




湖仓场景现状和遇到的问题
随着公司业务发展,实时性业务需求越来越多,2021年开始逐步调研并引入湖仓架构,结合当时数据湖架构,最终我们选择 Hudi 作为湖仓底座。通过内部自研数据集成能力能够一键将内部 base 层的 Binglog 数据导入到湖仓内,逐步替代了基于 hive 实时同步,凌晨合并的方式;另外还结合湖上的流读能力,通过增量读的方式将增量结果合并到 DWD 层;以及结合 flink 窗口计算完成了大量实时报表的改造,极大提高了数据时效性,同时也节省了大量批处理合并计算资源。
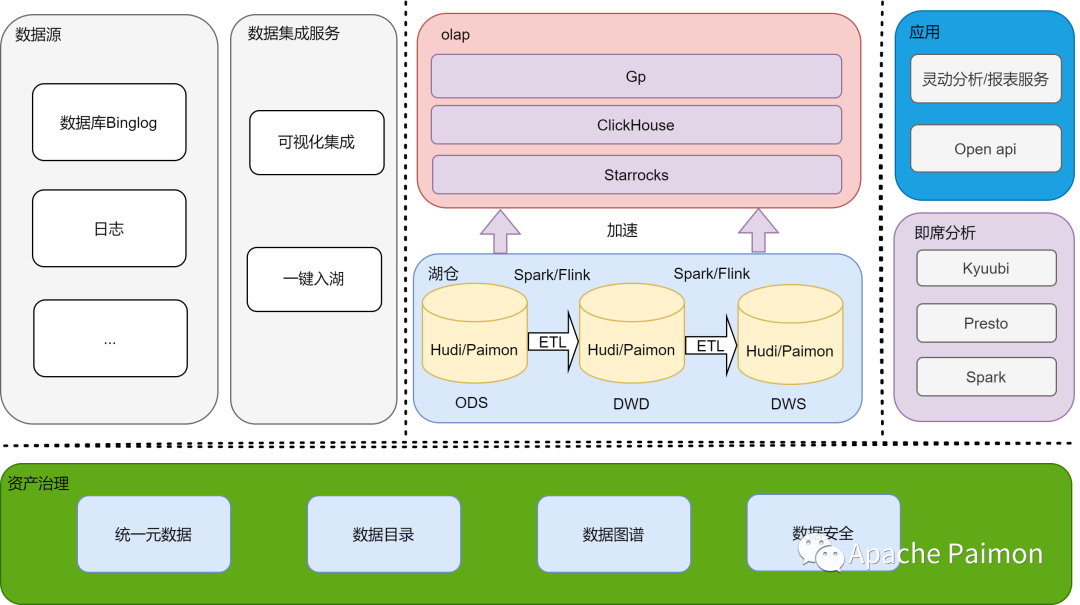
1.1 湖仓应用现状
1.2 湖仓写入性能问题
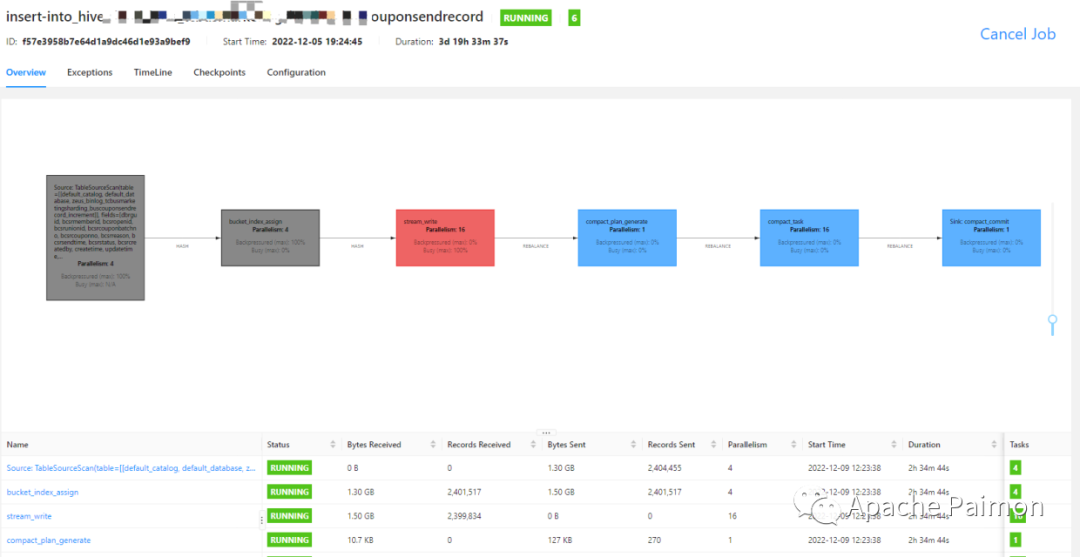
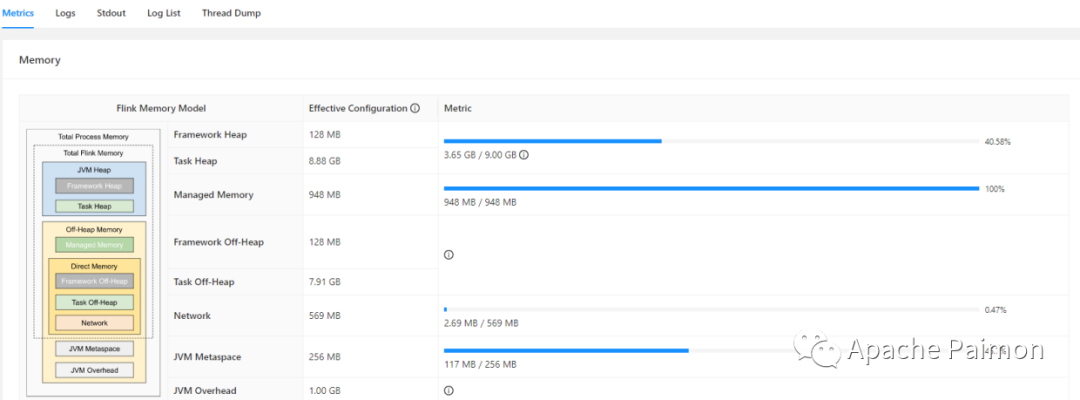
1.3 湖仓查询性能问题
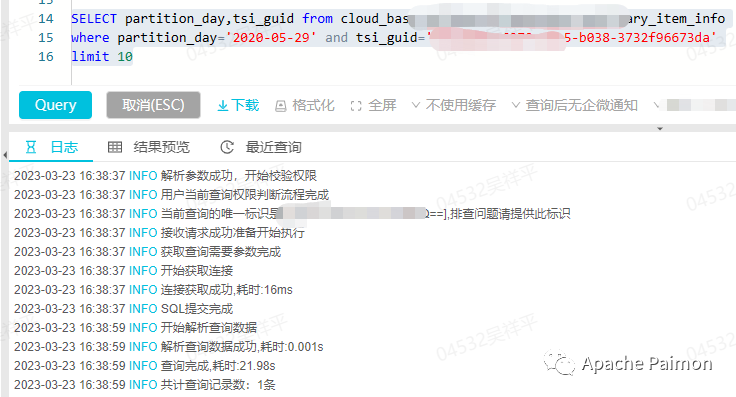
1.4 成本相对较高
遇见 Apache Paimon
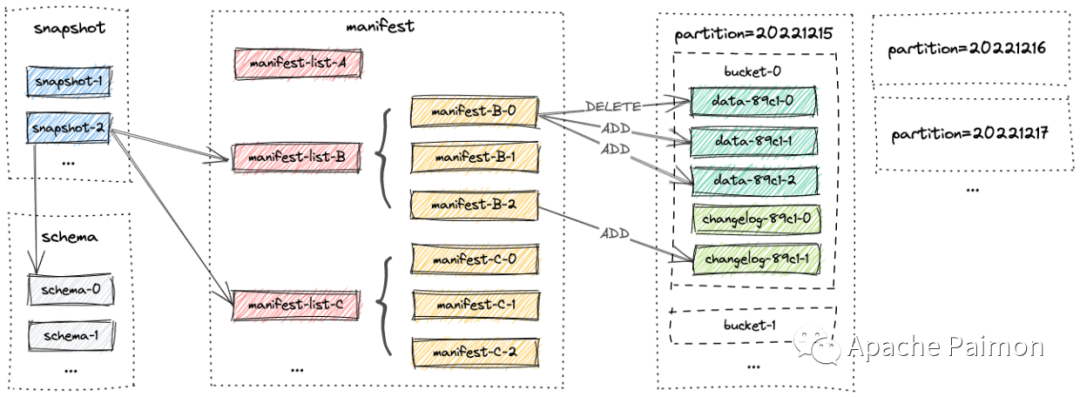
彼时还叫 Flink Table Store,如今成功晋升为 Apache 孵化项目 Apache Paimon,官网地址 [1],首次接触在 FLIP-188: Introduce Built-in Dynamic Table Storage [2] 就被基于原生 LSM 的写入设计以及 universal compaction 深深吸引,便持续关注,在 0.2 时我们开始接入测试使用。https://github.com/facebook/rocksdb/wiki/Universal-Compaction
2.1 Apache Paimon 简介
Apache Paimon(incubating) is a streaming data lake platform that supports high-speed data ingestion, change data tracking and efficient real-time analytics
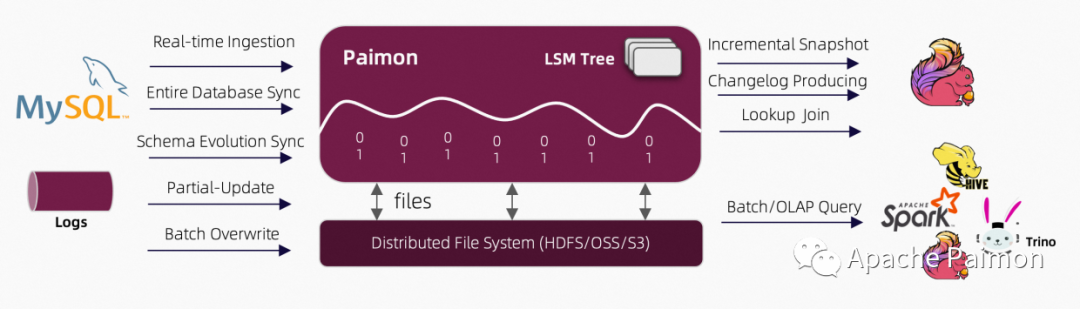
• 近实时高效更新
• 局部更新
• 增量流读
• 全增量混合流读
• 多云存储支持
• 多查询引擎支持
• 特别的 Lookup 能力
• CDC 摄入(进行中)
2.2 基于Apache Paimon优化效果
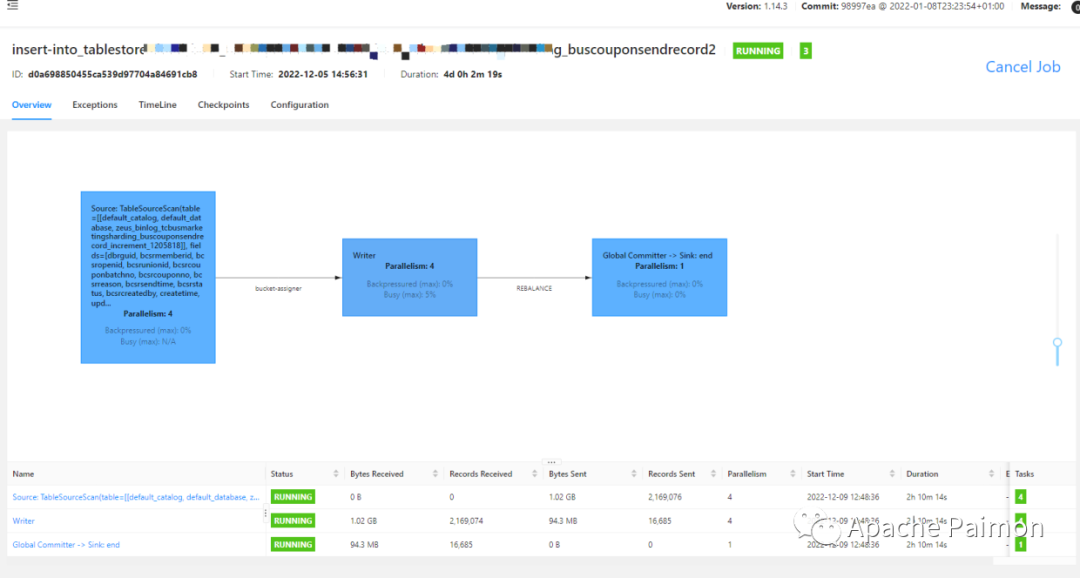
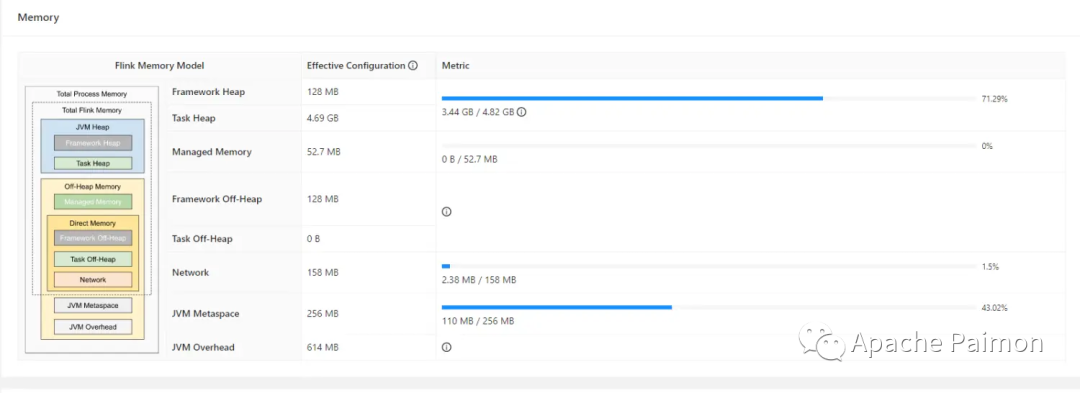
parallelish.default : 2execution.checkpointing.interval : 2 mintaskmanager.memory.process.size : 6g
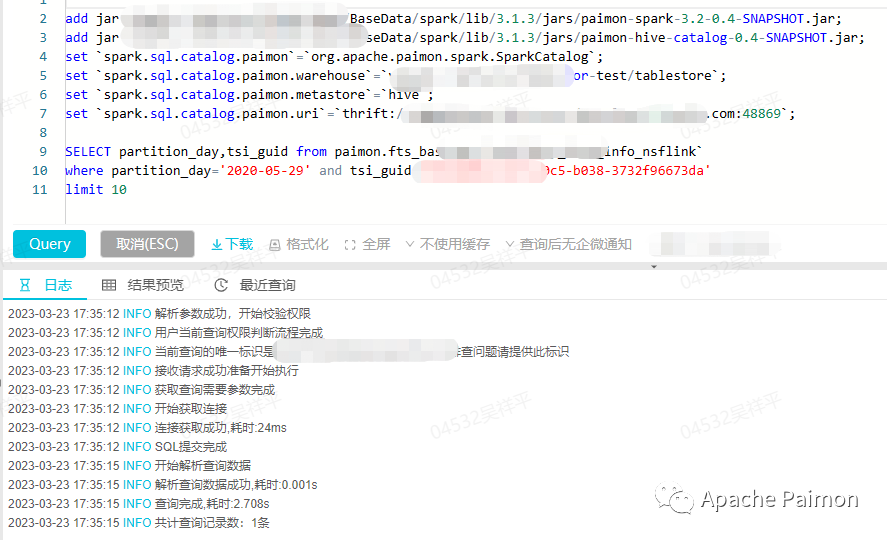
Apache Paimon 的应用实践
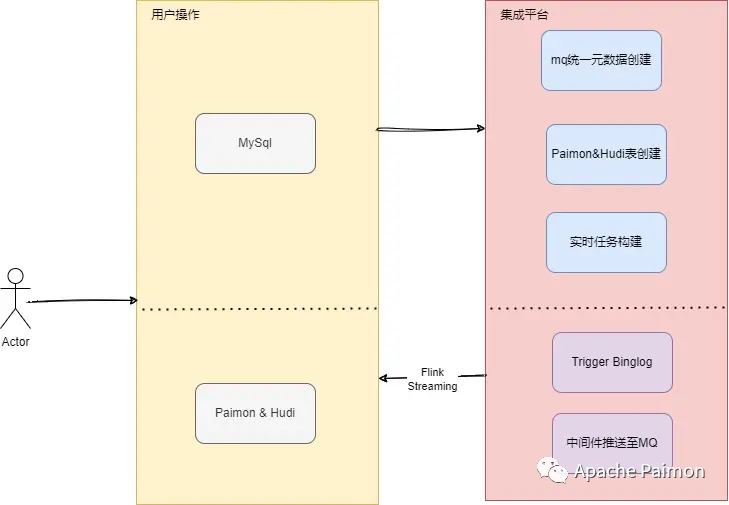
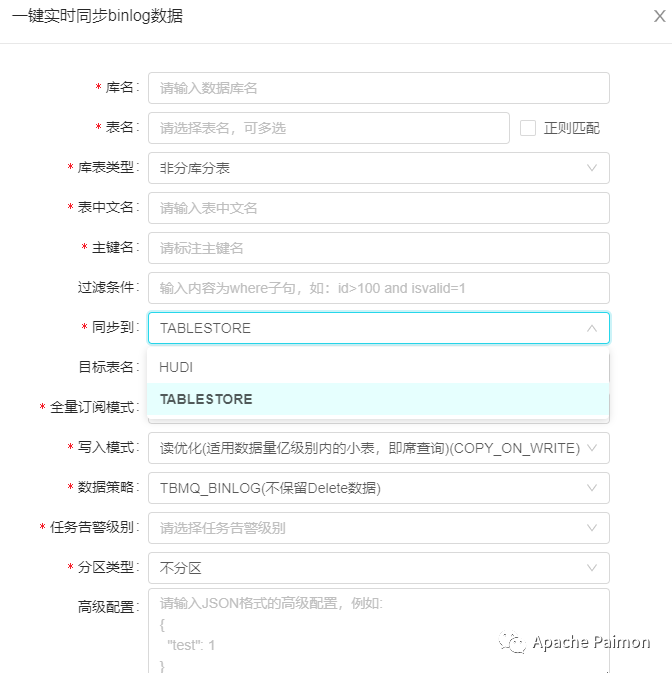
3.1 Paimon的自动化数据集成
INSERT INTO paimon.ods.order_info/*+ OPTIONS('sink.parallelism'='100','write-buffer-size'='1024m','sink.partition-shuffle' = 'true') */SELECT*FROMhudi.ods.order_info/*+ OPTIONS('read.tasks' = '100') */;
3.2 基于 Partial Update 的准实时宽表
'merge-engine' = 'partial-update'
• 结果表字段由多个数据源提供组成,可使用 Union All 的方式进行逻辑拼接
--FlinkSQL参数设置set `table.dynamic-table-options.enabled`=`true`;SET `env.state.backend`=`rocksdb`;SET `execution.checkpointing.interval`=`60000`;SET `execution.checkpointing.tolerable-failed-checkpoints`=`3`;SET `execution.checkpointing.min-pause`=`60000`;--创建Paimon catalogCREATE CATALOG paimon WITH ('type' = 'paimon','metastore' = 'hive','uri' = 'thrift://localhost:9083','warehouse' = 'hdfs://paimon','table.type' = 'EXTERNAL');--创建Partial update结果表CREATE TABLE if not EXISTS paimon.dw.order_detail(`order_id` string,`product_type` string,`plat_name` string,`ref_id` bigint,`start_city_name` string,`end_city_name` string,`create_time` timestamp(3),`update_time` timestamp(3),`dispatch_time` timestamp(3),`decision_time` timestamp(3),`finish_time` timestamp(3),`order_status` int,`binlog_time` bigint,PRIMARY KEY (order_id) NOT ENFORCED)WITH ('bucket' = '20', -- 指定20个bucket'bucket-key' = 'order_id','sequence.field' = 'binlog_time', -- 记录排序字段'changelog-producer' = 'full-compaction', -- 选择 full-compaction ,在compaction后产生完整的changelog'changelog-producer.compaction-interval' = '2 min', -- compaction 间隔时间'merge-engine' = 'partial-update','partial-update.ignore-delete' = 'true' -- 忽略DELETE数据,避免运行报错);INSERT INTO paimon.dw.order_detail-- order_info表提供主要字段SELECTorder_id,product_type,plat_name,ref_id,cast(null as string) as start_city_name,cast(null as string) as end_city_name,create_time,update_time,dispatch_time,decision_time,finish_time,order_status,binlog_timeFROMpaimon.ods.order_info /*+ OPTIONS ('scan.mode'='latest') */union all-- order_address表提供城市字段SELECTorder_id,cast(null as string) as product_type,cast(null as string) as plat_name,cast(null as bigint) as ref_id,start_city_name,end_city_name,cast(null as timestamp(3)) as create_time,cast(null as timestamp(3)) as update_time,cast(null as timestamp(3)) as dispatch_time,cast(null as timestamp(3)) as decision_time,cast(null as timestamp(3)) as finish_time,cast(null as int) as order_status,binlog_timeFROMpaimon.ods.order_address /*+ OPTIONS ('scan.mode'='latest') */;
3.3 AppendOnly 应用
CREATE TABLE if not exists paimon.ods.event_log(.......)PARTITIONED BY (......)WITH ('bucket' = '100','bucket-key' = 'uuid','snapshot.time-retained' = '7 d','write-mode' = 'append-only');INSERT INTO paimon.ods.event_logSELECT.......FROMrealtime_event_kafka_source;
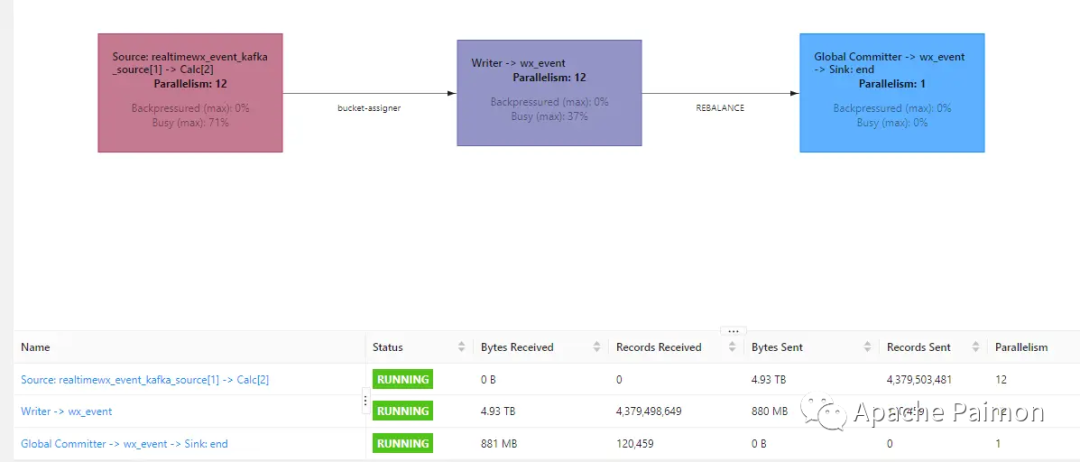
问题发现和解决
@Overridepublic Path getDataTableLocation(Identifier identifier) {try {Table table = client.getTable(identifier.getDatabaseName(), identifier.getObjectName());return new Path(table.getSd().getLocation());} catch (TException e) {throw new RuntimeException("Failed to get table location", e);}}
4.2 大量分区 + Bucket 场景下 Flink 批读超过 Akka 消息限制优化
2023-03-21 15:51:08,996 ERROR akka.remote.EndpointWriter [] - Transient association error (association remains live)akka.remote.OversizedPayloadException: Discarding oversized payload sent to Actor[akka.tcp://flink@hadoop-0xx-xxx:29413/user/rpc/taskmanager_0#1719925448]: max allowed size 10485760 bytes, actual size of encoded class org.apache.flink.runtime.rpc.messages.RemoteRpcInvocation was 1077637236 bytes.
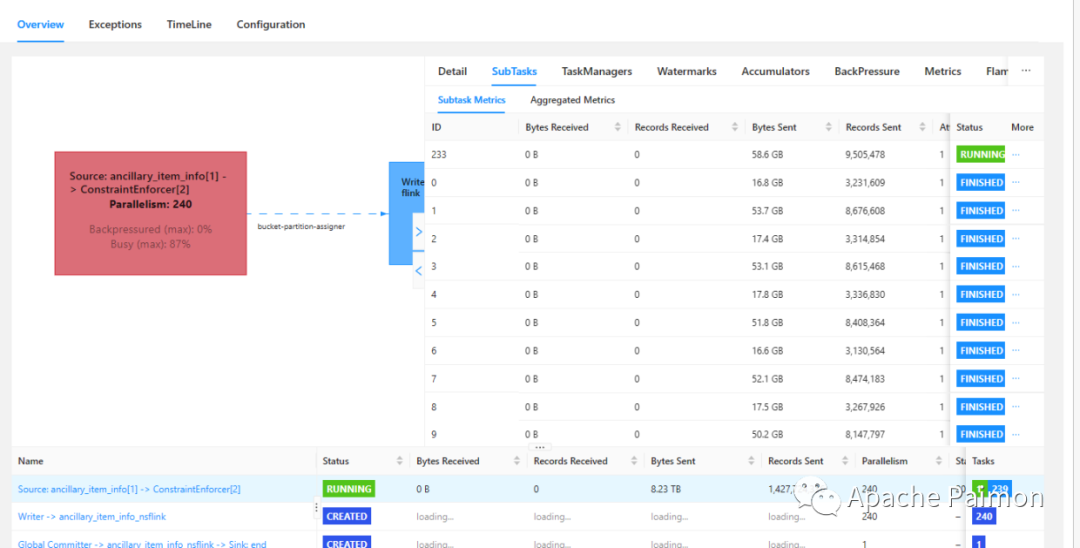
4.3 流读场景下,并行度分配不合理以及基于时间戳读取过期时间报错的问题
未来规划
• 完善 Paimon 平台分析等相关生态
• 基于 Paimon 的流式数仓构建
• 推广 Paimon 在集团内部的应用实践
[1] Apache Paimon 官网:
https://paimon.apache.org/
[2] FLIP-188: Introduce Built-in Dynamic Table Storage :
https://cwiki.apache.org/confluence/display/FLINK/FLIP-188%3A+Introduce+Built-in+Dynamic+Table+Storage

作者简介 PROFILE
吴祥平
同程旅行大数据计算组负责人,对流计算和数据湖技术充满热情,Apache Hudi & Paimon Contributor

曾思杨
同程旅行公共 BI 数据开发,热爱流计算和数据湖技术及其实际应用
往期精选







 点击「阅读原文」,查看更多技术内容
点击「阅读原文」,查看更多技术内容文章转载自Flink 中文社区,如果涉嫌侵权,请发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
