




1 Oracle双格式数据库
1.1 数据库单格式存储面临的问题
市面上常见的关系数据库大多采用单一的格式来存储数据,或者采用行存,或者采用列存。采用行存的大多是传统的关系数据库如MySQL,SQL server,postgresql等,一般用来处理OLTP型业务,采用列存的数据库一般和大数据相关,用来处理OLAP业务。
OLTP和OLAP的从来不是完全分离的,许多OLTP数据库上定期或不定期的运行着分析型业务,比如很多系统的月结或者是年结,随着业务的不断发展,数据量越来越大,这些分析型业务的效率也越来越低,很多系统的月结的时间也越来越长,一条sql语句跑十分钟半小时,甚至几个小时都被认为是正常的。数据库里大量的全表扫描对CPU、内存、IO造成了很大的压力,影响到正常的OLTP业务的运行,甚至会导致数据库阻塞或者宕机。
1.2 Oracle的解决方案–双格式存储方案
为了解决OLTP数据库上运行OLAP业务的问题,Oracle提出了双格式存储方案,这种方案的架构通过官方的一张图可以看的很明白
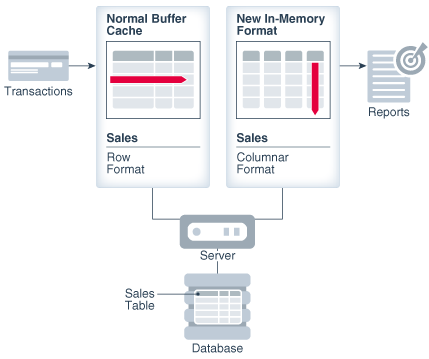
从上面的图上可以看到,表在内存里有两份存储,一份数据是采用行格式存储的,用于事务处理,另一份是采用列格式来存储的,用于报告或者分析。
2 Oracle IM column store简介
Oracle database In-memory和Oracle IM column store是两个不同的概念,Oracle database In-memory是一个特性集,包括IM column store,高级查询优化和可用性方案。IM column store是Oracle database In-memory里面的关键特性。 IM column store以列的格式存储经过压缩的表、分区及单独的列的数据,它不取代原来的基于行的存储(这里是指Oracle 数据库的缓冲区),而是位于另外一个区域(In-memory area),In-memory area是SGA的可选的一个组成部分。 IM column store可以在表空间级、表级或列级激活,可以将一部分表、一部分列或者是一部分分区放置到IM column store中。IM column store按列而不是按行存储数据。3 Oracle IM column store架构
3.1 列存和行存
列存和行存的区别可以从官网的这张图里看出来
3.2 In-memory area
IM column store的内存区域IIn-memory area 是SGA的一个可选的组成部分,它的大小由数据库实例初始化参数INMEMORY_SIZE决定,这个参数的默认值是0,这意味着列存在缺省的情况下是关闭的。首次将这个参数设置为非零值即激活列存需要重启数据库实例.激活之后,这个内存区域的大小可以才sga信息里看到,下面是数据库启动后显示的列存信息在12.2 之后激活之后可以动态增加列存的大小,但是不可以减小它的值。 In-memory area 分为列数据池和元数据池,如下图所示:ORACLE instance started. Total System Global Area 3707763120 bytes Fixed Size 8903088 bytes Variable Size 654311424 bytes Database Buffers 2617245696 bytes Redo Buffers 7872512 bytes In-Memory Area 419430400 bytes Database mounted. Database opened.
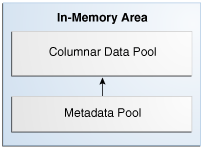
In-memory area这两个池的大小由Oracle数据库自动决定,不能人工设定或者干涉。通过视图V$INMEMORY_AREA可以查询这两个池的大小和使用情况’
SELECT POOL, TRUNC(ALLOC_BYTES/(1024*1024*1024),2) "ALLOC_GB",TRUNC(USED_BYTES/(1024*1024*1024),2) "USED_GB",POPULATE_STATUS FROM V$INMEMORY_AREA;
POOL ALLOC_GB USED_GB POPULATE_STATUS
--------- ---------- ---------- ---------------
1MB POOL .26 0 DONE
64KB POOL .1 0 DONE
3.3In-Memory存储单元
与缓冲池使用数据块存放数据不同,IM列存并使用数据块存放数据,而是使用优化的存储单元存放数据和元数据。列存使用的存储单元可以从下面的图中看到,从下面的图里,也可以看到Oracle进程和In-Memory 区域的交互。
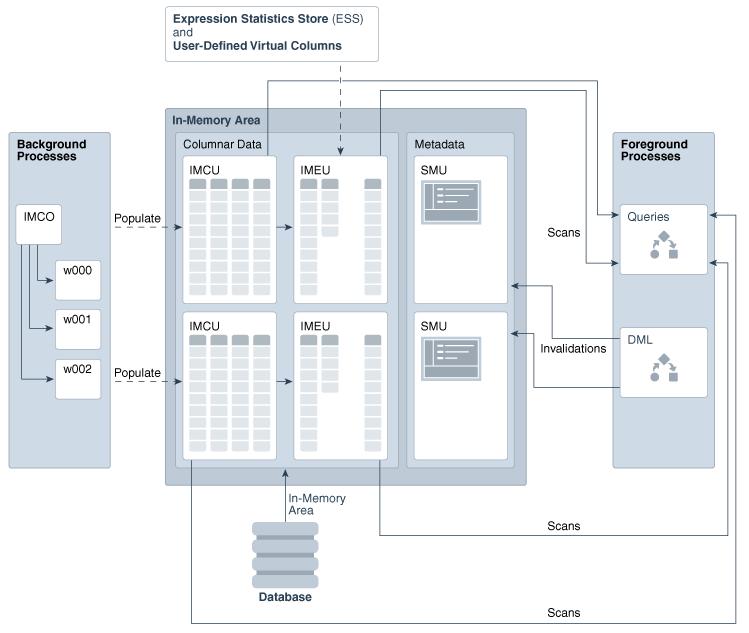
从上面的图中可以看到,一共有三个类型的存储单元,IMCU和IMEU用于存储列数据,SMU用来存储元数据。
IMCU,IM 压缩单元,和表空间的扩展(extent)类似,存储是经过压缩的只读的一列或者是多列数据,一个IMCU只能存储一个对象的数据库,这个对象可以是表,分区或者是物化视图。表的列和IMCU的关系在下面的图里一目了然
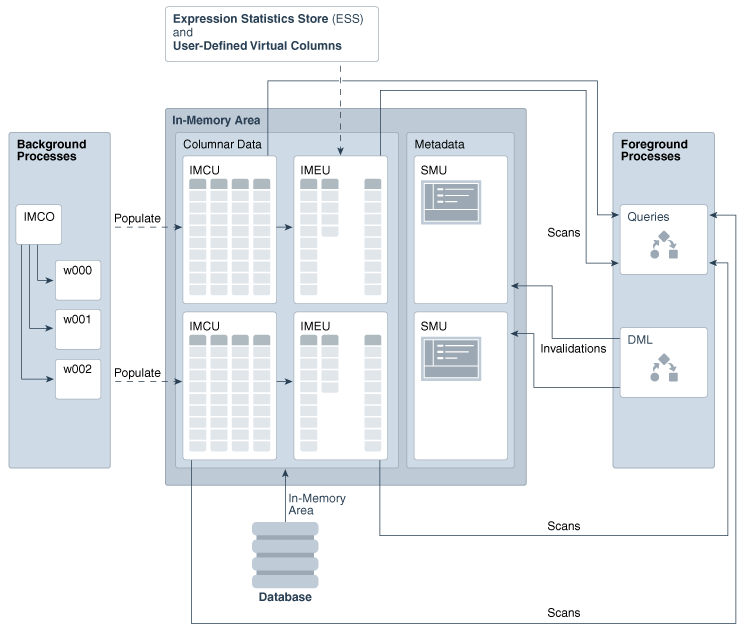
IMEU(In-Memory Expression Unit) IM表达式单元,IMEU里存储的物化的表达式和用户定义的虚拟列。从概念上讲,IMEU是它的上级IMCU的逻辑扩展。每一个IMEU映射到也只能映射到一个IMCU。
SMU( Snapshot Metadata Unit) 快照元数据单元包含相关IMCU的元数据和事务信息。每一个IMCU映射到一个单独的SMU,因此它们是一一对应的关系。
4 使用列存提高数据库全表扫描的效率
4.1 激活IM 列存储
IM 列存储是否激活由实例配置参数inmemory_size,当inmemory_size的参数是 大于0的值时,列存是激活的,否则,列存就是关闭的。在默认的情况下,这个参数的值是0。将这个参数由默认值改为大于0的值需要重新启动实例。
--显示inmomery_size的当前值
show parameter inmemory_size
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
inmemory_size big integer 0
--设置inmemory_size来激活im列存储
alter system set inmemory_size=400m scope=spfile;
--重启数据库实例
shutdown immediate;
Database closed.
Database dismounted.
ORACLE instance shut down.
startup;
ORACLE instance started.
Total System Global Area 3707763120 bytes
Fixed Size 8903088 bytes
Variable Size 654311424 bytes
Database Buffers 2617245696 bytes
Redo Buffers 7872512 bytes
In-Memory Area 419430400 bytes
Database mounted.
Database opened.
--实例重启后,SGA 中多了一个In-Memory Area,大小是400MB。
show parameter inmemory_size
NAME TYPE VALUE
------------------------------------ ----------- ------------------------------
inmemory_size big integer 400M
--查看inmemory_size的当前值,也是400M,inmemory_size设为大于0的值之后,就可以
--inmemory_size可以动态增加大小了,减少它的大小则需要重启数据库实例。
4.2 配置表使用列存
表默认是不启用列存的,要想使表使用列存,可以在创建表时加上inmemory选项,也可以在表创建后用alter语句给表设置inmemory。先看一下表在没有启用列存时的执行计划。
explain plan for select * from EMP;
Explained.
select * from table(dbms_xplan.display());
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 3956160932
--------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000K| 71M| 4957 (1)| 00:00:01 |
| 1 | TABLE ACCESS FULL| EMP | 1000K| 71M| 4957 (1)| 00:00:01 |
--------------------------------------------------------------------------
8 rows selected.
使用alter语句给表emp启动列存
alter table emp inmemory;
列存启用之后,在看一下语句的执行计划
explain plan for select * from EMP;
Explained.
select * from table(dbms_xplan.display());
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 3956160932
-----------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1000K| 71M| 4957 (1)| 00:00:01 |
| 1 | TABLE ACCESS INMEMORY FULL| EMP | 1000K| 71M| 4957 (1)| 00:00:01 |
-----------------------------------------------------------------------------------
8 rows selected.
执行计划使用了TABLE ACCESS INMEMORY FULL,可以它的扫描的行数、字节数和成本同未启用列存的全表扫描时完全相同。这是因为emp虽然启用了列存,表的数据还没有装入到列存中。
4.3 将表载入列存
为表启用IM 列存后,表的数据并不立即载入列存内。因此,上面显示的执行计划虽然在全表扫描时使用了列存,操作显示的成本和未使用列存的全表扫描时相同。启动列存后,如果有对表进行全表扫描的操作,表的数据会载入的列存。比如运行
select * from emp
就会将emp表的数据载入到列存中。也可以运行下面的命令,将表的数据手动载入到列存中。在数据库重启启动后,重启前已载入列存的表也不会重新载入到列存中
EXEC DBMS_INMEMORY.POPULATE('TEST', 'EMP');
查询视图v$im_segments可以发现现在已在列存中的表分段
SQL> select SEGMENT_NAME,INMEMORY_SIZE,POPULATE_STATUS from v$im_segments where SEGMENT_NAME='EMP';
SEGMENT_NAME INMEMORY_SIZE POPULATE_STAT
-------------------------------- ------------- -------------
EMP 46596096 COMPLETED
4.4 表数据载入到列存后的执行计划
SQL> explain plan for select count(*) from emp;
Explained.
SQL> select * from table(dbms_xplan.display());
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 2083865914
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 185 (1)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS INMEMORY FULL| EMP | 1000K| 185 (1)| 00:00:01 |
----------------------------------------------------------------------------
9 rows selected.
全表扫描的成本同之前相比,由4957降到了185。可以看出来,列存执行全表扫描的效率非常高。再看一下实际执行计划的对比
Plan hash value: 2083865914
----------------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
----------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 185 (1)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS INMEMORY FULL| EMP | 1000K| 185 (1)| 00:00:01 |
----------------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
2 consistent gets
0 physical reads
0 redo size
550 bytes sent via SQL*Net to client
386 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
SQL> /
COUNT(*)
----------
1000000
Execution Plan
----------------------------------------------------------
Plan hash value: 2083865914
-------------------------------------------------------------------
| Id | Operation | Name | Rows | Cost (%CPU)| Time |
-------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 4954 (1)| 00:00:01 |
| 1 | SORT AGGREGATE | | 1 | | |
| 2 | TABLE ACCESS FULL| EMP | 1000K| 4954 (1)| 00:00:01 |
-------------------------------------------------------------------
Statistics
----------------------------------------------------------
0 recursive calls
0 db block gets
18267 consistent gets
0 physical reads
0 redo size
550 bytes sent via SQL*Net to client
386 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
在执行列存的全表扫描的情况下,一致读才2个,比起普通的全表扫描的18267个逻辑读来说,对性能的提升非常大
4.5 列存和数据库缓存的关系
列存对数据库缓冲区和数据文件里的数据没有任何影响,也不会影响undo数据和redo日志的记录,DML操作也不会应为开启列存而有所改变。Oracle数据库使用内部机制跟踪列和行的变化,确保列存中的数据同存在其它地方的数据保持一致,查询列存返回的数据和查询数据库缓冲区返回的数据是一致的。
表启动列存,数据载入到列存后,Oracle优化器将列存操作列入可选的访问路径中,根据计算的成本决定是否选择列存操作,比如下面的update语句,仍然执行范围扫描
SQL> explain plan for update emp set sal=2500 where empno=101;
Explained.
SQL> select * from table(dbms_xplan.display());
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
Plan hash value: 169504908
--------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
--------------------------------------------------------------------------------
| 0 | UPDATE STATEMENT | | 1 | 8 | 4 (0)| 00:00:01 |
| 1 | UPDATE | EMP | | | | |
|* 2 | INDEX RANGE SCAN| IDX_EMP_NO | 1 | 8 | 3 (0)| 00:00:01 |
--------------------------------------------------------------------------------
Predicate Information (identified by operation id):
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------
---------------------------------------------------
2 - access("EMPNO"=101)
14 rows selected.
如果更新的数据较多,就会选择列存操作
SQL> select * from table(dbms_xplan.display());
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 1494045816
------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
------------------------------------------------------------------------------------
| 0 | UPDATE STATEMENT | | 10066 | 70462 | 191 (4)| 00:00:01 |
| 1 | UPDATE | EMP | | | | |
|* 2 | TABLE ACCESS INMEMORY FULL| EMP | 10066 | 70462 | 191 (4)| 00:00:01 |
------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
---------------------------------------------------
2 - inmemory("EMPNO"=70)
filter("EMPNO"=70)
15 rows selected.
4.6利用列存优化hash连接
hash连接是大数据连接的常用方式,这种方式效率比嵌套连接高得多。但是,仍然要对表做全表扫描,往往是数据库中的cpu消耗大户。对hash连接的表使用列存后,可以大幅度提高扫描效率,降低CPU消耗,对IO和存储的占用也会大幅度降低。看一下下面语句的执行计划会有一个直观的感受
SQL> explain plan for select a.empno, b.ename from emp a inner join emp_par b on a.empno=b.empno;
Explained.
SQL> select * from table(dbms_xplan.display());
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Plan hash value: 872441646
--------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
--------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 43 | 192 (4)| 00:00:01 | | |
|* 1 | HASH JOIN | | 1 | 43 | 192 (4)| 00:00:01 | | |
| 2 | JOIN FILTER CREATE | :BF0000 | 1 | 40 | 2 (0)| 00:00:01 | | |
| 3 | PARTITION HASH ALL | | 1 | 40 | 2 (0)| 00:00:01 | 1 | 4 |
| 4 | TABLE ACCESS FULL | EMP_PAR | 1 | 40 | 2 (0)| 00:00:01 | 1 | 4 |
| 5 | JOIN FILTER USE | :BF0000 | 1000K| 2929K| 187 (2)| 00:00:01 | | |
PLAN_TABLE_OUTPUT
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
|* 6 | TABLE ACCESS INMEMORY FULL| EMP | 1000K| 2929K| 187 (2)| 00:00:01 | | |
--------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
1 - access("A"."EMPNO"="B"."EMPNO")
6 - inmemory(SYS_OP_BLOOM_FILTER(:BF0000,"A"."EMPNO"))
filter(SYS_OP_BLOOM_FILTER(:BF0000,"A"."EMPNO"))
hash连接时,优化器根据访问路径的成本选择了列存全表扫描,不但CPU的成本降低了,扫描的数据也从71M降低到了2.929M。
