




explain 用法详解
首先看下最常见的explain命令结果集:

id (select唯一标识)
该列表示select的唯一标识,通常执行计划包含的信息 id 由一组数字组成,表示一个查询中各个子查询的执行顺序:
id相同执行顺序由上至下。
id不同,id值越大优先级越高,越先被执行。
id相同和不同都有时,先执行序号大的,先从下而上执行。遇到序号相同时,再从上而下执行。
id为null时表示一个结果集,不需要使用它查询,常出现在包含UNION等查询语句中。
select type (select类型)
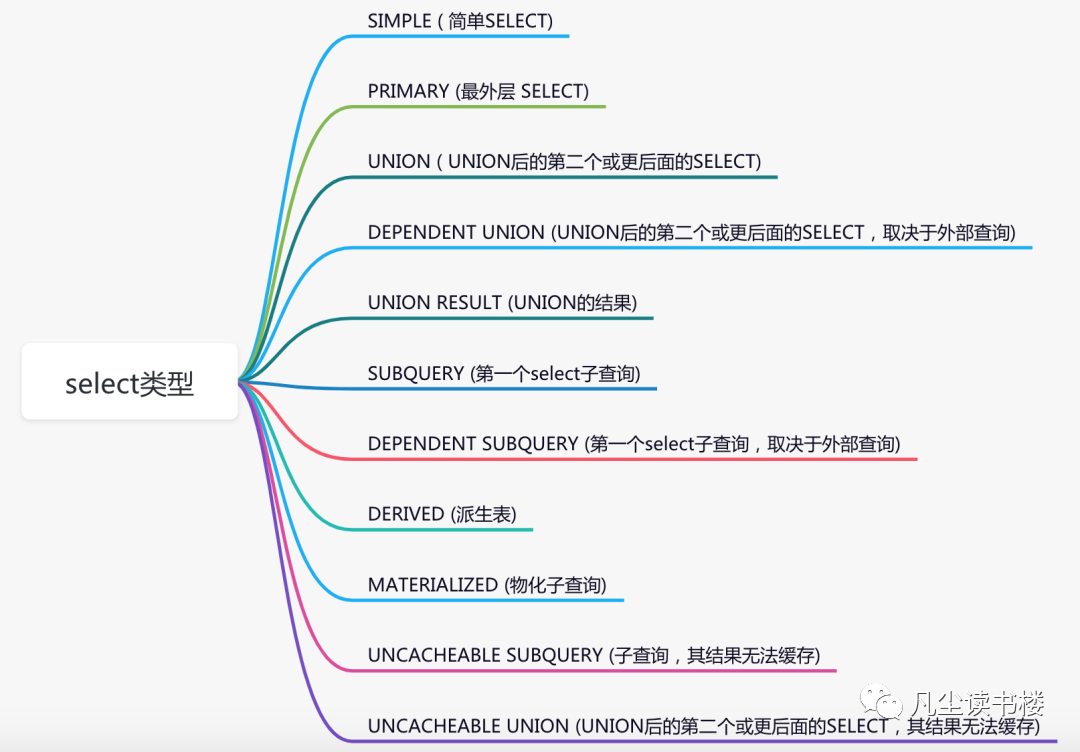
但是常用的其实就是下面几个:
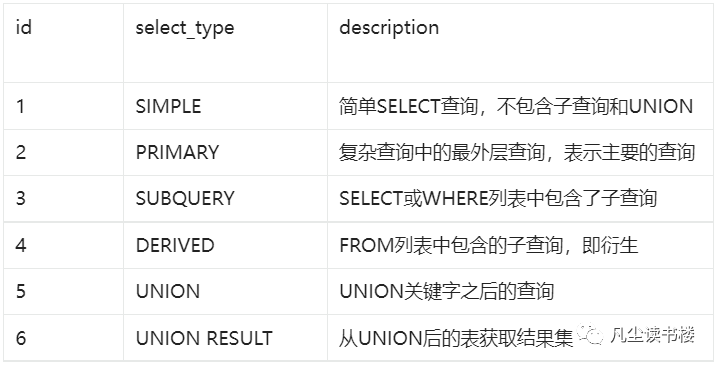
详细说明如下:
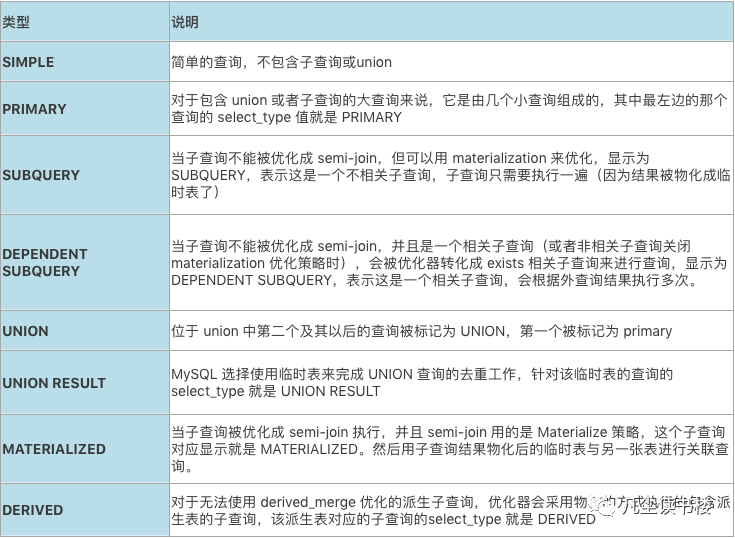
table (表名称)
<unionM,N>:具有和id值的行的M并集N。
<derivedN>:用于与该行的派生表结果id的值N。派生表可能来自(例如)FROM子句中的子查询 。
<subqueryN>:子查询的结果,其id值为N。
partitions (匹配的分区)
type (连接类型)
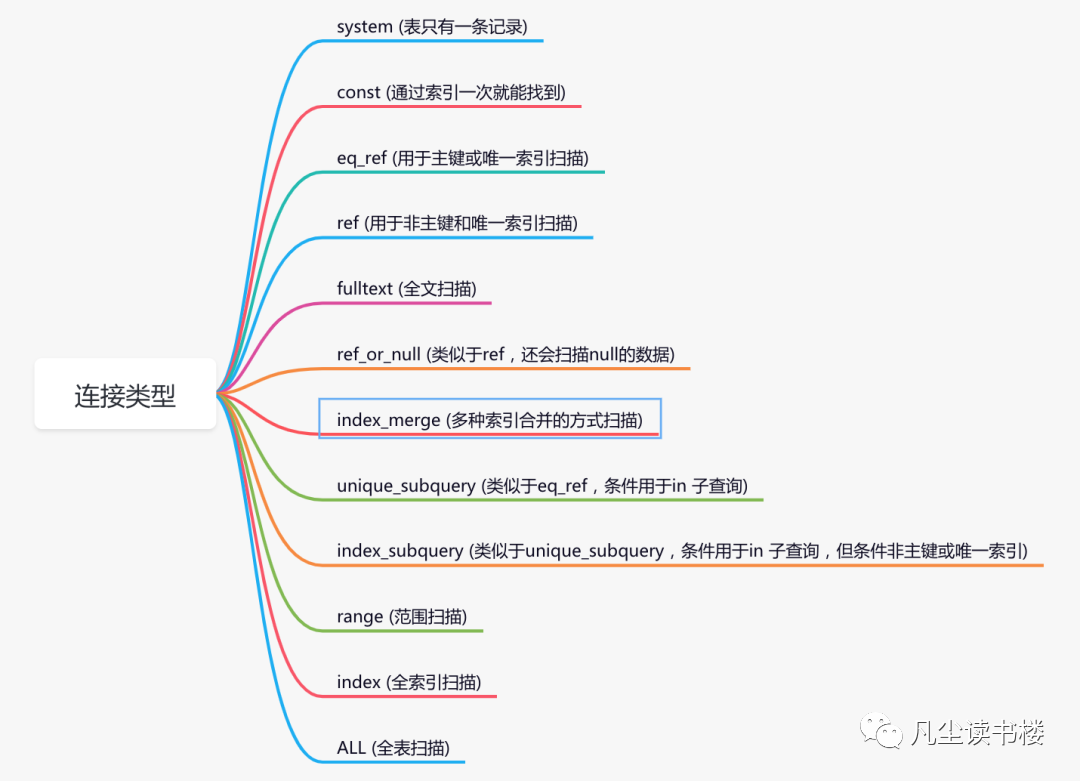

1、const
2、eq_ref
3、ref
4、range
5、index
6、ALL
possible_keys (可能的索引选择)
key (实际用到的索引)
key_len (实际索引长度)
ref (与索引比较的列)
rows (预计要检查的行数)
filtered (按表条件过滤的行百分比)
如果是全表扫描,filtered 值代表满足 where 条件的行数占表总行数的百分比;
如果是使用索引来执行查询,filtered 值代表从索引上取得数据后,满足其他过滤条件的数据行数的占比。
mysql> explain select * from t1 where a<100 and b > 100; +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+------------------------------------+ | id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra | +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+------------------------------------+ | 1 | SIMPLE | t1 | NULL | range | a | a | 5 | NULL | 99 | 33.33 | Using index condition; Using where | +----+-------------+-------+------------+-------+---------------+------+---------+------+------+----------+------------------------------------+
mysql> explain select * from s1 inner join s2 on s1.key1 = s2.key1 where s1.common_field = 'a';
+----+-------------+-------+------------+------+---------------+----------+---------+-------------------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+----------+---------+-------------------+------+----------+-------------+
| 1 | SIMPLE | s1 | NULL | ALL | idx_key1 | NULL | NULL | NULL | 9688 | 10.00 | Using where |
| 1 | SIMPLE | s2 | NULL | ref | idx_key1 | idx_key1 | 303 | xiaohaizi.s1.key1 | 1 | 100.00 | NULL |
+----+-------------+-------+------------+------+---------------+----------+---------+-------------------+------+----------+-------------+
Extra (附加信息)
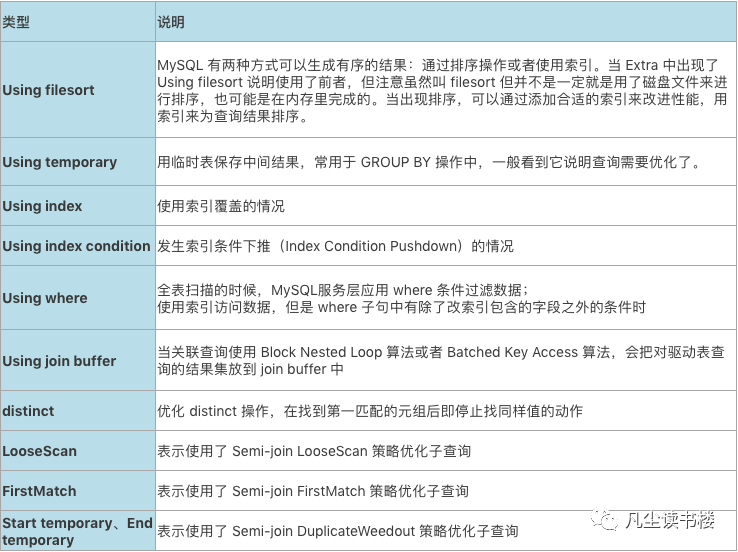
总结

2、最后,如果通过explain命令查看执行计划依然无法优化sql,可以通过show profiling来定位一下到底是哪个环节出现的问题,具体操作可见文章:MySQL优化:profiling和Optimizer Trace
全文完,希望可以帮到正在阅读的你,如果觉得有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
❤ 欢迎关注我的公众号【凡尘读书楼】,一起学习新知识!
————————————————————————————
公众号:凡尘读书楼
墨天轮:https://www.modb.pro/u/399450
知识星球 :凡尘dba人生有限公司
————————————————————————————
最后修改时间:2024-07-07 19:13:30
「喜欢这篇文章,您的关注和赞赏是给作者最好的鼓励」
关注作者
【版权声明】本文为墨天轮用户原创内容,转载时必须标注文章的来源(墨天轮),文章链接,文章作者等基本信息,否则作者和墨天轮有权追究责任。如果您发现墨天轮中有涉嫌抄袭或者侵权的内容,欢迎发送邮件至:contact@modb.pro进行举报,并提供相关证据,一经查实,墨天轮将立刻删除相关内容。
