




本期将分享近期全球知识图谱相关
行业动态、论文推荐

中国科学院天津工业生物技术研究所(简称“天津工业生物所”)生物设计中心平台实验室与亚马逊云科技共同推动生物计算设计领域发展,目前已推出基于图数据库的大肠杆菌调控代谢关系知识图谱ERMer和全流程高通量编辑序列设计云平台AutoESD等20多项生物计算设计工具和软件应用。
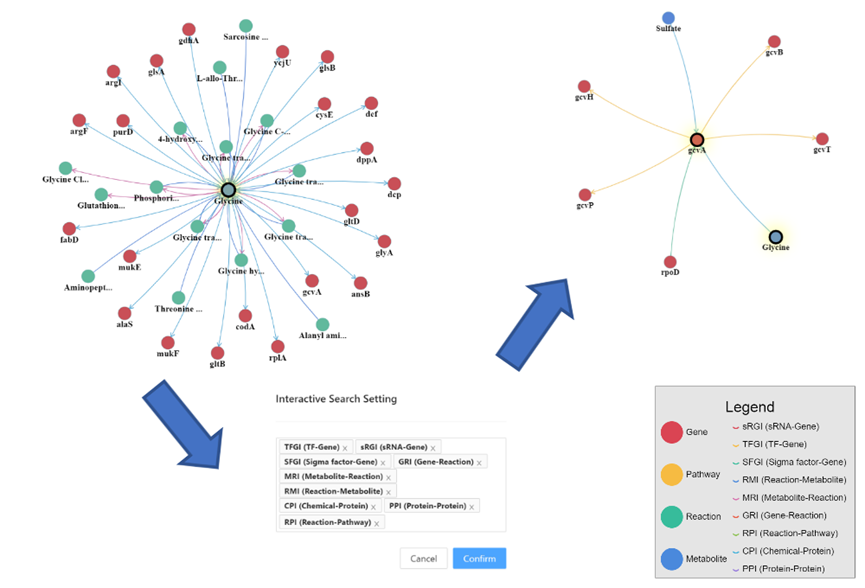
据了解,天津工业生物所生物设计中心团队联合亚马逊云科技团队在计算生物学国际期刊Nucleic Acids Research上发表文章,并发布了全球首个基于图数据库Amazon Neptune的大肠杆菌调控代谢关系知识图谱ERMer,首次提供了全局的代谢调控图谱,并通过可视化框架实现了丰富的搜索功能,如多步查询、最短路径查询等。ERMer采用专门为高度关联的复杂数据集的高效存储和查询设计图数据库架构,这打破了传统的低效数据检索方式,有效增强用户和图谱的人机交互,大大降低了使用门槛。为充分发挥知识图谱的价值,生物设计中心团队还进一步采用基于图神经网络技术进行推理,成功实现了转录因子预测和转录因子靶点预测等功能,这将有助于挖掘潜在的关键调控因子和调控靶点,构建新的调控代谢网络,能够为研究人员提供新的思路和方向。
Kobai推出一款新产品Saturn(土星),旨在将知识图谱的力量应用于已经存储在数据湖仓(Lakehouse)的数据。通过在Snowflake和Databricks的Lakehouse上创建一个语义层,客户可以对这些数据运行SPARQL查询,这为他们提供了一种强大的新方法来收集见解,但避免了全面的图形数据库项目的复杂性。
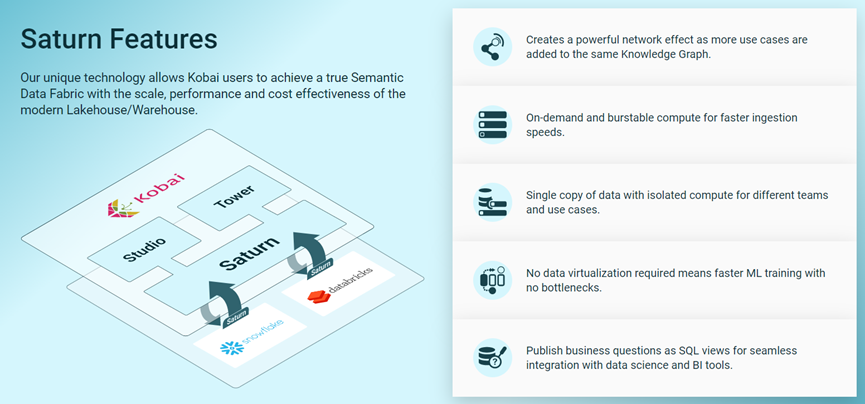
土星基本上是Kobai Studio和Snowflake或Databricks的底层湖屋之间的虚拟化层。该层采用Kobai Studio生成的SPARQL查询,并将其转换为Snowflake和Databricks所期望的SQL代码。然后,土星将查询结果返回给Kobai Studio用户,在那里它以可视化仪表板或以其他方式使用。
数据湖仓还为Kobai客户提供了更低的拥有成本,以及工作负载隔离。如果用户启动了一个密集的图形查询,该查询触及Snowflake或Databricks查询的同一条数据,那么Kobai用户就不必担心这些工作负载冲突时会导致的性能问题。
在第16个世界孤独症关注日到来之际,位于中国科学院合肥创新工程院的星元智能AI团队发布了国内首个孤独症垂类大语言模型Starlight。

星元智能AI团队经过近两年的研究和实验,于2021年发布了一款基于知识图谱的孤独症家庭干预支持公益平台“星星之心”,为家长及行业从业者免费提供包括居家教学、信息查询、供需对接、前沿研究、社区分享等数字化信息支持,上线3个月迅速累积1万多位忠实用户,获得广泛好评。
2023年3月,星元智能AI团队发布国内首个孤独症垂直领域的大语言模型——Starlight。从微信小程序“星小查”的对话机器人功能,发展到基于语言大模型的对话系统,用户可无障碍地向其提问任何有关孤独症谱系障碍的疑问,并得到即时解答。Starlight利用临床研究中产生的信息汇总成庞大的数据库,对约2.5T的诊断样本进行深度学习,辅以监督微调、反馈自助、强化学习等前沿技术,训练出一套高效的NLP算法,用纯attention搭建出transformer语言大模型。该模型具备强大的自然语言处理能力和高质量对话生成能力,可以和用户进行非常流畅的自然语言沟通,同时在扩展性、可部署性和数据安全性上都有很高表现。
ICDE 2023

第39届 IEEE 数据工程国际会议(ICDE 2023)将于2023年4月3日至7日在美国加利福尼亚州阿纳海姆万豪酒店举行。
一年一度的IEEE数据工程国际会议(ICDE)讨论设计、构建、管理和评估高级数据密集型系统和应用程序的研究问题。它是研究人员、从业者、开发人员和用户探索前沿思想和交流技术、工具和经验的领先论坛。
PKUMOD有四篇文章发表:
苏勋斌、林殷年博士:FASI:一个在大图上对FPGA友好的子图同构算法
胡琳博士:GAMMA:一个在大图上进行图挖掘算法的GPU上的处理框架
庞悦博士:IFCA: Index-Free Community-Aware Reachability Processing Over Large Dynamic Graphs
PKUMOD毕业生,湖南大学李友焕副教授:VEND:基于点编码的边存在性判定
本周推荐的是一个集大成的知识图谱构造流水线工具Plumber,其最新的文章Information extraction pipelines for knowledge graphs发表于期刊Knowledge and Information Systems 2023,作者来自德国汉诺威莱布尼茨大学等。

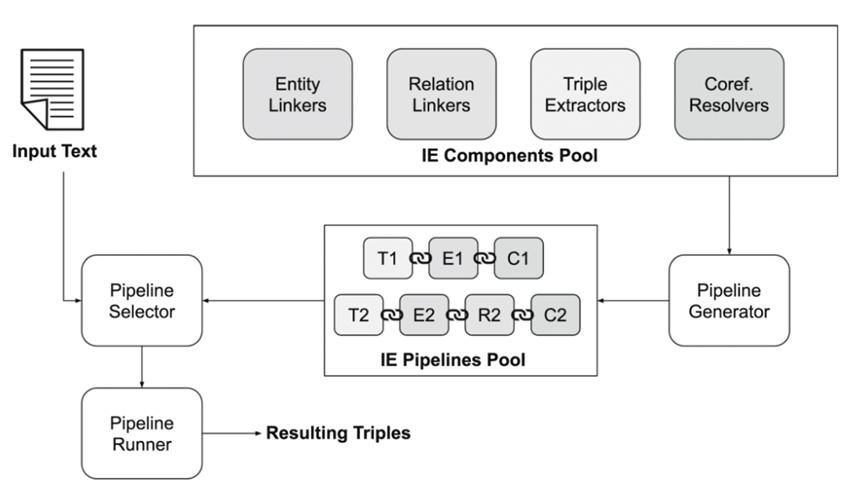
在这个工作中,作者集成了知识图谱构建过程中的信息抽取流水线的多个模块——实体链接、关系链接、三元组抽取、共指消解,引入了多个典型方法,并设计了一个基于Roberta分类的动态流水线选择器,使得对于输入文本,Plumber系统可以自动选择最佳的信息抽取组件进行三元组抽取和知识图谱构建,整体框架如下图所示。
Plumber集成了信息抽取领域的40个经典工作,并基于独立、可复用和可扩展的原则设计了一个信息抽取平台,其用户界面如下图所示。用户既可以手动配置信息抽取的各个环节,也可以受益于平台的流水线选择器进行自动的组件配置,极大的降低了开放信息抽取任务的训练和配置成本。文章也用实验证明了Plumber流水线选择的优势和它在端到端的知识图谱构建任务中的性能。
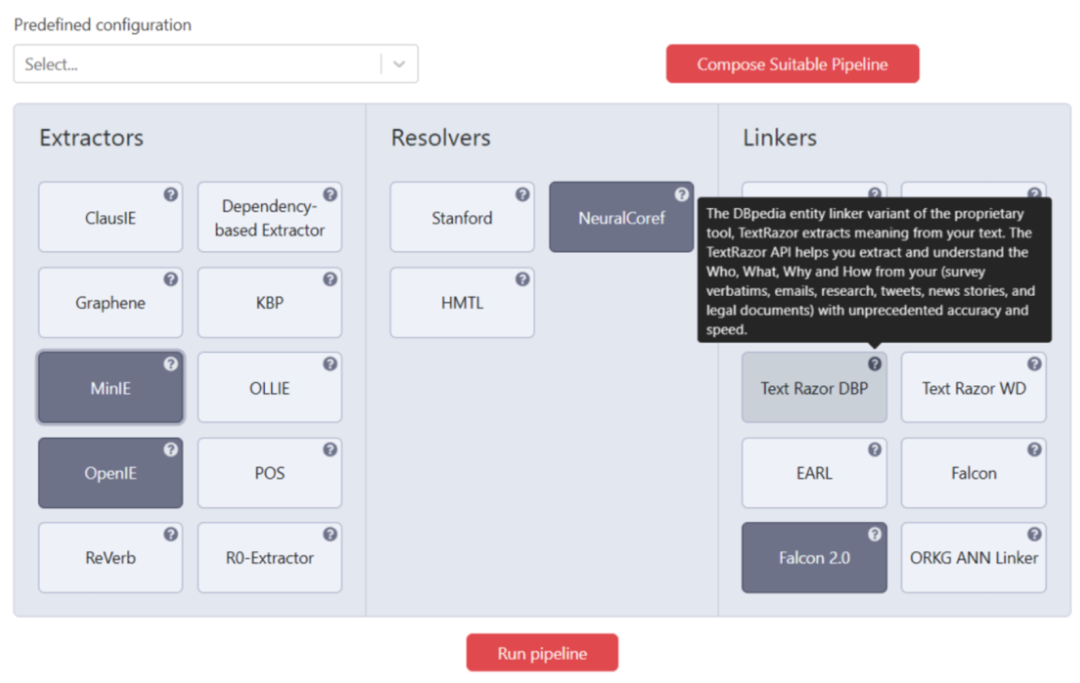
该工作的代码开源https://github.com/YaserJaradeh/ThePlumber,并且配备了一个较为详细的演示视频https://www.youtube.com/watch?v=XC9rJNIUv8g,感兴趣的读者可以前去查看和使用。
更多链接
内容:胡喆媛、代雪佩、薛冰聪、王图图
编辑:王图图
排版:王图图

诚邀您加入我们的gStore社区,我们将在群内解决使用问题,分享最新成果~
请在微信公众号图谱学苑发送“社区”入群~或扫码入群



欢迎关注北京大学王选计算机研究所数据管理实验室微信公众号“图谱学苑“
实验室官网:https://mod.wict.pku.edu.cn/
微信社区群:请回复“社区”获取
gStore官网:http://www.gstore.cn/
GitHub:https://github.com/pkumod/gStore
Gitee:https://gitee.com/PKUMOD/gStore

