




点击蓝字 关注我们

摘要
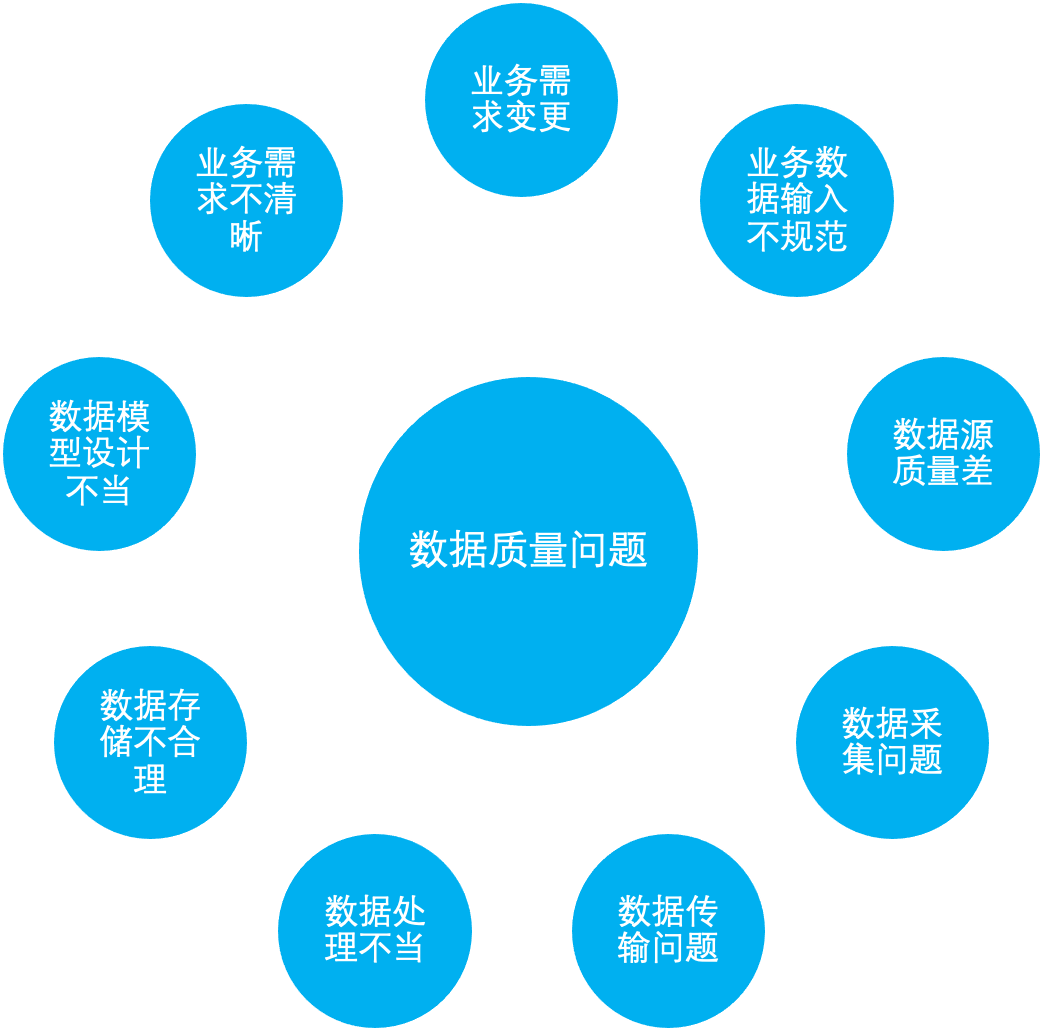
做数据的同学经常会遇到的一种情况是:业务同学经常说我们做的报表看起来数据不准确,有什么办法改善吗?这就是今天我们要聊的常见数据质量管理的一种常见情况。
为什么要做数据质量管理
数据可信度低 影响数据分析和数据挖掘的准确性 可能会导致错误的决策 数据开发层面的工作越来越多,链路也越来越长,如果没有在一些关键的节点配置好相应的检查,一旦出现数据错误的问题就比较难定位。

“
数据及时性
“
数据完整性
“
数据准确性
“
数据一致性
如何做好数据质量管理
“
事前制定规范
大部分数据质量问题是因为没有遵循数据开发规范导致。我们可以根据数据质量特性制定相关开发规范并在事前进行约定遵守。
数据模型规范:
数据结构清晰、分层明确-层级依赖(星型建模或维度建模)等。元数据规范:
字段描述、字段类型-长度-取值范围、枚举范围、主键唯一等。命名规范:
表、字段名称,项目名称,文件名称、函数名称、编码规范等。安全规范:
隐私字段脱敏、权限层级管控等。
“
事中数据质量监控(验证)
利用系统定义的各种校验规则对业务表、字段进行多角度的数据质量监控,对关键业务数据的质量情况进行全方位把握,大体包含以下几种:
唯一值监控:监控某个字段值是否唯一,例如 ID,如果唯一值字段出现重复数据,则代表数据质量异常。 空值监控:某个字段必须有值,例如付款记录中的金额。此规则监控此类字段是否为空,为空则判断异常。 指标波动监控:某个指标例如 GMV,如果当天指标比昨天暴涨 10 倍,大概率为异常。 取值范围监控:例如年龄字段,值是否超过常规范围。枚举字段,值是否超过定义范围。 记录数量波动监控:如果当前表日均增加 1W 条记录,某天新增超过 2W 条,大概率出现异常。 数据规范校验:字段格式规范(例如时间字段是否按照指定格式)
对上述监控规则中,出现异常的任务进行告警至责任人。包括但不限于:邮件、Slack、微信、钉钉等方式。
责任人接收到异常告警后,及时对数据任务进行排查以及修复,同时对当前异常进行记录用于后续整改。
“
事后监督
如何做好数据质量验证
“
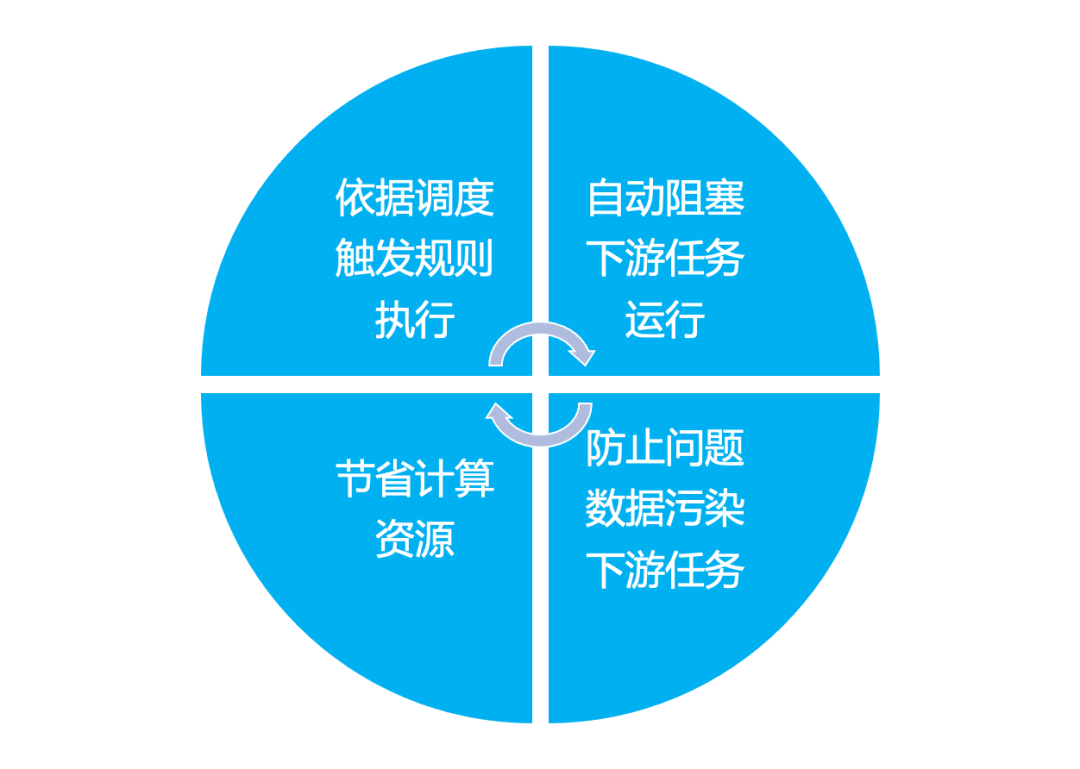
3.1、基于调度系统去做数据质量检查的优势
“
3.2 为什么基于 Apache DolphinScheduler 来做?
高可靠性,去中心化的多 Master 和多 Worker 架构设计, 可以避免单 Master 压力过大,另外采用任务缓冲队列来避免任务过载 简单易用,所有流程定义都是可视化,通过拖拽任务可完成工作流创建,也可通过 API 或 PyDolphinScheduler 这种 Python 方式或 YAML 创建或与第三方系统集成, 一键部署 具有丰富的应用场景,支持多租户,支持暂停恢复操作. 紧密贴合大数据生态,提供 Spark, Hive, M/R, Python, Sub_process, Shell 等 20+ 种任务类型 高扩展性,支持自定义任务类型,调度器使用分布式调度,调度能力随集群线性增长,Master 和 Worker 支持动态上下线 高性能,调度能力通常是同类开源调度系统的 N 倍以上
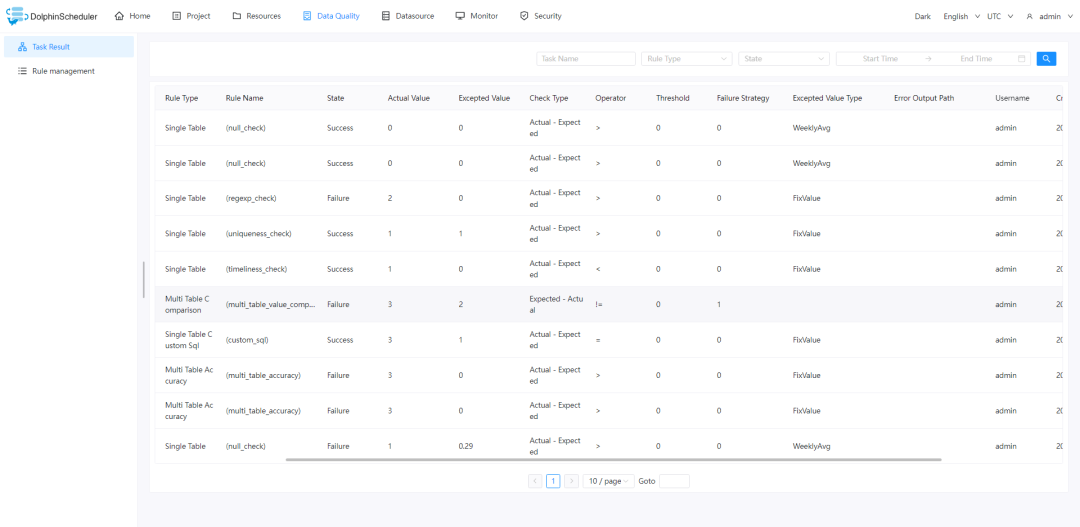
具备丰富的内置规则,能够满足我们日常的各种检查需求 能够无缝地接入到工作流当中,当出现严重数据错误问题时能及时进行告警和阻断 有较为完善的结果处理机制 能够查看数据检查结果和错误数据,方便排查问题
Apache Griffin: Apache 顶级项目,是一个优秀并且完备的数据质量检查系统, 具有独立的UI、调度和内置规则,依赖于 Apache Livy 来提交 Spark 作业 一个独立的系统,较难无缝地接入到工作流当中来实现当出现严重数据质量问题时的阻断。 Qualitis: 微众开源的数据质量系统,具备较丰富的内置规则,界面简洁容易使用 依赖于 Linkis 作为执行 Spark 作业的引擎 如果想要实现无缝接入工作流需要依赖 DataSphere Studio,有点儿重 Great Expectations 可能不少同学对 Great Expectations 比较陌生,但在数据科学领域 great_expectations 是一个不错的框架 Python 编写,目前最新版本为 0.15
DolphinScheduler 作 为一个任务调度系统,具备了执行任务的基础,不需要引入新的组件来提交任务 数据质量检查可以作为一种任务类型无缝接入到工作流当中 无需新增其他服务来增加运维的难度 可以很好地与社区共建开源
数据质量监控的设计和实现
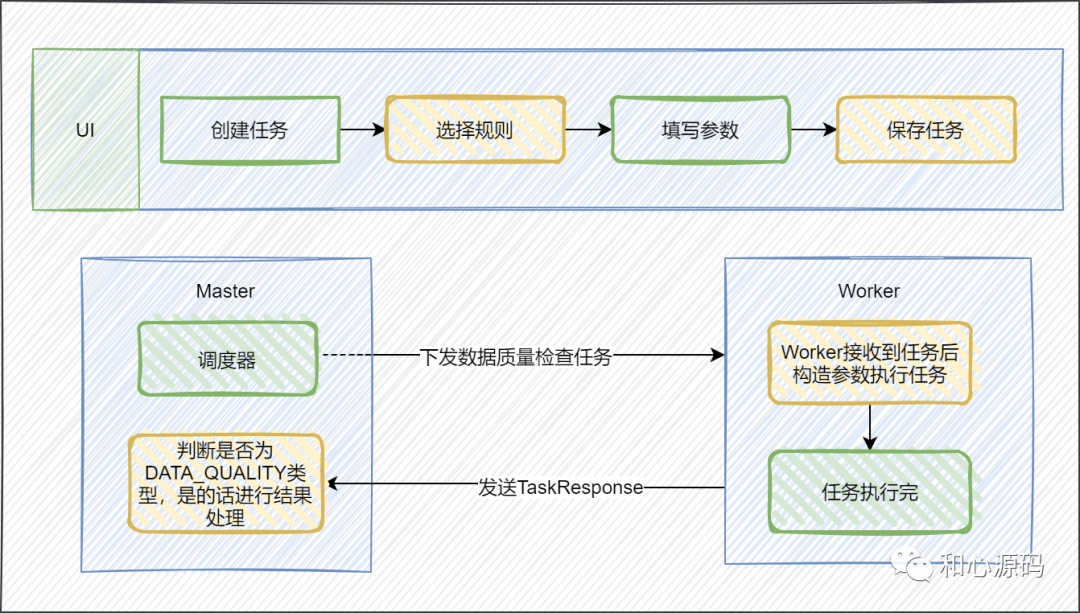
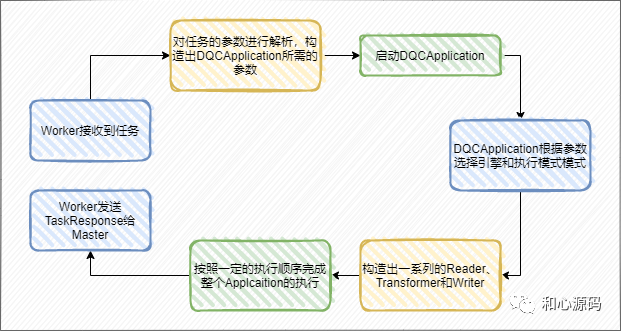
数据质量任务开始执行,由 Master 下发任务到 Worker ,Master 是DolphinScheduler中的调度工作流和任务的组件,Worker 是DolphinSchduler中负责实际执行任务的组件。 Worker 接收到任务以后会进行参数的解析和构造,执行 DQCApplicaiton,DQCApplicaiton 执行完成后会将结果写入到相应的存储引擎,当前数据质量任务结果存储在 t_ds_dq_execute_result 表中, Worker 会发送 TaskResponse 给 Master。 Master 接收到 TaskResponse 后会对任务类型进行判断,如果是数据质量检查任务的话会进行数据质量结果判断,一旦发现数据异常就会进行告警或者阻断。
规则管理:规则定义以及规则的使用 数据处理:Worker 将规则定义转化为 DQCAppliccation 所需的参数以及 DQCApplicaiton 执行数据处理 结果处理:结果检查以及异常后的处理
“
4.1 规则管理
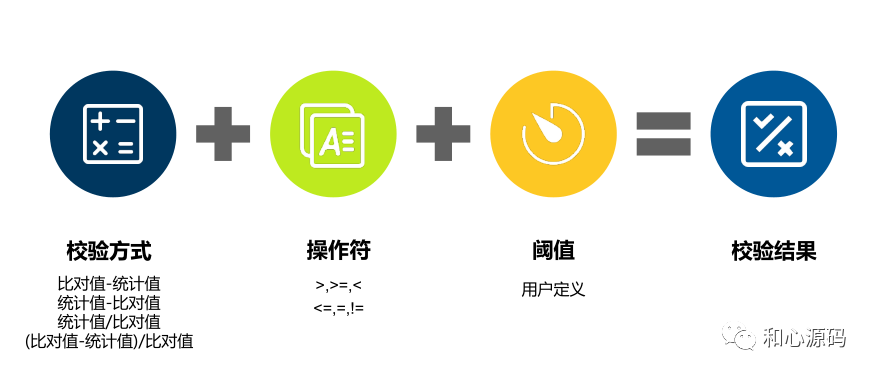
参数输入项:在数据质量检查规则中核心的输入项包括: 统计值指的是我们对要检验的数据执行一系列操作后得到的值,例如表总行数或者为某字段为空的行数。 比对值指的是用来作为比较目标的值,比对值可以是固定值,也可以是由定义好的计算逻辑计算出来的值 数据源输入项,定义了要检查哪些数据 统计值参数和比对值参数 结果判断相关的参数,包括检查的方式、比较符和阈值以及失败,这部分的参数主要是用来定义怎样判断数据是否异常和异常如何处理。 SQL 定义:需要定义 SQL 来计算得到统计值、比对值以及获取错误数据
后续新增规则不希望频繁修改前端页面 保证用户良好的体验包括输入项的联动比如数据源、表和列的选择联动等等。
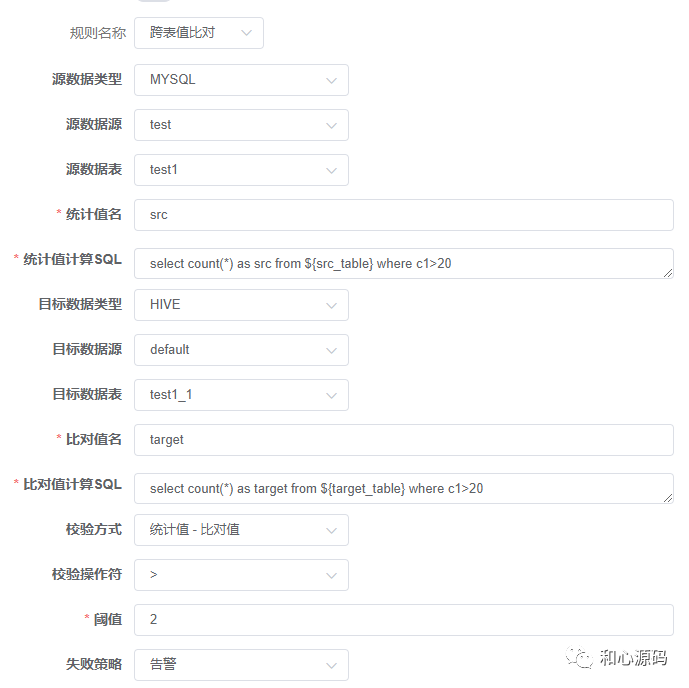
唯一性指的是检查哪些数据是重复数据或者数据的哪些属性是重复的,对应的规则例如主键唯一性检查。 规范性指的是检查数据是否符合规范,是否按照规定的格式存储,对应的规则包括正则表达式检查,字段长度检查,枚举集合检查,数值范围等。 自定义指的是用户可以通过自定义 SQL 的方式来定义要检查的逻辑,支持的规则包括单表自定义 SQL 和跨表值比对。
固定值 最近 7 天波动 最近 30 天波动 日波动 周波动 月波动 源表总行数 目标表总行数
execute_sql:该 sql 是用来计算出比对值 output_table_name:将 execute_sql 执行的结果注册到临时视图所用的表名 comparison_name:是比对值的名称,结合 output_table_name 可用于其他 SQL 中
“
4.2 数据处理
执行引擎:我们选择了 Spark 作为任务的执行引擎。Spark 支持多种数据源类型的连接同时计算比较快。 执行链路组件:我们设计了 Reader、Transformer 和 Writer 三种类型的组件, Reader 用于连接数据源,Transformer 用于执行 sql 进行数据的处理,Writer 用于将数据输出到指定的存储引擎中
DolphinScheduler Worker 接收到任务以后,会将规则的参数输入项和 SQL 定义转换成 DQCApplication 所需要的参数传给 DQCApplication 去执行 DQCApplication 解析参数选择相应的引擎,构造出引擎对应的 RuntimeEnviroment 和 Execution 同时也会根据参数创建一系列的 Reader、Transformer 和 Writer , Execution 会按照一定的顺序去执行这些组件中的逻辑,来完成整个数据质量校验任务

告警,告警等级是当检查结果为异常时会进行告警,但不会将任务结果设置为 false,不导致整个工作流的阻断。 阻断:当检查结果为异常时,首先是进行告警,同时会将任务的结构设置为 false,对整个工作流进行阻断。
数据质量管理的评价体系
☆ 考量数据项信息是否全面、完整、无缺失
★ 指标公式:表完整性和字段完整性的平均值
☆ 确保数据遵循统一的数据标准或规范要求
★ 指标公式:已监控作业个数/作业总个数
☆ 通过日常管理、应急响应,降低或消除问题影响,避免数据损毁、丢失
☆ 考量数据是否符合预设的质量要求,如唯一性约束、记录量校验等
★ 指标公式:1 - 告警作业个数/监控作业总个数
☆ 考量作业的运行稳定性,是否经常报错,导致数据事故
★ 指标公式:1 - 错误作业个数/作业总个数
☆ 考量数据项信息可被获取和使用的时间是否满足预期要求
★ 指标公式:延迟的高价值作业个数/高价值作业总个数
☆ 考量作业的执行效率和健康度,诊断作业是否倾斜等性能问题
★ 指标公式:1 - 危急作业个数/作业总个数
https://www.cnblogs.com/testzezhang/p/15847945.html https://mp.weixin.qq.com/s/uA-7lQN9nI6sSAt4B4aPxw https://blog.csdn.net/DolphinScheduler/article/details/119951778 https://dolphinscheduler.apache.org/en-us/docs/3.1.2/guide/data-quality https://mp.weixin.qq.com/s/xWN4L3LI1xcGEpdCmlDjzw
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。

参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。

添加社区小助手微信(Leonard-ds)
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
☞Apache DophinScheduler Meetup 成都站— 批流一体与大数据调度最佳实践
☞Apache DolphinScheduler 从 1.3.4 升级至3.1.2 过程中的问题记录及解决方案

