




本年业界盛会DTC『数据技术嘉年华』将于明天4月7日在北京新云南皇冠假日酒店举办。还没有报名的小伙伴还有机会。文后有免费方式。这是我给大家福利。
朝花夕拾系列MySQL 8.0 组复制,每天更新一篇欢迎大家订阅。MogDB 学习记录也在持续更新。 欢迎大家订阅。谢谢大家的持续关注与支持。
本个月DB-Engines 上榜414个产品,比上个月增加四个产品。这个月DB-Engines很奇怪,前六名都在跌,有点像A股最近的状态。Oracle更是领跌33.01分。MySQL跌25分,第1五名,MongoDB 跌了16.89。这种情况前所未有。IBM Db2 以涨2.57分位于全镑涨幅第一。不知道应该哭还是笑。
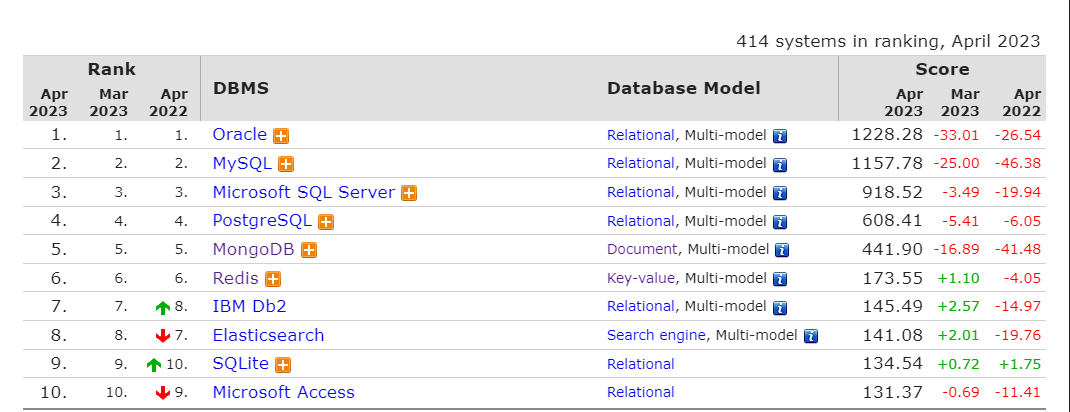
本月11到20排名上年度数据库Snowflake与大数据Cassandra发生了再次互换,这次相差0.69分,下个月极有可能再次反转。Snowflake本月出现下降的情况,这也是最近一段时间的第二次次下跌。这次下跌幅度不小3.27分。Microsoft Azure SQL Database本月增加1.62。总分79.06,本月上升一位,来到第十五位。Google BigQuery 上升一位,首次进入前二十名。其它无变化。
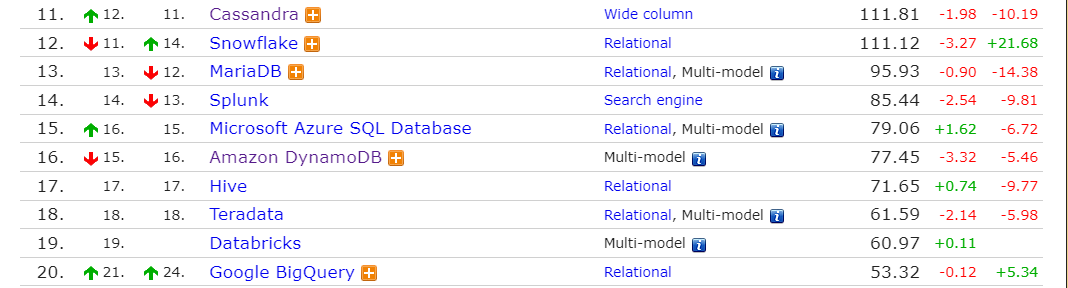
21到50之间, SAP HANA,Couchbase,Informix,Spark SQL,Firebase Realtime Database,Presto,分别上升一位。其它对应下降一位。
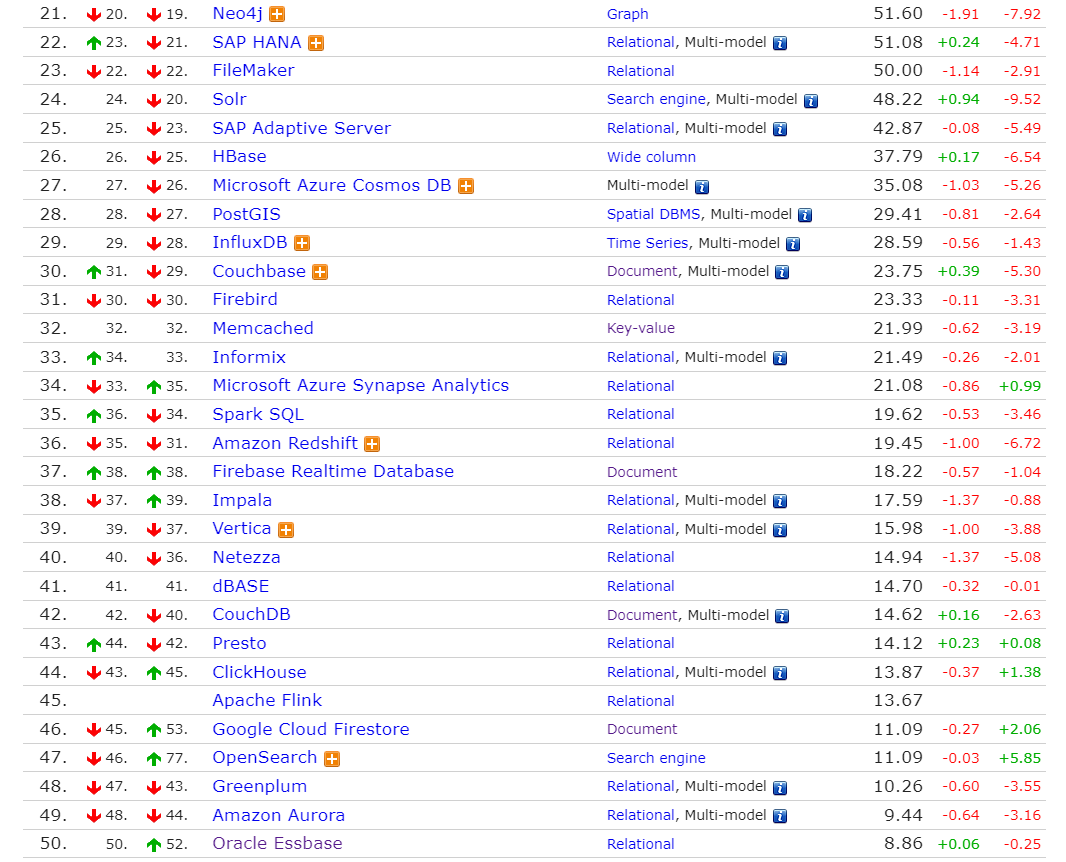
说一说Spark SQL,Spark SQL是Apache Spark核心的上层组件,是为Apache Spark 结构化数据。 Apache Spark 是用于大规模数据处理的统一分析引擎。它提供了 Java、Scala、Python 和 R 的高级 API,以及支持通用执行图的优化引擎。它还支持一组丰富的高级工具,包括用于 SQL 和结构化数据处理的Spark SQL 、用于pandas 工作负载的Spark 上的 pandas API 、用于机器学习的MLlib 、用于图形处理的GraphX以及用于增量计算和流处理的Structured Streaming。有对Spark 感兴趣的同学,可以参考https://spark.apache.org/docs/latest/
各位下个月见。
DB-Engines Ranking的分数计算方法
DB-Engines Ranking 是一个数据库管理系统列表,按其当前受欢迎程度进行排名。我们使用以下参数来衡量系统的受欢迎程度:
网站上系统的提及次数,以搜索引擎查询中的结果数来衡量。目前,我们使用Google和Bing进行此测量。为了只计算相关结果,我们搜索 以及术语数据库,例如“Oracle”和“database”。对系统的普遍兴趣。 对于此测量,我们使用Google 趋势中的搜索频率。
关于系统的技术讨论频率。 我们使用著名的 IT 相关问答网站Stack Overflow和DBA Stack Exchange上相关问题的数量和感兴趣的用户数量。工作机会的数量,其中提到了系统。 我们使用领先的工作搜索引擎Indeed和Simply Hired上的报价数量。
专业网络中的配置文件数量,其中提到了系统。 我们使用国际上最流行的专业网络LinkedIn。
社交网络中的相关性。我们计算了Twitter推文的数量,其中提到了该系统。
我们通过对各个参数进行标准化和平均来计算系统的流行度值。这些数学变换以某种方式进行,以便保留各个系统的距离。这意味着,当系统 A 在 DB-Engines Ranking 中的值是系统 B 的两倍时,那么在单个评估标准上进行平均时,它的受欢迎程度是两倍。为了消除数据源本身数量变化带来的影响,流行度分数始终是一个相对值,只能与其他系统进行比较来解释。
DB-Engines 排名不衡量系统的安装数量,或它们在 IT 系统中的使用。可以预期,由 DB-Engines 排名衡量的系统受欢迎程度的增加(例如在讨论或工作机会中)在系统的相应广泛使用之前某个时间因素。因此,DB-Engines Ranking 可以作为早期指标。
