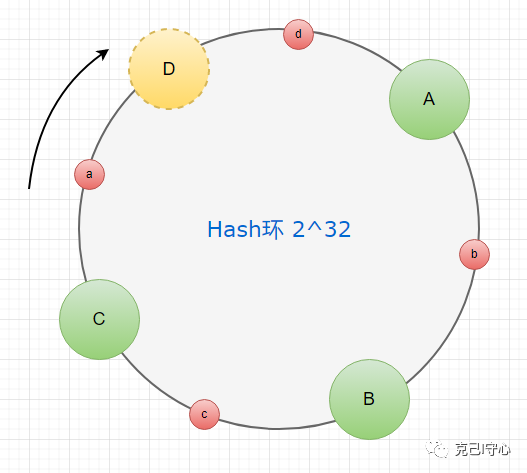
当节点失效时,只需要取出它在环上负责的数据,将这部分数据分配到和它在环上相邻的节点中,即可实现节点的替换和数据的迁移,而不影响整个系统的正常运行。
如下图所示,失效的D节点负责节点C到节点D之间数据的存储会交给A节点管理
负载均衡
虽然说一致性Hash解决了基础Hash算法的很多弊端,但是上面的方案真的解决了所有的问题了吗?
显然没有,看看下面的场景:
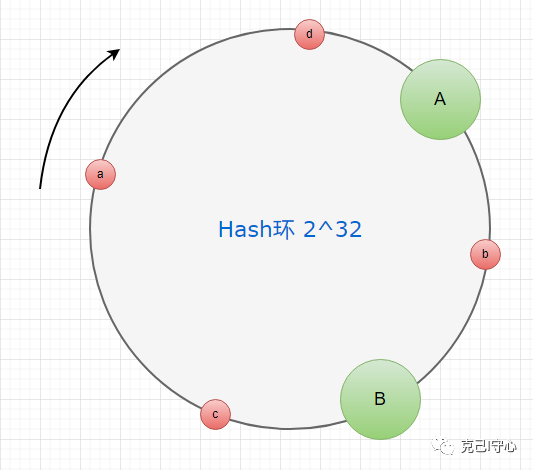
从图上可以看出,整个系统只有两个节点.其中A节点管理a,c,d三条数据;B节点负责管理b数据。A节点的读写压力明显高于B节点,所以负载均衡的效果不是很理想,这种方式一致性Hash如何应对和解决呢?
答案是虚拟节点,将每个节点都通过定位算法生成几个在 Hash 环上的位置,每个位置都承担上面节点的功能,原来每个节点对应一个节点,现在每个节点会对应若干个节点。
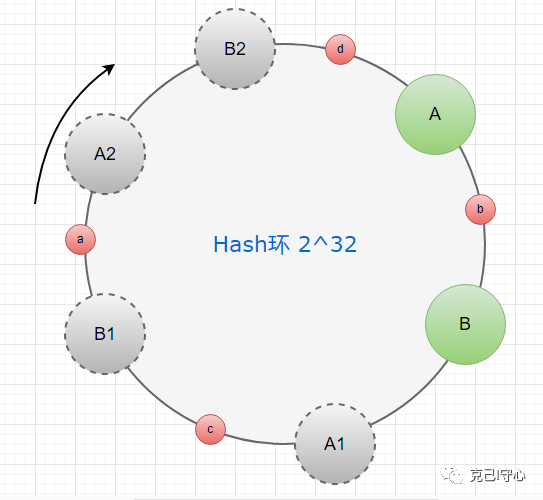
从上图可以看出原来的A,B两个节点,再加入虚拟节点后变成了A,A1,A2以及B,B1,B2 6个虚拟节点。
在加入虚拟节点后,读写流程就变为:数据读写 -> 虚拟节点 -> 真实节点 -> 读写
而在新规则下,A节点负责管理a,d两条数据;B节点负责管理b,c两条数据,负载均衡效果明显好了很多。
总结
上面介绍了一致性Hash的基本原理和操作,下面来总结下一致性Hash的优点以及使用场景。
一致性Hahs的优点包含如下几点:
均匀性:通过环形映射,数据分布更加均匀,在节点动态变化时,数据移动量也更加平均分布,不会引起数据倾斜的现象,更好地保证了各节点的负载均衡。 扩展性:添加或删除节点时,只需要在环上计算每个节点的数据范围即可,不需要重新Hash所有数据,因此可快速、平稳地进行系统扩展。 可靠性:由于数据均匀分布在各节点上,当有节点宕机时,只有部分数据需要迁移,不会造成整个系统崩溃,极大地提高了系统的可靠性。 高效性:减少了数据的重新Hash,降低了计算和网络传输的开销,同时也降低了Hash冲突的可能性,使系统更高效。
使用场景如下:
负载均衡:对于高并发、大规模的应用场景,可以使用一致性Hash算法来实现负载均衡。 分布式缓存:多个节点组成的缓存集群可以使用一致性Hash算法来进行缓存key的映射,保证数据的均匀分布。 分布式文件系统:在分布式文件系统中,可以使用一致性Hash算法将文件块映射到不同的节点上,实现数据均衡分布和快速定位,提高系统的可扩展性和可靠性。
而在现实的各种实现中,一致性Hash算法已经广泛应用于各种场景,总结下来如下:
请求的负载均衡:比如Nginx的ip_hash策略,通过对IP的Hash值来决定将请求转发到哪台Tomcat 分布式存储:比如分布式集群架构Redis、Hadoop、ElasticSearch、Mysql分库分表,数据存入哪台服务器,就可以通过Hash算法来确定
综上所述,一致性Hash算法是一种高效、可靠的分布式Hash算法,可广泛应用于负载均衡、分布式缓存、分布式文件系统等场景。
文章到这里就结束了,最后路漫漫其修远兮,技术之路还很漫长。如果想一起学习各种技术的小伙伴,欢迎点赞转发加关注,下次学习不迷路,我们在技术的路上共同前进!

